一种基于动态修正向量的图像增量学习方法与流程
本发明涉及知识蒸馏(knowledgedistillation)技术和代表性记忆(representativememory)方法,利用动态修正向量(dynamiccorrectionvector)的技巧,在保持旧类别分类识别精度的前提下,同时提高对新增类别数据的分类精度,从而实现在原有数据集上的增量学习识别任务。
背景技术:
近年来,深度卷积神经网络(deepconvolutionalneuralnetwork,dcnns)大量用于检测、分割、物体识别以及图像的各个领域。尽管卷积神经网络应用的很成功,但是它被计算机视觉以及机器学习团队开始重视是在imagenet竞赛。2012年,alexnet通过实施deep-cnn并将dcnns推入大众视野下,该结果达到了前所未有的效果,几乎比当时最好的方法降低了一半的错误率,从而轻松赢得了imagenet大规模视觉识别挑战(islvrc)。从此之后,dcnns就主导了islvrc,并在mnist、cifar-100和imagenet等流行的图像数据集上表现出色。
dcnns能够在同一个模型中实现特征提取和分类识别,但是各个领域的任务大不相同,即使对模型的参数空间稍作修改都会对模型输出产生极大的影响。实际应用场景中,数据集都是随着时间逐步收集的。所以,dcnns的学习任务通常分为多个阶段,称之为增量学习。传统的学习策略应用于增量学习会造成在新任务识别能力很高的同时,旧任务上的识别能力大幅度下降。这就是dcnn增量训练的另一个难题——灾难性遗忘问题,可参考文献1(i.j.goodfellow,m.mirza,d.xiao,a.courville,andy.bengio.“anempiricalinvestigationofcatastrophicforgettingingradient-basedneuralnetworks.”arxivpreprintarxiv:1312.6211,2013,即i.j.goodfellow,m.mirza,d.xiao,a.courville,andy.bengio.基于梯度的神经网络中灾难性遗忘的证实研究.arxivpreprintarxiv:1312.6211,2013)。由于新的数据被输入dcnns时,模型会遗忘之前的学习任务,这要求在引入新数据的同时进行再次训练时使用先前的数据。
近年来在增量学习方面取得了较大进展,例如icarl,它是目前计算机视觉领域最先进的类别增量学习方法。它将深度学习与k近邻相结合,利用深度学习提取每个数据点的高级特征表示,并将knn作为最终分类器。在分类过程中,它使用属于该类的所有训练数据(或保留的示例)计算某个类的平均数据表示,为测试数据找到最近的类别的平均表征,并相应地分配类标签。为了在类数量急剧增加时减少内存占用,该方法为每个类维护一个示例集。为了构造示例,它选择那些最接近该类的平均表示的数据点。通过新旧数据的结合,避免了灾难性遗忘,可参考文献2(rebuffi,s.,kolesnikov,a.,andlampert,c.h.(2016).“icarl:incrementalclassifierandrepresentationlearning.”corr,abs/1611.07725,即rebuffi,s.,kolesnikov,a.,andlampert,c.h.(2016).icarl:增量分类器和表示学习corr,abs/1611.07725)。尽管该方法在一部分数据集上的性能令人印象深刻,但它在生物信息学数据集上的效果却急剧下降,说明这种方法缺乏泛化性。同时,突触可塑性理论在增量学习中也起着重要的作用。ewc就是受到该理论的启发,是一个非常实用的解决方案,可以解决训练一组序列分类模型时的灾难性遗忘问题。该方法通过考虑每个权值的fisher信息,并在损失函数中添加一个惩罚项,在权值与旧数据上的分类器密切相关的情况下,防止权值变化过大,可参考文献3(kirkpatrickj,pascanur,rabinowitzn,etal.overcomingcatastrophicforgettinginneuralnetworks[j].proceedingsofthenationalacademyofsciences,2017,114(13):3521-3526,即kirkpatrickj,pascanur,rabinowitzn,etal.“克服神经网络中的灾难性遗忘”proceedingsofthenationalacademyofsciences,2017,114(13):3521-3526)。
大数据背景下,很多中小企业以及个人不能承担大型分布式计算集群的费用。增量学习作为一种减少对计算开销时间和系统内存依赖的有效手段,为普通用户进行大数据处理提供了一种新的解决方式,在经济社会的发展中起着重要的作用,需要对增量学习方法进行更深入和更广泛的研究。
技术实现要素:
为了解决实际应用场景下深度模型对动态变化的数据集进行训练的问题,减小对分布式计算系统的依赖,并且节省大量的计算开销和系统内存,本发明提出以32层残差网络resnet-32为基础,通过引入知识蒸馏技术和代表性记忆方法,利用动态修正向量的技巧,缓解了灾难性遗忘问题,提高了增量学习的性能。这种增量学习方法适应了实际应用场景的需求,在人工智能领域具有重要的研究和应用价值。
本发明实现上述发明目的所采用的技术方案为:
一种基于动态修正向量的图像增量学习方法,包括以下步骤:
s1:构造以resnet-32网络层结构为模型的主干网络,用于识别增量阶段任务中出现的新旧类别,resnet-32模型采用adam训练优化器,同时,基础分类损失函数是kullback-leiblerdivergence相对熵损失函数;
s2:resnet-32引入知识蒸馏损失函数,帮助新模型学习旧类别中的知识,缓解灾难性遗忘问题;
s3:训练方式采用代表性记忆方法,即预定义的超参数k用于固定系统内存中保存的旧类别数据的数目,从而联合新到来的数据训练resnet-32模型:内存中的每一类数据的数目都相同;每次增量训练结束后,随机删除内存中每一类的旧数据,为新到来的数据预留存储空间,动态修正向量用于训练过程中统计模型训练的数据类别,防止模型在预测阶段过多偏向于数据较多的类别;
s4:重载上一增量阶段训练的最佳模型,重复s2~s3步骤,评估在所有测试集上的性能,直到训练完所有增量数据。
进一步,所述步骤s1中,resnet-32是一个残差结构的卷积神经网络,残差结构可以防止过拟合发生,提高模型在训练中的收敛速度,在增量学习中起着至关重要的作用。resnet-32模型采用adam训练优化器,提高了模型参数的优化速率,同时,基础分类损失函数是kullback-leiblerdivergence相对熵损失函数。它有着比交叉熵损失更加低的数值,减小了超参数的选取的敏感性,定义为:
其中xi表示第i个数据,yi表示第i个数据的标签,
再进一步,所述步骤s2中,resnet-32引入知识蒸馏具体来说,在每一个增量步骤中,教师模型是前一个增量步骤中完全训练过的学生模型,而学生模型是当前步骤的更新模型。例如,假设f(xi)是教师模型在i增量步骤中预测的输入xi的概率分布,g(xi)是学生模型的softmax层的输出,随着分类类别数目的增长,存储在每个类的代表性内存中的样本会减少。为了解决这个问题,学生模型可以从教师模型中学习已有的知识,换句话说,旧数据的知识被表示为教师模型的参数,因此,从教师模型的概率标签中间接地学习已有的数据集;
概率标签由教师模型的分类层计算得到,训练数据有两个标签,分别是概率标签和真实标签,每个样本的概率标签与类的尺寸相同,为了计算f(xi)和g(xi)之间的距离,使用kullback-leiblerdivergence作为知识提取过程中的损失函数,与常用的交叉熵损失相比,kullback-leiblerdivergence损失较小,有利于超参数的调整,通过最小化蒸馏损失,学生模型可以从教师模型中获得足够的信息,知识蒸馏损失函数
上式中t是将概率标签提升到指数1/t的温度参数,参数t可以强化训练模型中已有的知识。特别是当t=1时,知识蒸馏损失函数退化为分类损失函数,当温度值大于0.9时,得分较低的等级对结果的影响更小,当t>1时,得分高的类对损失的影响较小,而得分低的类对损失的影响较大,因此,温度参数迫使网络更加关注细粒度分离,通过知识蒸馏,网络可以有选择地学习更加鲁棒的特征。
再进一步,所述步骤s3中,原有的知识蒸馏损失存在问题,对于现有的类别,教师模型中存在明显的噪声,会对学生模型产生误导。对于新的增量类别,由于教师模型使用旧类生成概率标签,因此它们可能是不正确的,并导致学生模型的性能恶化,为了解决这些问题,我们使用动态修正向量
其中n是现有类的数量,k是新类的数量,·是点乘操作的符号,修正向量将教师模型生成的概率标签和分类损失生成的真实标签相加,因此,它在训练过程中增加的计算开销可以忽略不计,向量
其中
因此,通过结合动态修正向量技术,在下面的公式中推导出新的损失函数:
其中
因此,应用动态修正向量后,学生模型g′(x)在预测中的预测结果由下面的公式给出:
其中·为点乘法运算符号。该操作仅仅在测试集上运用的。
实验中数据集采用mnist和cifar-100。
mnist包含70,000张图片,其中60000张用于训练,10000张用于测试。它包括从0到9的手写数字图像。每个图像有28×28个灰度像素。在实验中,我们将增量步骤设置为2和5,即,新类分别依次添加2和5。在每一次增量训练结束时,我们都会对性能进行评估。
cifar-100包含60000个图像,分为100个对象类和20个超类。每班有500张训练图片和100张测试图片。100个对象类以随机顺序将任务分为5、10、20和50个任务。因此,分别有20步、10步、5步和2步增量训练。在每一次增量训练结束时,我们都会评估性能。
对比的增量学习实验方法采用lwf、icarl和dtm。模型分别采用vgg-16以及resnet-32。我们将多类精度分为最后一个增量任务alast的精度和平均增量任务amean的精度两部分。amean评估整个增量过程的性能。对于所有的增量阶段,它公平地反映了每种方法的平均精度。alast强调最后一个增量阶段的准确性。
表1为各种增量学习技术在mnist和cifar-100上的比较结果:
表1。
本发明的技术构思为:鉴于实际生活中数据集都是动态变化的,为了解决深度模型对动态变化的数据集进行训练的问题,减小对分布式计算系统的依赖,并且节省大量的计算开销和系统内存,本发明提出以32层残差网络resnet-32为基础,通过引入知识蒸馏技术和代表性记忆方法,利用动态修正向量的技巧,缓解了灾难性遗忘问题,提高了增量学习的性能。这种增量学习方法适应了实际应用场景的需求,在人工智能领域具有重要的研究和应用价值。。
与现有的技术相比,本发明的有益效果是:与传统的增量学习方法相比,本发明大大节省了计算开销和对系统内存的依赖,并结合知识蒸馏和动态修正向量,成功缓解了增量学习中的灾难性遗忘问题。
附图说明
图1为构建resnet-32的训练的流程图。
图2为采用代表性记忆的流程图。
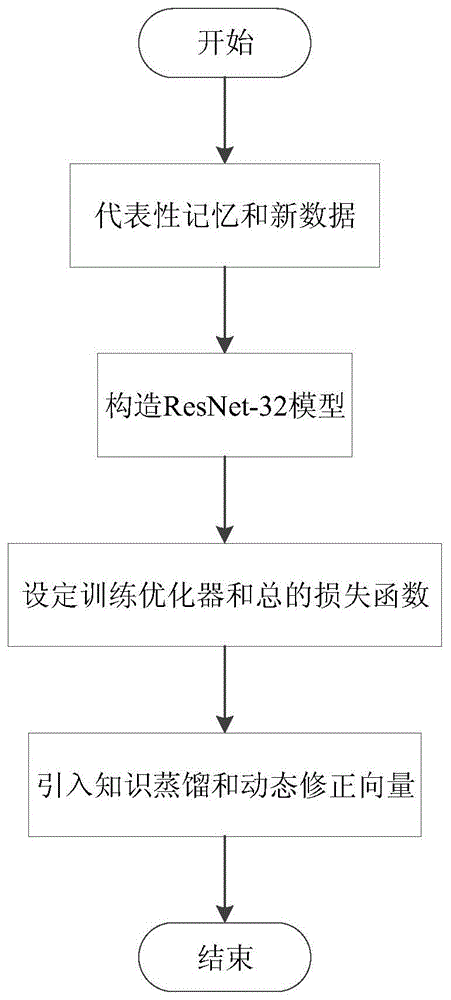
图3为基于动态修正向量的图像增量学习方法的流程图。
具体实施方式
下面结合说明书附图对本发明做进一步说明。
参照图1~图3,一种基于动态修正向量的图像增量学习方法,解决了深度模型对动态变化的数据集进行训练的问题,减小对分布式计算系统的依赖,并且节省大量的计算开销和系统内存,本发明提出以32层残差网络resnet-32为基础,通过引入知识蒸馏技术和代表性记忆方法,利用动态修正向量的技巧,缓解了灾难性遗忘问题,提高了增量学习的性能。
本发明包括以下步骤:
s1:构造以resnet-32网络层结构为模型的主干网络,用于识别增量阶段任务中出现的新旧类别,resnet-32模型采用adam训练优化器,同时,基础分类损失函数是kullback-leiblerdivergence相对熵损失函数;
s2:resnet-32引入知识蒸馏损失函数,帮助新模型学习旧类别中的知识,缓解灾难性遗忘问题;
s3:训练方式采用代表性记忆方法,即预定义的超参数k用于固定系统内存中保存的旧类别数据的数目,从而联合新到来的数据训练resnet-32模型:内存中的每一类数据的数目都相同;每次增量训练结束后,随机删除内存中每一类的旧数据,为新到来的数据预留存储空间,动态修正向量用于训练过程中统计模型训练的数据类别,防止模型在预测阶段过多偏向于数据较多的类别;
s4:重载上一增量阶段训练的最佳模型,重复s2~s3步骤,评估在所有测试集上的性能,直到训练完所有增量数据。
进一步,所述步骤s1中,resnet-32是一个残差结构的卷积神经网络,残差结构可以防止过拟合发生,提高模型在训练中的收敛速度,在增量学习中起着至关重要的作用,resnet-32模型采用adam训练优化器,提高了模型参数的优化速率,同时,基础分类损失函数是kullback-leiblerdivergence相对熵损失函数。它有着比交叉熵损失更加低的数值,减小了超参数的选取的敏感性,定义为:
其中xi表示第i个数据,yi表示第i个数据的标签,
再进一步,所述步骤s2中,resnet-32引入知识蒸馏具体来说,在每一个增量步骤中,教师模型是前一个增量步骤中完全训练过的学生模型,而学生模型是当前步骤的更新模型,例如,假设f(xi)是教师模型在i增量步骤中预测的输入xi的概率分布,g(xi)是学生模型的softmax层的输出,随着分类类别数目的增长,存储在每个类的代表性内存中的样本会减少。为了解决这个问题,学生模型可以从教师模型中学习已有的知识,换句话说,旧数据的知识被表示为教师模型的参数,因此,从教师模型的概率标签中间接地学习已有的数据集;
概率标签由教师模型的分类层计算得到,训练数据有两个标签,分别是概率标签和真实标签。每个样本的概率标签与类的尺寸相同,为了计算f(xi)和g(xi)之间的距离,我们使用kullback-leiblerdivergence作为知识提取过程中的损失函数,与常用的交叉熵损失相比,kullback-leiblerdivergence损失较小,有利于超参数的调整,通过最小化蒸馏损失,学生模型可以从教师模型中获得足够的信息,。知识蒸馏损失函数
上式中t是将概率标签提升到指数1/t的温度参数,参数t可以强化训练模型中已有的知识。特别是当t=1时,知识蒸馏损失函数退化为分类损失函数,当温度值大于0.9时,得分较低的等级对结果的影响更小。当t>1时,得分高的类对损失的影响较小,而得分低的类对损失的影响较大,因此,温度参数迫使网络更加关注细粒度分离。通过知识蒸馏,网络可以有选择地学习更加鲁棒的特征。
再进一步,所述步骤s3中,原有的知识蒸馏损失存在问题,对于现有的类别,教师模型中存在明显的噪声,会对学生模型产生误导,对于新的增量类别,由于教师模型使用旧类生成概率标签,因此它们可能是不正确的,并导致学生模型的性能恶化,为了解决这些问题,我们使用动态修正向量
其中n是现有类的数量,k是新类的数量,·是点乘操作的符号,修正向量将教师模型生成的概率标签和分类损失生成的真实标签相加,因此,它在训练过程中增加的计算开销可以忽略不计,向量
其中
因此,通过结合动态修正向量技术,在下面的公式中推导出新的损失函数:
其中
因此,应用动态修正向量后,学生模型g′(x)在预测中的预测结果由下面的公式给出。
其中·为点乘法运算符号。该操作仅仅在测试集上运用的。
综上所述,本发明提出以32层残差网络resnet-32为基础,通过引入知识蒸馏技术和代表性记忆方法,利用动态修正向量的技巧,缓解了灾难性遗忘问题,提高了增量学习的性能,有效地提高了实际应用价值,扩大了应用领域。对发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!