一种基于多尺度字典学习的单图像去雨方法与流程
本发明属于图像处理领域,特别涉及用字典学习的方法进行单帧图像去雨。
背景技术:
现实中,大部分计算机视觉算法都假定输入是清晰的,然而对于大多数室外视觉系统,例如视频监控和自动驾驶,雨天环境会严重影响成像质量,造成图像模糊、变形、可视性差等问题,这会大大降低系统的性能,因此,有效地消除雨水对图像的影响具有重要应用价值,特别是单张图像去雨,是去雨任务的重中之重。目前,单张图像去雨算法主要分为两类:基于先验和基于学习的方法。
基于先验的方法往往需要事先观察雨线特性,设计特定先验信息,例如雨线在某范围内多呈倾斜的直线或者具有低秩特性,但是此类算法的去雨性能很大程度上取决于先验信息的选取,难以处理现实中的复杂降雨情况。
基于学习的方法是近些年的研究热点,主要包括基于卷积神经网络(cnn)的方法,此类方法将图像去雨任务视为一个逐像素的回归任务,以整张图作为输入,去雨图作为输出,进行端对端的训练和测试。此类方法无需手工设计先验,利用cnn强大的学习能力,让网络自己学习雨线特征,但是此类方法中网络设计时缺少指导方案,缺少可解释性,不利于网络的改进和提升。
技术实现要素:
基于上述分析,本发明的目的在于提供一种多尺度字典学习的单图像去雨方法,该方法将稀疏先验引入cnn网络设计,大大提高了去雨效果
本发明提供的一种多尺度字典单图像去雨方法,包括以下具体步骤:
步骤1,根据已有干净图像,通过添加雨线得到对应合成带雨图像,将每对干净图像和合成带雨图像作为一个训练样本对,建立训练集;
步骤2,网络模型构建,所述网络模型包括粗糙雨线提取模块和精细雨线提纯模块,其中,粗糙雨线提取模块包括两个卷积层和两个relu激活函数层,用于实现对合成带雨图像的粗糙雨线提取;精细雨线提纯模块包括七个卷积层和四个relu激活函数,用于从带噪雨线图像中恢复出精细雨线图;
步骤3,利用步骤1中构建的训练集对网络模型进行训练,
步骤4,将待测试的带雨图像输入到训练好的网络模型中,获得相应的去雨图像。
进一步的,步骤2中的粗糙雨线提取模块的具体实现如下,
其中,e1,e2为两个卷积层,
进一步的,步骤2中精细雨线提纯模块的具体实现方式如下,
所述精细雨线提纯模块包括稀疏编码求解与hr特征重建两部分,其中稀疏编码是通过卷积方式求解如下最小化问题:
其中,fj,i表示第j个字典的第i个滤波器核,fj,i为三组滤波器组,即j=3,实际含义为三个不同尺度的雨线字典,记为s1、s2、s3,其转置字典记为g1、g2、g3,其中s1、s2、s3、g1、g2、g3均由卷积层实现,c为分解的通道数,zj,i为待求解的卷积稀疏编码,||.||1,||.||2分别表示l1范数与l2范数,λ为稀疏惩罚系数;
取得稀疏编码后,重建出去噪后的雨线图:
其中,
具体流程为:首先将
进一步的,利用卷积与矩阵相乘的关系将式(2)转化为传统稀疏编码问题,并且在非负稀疏编码假设下,采用ista算法求解,
其中,
进一步的,步骤3中将全局残差学习引入到网络模型中,并选择mse损失函数,以最小化此损失函数为训练目标,mse损失函数的表达式如下:
其中,θ是指网络模型参数,l为训练集中训练样本的索引,yl-rl为网络模型输出的去雨图像,与真实的干净图像xl做差并累加得到最终误差,使得最终误差最小化实现网络模型的优化。
进一步的,步骤1中采用翻转、旋转、缩放、裁剪的手段增加训练集中的图像数量,然后通过photoshop对每个干净图像添加雨线,得到合成带雨图像,将对应的干净图像和合成带雨图像作为一个训练样本对。
本发明提供了一种单图像去雨算法,综合利用了稀疏理论和cnn学习能力,通过求解sc中的优化问题得到迭代公式,并用cnn实现,大大提高了sc问题的求解效率和重建精度。
附图说明
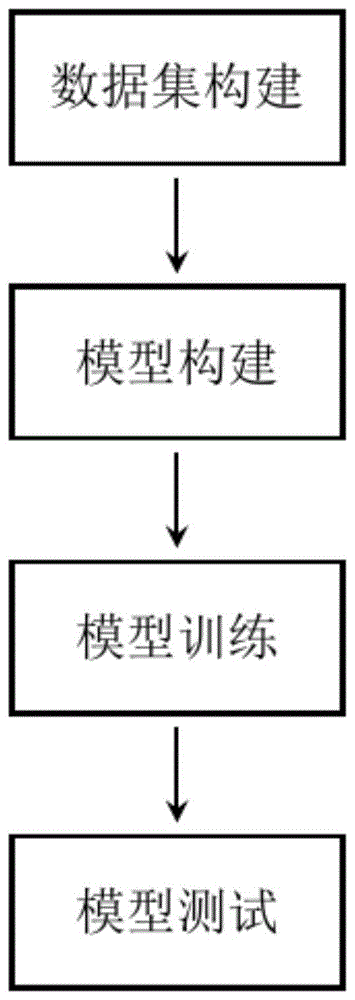
图1为本发明实施例中网络模型构建的大致流程图。
图2为稀疏编码求解示意图。
图3为rain12数据集中猫咪图像各算法去雨对比图。
图4为rain1200数据集中森林图像各算法去雨对比图。
具体实施方式
为了更清楚地了解本发明,下面具体介绍本发明技术内容。
如图1所示,本发明提供的一种基于多尺度字典学习的单图像去雨方法,具体分为四个步骤:
步骤1,根据已有干净图像,通过添加雨线得到对应合成带雨图像,将每对干净图像和合成带雨图像作为一个训练样本对,建立训练集;
由于训练数据集有限,需要经过数据增强方法来有效利用有限的hr图像。数据增强是扩充数据样本规模的一种有效地方法。深度学习是一种数据驱动的方法,训练数据集越大,训练的模型泛化能力越强。然而,实际中采集数据时,很难覆盖所有场景,而且采集数据也需要大量成本,这就导致实际中训练集有限。如果能够根据已有数据生成各种训练数据,就能做到更好的开源节流,这就是数据增强的目的。
常用的数据增强技术有:
(1)翻转:翻转包括水平翻转和垂直翻转。
(2)旋转:旋转就是顺时针或者逆时针的旋转,注意在旋转的时候,最好旋转90-180°,否则会出现尺度问题。
(3)缩放:图像可以被放大或缩小。放大时,放大后的图像尺寸会大于原始尺寸。大多数图像处理架构会按照原始尺寸对放大后的图像进行裁切。
(4)裁剪:裁剪图片的感兴趣区域,通常在训练的时候,会采用随机裁剪出不同区域,并重新放缩回原始尺寸。
(5)平移:平移是将图像沿着x或者y方向(或者两个方向)移动。我们在平移的时候需对背景进行假设,比如说假设为黑色等等,因为平移的时候有一部分图像是空的,由于图片中的物体可能出现在任意的位置,所以说平移增强方法十分有用。
(6)添加噪声:过拟合通常发生在神经网络学习高频特征的时候(因为低频特征神经网络很容易就可以学到,而高频特征只有在最后的时候才可以学到)而这些特征对于神经网络所做的任务可能没有帮助,而且会对低频特征产生影响,为了消除高频特征我们随机加入噪声数据来消除这些特征。
首先,本实施例为了训练cnn模型,需要构造训练样本对。通过photoshop软件对上述干净图像添加雨线,得到合成带雨图像。在获得干净和合成图像对后,采用翻转、旋转、缩放、裁剪的手段增加训练样本对数量,然后即可输入模型进行训练。
步骤2,网络模型构建,具体包括粗糙雨线提取模块和精细雨线提纯模块两部分。
步骤2a,粗糙雨线提取模块由简单的两层卷积层和两个relu层实现,实现对带雨图像的粗糙雨线提取;
其中,e1,e2为两个卷积层,
步骤2b,构建精细雨线提纯模块,包括七个卷积层,四个relu激活函数,用于对上述粗糙(带噪)雨线图像进行去噪处理,得到干净的雨线;
精细雨线提纯模块是本发明的核心内容,关键在于求解三个字典s1、s2、s3及其转置字典g1、g2、g3:
其中,fj,i表示第j个字典的第i个滤波器核,fj,i为三组滤波器组,即j=3,实际含义为三个不同尺度的雨线字典,记为s1、s2、s3,其转置字典记为g1、g2、g3(s1、s2、s3、g1、g2、g3均由卷积层实现),c为分解的通道数,zj,i为待求解的卷积稀疏编码,||.||1,||.||2分别表示l1范数与l2范数,λ为稀疏惩罚系数,本实施例中设置为1。
取得稀疏编码后,即可重建出去噪后的雨线图像;
其中,
针对于第一个最小化问题,利用卷积与矩阵相乘的关系可以转化为传统稀疏编码问题,并且在非负稀疏编码假设下,采用ista算法求解:
其中,
据此,可以得到精细雨线提纯模块中的稀疏编码迭代求解过程,cnn实现示意图如附图2所示,s1、s2、s3和g1、g2、g3均可通过卷积层实现。经过粗糙雨线提取模块后,粗糙雨线图像r∈被输入进精细雨线提纯模块部分,该部分主要分为两步:稀疏编码求解与hr特征重建,求解稀疏编码对应图2,通过迭代卷积实现的ista算法,经过一定次数后将输出最优稀疏编码。
最终,整个网络流程为:输入合成带雨图像y,经过两个卷积e1,e2和两个relu得到粗糙雨线图像r∈,将
步骤3,利用步骤1中构建的训练集对网络模型进行训练。同时,本实施例中选择mse损失函数:
其中,θ是指网络模型参数,l为训练集中训练数据的索引,yl-rl为网络模型输出的去雨图像,与真实的干净图像xl做差并累加得到最终误差,据此进行网络优化。
步骤4,将待测试的带雨图像输入到训练好的网络模型中,获得相应的去雨图像。
测试过程中采用峰值信噪比(psnr)和结构相似度(ssim)作为衡量标准,二者具体定义如下:
psnr=10*log10(2552/mean(mean((x-y)2)))
ssim=[l(x,y)a]×[c(x,y)b]×[s(x,y)c]
其中,
其中,psnr与ssim数值越高,则说明重建效果越好。
测试过程中,选择cnn、jorder与didmdn作为对比算法,视觉对比如附图4所示,本专利方法更容易去除图像中的雨线,同时保存良好细节信息,而对比算法去雨效果不理想,去雨不完全或产生模糊结果,甚至产生伪影。至于定量指标,则选择常用的两个数据集(rain12和rain1200)作为测试集,测试结果如表1所示,可以看出:本专利的方法大幅度提升去雨结果的psnr和ssim,说明了本专利方法的有效性。
表1测试结果
应当理解的是,上述针对实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!