一种基于深度自编码器的未知网络流量识别方法及系统与流程
本发明属于网络安全技术领域,涉及流量识别技术,特别涉及一种基于深度自编码器的未知网络流量识别方法及系统。
背景技术:
网络流量识别技术的目的是通过分析网络流量识别出哪些网络协议或应用运行在网络中,并建立网络数据流与产生其应用的映射关系。如何正确理解网络流量中的应用程序和协议是网络安全领域关注的核心问题之一,同时也是其他网络管理任务的工作基础,其典型应用场景包括网络监控、服务质量保证、入侵与防范系统(ids/ips)等。
但是随着网络的不断发展,网络中协议和应用的种类不断增加,流量识别正面临着一个新的挑战,即未知流量的识别问题。未知流量的概念是相对于现已构建好的流量识别系统而言的,是指未知应用程序(即零日应用程序)产出的网络流量,这部分流量未被现已构建好的识别系统所建模和识别。未知流量作为不可控制的数据,给网络管理带来了潜在的危险。internet2组织对北美主干网的网络流量统计表明,近50%的流量属于未知流量。然而,现有的未知流量识别技术不能有效的解决该问题,其局限性如下:
特征构建依赖专家经验,扩展性差。在构建未知流量识别系统时,输入数据为无标记网络流量,特征构建一般依赖专家经验,直接使用专家推荐特征表示数据,无法对特征进行有效的选择,得到低冗余和高相关的样本特征。
技术实现要素:
本发明技术解决问题:针对未知网络流量识别的问题,提供一种基于深度自编码器的未知网络流量识别方法及系统,能够对混合网络流量进行聚类分析,形成纯净的未知网络流量簇,有效解决了未知网络流量识别问题;同时实现网络流量的特征提取无需依赖特征工程,即能够在无监督的条件下自动完成特征提取。
本发明技术解决方案:一种基于深度自编码器的未知网络流量识别方法,包括以下步骤:
步骤1,特征提取:输入网络中现有方法无法识别的数据包,首先采用n元模型n-gram嵌入方法对输入的每个数据包中负载的前m个字节进行切割,得到m-n+1个长度为n个字节的载荷字符串,通过设置n-gram模型中参数n,构建不同长度的载荷字符串,得到同一数据包的多个维度的特征集合,然后使用m-n+1个载荷字符串构建数据包特征集,最后将数据包特征集的载荷字符串嵌入(embedding)到数值向量空间,完成载荷字符串数据到数值型数据转换,将n-gram模型每个参数n的m-n+1个特征向量拼接,构建不同维度的数据包特征向量;
步骤2,特征构建:基于步骤1得到的不同维度的数据包特征向量,实现数据包特征向量的降维和关键特征提取,采用深度自编码器算法训练数据包特征向量,生成基于深度自编码器算法的数据包特征向量的降维和关键特征提取模型,使用该模型实现对于不同维度特征向量的无监督特征提取,得到数据包不同维度特征向量,然后将得到的数据包不同维度特征向量进行拼接,得到优化的网络数据包特征向量;
步骤3,未知流量识别:根据步骤2得到的优化的网络数据包特征向量,基于k-means算法对未知网络流量进行聚类分析,构建未知网络流量识别模型,并采用该模型对实时的网络流量进行监测,当训练数据中的未知流量在实时的网络中再次出现时,该模型对实时网络中的未知流量进行识别,最终得到未知流量识别结果。
所述步骤1特征构建,具体步骤为:
(11)以网络中数据包为最小单元,提取数据包中前m个字节的负载信息作为原始数据;
(12)使用n-gram嵌入方法对输入的每个数据包中负载的前m个字节进行切割,设置n-gram模型的参数n∈{1,2};
(13)针对每个参数n,为每个数据包构造m-n+1个特征字符串;
(14)针对每个参数n构造的m-n+1个特征字符串,通过自然语言处理中字典查找的方法将特征向量化,得到特征字符串的特征向量;
(15)将n-gram模型每个参数n的m-n+1个特征向量拼接,构建不同维度的数据包特征向量。
所述步骤2特征提取,具体步骤为:
(21)以特征向量为输入数据,基于自动编码器算法,训练一个自动编码器,以x表示自编码器输入,r表示自编码器输出,自编码器通过内部表示或编码,将输入x映射到r,自编码器有一个隐藏层h、一个由函数h=f(x)表示的编码器f,和一个由函数r=g(h)表示的解码器g组成,编码器f将输入x映射到h,解码器g将h映射到r;
(22)保存步骤(1)训练获得的自动编码器的隐藏层h数据,以该数据作为输入,迭代训练下一个自动编码器;
(23)重复步骤(2),以第t个自动编码器的隐藏层数据ht训练t+1个自动编码器,得到多个自动编码器;
(24)最后训练获得一个隐藏层单元数为2的自动编码器;
(25)在获得一个隐藏层单元数为2的自动编码之后,将所有自动编码器的编码层f按照训练顺序串联,将隐藏层单元数为2的自动编码器放在最后,并按照逆向训练顺序连接解码层,形成一个深度自动编码器;
(26)最后放弃连接的解码层部分,使用连接的编码层作为在原始特征空间和目的特征空间之间的映射,提取每个数据包基于不同参数n的特征向量;
(27)将提取到的基于不同参数n的特征向量拼接,得到优化的网络数据包特征向量。
本发明的一种基于深度自编码器的未知网络流量识别系统,如图2所示,包括特征构建模块、特征提取模块以及未知流量聚类模块;
特征构建模块:以网络中现有方法无法识别的数据包作为原始输入,使用n-gram嵌入方法对输入的每个数据包中负载的前m个字节进行切割,得到m-n+1个长度为n个字节的载荷字符串,通过设置n-gram模型中参数n,构建不同长度的载荷字符串,得到同一数据包的多个维度的特征集合,然后使用m-n+1个载荷字符串构建数据包特征集,最后将数据包特征集的载荷字符串嵌入(embedding)到数值向量空间,完成载荷字符串数据到数值型数据转换,将n-gram模型每个参数n的m-n+1个特征向量拼接,构建不同维度的数据包特征向量;
特征提取模块:以特征构建模块构建的不同维度的数据包特征向量作为输入,采用深度自编码器算法训练数据包特征向量,生成基于深度自编码器算法的数据包特征向量的降维和关键特征提取模型,使用该模型实现对于不同维度特征向量的无监督特征提取,得到数据包不同维度特征向量,然后将得到的数据包不同维度特征向量进行拼接,得到优化的网络数据包特征向量;
未知流量识别模块:以特征提取模块获得的优化的网络数据包特征向量作为输入,基于k-means算法,构建流量聚类模型,并采用该模型对实时的网络流量进行监测,当训练数据中的未知流量在实时的网络中再次出现时,该模型对实时网络中的未知流量进行识别,最终得到未知流量识别结果。
本发明与现有技术相比,
(1)本发明的方法,在无监督的条件下,完成对网络流量特征的特征提取,实现以网络数据包为最小单位的网络未知流量的识别,且具有较高的识别效率和识别准确率。
(2)本发明以原始网络数据流为输入,首先利用n-gram嵌入对数据负载进行向量化处理,然后利用深度自编码器对特征向量进行提取和选择,最后通过聚类方法,从混合流量中得到未知流量的簇。该方法只需要使用数据包中前m个字节的负载信息,在实现识别功能的前提下尽量保证用户隐私,且该方法不需要依赖任何的先验知识,不需要人工提取特征,节省人力物力。除此之外,该方法可以处理面向连接(tcp)和无连接(udp)的协议或应用,同时也支持文本协议和二进制协议。
附图说明
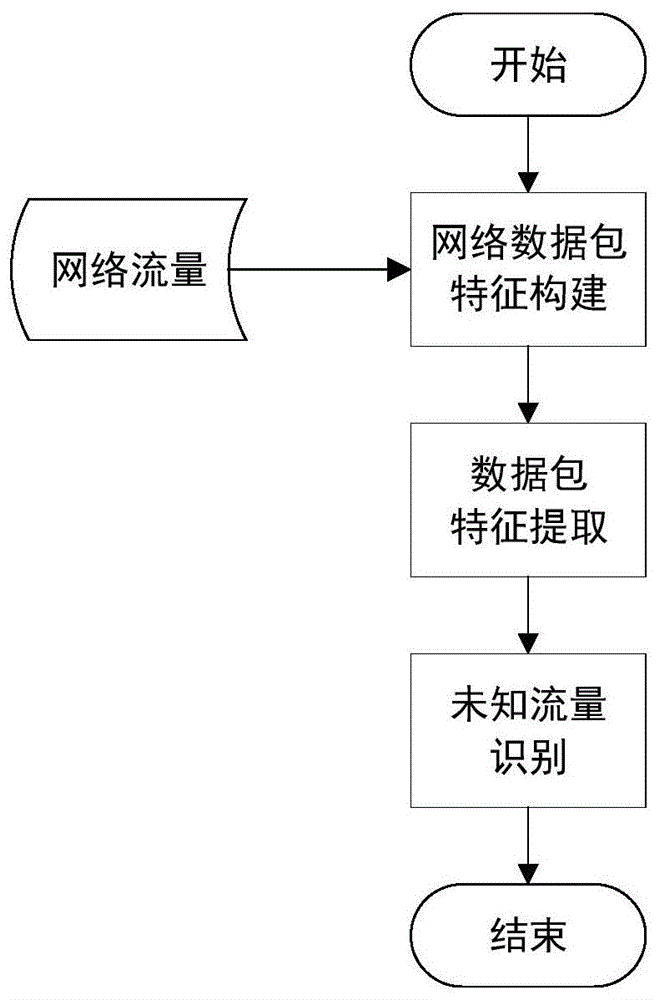
图1为本发明的深度自编码器的网络未知流量识别方法的实现流程图;
图2为本发明的深度自编码器的网络未知流量识别系统架构图。
具体实施方式
下面结合附图及实施例对本发明进行详细说明。
如图1所示,本发明基于深度自编码器的未知网络流量识别方法主要有三个核心阶段:未知网络流量特征构建、特征提取和未知流量识别。
一、未知网络流量特征构建包含以下步骤:
(1)以网络中数据包为最小单元,提取数据包中前m个字节的负载信息作为原始数据;
(2)使用n-gram嵌入方法对输入的每个数据包中负载的前m个字节进行切割,设置n-gram模型的参数n∈{1,2};
(3)针对每个参数n,为每个数据包构造m-n+1个特征字符串;
(4)针对每个参数n构造的m-n+1个特征字符串,通过自然语言处理中字典查找的方法将特征向量化,得到特征字符串的特征向量;
(5)将n-gram模型每个参数n的m-n+1个特征向量拼接,构建不同维度的数据包特征向量。
二、特征提取包含以下步骤:
(1)以特征向量为输入数据,基于自动编码器算法,训练一个自动编码器,以x表示自编码器输入,r表示自编码器输出,自编码器通过内部表示或编码,将输入x映射到r,自编码器有一个隐藏层h、一个由函数h=f(x)表示的编码器f,和一个由函数r=g(h)表示的解码器g组成,编码器f将输入x映射到h,解码器g将h映射到r;
(2)保存步骤(1)训练获得的自动编码器的隐藏层h数据,以该数据作为输入,迭代训练下一个自动编码器;
(3)重复步骤(2),以第t个自动编码器的隐藏层数据ht训练t+1个自动编码器,得到多个自动编码器;
(4)最后训练获得一个隐藏层单元数为2的自动编码器;
(5)在获得一个隐藏层单元数为2的自动编码之后,将所有自动编码器的编码层f按照训练顺序串联,将隐藏层单元数为2的自动编码器放在最后,并按照逆向训练顺序连接解码层,形成一个深度自动编码器;
(6)最后放弃连接的解码层部分,使用连接的编码层作为在原始特征空间和目的特征空间之间的映射,提取每个数据包基于不同参数n的特征向量。
(7)将提取到的基于不同参数n的特征向量拼接,得到优化的网络数据包特征向量。
三、未知流量识别包含以下步骤:
(1)以优化的网络数据包特征向量为输入数据,基于k-means算法,对未知网络流量进行聚类分析,构建未知网络流量识别模型;
(2)采用未知网络流量识别模型对实时的网络流量进行监测,当训练数据中的未知流量在实时的网络中再次出现时,该模型可对实时网络中的未知流量进行识别,最终得到未知流量识别结果。
结合上述基于深度自编码器的未知网络流量识别方法,本发明同时公开了一种基于深度自编码器的未知网络流量识别系统,主要由特征构建模块、特征提取模块以及未知流量聚类和识别模块三部分构成,其框架图如图2所示:
特征构建模块:以网络中现有方法无法识别的数据包作为原始输入,使用n-gram嵌入方法对输入的每个数据包中负载的前m个字节进行切割,得到m-n+1个长度为n个字节的载荷字符串,通过设置n-gram模型中参数n,构建不同长度的载荷字符串,得到同一数据包的多个维度的特征集合,然后使用m-n+1个载荷字符串构建数据包特征集,最后将数据包特征集的载荷字符串嵌入(embedding)到数值向量空间,完成载荷字符串数据到数值型数据转换,将n-gram模型每个参数n的m-n+1个特征向量拼接,构建不同维度的数据包特征向量;
特征提取模块:以特征构建模块构建的不同维度的数据包特征向量作为输入,采用深度自编码器算法训练数据包特征向量,生成基于深度自编码器算法的数据包特征向量的降维和关键特征提取模型,使用该模型实现对于不同维度特征向量的无监督特征提取,得到数据包不同维度特征向量,然后将得到的数据包不同维度特征向量进行拼接,得到优化的网络数据包特征向量;
未知流量识别模块:以特征提取模块获得的优化的网络数据包特征向量作为输入,基于k-means算法,构建流量聚类模型,并采用该模型对实时的网络流量进行监测,当训练数据中的未知流量在实时的网络中再次出现时,该模型可对实时网络中的未知流量进行识别,最终得到未知流量识别结果。
实验验证
为了证明方法的有效性,本发明在大量的真实数据上进行了反复的实验。在实验中,本发明首先抓取骨干网的数据流并使用ndpi工具对数据进行标定,并选取其中的八个典型的应用层协议,包括dns、dhcp、bittorrent、ssh、http、imap、mysql和github,模拟网络未知流量来评估本发明的方法。实验的实施步骤包括数据集的构建和标注、实验评估指标和实验结果评估三个模块。
(1)数据集的构建和标注:本发明基于零拷贝方法,于2015年8月17日上午1点至下午12点,在中国大陆某校园网络的路由器捕获20gb网络流量数据。为了保证用户隐私,在数据集中,每个数据包仅包含30个字节的应用层负载。在这项工作中,通过使用开源ndpi工具和基于端口的方法,构建包含多个协议的标记样本。实验数据集中包含八个典型的应用层协议,包括dns、dhcp、bittorrent、ssh、http、imap、mysql和github。注意,这些目标协议包括无连接协议(udp)和面向连接的协议(tcp)。同时,数据集中的协议包含文本协议和二进制协议。在实验中,使用八类协议的网络数据模拟混合的未知流量数据,对实验方法进行测试。
(2)实验评估指标:
为了评估方法的有效性,本发明将聚类纯度作为评价指标。聚类纯度定义为每个簇中优势类标签的平均百分比。聚类纯度的定义如下所示:
(3)实验结果评估:在实践过程中,不同的参数组合都可以产生较好的实验效果。因此,在实验中通过控制不同的变量,例如每层的单元数,隐藏层数和聚类簇数等,得到不同的实验结果。
表1网络未知流量聚类结果
表1为未知网络流量的聚类结果。该表显示了在选择不同包有效载荷长度、嵌入尺寸的实验结果,实验样本约为105000个数据包,batch为64,迭代次数为1600次。深度自编码器的拓扑结构共有9层,结构为:((m-n+1)×e)-100-100-200-8-200-100-100-((m-n+1)×e),其中m表示数据包中前m个字节的负载信息,n为n-gram模型参数,e表示词嵌入的目标向量的维数。该深度神经网络所有的连接数超过100000个。此外,采用0.01的学习率,并采用100次重复实验的平均结果,以确保结果的可靠性。此外,由于该方法对聚类簇值敏感,所以选择的参数k在10到100之间,k={10,20,…,50,60,…,100}。从表中可以观察到,该方法在聚类纯度上可以达到97.35%以上。此外,当聚类数(k=10)接近未知协议数(实验数据中协议类别数为8种)时,该方法依然可以获得较高的聚类纯度。
本发明能够对混合网络流量进行聚类分析,形成纯净的未知网络流量簇,有效解决了未知网络流量识别问题;实现网络流量的特征提取无需依赖特征工程,即能够在无监督的条件下自动完成特征提取。
以上虽然描述了本发明的具体实施方法,但是本领域的技术人员应当理解,这些仅是举例说明,在不背离本发明原理和实现的前提下,可以对这些实施方案做出多种变更或修改,因此,本发明的保护范围由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!