基于深度学习的行人检测模型构建方法及行人检测方法与流程
本发明涉及计算机视觉和模式识别领域,具体涉及一种基于深度学习的行人检测模型构建方法及行人检测方法。
背景技术:
计算机视觉近几年来一直是研究的热点和难点,而行人检测作为高层视觉任务的基础,已成为计算机视觉领域中至关重要的研究问题。
计算机视觉即通过机器视觉来模仿人眼的视觉系统,认知心理学和神经生物学的研究发现,人类在识别一个具体的物体是什么之前具有一种很强的感知物体的能力。对一幅复杂的图像来说,人类的视觉系统在一开始的反应时间内只会关注其中的某些部分,并忽略图像中其余不显著的部分。这进一步说明在识别一个具体事物之前,在人类的视觉系统中存在一个简单的视觉注意机制,该机制用来筛选出最有可能含有物体的区域。
近年来,卷积神经网络(cnn)在计算机视觉和模式识别方面表现出了强大的能力。许多基于cnn的物体检测方法已经被提出,这促进了行人检测的学术研究和应用进展。目前最先进的行人检测方法为ssd,ssd是端到端的目标检测算法,ssd框架主要包括两部分:特征提取网络和预测网络。其中,特征提取网络用于提取图像特征,生成特征图,现有的特征提取网络提前到的特征不够丰富,且参数多、计算量大。ssd模型在预测阶段,通过直接预测真实框相对于先验框的偏移量,得到目标检测框,缺少了对预测框的修正过程,导致预测框不能准确定位行人。另外,现有的ssd中使用的损失函数缺少对遮挡行人的特殊处理。
技术实现要素:
本发明目的在于提供一种基于深度学习的行人检测模型构建方法及行人检测方法,以提高ssd模型在行人检测方面的性能。
实现本发明目的的技术方案为:一种基于深度学习的行人检测模型构建方法,包括以下步骤:
步骤a1,对行人数据集做预处理,然后利用特征提取网络,提取行人特征,生成特征图;
步骤a2,将特征图和先验框输入预测网络,生成预测框并作为新的先验框,然后将特征图和新的先验框输入预测网络,生成行人预测框;
步骤a3,利用行人数据集训练用于检测行人的深度卷积神经网络,并输出训练好的用于检测行人的深度卷积神经网络;所述深度卷积神经网络的损失由focalloss分类损失和具有吸引和排斥功能的定位损失组成。
一种基于深度学习的行人检测方法,包括如下步骤:
步骤b1,输入待检测行人图像;
步骤b2,利用步骤a2中训练好的特征提取网络提取待检测图像的特征,生成特征图,并通过a3训练好的预测网络生成检测框;
步骤b3,利用非极大值抑制策略对步骤b2中生成的检测框进行筛选,并输出行人检测结果。
与现有技术相比,本发明的显著优点为:(1)本发明采用resnet-50作为特征提取网络,并生成4个不同尺度的特征图,保证了模型既能检测到较大目标又能有效的发现小目标;(2)本发明采用两步预测的方式,第二次是在第一次预测框的基础上做预测,相当于增加了预测框的修正过程,使预测框定位更加准确;(3)针对行人间的密集遮挡问题,本发明使用giou损失替换smoothl1损失作为新的吸引项,并增加了辅助排斥损失项,能够更好的将遮挡率高的行人区分开来,减少了检测器的漏检和误检,提高了检测器的鲁棒性。
附图说明
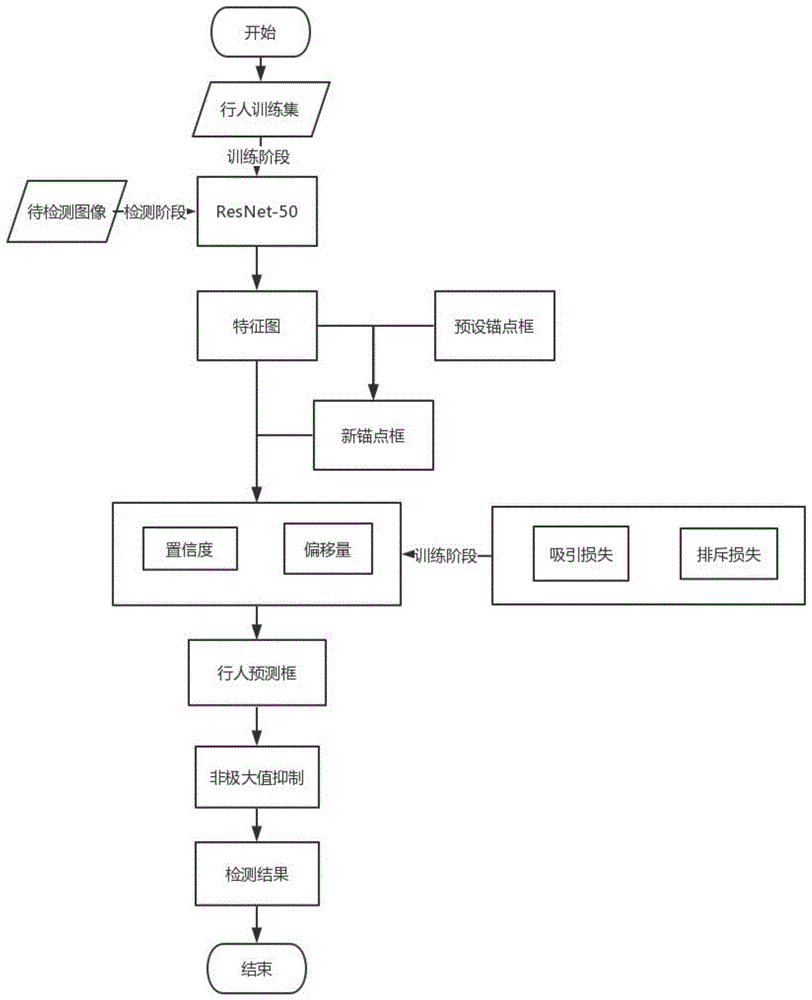
图1是基于深度学习的行人检测模型构建方法及行人检测方法流程图。
具体实施方式
本发明所提出的基于深度学习的行人检测模型构建方法及行人检测方法,主要包括将第一步预测的预测框作为新的先验框进行第二步预测、使用新的吸引项和排斥项替换smoothl1损失并训练ssd模型、使用ssd检测器完成行人检测三个主要部分。
下面结合附图,对本发明的一些示范性实施例加以说明。
一种基于深度学习的行人检测模型构建方法,以克服现有ssd的行人检测方法出现明显误检测的问题。结合图1,该方法包括以下3个步骤:
步骤a1,对行人数据集做预处理,然后利用特征提取网络,提取行人特征,生成特征图;
步骤a2,将特征图和先验框输入预测网络,生成预测框并作为新的先验框,然后将特征图和新的先验框输入预测网络,生成行人预测框;
步骤a3,利用行人数据集训练用于检测行人的深度卷积神经网络,并输出训练好的用于检测行人的深度卷积神经网络;所述深度卷积神经网络的损失由focalloss分类损失和具有吸引和排斥功能的定位损失组成。
优选的,所述预处理包括对行人标签的处理和数据增强两部分,其中对行人标签的处理是保留行人高度大于50像素的行人真实框,数据增强包括图像随机裁剪、图像翻转、调节图像亮度和图像扭曲。
优选的,在步骤a3中所述深度卷积神经网络由特征提取网络和预测网络两个子网络构成;
使用resnet-50网络作为特征提取网络的基础网络,在特征提取网络后面添加若干卷积层作为预测网络。
优选的,使用resnet-50网络中stage3、stage4和stage5的最后一层作为三个不同尺度的特征图,然后在它们后面分别加一个卷积层作为第四个特征图。另外,预测网络为,在特征提取网络的后面添加一个3*3的卷积层,然后附加两个1*1的分支卷积层。
优选的,利用特征提取网络,可以得到4种不同尺度的特征图,分辨率分别为80*160*512、40*80*1024、20*40*2048和10*20*2048。另外,利用预测网络可以得到预测框和每个预测框对应的分类置信度。
优选的,通过两步预测的方式,预测网络利用特征图和先验框生成预测框和分类置信度,其预测步骤具体为:首先,将特征图和预设的先验框输入预测网络,得到第一步预测的预测框,然后,将第一步预测得到的预测框作为新的先验框,并与特征图共同输入预测网络,得到第二步预测的预测框。
优选的,所述的先验框为预设的候选窗口,对于特征图的每一个位置,输出这个位置上4种尺度和4种长宽比的16个候选窗口。
优选的,所述深度卷积神经网络中的特征提取网络的输入为预处理后的行人数据集,预测网络的输入为特征图和先验框;其中预测网络中的特征图为经过特征提取网络从行人数据集中提取到的行人特征图。
所述深度卷积神经网络的损失函数,其构建方法具体为:使用focalloss作为分类损失,定位损失包括具有定位功能的吸引项和具有辅助定位功能的排斥项。
优选的,所述的吸引项能够使预测框尽可能接近真实框,所述的排斥项可以使预测框尽可能远离其它目标的真实框,进而有效减少遮挡造成的漏检。
优选的,吸引项使用giou损失函数,排斥项使用改进的repulsionloss损失函数:
其中
g和p分别表示真实框和预测框,g表示所有真实框,p+表示预测框中所有正样本,c表示g与p的最小闭包矩形,
本发明基于上述基于深度学习的行人检测模型构建方法,还提出了一种基于深度学习的行人检测方法,包括如下步骤:
步骤b1,输入待检测行人图像;
步骤b2,利用步骤a2中训练好的特征提取网络提取待检测图像的特征,生成特征图,并通过a3训练好的预测网络生成检测框;
步骤b3,利用非极大值抑制策略对步骤b2中生成的检测框进行筛选,并输出行人检测结果。
下面结合附图和实施例对本发明进行详细说明。
实施例
步骤c1,在citypersons训练集上训练本发明提出的模型;
步骤c2,以citypersons验证集作为输入,利用步骤c1中训练好的模型,生成行人检测框。
步骤c3,利用验证集的真实框和步骤c2输出的行人检测框评估模型的对数平均漏检率。
表1不同阈值下模型在citypersons验证集上的对数平均漏检率
如表1所示,交叠率阈值为0.5时,本发明提出的模型在验证集的reasonable子集上的对数平均漏检率为13.15%,而这一指标在原始的ssd上仅为16.41%,漏检率降低了3.26%。因此,本发明提出的模型能够跟有效的降低行人的漏检率。
综上所述,本发明提供基于深度学习的行人检测模型构建方法和行人检测方法。针对监控视频中的行人检测,由于行人尺度变化大和互相遮挡等原因,存在许多漏检、误检的问题,本发明在ssd模型的基础上引入了预测加修正的定位策略,并通过替换新的损失函数,在训练时使两个存在类内遮挡的行人的预测框尽可能远离,从而得到更加精确的行人检测器。具体包括:将第一步预测的预测框作为新的先验框进行第二步预测、使用新的吸引项和排斥项替换smoothl1损失并训练ssd模型、使用ssd检测器完成行人检测。利用本发明提出的方法,可以提高预测框的定位准确度,降低小目标的漏检率,减少由于类内遮挡造成的漏检和误检。
虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!