视频人物关系识别方法与流程
本发明涉及计算机视觉和自然语言处理领域,尤其涉及一种视频人物关系识别方法。
背景技术:
视频中人物的社交关系是视频理解的重要课题,它既可以帮助观众更好地理解视频内涵,也将支撑许多视频相关的应用,如视频标注、视频检索和视觉问答等。传统的方法主要分析可由视觉内容直接体现的空间或动作关系等,很少涉及到更高层的语义信息,如视频中人物之间的社交关系。
与此同时,现有的视频分析工作主要针对人工剪裁的富含语义的图片或短视频,但是在现实场景的长视频中,往往却包含着大量与人物关系无关的信息,不仅场景和人物频繁切换,社交关系的呈现方式也更为复杂。因此,现有技术往往难以取得令人满意的效果。
技术实现要素:
本发明的目的是提供一种视频人物关系识别方法,可以精确地识别出人物之间社交关系的类别。
本发明的目的是通过以下技术方案实现的:
一种视频人物关系识别方法,包括:
对原始视频数据进行等间距采样,得到一个由视频帧组成的序列;并对与原始视频数据相关的文本进行预处理,得到与视频帧序列相对应的文本信息;
建立识别模型,包含三个模块:人物搜索模块,对每一人工标记的目标人物,均通过重识别方法从视频帧序列中识别出目标人物出现的片段;多模态嵌入模块,通过多流的网络,提取每一目标人物出现的片段中每一视频帧及对应文本信息的视觉特征和文本特征,并结合注意力机制,得到相应片段的多模态表征;关系分类模块,利用社交关系分类器根据每一片段的多模态表征,得到每一片段在所有社交关系类别上的概率分布;对于一对目标人物a与b,选出至少包含目标人物a或b的多个片段,并计算所选出片段的概率分布的均值,作为一对目标人物的社交关系概率分布,将其中概率最大的一项所对应的社交关系作为识别的结果。
由上述本发明提供的技术方案可以看出,结合视觉信息以及丰富的文本信息,能够准确的的识别视频中任务之间的社交关系;在电影数据集上进行了人物社交关系的识别验证,结果表明该方案在客观评价指标上取得了突出的效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
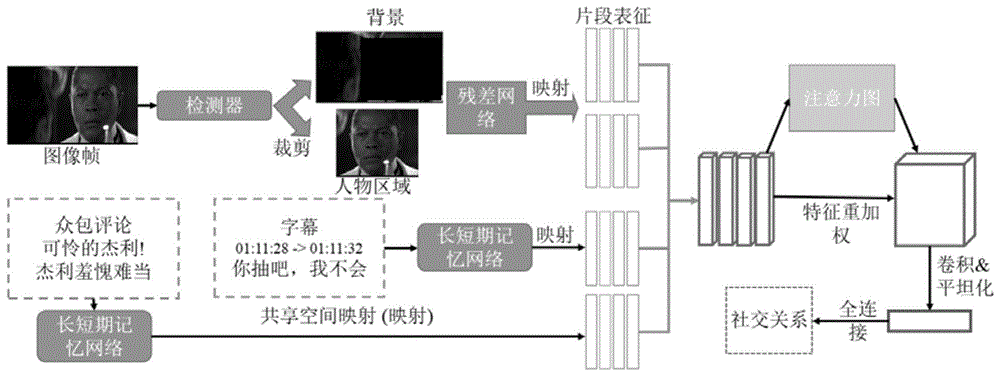
图1为本发明实施例提供的一种视频人物关系识别方法的框架图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
现有技术所存在的技术缺陷的主要问题就在于语义标注的缺失,而正是这一环节依赖大量的人工标注,因此导致了极高的成本。与此同时,也注意到,随着社交媒体平台的发展,视频往往会吸引到大量的众包评论,这些评论不仅可以提供主观的描述,而且往往包含时间戳信息,因此可以与视频中的帧直接对应。显然,这些文本信息为识别人物社交关系提供了新的线索。然而,众包文本包含着大量的无关甚至噪声信息,需要在视频与文本信息有效对齐的基础之上进行筛选和表征,才能够更好地支撑本发明的任务。
如图1所示,为本发明实施例提供的一种视频人物关系识别方法的框架,其主要包括:
1、数据的预处理。
本发明实施例中,将完整视频作为输入,对原始视频数据进行等间距采样,得到一个由视频帧组成的序列;并对与原始视频数据相关的文本进行预处理,得到与视频帧序列相对应的文本信息。
示例性的,可以以1帧/秒的采样频率进行采样得到由视频帧组成的序列。
对文本进行预处理包括:对众包评论文本信息,通过正则规则进行过滤;对过滤后的众包评论文本信息进行时间轴校正。
示例性的,众包评论文本信息的噪声较高,为了过滤掉无关的文本,可以参考屏蔽词网站上提供的正则规则进行过滤。同时,考虑到众包评论发送具有一定的时间延迟,可以以30字/1分钟的打字速度对众包评论的发送时间做了矫正。
2、模型的建立。
本发明实施例中,建立的识别模型,包含三个模块:人物搜索模块、多模态嵌入模块以及关系分类模块。
1)人物搜索模块。
人物搜索模块,对每一人工标记的目标人物,均通过重识别方法从视频帧序列中识别出目标人物出现的片段;具体来说:
首先,基人物检测方法,逐帧地及无差别地定位出所有视频帧序列中出现的人物区域,保存相应的人物区域及对应的视频帧。示例性的,可以基于fasterr-cnn的人物检测方法来检测人物区域,对fasterr-cnn人物检测器使用vgg-16网络进行初始化,检测的置信度大于0.85的区域将被视为有人物出现的区域。
其次,对于每个目标人物,人工标记指定数目的包含目标人物的人物区域作为参照;采用重识别方法从保存的人物区域及中估计每个人物区域内相应目标人物出现的概率;示例性的,对于一对目标人物中的每个人物,都随机选取10张包含该人物的检测区域作为参照,并使用kpmm(克罗内克积匹配模型)来估计出每个由fasterr-cnn检测得到的检测区域内每个目标人物出现的概率,具体而言,所有的检测区域的分辨率都被归一化为256×128,先采用数据增广策略(在训练阶段,通过对于训练图像的横向翻转来进行训练数据的扩充)以增强该模型的泛化能力,再使用难例挖掘的策略(在训练过程的每个批次中,只有那些交叉熵损失大于0.05的样本才会进行反向传播以优化该模型的参数)来增强模型的效果。对于每一帧,只有出现概率最高的区域才会被记录下来。如果该帧中没有区域被检测到,则出现概率记为0。
如果某一视频帧中目标人物出现的概率高于设定的概率阈值,则保留相应视频帧;最终将所保留的视频帧聚合为相应目标人物出现的片段。
示例性的,通过重识别的方式估计目标人物出现的概率后,可以将潜在目标人物出现的帧都保存下来,构成潜在序列{<imgt,probt>},其中imgt和probt分别表示时刻t的潜在的目标人物出现帧和出现概率。为了增加表示的稳定性,我们先对于出现概率序列进行滑动平均操作。考虑到片段相比于单帧图像,包含更多且更完整的信息以助益于关系的识别,我们通过一个全局阈值(也即前文提到的概率阈值)θ=0.70筛选相应的视频帧,因为相邻帧的出现概率都经过了滑动平均处理,按照全局阈值筛选也就得到了目标人物的出现片段。之后,删去过短的片段或分割过长的片段,把所有片段长度控制在(6,15)的长度范围内,以使得每一个片段都包含有充足且精简的信息量。
通过上述人物搜索模块,对于每一个目标人物都能够,单独识别出对应的片段。
2)多模态嵌入模块。
多模态嵌入模块,通过多流的网络,提取每一目标人物出现的片段中每一视频帧及对应文本信息的视觉特征和文本特征,并结合注意力机制,得到相应片段的多模态表征。
a、对于片段中的每一帧,我们先使用一个多流的网络来分别提取出多个信息流的特征,具体来说:通过预训练的残差网络(例如,在imagenet数据集上预训练得到的50层残差网络)从目标人物出现的片段中提取视觉特征:从出现概率最高的人物区域,以及由其余部分组成的背景区域中提取对应的特征;通过预训练的长短期记忆网络(例如,预先训练好的3层的长短期记忆网络)来从每一帧对应的文本信息中提取文本特征:字幕文本特征与众包评论文本特征。
本领域技术人员可以理解,字幕文本主要是指电影中人物的对话和旁白文本;众包评论文本主要是指用户在观看电影时发的弹幕评论文本,这两类文本特征都是指通过长短期记忆网络从相应的文本中抽取出的文本向量。
b、再通过特征融合操作将多流特征映射到同一个特征空间中,并建立起特征间的关联。具体来说:通过特征融合操作将上述视觉特征与文本特征映射到同一个特征空间中,并建立起特征间的关联,得到融合后的片段级别的特征。
示例性的,考虑到文本与视觉特征之间所具有的关联性,对以上4类特征,均通过全连接层将它们映射到64维的共享特征空间中来进行特征融合,通过每一帧的特征的拼接,得到了片段级别的多流特征fi∈rn×64,i∈[1,2,3,4],分别表示从出现概率最高的人物区域提取到的特征、从由其余部分组成的背景区域提取到的特征、字幕文本特征、众包评论文本特征;n为片段中的视频帧数目。
通过损失函数来拉近文本特征与视觉特征的距离,通过软间隔m来放置过度拟合,损失函数为:
为了增加时间上的鲁棒性,对时间上相邻的特征进行高斯模糊:
其中,fi,t表示第t帧第i流特征,t=1,…,n;g(·)为期望为0,方差为1的高斯函数;k=[-2,2],[-2,2]表示时间窗口范围。
根据i和t的顺序将
c、利用注意力机制,对片段级别的特征进行整合,得到片段的多模态表征。
得到融合后的片段级别的特征f∈r4×n×64后,考虑到每一类的特征对于社交关系的识别的重要程度都是不同的,同时每一帧的重要程度也互不相同,所以我们又通过一个注意力机制来对特征f进行整合。具体来说,通过卷积(例如,1×1×64的卷积操作)、批量池化以及线性整流操作,得到能够反映片段中每一帧上每一流特征重要性的注意图a∈r4×n,从而通过特征重加权的方式进行特征整合:
将整合后的特征
3)关系分类模块。
关系分类模块,利用社交关系分类器(依次连接的两个全连接层以及一个softmax层)根据每一片段的多模态表征,得到每一片段在所有社交关系类别上的概率分布;对于一对目标人物a与b,选出至少包含目标人物a或b的多个片段,并计算所选出片段的概率分布的均值,作为一对目标人物的社交关系概率分布,将其中概率最大的一项所对应的社交关系作为识别的结果。具体来说,社交关系分布将表示为一个n维的向量,分别对应于n类社交关系,其中概率最大的一项所对应的社交关系就作为模型识别的结果。
本发明实施例中,对于每一片段都预先计算出概率分布,此后,可以基于相关片段的概率分布来计算一对指定目标人物的社交关系。因为考虑到社交关系并非仅仅体现在两个目标人物共同出现的片段中,而哪怕只包含一个目标人物的片段也有可能对两个人物间的关系有揭示作用,所以会利用所有至少包含其中一个目标人物的片段来判断两个目标人物间的社交关系。比如说ab两个目标人物,对于两个至少包含a或b的片段s1和s2,s1在3个社交关系类别上的概率分布为[0.1,0.6,0.3],s2在3个社交类别上的概率分布为[0.3,0.5,0.2],则计算得到的均值就是[0.2,0.55,0.25],则ab的关系就是第二类社交关系。
此外,关于社交关系的各个类别可以根据情况预先定义,例如,朋友、同事等。
同时,考虑到上一步中得到的注意力图a可以反映每一帧上每一流的特征的重要性得分,所以利用在训练过程中得到的注意力图来增强测试过程的输入的人物出现片段的质量。具体来说,保存了在训练过程中产生的注意力图a以及其相应的视频帧,再在此基础上训练一个基于径向基函数的支持向量回归模型(svr)以建立起从视频帧的文本特征到重要性得分的映射(考虑到文本特征对于社交关系更加敏感)。因此,该支持向量回归模型可以被看成是一个针对视频帧的过滤器。在此基础之上,只有那些由得分在前20%之内的视频帧组成的人物片段才参与到测试过程中,这样就确保了测试阶段的输入片段的质量。
注意力图本质上反映的是当前片段上的每一帧对于社交关系判断的重要性,所以上述操作只是将训练片段的注意力图作为svr模型的标签,将训练片段本身作为svr模型的训练数据,通过svr模型来拟合从片段到注意力图的映射,这样训练得到的svr模型就能够预先对测试片段去预测片段上每一帧的注意力(在社交关系判断上的重要性)
3、基于上述建立的模型,在训练阶段,利用包含已知不同目标人物的标签和不同目标人物之间的社交关系标签数据去训练识别模型,当识别模型训练完毕后,能够在视频中进行人物社交关系的识别。
对于每一对目标人物,为保证训练数据的质量,只有它们共同出现的片段才会参与到训练当中。在训练的过程中,使用随机梯度下降算法来优化交叉熵损失函数,距离损失函数losspush以及l2正则化损失函数,使用的优化器是动量优化器(momentumoptimizer)反向传播优化参数。每个批次的大小为4,初始学习率设置为0.0001,随着训练轮数指数级下降。
需要说明的是,上述实施例中所涉及的参数数值均为举例,并非构成限制;具体的参数数值可根据实际应用场景中的数据特点进行调整,此外,图1中所示的文本信息的内容也仅用于示意,并非限制。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!