一种富媒体文件解析方法与流程
本发明涉及大数据处理技术领域,具体涉及一种富媒体文件解析方法。
背景技术:
随着互联网数据的日益增长,数据种类和数据容量正以前所未有的速度进行爆炸式增加。
对于普通企业和有关单位,常用的文件格式形如邮件数据、文档数据(包括office文档pdf文档等等)、网页数据、话单数据、资金数据、手机备份和勘验数据、电脑备份和勘验数据、以及数据库结构化数据(mysqloraclesqlserveraccessmongodbredis)等种类繁多,那么如何把这些数据综合存储、利用、分析,并进行常用业务的查询、数据挖掘,这是一个对技术水平要求很高的难题。
技术实现要素:
本发明提供了一种富媒体文件解析方法,解决如何将各种不同文件格式的数据综合存储、利用、分析,并进行常用业务的查询、数据挖掘。
为实现以上目的,本发明通过以下技术方案予以实现:
一种富媒体文件解析方法,其特征在于,包括:
对海量富媒体文件进行文件格式的筛选归类;
对筛选归类后的富媒体文件通过资源工厂分配需要处理的硬件资源以及相应文件格式所需要的数据解析接口;
采用spark并行计算框架,对分配后的各节点数据解析接口进行高并发的解析处理;
对解析处理后的结果进行多节点集群索引;
基于索引的查询接口,进行大数据的可视化分析。
根据本发明的另一实施方式,所述富媒体文件包括zip压缩包、rar压缩包、har压缩包、邮件的pst/ost压缩文件以及综合文档文件夹。
根据本发明的另一实施方式,所述对海量富媒体文件进行文件格式的筛选归类的步骤包括:
对海量的富媒体文件进行解压,使用遍历算法对文件进行多层解压缩提取;
通过内置的筛选分发引擎,对解压后的不同文件进行分拣,根据文件名称的后缀进行文件格式区分归类,并将其暂存在以不同数据格式命名的分类文件夹中。
根据本发明的另一实施方式,进行归类后的文件包括word文档、excel文档、ppt文档/pdf文档、图片文件、eml文件、手机备份/勘验数据以及硬盘备份/勘验数据。
根据本发明的另一实施方式,所述通过资源工厂分配需要处理的硬件资源以及相应文件格式所需要的数据解析接口的步骤包括:
根据不同数据格式的文件进行分配解析接口,当输入为word文档、excel文档、ppt文档、pdf文档时,资源工厂分配文档解析接口;当输入为eml文件、音频文件、视频文件时,资源工厂自动分配媒体文件解析接口;当输入文件为手机取证勘验、硬盘取证勘验时,分配取证勘验解析接口;
根据不同解析接口的数据大小分配不同的硬件资源,得到各个数据节点的硬件资源。
根据本发明的另一实施方式,所述采用spark并行计算框架,对分配后的各节点数据解析接口进行高并发的解析处理的步骤包括:
将各节点的硬件资源进行汇总到spark框架中。
通过spark计算框架将一个整体任务划分为若干个小的任务,根据单个任务执行需要分配的资源进行并发线程分配和计算,并对单个任务执行的结果进行汇总和持久化。
根据本发明的另一实施方式,所述对解析处理后的结果通过分布式全文索引技术进行多节点集群索引。
根据本发明的另一实施方式,所述大数据的可视化分析采用关系对象查询技术。
本发明提供了一种富媒体文件解析方法。具备以下有益效果:首先对海量富媒体文件数据筛选归类,将复杂结构数据筛选为相对规则的分类数据,从而可以对单个数据格式进行精确的格式处理。再通过资源工厂,自动分配需要处理的硬件资源和相应文件格式需要的数据解析接口;再通过使用spark并行计算,采用多线程、多并发的方式,最大限度提升解析速度;使用分布式全文索引技术,提升数据的安全性和整体查询速度。并且基于大数据可视化分析,给用户呈现直观、准确、高效的处理结果。
附图说明
为了更清楚地说明本发明或现有技术中的技术方案,下面将对现有技术描述中所需要使用的附图作简单地介绍。
图1是本发明的一种富媒体文件解析方法的一个实施例的流程示意图;
图2是本发明的一种富媒体文件解析方法的步骤100一个实施例的流程示意图;
图3是本发明的一种富媒体文件解析方法的步骤100的原理框图;
图4是本发明的一种富媒体文件解析方法的步骤200一个实施例的流程示意图;
图5是本发明的一种富媒体文件解析方法的步骤200的原理框图;
图6是本发明的一种富媒体文件解析方法的步骤300一个实施例的流程示意图;
图7是本发明的一种富媒体文件解析方法的步骤300的原理框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述。
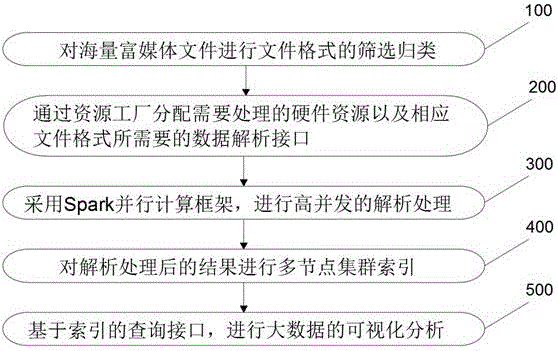
如图1所示,一种富媒体文件解析方法,包括:
步骤100:对海量富媒体文件进行文件格式的筛选归类;
步骤200:对筛选归类后的富媒体文件通过资源工厂分配需要处理的硬件资源以及相应文件格式所需要的数据解析接口;
步骤300:采用spark并行计算框架,对分配后的各节点数据解析接口进行高并发的解析处理;
步骤400:对解析处理后的结果进行多节点集群索引;
步骤500:基于索引的查询接口,进行大数据的可视化分析。
本发明实施例的富媒体文件解析方法首先对海量富媒体文件数据筛选归类,将复杂结构数据筛选为相对规则的分类数据。从而可以对单个数据格式进行精确的格式处理。再通过资源工厂,自动分配需要处理的硬件资源和相应文件格式需要的数据解析接口;再通过使用spark并行计算,采用多线程、多并发的方式,最大限度提升解析速度;使用分布式全文索引技术,提升数据的安全性和整体查询速度。并且基于大数据可视化分析,给用户呈现直观、准确、高效的处理结果。
可选地,本发明实施例中富媒体文件包括zip压缩包、rar压缩包、har压缩包、邮件的pst/ost压缩文件以及综合文档文件夹。
在一些实施例中,参见图2-3所示,本发明的富媒体文件解析方法的步骤100包括:
步骤101:对海量的富媒体文件进行解压,使用遍历算法对文件进行多层解压缩提取;并且将获取到的实体文件保存在分布式文件存储的临时目录中。
步骤102:通过内置的筛选分发引擎,对解压后的不同文件进行分拣,根据文件名称的后缀进行文件格式区分归类,并将其暂存在以不同数据格式命名的分类文件夹中,便于后续的解析操作。
在本步骤中,进行归类后的分类文件夹包括word文档、excel文档、ppt文档/pdf文档、图片文件、eml文件、手机备份/勘验数据以及硬盘备份/勘验数据。
在一些实施例中,参见图4-5所示,本发明的富媒体文件解析方法的步骤200包括:
步骤201:根据不同数据格式的文件进行分配解析接口;
在本步骤中,当输入为word文档、excel文档、ppt文档、pdf文档时,资源工厂分配文档解析接口;当输入为eml文件、音频文件、视频文件时,资源工厂自动分配媒体文件解析接口;当输入文件为手机取证勘验、硬盘取证勘验时,分配取证勘验解析接口;
步骤202:根据不同解析接口的数据大小分配不同的硬件资源,得到各个数据节点的硬件资源。例如平台系统的支持大小为10t每批次,当输入文件总大小为2t时,根据需要的硬件资源自动分配每节点8核、32g内存进行后续的解析处理;当输入文件总大小为10t时,根据解析需要自动分配32核、128g内存进行后续的解析处理。
在一些实施例中,参见图6-7所示,本发明的富媒体文件解析方法的步骤300包括:
步骤301:将各节点的硬件资源进行汇总。
在本实施例中,当每个节点采用32核cpu、128g内存进行配置,汇总后具备128核cpu、512g内存的硬件资源。由于解析过程直接使用内存进行计算,大大提高了解析效率,解决了数据落地和磁盘io问题。
步骤302:通过spark计算框架将一个整体任务划分为若干个小的任务,根据单个任务执行需要分配的资源进行并发线程分配和计算,并对单个任务执行的结果进行汇总和持久化。
在本实施例中,当单个任务执行需要4g内存和1核cpu进行计算,总体可以分配100多个线程进行并发计算,极大的提高了运行速度和执行效果。
优选地,本发明的富媒体文件解析方法的步骤400中,对解析处理后的结果通过分布式全文索引技术进行多节点集群索引。
由于分布式的全文索引不同于普通的数据库查询技术,专业为搜索引擎提供海量数据的查询操作,搜索速度达到毫秒级响应。通过数据分片把原始文件的内容拆分为基于lucene格式的索引文件,便于快速查找,也便于数据大小的压缩;
并且分布式全文索引技术将每个分片的数据存储为多个备份,散步在不同机架、不同节点的不同数据块上。有效的防止了数据磁盘损坏、机房意外故障导致的数据丢失问题。通过索引集群的健康值给用户一个直观的提示。
优选地,本发明的富媒体文件解析方法的步骤500中,大数据的可视化分析采用关系对象查询技术。
一方面,后端基于分布式全文索引技术的查询接口,保证了数据查询的响应时间,能够在短时间内批量请求大量的json数据。
另一方面,大数据可视化分析采用了关系对象查询技术。比如neo4j数据库查询接口,在一对一,多对一,多对多的关系查询中,可视化分析能够提供更准确、更高效、更快速的结果呈现。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!