一种无监督可迁移的3D视觉物体抓取方法与流程
本发明涉及一种无监督可迁移的3d视觉物体抓取方法,属于机器人视觉抓取领域。
背景技术:
产品生产过程中,混杂物体分拣是非常重要的环节,该环节直接影响产品生产线的生产速度。目前工业中的混杂物体分拣很多还是由分拣工人完成,但是人工分拣存在很多问题,例如重复劳动的疲劳问题及心理问题,长时间工作的效率问题,人工成本问题。在这样的背景下,能够自动识别并分拣混杂物体的机器人便尤为重要。相比于人工分拣,机器人自动分拣的适用范围更广,可以适应工厂特殊环境,工作时间长且稳定可靠。
通过对已公开的文献、专利和工业产品调研发现,机器人自动分拣主要采用视觉抓取的方式,而视觉抓取主要分为两种:基于2d视觉的伺服抓取方式和基于3d视觉的直接抓取方式。基于2d视觉伺服抓取方式是将相机固定于机械臂上,通过对比识别采集到的图像与目标图像的差别,从而判断出机械臂应该改变的位姿,并发送给机械臂进行调整。然而视觉伺服控制机械臂进行混杂分拣的方法还存在以下不足:
1、传统的2d视觉只能测量出物体的2d位置,无法测量出物体的远近,因此很难重建出待抓取物体的具体位置,给抓取造成了较大困难。
2、视觉伺服需要进行多次迭代,抓取速度低。
3、2d视觉对光线和纹理比较敏感,容易造成错误识别。
3d机器视觉可以解决上述问题,因为3d相机可以直接测量出目标点的3d位置,从而可以直接作为目标位姿输入给机器人进行抓取。同时,由于3d相机一般有主动投射光源,因此受光线,纹理影响较小,比如3d相机可以在黑夜中进行工作,因此比2d相机的鲁棒性更高。基于3d视觉的直接抓取方式是将相机固定于支架上,采集当前物体的rgbd图像,通过传统的几何算法或者神经网络分割出目标物体,然后计算出目标物体几何中心对应的中心点坐标和法向量,发送给机械臂,从而抓取目标物体。然而传统的几何算法和基于神经网络的物体识别方法还有以下不足:
1、当前深度摄像头分辨率还较低,基于深度图的几何分割方法很难识别贴合紧密的物体,很难达到高精度分割的要求。
2、传统的几何算法泛化能力不足,识别不同的目标物体可能需要设计不同的几何算法。
3、基于神经网络的物体识别方法一般需要标注大量的数据,对每一类新物体都要重新进行数据标注,浪费大量的人力物力。
4、传统的抓取点估计算法一般会计算物体的几何中心,然而这种传统方法只适用于凸几何体,对于包含有凹形的几何体,其几何中心可能会在物体外部。
技术实现要素:
本发明需要解决混杂物体视觉分拣的问题,研制一种无监督,可迁移的3d视觉物体抓取方法,可以用于不同目标物体的混杂分拣。
本发明解决其技术问题所采用的技术方案是:
一种无监督可迁移的3d视觉物体抓取方法包括:(1)可解耦机械臂,(2)可与机械臂结合的rgbd(深度+彩色)摄像头,(3)上位机控制系统。
所述的机械臂(1)将与rgbd摄像头(2)结合,得到的rgbd图像输入到上位机控制系统中(3)中,根据所设计的无监督可迁移的3d视觉物体识别方法对抓取点中心及法向量进行估计,然后由机械臂(2)进行操纵,从而抓取到目标物体。
所述的无监督可迁移的3d视觉物体抓取方法,其特征在于该方法基于一种对抗性神经网络,以及对于新的目标物体,只用标注少量的测试集(无监督),便可以对目标物体进行识别抓取(可迁移)。该系统不仅适用于单目标物体抓取,也适用于多目标和混杂物体抓取。
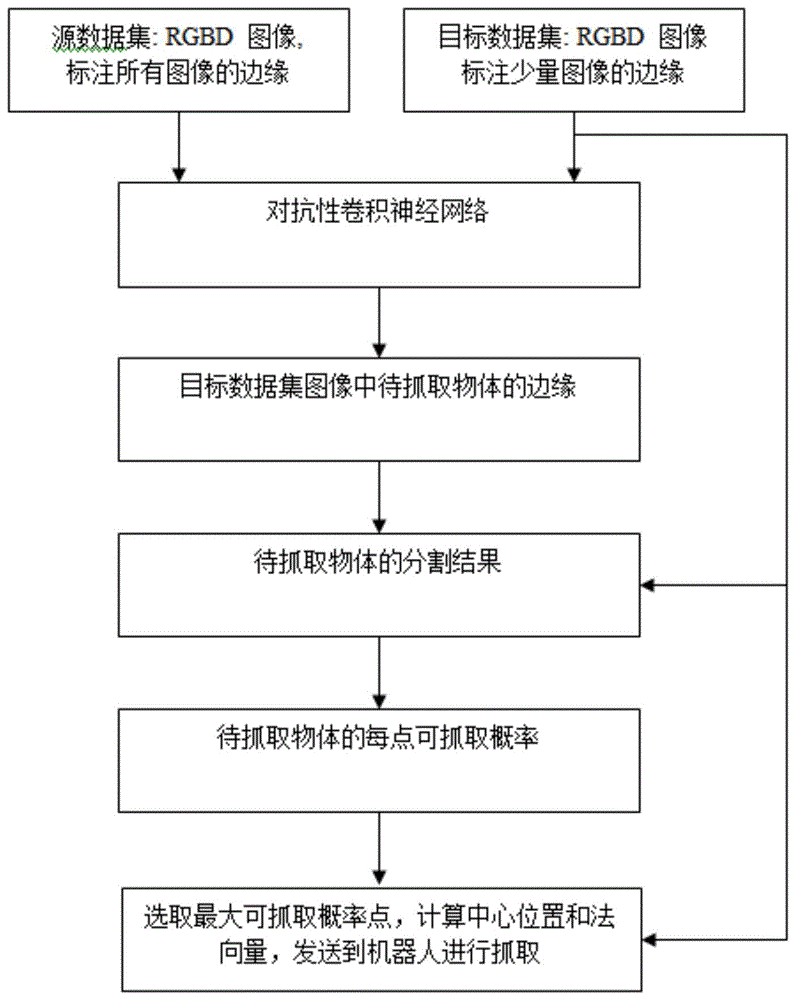
所述的无监督可迁移的3d视觉物体抓取方法,其特征在于待抓取物体的识别抓取分为如下几个步骤:
s1,获取常见的混杂待抓取物体的4通道的rgbd图像,人工标出待抓取物体的边缘部分,作为源数据集。获取项目所需的特定混杂待抓取物体,只对一小部分测试集进行边缘标注,其余图像不用标注,作为目标数据集。
s2,将源数据集和目标数据集的rgbd图像输入对抗性卷积神经网络,训练网络同时对源数据集和目标数据集的物体边缘进行准确识别。
s3,将rgbd摄像头固定于机械臂末端或者固定支架上,标定rgbd摄像头与机械臂之间的转换矩阵。将待抓取混杂物体放置于机械臂的运动范围内以及rgbd摄像头的视野范围内。
s4,拍摄待抓取物体的rgbd图像,输入s2中训练好的神经网络进行边缘识别。根据其边缘识别结果,去除深度图中的边缘及背景平面,分割出待抓取物体。
s5,根据深度图分割结果,识别待抓取物体中每个点的可抓取概率。
s6,选取可抓取概率最大点,计算该点的坐标及法向量,发送给机器人进行抓取。
本发明所涉及的无监督可迁移的3d视觉物体抓取方法,泛化能力强,不用对每一种新物体进行大量的数据标注,可以输出物体上每点的抓取概率,从而自动选取最合适的抓取点,因此适用于混杂物体的自动分拣。
附图说明
图1为本发明实施中一种无监督可迁移的3d视觉物体抓取方法的流程图;
图2为无监督可迁移的物体边缘识别的对抗性卷积神经网络图;
图3为抓取概率识别的卷积神经网络图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细描述。
s1,获取常见的混杂待抓取物体的4通道的rgbd图像,人工标出待抓取物体的边缘部分,作为源数据集{xs,ys}。获取项目所需的特定混杂待抓取物体,只对一小部分测试集进行边缘标注,其余图像不用标注,作为目标数据集{xt}。
s2,将源数据集和目标数据集的rgbd图像输入对抗性卷积神经网络,训练网络同时对源数据集和目标数据集的物体边缘进行准确识别。训练具体步骤如下:
1.输入源数据集的图像xs和标注的边缘图像ys,同时训练图2中的编码网络f和两个解码网络g1和g2来最小化预测的边缘结果与标注的边缘图像之间的差别(损失函数):
其中r,c分别代表图像中的第几行和第几列。i[n=ys(r,c)]在n等于ys(r,c)时为1,否则为0。n=1代表该点是边缘。pn代表输入图像xs时,别到的一点y(r,c)时n的概率。
输入目标数据集的图像xt,固定图2中编码网络f的参数,只训练图2中的两个解码网络g1和g2来最大化两个解码网络的预测结果,同时继续最小化步骤1中的损失函数:
2.输入目标数据集的图像xt,固定图2中两个解码网络g1和g2的参数,只训练编码网络f的参数来最小化两个解码网络的预测结果:
上述步骤中,步骤2和步骤3构成了两个对抗性的目标,最终能够迫使网络学习到数据集无关的边缘,从而在不标注的情况下正确识别目标数据集中物体的边缘。
s3,将rgbd摄像头固定于机械臂末端或者固定支架上,标定rgbd摄像头与机械臂之间的转换矩阵。将待抓取混杂物体放置于机械臂的运动范围内以及rgbd摄像头的视野范围内。
s4,拍摄待抓取物体的rgbd图像,输入s2中训练好的神经网络进行边缘识别。根据其边缘识别结果,去除深度图中的边缘及背景平面,分割出待抓取物体。
s5,根据深度图分割结果,利用图3所示的抓取概率识别网络识别待抓取物体中每个点的可抓取概率。训练该网络时,需要预先标注常见物体的可抓取点,设该点为1,然后其余不可抓取均设为0。抓取概率识别网络会根据物体分割图像拟合标注的抓取点,最终生成一个泛化的物体抓取概率图像。
s6,选取可抓取概率最大点,计算该点的坐标及法向量,发送给机器人进行抓取。
- 还没有人留言评论。精彩留言会获得点赞!