面向医院医保限额分配的数据交互系统及方法与流程
本公开涉及医保限额分配
技术领域:
,特别是涉及面向医院医保限额分配的数据交互系统及方法。
背景技术:
:本部分的陈述仅仅是提到了与本公开相关的
背景技术:
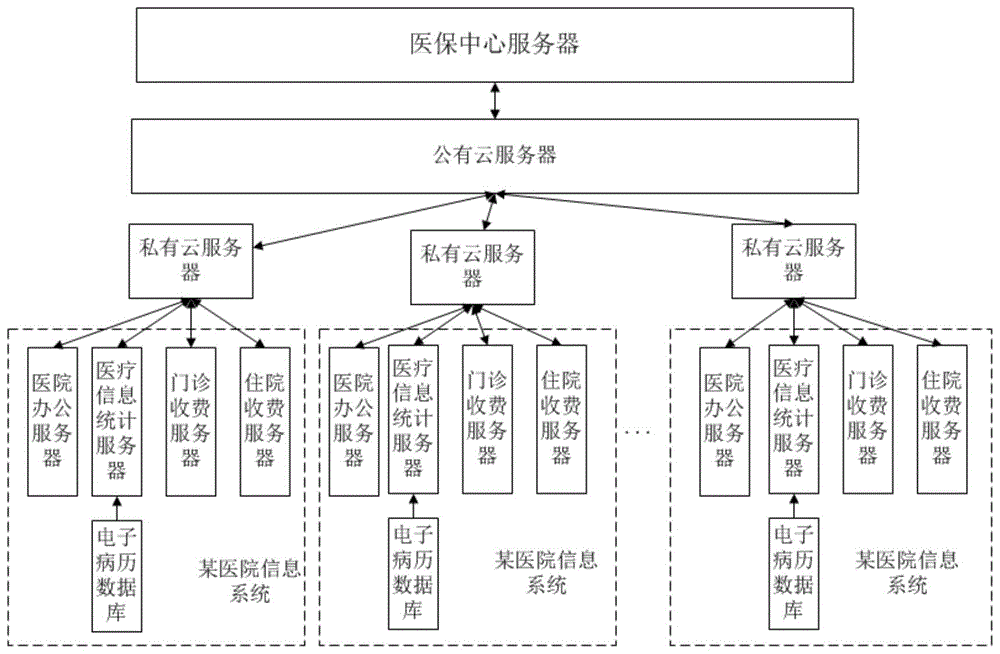
,并不必然构成现有技术。医疗保险是为了补偿劳动者因疾病风险造成的经济损失而建立的一项社会保险制度。近年来,随着全民医保的普及和不断完善,医疗费用也走上了增长的快车道,医保基金也因此面临越来越大的支付压力。因此,医疗保险必须控制医疗费用过快增长,维护医保基金的收支平衡,保障医保制度的安全和可持续。而总额控制就是控制医疗费用过快增长的基础性管理和支付工具。医疗保险总额控制本质上是医保基金的预算管理和约束,也就是根据医保基金收入预算来分配可用的基金,使得基金收支保持预算平衡。然而,总额控制有其自身的弊端和缺点,主要问题是总额控制标准设置不合理,而且也没有考虑到各定点医疗机构的实际情况。因此如何准确预测医院的医疗总额,为医保机构实行总额控制提供参考,具有重要意义。目前,预测医院费用总额问题可以看作是一个时间序列分析问题,传统的时间序列分析方法都是通过模拟序列本身的趋势性和周期性来预测未来的发展。随着计算性能的不断提高,深度神经网络在数据处理和机器翻译等许多领域的成功,为时间序列预测任务提供了新的契机。其中,递归神经网络(recurrentneuralnetworks,rnns)能够对时间模式进行深度非线性建模。为避免梯度爆炸并延长短时预测,长短期记忆(long-shorttermmemory,lstm)和门控循环单元(gatedrecurrentunit,gru),作为其变体,在时序序列预测方面展现出优越性能,而后者在更小更简单的数据集上仍可良好拟合数据时序规律。然而,在实际的医院费用预测的过程中,发明人发现就医序列中的极端事件的发生对医院费用总额的预测也是有影响的。极端事件(如2003年非典疫情)的发生,虽然是小概率事件,但往往占赔付金额的比重较高。医保基金需考虑该类事件的临时赔付金额剧增,故亟需基于当前医保基金预测的基础上,通过捕获数据分布规律的相似性,加强对极端事件的预测,提高模型预测的精准度,保障医保基金储备的合理性。在实现本公开的过程中,发明人发现现有技术中存在以下技术问题:目前各医院的医保限额分配不均,缺乏对各个医院的自身就诊量的考虑,而且医保中心服务器与各家医院信息系统之间没有有效的数据交互,医保中心服务器对各家医院信息系统的数据采集数量庞大的时候会严重影响各家医院信息系统自身工作的性能,医保中心服务器对各家医院信息系统的错时采集又会降低数据采集的时间准确度,医保中心服务器对各家医院信息系统的重复采集会使医保中心服务器收集到的数据存在冗余,而且各家医院信息系统同时往医保中心服务器上传数据量过大,会给医保中心服务器带来数据存储和计算的压力,也会影响医保中心服务器计算的速度,进一步影响各家医院信息系统对医保中心服务器的服务体验。技术实现要素:为了解决现有技术的不足,本公开提供了面向医院医保限额分配的数据交互系统及方法;第一方面,本公开提供了面向医院医保限额分配的数据交互系统;面向医院医保限额分配的数据交互系统,包括:医保中心服务器,所述医保中心服务器与公有云服务器进行通信,所述公有云服务器与若干个私有云服务器进行通行,每个私有云服务器与对应的医院信息系统进行通信;所述医院信息系统,包括:医院办公服务器、医疗信息统计服务器、门诊收费服务器和住院收费服务器,其中,医院办公服务器、医疗信息统计服务器、门诊收费服务器和住院收费服务器均与对应的私有云服务器进行通信;所述医疗信息统计服务器还与电子病历数据库进行连接;某个医院信息系统的医院办公服务器将包含医院唯一编码的医保限额分配请求发送给对应的私有云服务器,私有云服务器将所述医保限额分配请求上传给公有云服务器,公有云服器将所述医保限额分配请求发送给医保中心服务器;医保中心服务器根据医保限额分配请求,对当前医院的社保限额分配额度进行计算,将计算得到的医保限额分配额度依次通过公有云服务器和私有云服务器发送给对应的医院办公服务器。第二方面,本公开还提供了面向医院医保限额分配的数据交互方法;面向医院医保限额分配的数据交互方法,包括:某个医院信息系统的医院办公服务器将包含医院唯一编码的医保限额分配请求发送给对应的私有云服务器,私有云服务器将所述医保限额分配请求上传给公有云服务器,公有云服器将所述医保限额分配请求发送给医保中心服务器;医保中心服务器根据医保限额分配请求,对当前医院的社保限额分配额度进行计算,将计算得到的医保限额分配额度依次通过公有云服务器和私有云服务器发送给对应的医院办公服务器。与现有技术相比,本公开的有益效果是:1、根据各个医院的自身实际就诊量和历史最相似时间序列的就诊量,实现各医院的医保限额按需分配,而且医保中心服务器与各家医院信息系统之间通过公有云服务器和私有云服务器实现有效的数据交互,医保中心服务器对各家医院信息系统的数据采集,不是直接采集,而是通过公有云服务器和私有云服务器进行过度,不会影响各家医院信息系统自身工作的性能,医保中心服务器对各家医院信息系统的采集通过云服务器来实现,提升了数据采集的时间准确度,而且有效避免了重复采集,而且各家医院信息系统同时往医保中心服务器上传数据量暂存在私有云服务器,私有云服务器会上传给公有云服务器,由公有云服务器再上传给医保中心服务器,不会给医保中心服务器带来数据存储和计算的压力,也不会影响医保中心服务器计算的速度,不会影响各家医院信息系统对医保中心服务器的服务体验。2、该模型首先采用f检验方法分析出影响医院费用的因素集合。考虑到极端事件对医院费用序列预测的影响,本实施例提出一个相似性快速搜索算法(similarityfastsearch,sfs),并通过定义时间窗口从历史时间序列中找到与现在相似的时间序列,模拟相似时序的变化趋势,从而判读未来是否发生极端事件。如不存在相似性序列,本实施例采用记忆网络的神经结构来记忆历史的极端事,并采用一种新的极值损失函数(extremevalueloss,evl),从而实现对未来极端事件的预测。最后将基础特征和未来是否存在极端事件作为输入,通过lstm实现医院费用预测。3、本公开以历史医保数据为基础,考虑到极端事件的发生对医院费用预测的影响,采用相似性快速搜索(sfs)算法,并定义时间窗口,通过迭代优化求解的方式从历史时间序列中找到与现在相似的时间序列,模拟相似时序的变化趋势,从而判读未来是否发生极端事件;对未从历史序列中找到相似序列的情况,采用记忆网络的神经结构来记忆历史的极端事件,并采用拟合极端事件趋势的交叉熵算法形成新的极值损失函数(evl),从而实现对未来极端事件的预测;4、模型可以在预测的正常值和极端值之间进行灵活切换。当当前时间序列段与历史中的某些极端事件之间存在相似性时,则通过设置历史相似序列来检测该类极端事件发生的极值点;当当前时间序列与历史序列几乎没有任何关系时,为了更好的拟合极端事件发生的概率,采用evl作为损失函数,从而提高对极端事件发生规律的拟合,推测出可靠的极端事件类型和预估时间,即gru基于历史记录给出的预测值。同时,该模型仍采用交叉熵作为损失函数,满足对一般事件规律的拟合性。附图说明构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。图1为第一个实施例的服务器连接示意图;图2为第一个实施例的提供的医院费用预测方法的整体流程图;图3为第一个实施例的基于f检验方法的影响医院费用的基础特征提取流程图;图4为第一个实施例的基于相似性匹配的极端事件预测的处理过程图;图5为第一个实施例的基于极端事件的医院费用预测的处理流程图;图6为第一个实施例的sfs算法相似性序列匹配效果示意图。具体实施方式应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本实施例使用的所有技术和科学术语具有与本申请所属
技术领域:
的普通技术人员通常理解的相同含义。需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。实施例一,本实施例提供了面向医院医保限额分配的数据交互系统;如图1所示,面向医院医保限额分配的数据交互系统,包括:医保中心服务器,所述医保中心服务器与公有云服务器进行通信,所述公有云服务器与若干个私有云服务器进行通行,每个私有云服务器与对应的医院信息系统进行通信;所述医院信息系统,包括:医院办公服务器、医疗信息统计服务器、门诊收费服务器和住院收费服务器,其中,医院办公服务器、医疗信息统计服务器、门诊收费服务器和住院收费服务器均与对应的私有云服务器进行通信;所述医疗信息统计服务器还与电子病历数据库进行连接;某个医院信息系统的医院办公服务器将包含医院唯一编码的医保限额分配请求发送给对应的私有云服务器,私有云服务器将所述医保限额分配请求上传给公有云服务器,公有云服器将所述医保限额分配请求发送给医保中心服务器;医保中心服务器根据医保限额分配请求,对当前医院的社保限额分配额度进行计算,将计算得到的医保限额分配额度依次通过公有云服务器和私有云服务器发送给对应的医院办公服务器。进一步地,所述医保中心服务器根据医保限额分配请求,对当前医院的社保限额分配额度进行计算,具体包括:所述医保中心服务器根据医保限额分配请求中包含的医院唯一编码,从公有云服务器中获取存储的医院数据;根据医院数据中的所有就诊患者的身份证号获取就诊患者的医保数据;根据医院数据和医保数据,对当前医院的社保限额分配额度进行计算。应理解的,所述医院数据,包括:医院级别、每天门诊的病人数量,每天住院的病人数量、住院天数、每个月份医院收费最高总额、住院总人数、医疗项目类型、参保人就医总费用、住院次数和外地患者就医占比。应理解的,所述医保数据,包括:参保人的年龄、性别、经济收入、参保类别、参保地、疾病类别、距离医院的距离、行业类别。进一步地,如图2和图5所示,根据医院数据和医保数据,对当前医院的社保限额分配额度进行计算;具体包括:s11:数据预处理,包括对医院数据和医保数据,进行的数据清洗、缺失值补全、去重处理和数据归一化处理;s12:利用f检验算法,从预处理后的数据进行特征提取,筛选出与医院费用之间相关性高于设定阈值的基础特征;s13:基于时间序列相似性搜索算法,将待计算医院的基础特征的时间序列与该医院同一个基础特征的历史时间序列进行相似性匹配,匹配出最相似的子时间序列;进而获取最相似子时间序列对应的基础特征;如果没有匹配出最相似的子时间序列,则将待计算医院的基础特征的时间序列输入到预训练的gru神经网络中,输出预测的子时间序列;进而获取预测的子时间序列对应的基础特征;s14:将s12获取的基础特征与s13获取的基础特征进行合并,获得综合特征向量;s15:将综合特征向量输入到预训练的lstm模型中,输出待预测医院的预测费用。应理解的,所述s11中,基于某市某地区的社保系统获取就医历史数据为应用实例,并分别从地区内部就医和地区外部就医两个方面进行讨论。将该地区2013-2017年历史就医数据作为训练样本,将2018年数据作为实验样本,如表1所示,为历史就医数据集统计示例,其中医院级别的数值越大,表明该医院治疗疾病的水平更高。表1就医数据集的基本统计信息搜集某市某地区的2013年~2017年的参保人员样本分别从参保人和医院两个方面研究影响医院费用的因素,得出如下主要因素:年龄、性别、参保类别、经济收入、疾病类别、医院级别、住院总人数、住院次数、总金额、迁移占比,获取海量医保数据中可能影响医院费用的部分因素集如表2所示:表2.医保数据中可能影响医院费用的部分因素集应理解的,所述s12中,基于f检验方法进行影响就医因素的特征选择,消除特征的冗余并提取与影响医院费用相关的特征。其中,对获取的数据进行数据预处理,包含缺失值处理、数据归一化,并采用卡方检验进行简单的相关性分析,消除重复影响因素及因子选择的任意性,降低问题的复杂性,从而消除特征的冗余并选择更多信息变量以提高预测模型的准确率和效率。针对获取的医保数据样本,基于f检验方法进行影响就医因素的特征选择,消除特征的冗余并提取与医院费用高关联度的特征,在就医过程中,筛选特征与医院费用之间的相关统计量随着时间的变化而改变,如住院总人数、疾病类别、住院次数对影响医院费用的程度更大,利用f检验法计算2016年部分筛选特征与医院费用之间的相关统计量如表3所示。表3.2016年部分医院费用的筛选特征及相关统计量影响因素权重值住院总人数0.8998疾病类别0.8884住院次数0.8577累积金额0.8373住院天数0.8109年龄0.7859迁移占比0.7233性别0.6845月份最高金额0.6710距离0.5233行业类别0.4806参保地点0.4677进一步地,如图3所示,所述s12中,利用f检验算法,从预处理后的数据进行特征提取,提取出与医院费用之间相关性高于设定阈值的特征;具体步骤包括:s121:定义医保数据中所有的就医类别编码为c1,c2,…,cc,…,c|c|∈c,其中|c|为就医类别编码的数量,假设有n个患者样本数据,第n个患者样本数据有t(n)条就医记录,则一个患者样本数据可由就医序列表示为每个就医记录包含一组特征向量x∈r|c|;s122:对就医样本数据进行规范化处理,采用min-max标准化方法对原始医保数据x进行归一化处理,特征数据取值为[0,1];s123:假设原样本中各个特征就医数据经均值化变化后的序列为:x0=(x0(1),x0(2),……,x0(n)),医院费用序列为:xk=(xk(1),xk(2),……,xk(n)),其中,i=1,2,…..,m;则x0与xk的均值计算公式如下:式中,和分别表示各个特征序列和医院费用序列的均值。s124:基于各个特征序列和医院费用序列的均值和求得序列的方差,计算公式如下:s125:各个特征序列和医院费用序列的方差和求得相关系数w,计算公式如下:最后通过设定阈值,筛选出大于阈值的特征及其对应的特征权重向量w。进一步地,所述s13中,基于时间序列相似性搜索算法,将待计算医院的基础特征的时间序列与该医院同一个基础特征的历史时间序列进行相似性匹配,匹配出最相似的子时间序列;具体步骤包括:基于筛选的影响医院费用的基础特征,采用相似性快速搜索算法(similarityfastsearch,sfs),匹配到相似的时间序列:首先,截取当前时间点的最小时间窗口匹配序列;然后,把历史数据序列用作被匹配序列从历史序列中找到与最小匹配序列最相似的子序列;然后,使用最相似的子序列作为匹配序列,并将最小时间窗口截取的时间序列作为被匹配序列;最后,不断增加当前时间点的时间窗口的宽度,直到找到对应于匹配序列的最合适的时间窗口;通过不断转换匹配序列和被匹配序列的角色,直到最相似的子序列不再更改,即匹配出最相似的子时间序列。定义sfs算法中变量,如表4所示:表4sfs算法的变量描述变量描述{xt}医院费用的序列数据t时间窗口的增长阈值d最小时间窗口series当前点截取的匹配序列iseries历史相似序列mindis匹配序列和被匹配序列的最短距离mseries最合适时间窗口截取的时间序列(匹配序列)miseries历史数据中最相似的时间序列(被匹配序列)本实施例匹配的时间序列变化规律上的相似性,为防止数据在大小上差异的影响,本实施例在动态时间归整算法(dynamictimewarping,dtw)中加入了归一化。相较于其他寻优算法,sfs需要同时找到最合适的截取段和最匹配的序列,且搜索速度明显优于其他算法。虽不能保证求到最优解,但是即使没有找到最优解,也能找到近似最优解。sfs算法过程如下:s13a1:设置时间序列series={x1,…,xn},miseries={x1,…,xm},其中n和m分别表示序列的长度;则序列series和miseries之间的最短距离被定义为:其中,wk表示序列中第k个值;max(n,m)≤k≤n+m-1;s13a2:为了找到序列之间的最佳匹配,检索了一条通过矩阵的路径,该路径使它们之间的总距离最小,评估公式γ(i,j)如下:γ(i,j)=dist(seriesi,miseriesj)+min{γ(i-1,j-1),γ(i,j-1)}(7)其中,dist(seriesi,miseriesj)=(seriesi-miseriesj)2表示的是序列series中第i个值和miseries中第j个值之间的距离;mseries、miseries和mindis是待计算的结果;最短序列(最匹配序列)的匹配过程,通过不断迭代求解,不断转换匹配序列和被匹配系列的角色,直到相似的子序列不再更改;s13a3:假设匹配序列mseries={xm,…,xt-1},其中1≤m≤t-1≤n;被匹配序列miseries={x1,…,xn},mseries和miseries的比例r表示为:其中,average(mseries)表示mseries中各个值的平均值;average(miseries)表示miseries中各个值的平均值;则t时间的测算值x′t可表示为:x′t=r×xn+1(9)其中r表示的是匹配序列mseries和被匹配序列miseries的比例;xn+1表示序列miseries中第n+1个值;x′t的值与两序列的相似程度有关,x′t是t时间点通过模拟相似序列对未来极端事件的预测值。极端事件,例如重症急性呼吸综合征(sars)。根据sfs算法找到历史的数据中与现在最相似的时序miseries和最合适的截取段mseries。由于miseries是从历史数据中截取的子序列,其后续的值是已知的。mseries与miseries的变化规律具有相似性,因此mseries后续值与miseries后续已知值也变化相似,故通过miseries后续已知值的变化推算出mseries的后续值。由于两个序列在变化规律上的相似,所以两个序列主要是长度和数据大小上的差异。本实施例研究的序列变化规律,通过模拟序列趋势来预测未来,匹配序列和相似序列之间长度的差异并不会产生影响。通过miseries与mseries之间数据大小上的差异,延伸到两序列的后续值,测算出mseries后续值的大小。为了验证本实施例提出的sfs算法的性能,将sfs算法与一种子序列时间转换矩阵算法(subsequencetimewarpingmatrix,stwm)算法进行比较。如图6所示,纵轴表示匹配序列与被匹配序列的距离,横轴表示迭代次数。基于图6中的结果可得,本实施例所提出的sfs收敛速度比stwm快且最终结果一样。这表明sfs可以快速找到相似的序列。应理解的,所述待计算医院的基础特征的时间序列输入到预训练的gru神经网络中,输出预测的子时间序列;具体步骤包括:s13b1:首先,在时间序列的上下文中定义窗口w的概念。对于每一个时间步骤t,首先通过w={w1,…,wm},其中m是gru神经网络的大小。对于每个窗口wj被定义为其中δ表示窗口的大小,并满足0<tj<t-δ;应用gru神经网络模块将每个窗口嵌入到特征空间中。具体,使用wj作为输入,并将最后的隐藏状态视为该窗口的潜在表示,表示为:其中r表示的实体数据集,m表示gru神经网络的大小;同时,应用一个gru神经网络模块来记忆对于每个窗口wj在tj+δ+1内是否存在极端事件。总之,在每个时间t,的gru神经网络模块提出的架构由以下两部分组成:·sj:是历史窗口j的特征表示。·是在窗口j之后是否存在极端事件的标签。s13b2:在每个时间步t,使用gru神经网络模块来产生输出值其中ht=gru([x1,x2,…,xt])表示表示每个时间步t时刻的隐藏状态值,表示权重矩阵,bo为偏置矩阵,并且sj分享相同的gru单元。由于的预测可能缺少在未来识别极端事件的能力。因此,本专利引入注意力机制,通过注意力权值atj来度量历史信息sj对隐藏状态ht的影响程度,从而提高极端事件的预测精度,即最后,gru神经网络模块在时间t的输出计算为其中在定义中,ut∈[0,1]是在时间t之后是否存在极端事件的预测,并且b是比例参数。为了使输出值ot和观测值yt之间的距离最小,损失函数定义为平方损失,公式为:其中t表示的序列的长度。尽管gru神经网络可以预测一些极端事件,但损失函数仍会遇到极端事件问题。研究表明,平方损失函数可能导致yt的非参数相似。因此,建议在构建损失函数时,不要直接对输出值进行建模,而是关注极端事件指标ut。即,对于观测值yt,近似可写成:其中函数f是比例函数,p(vt=1)是数据集中极端事件的比例。此外,考虑二分类任务来检测极端事件。在本专利的模型中,预测指标是ut,可以被认为极度近似∈1被定义为阈值。然后将该近似值l1视为权重,并将它们添加到二元交叉熵的每个项中,其中β0=p(vt=0)表示数据集中正常事件的比例,β1=p(vt=1)是数据集中极端事件的比例。γ是超参数,是近似中的极值指数。为了将evl与提出的gru神经网络相结合,本专利将预测输出和极端事件预测结合起来,损失函数定义如下:在本实施例中,极端事件在医院费用预测的过程中起着重要作用。表5描述了对于极端事件,使用不同损失函数的性能结果。为了验证本专利提出的evl对未来极端事件预测的有效性,使用两个度量指标来进行评估:(1)准确性,指的是预测结果与实际结果的比值;(2)f1分数,是预测问题的一个衡量指标,即属于每个类别的加权平均值。公式定义为:其中,b代表的是类别总数。tpi,fni,fpi,tni分别表示的是真阳性,假阴性,假阳性,假阴性。表5不同损失函数的性能比较基于表5的结果可得,本实施例采用的损失函数(evl)在极端事件预测方面要优于交叉熵函数(crossentropy,ce)。此外,当损失函数相同时,由于极端事件样本量较少,故使用gru预测极端事件比lstm准确率高。进一步地,所述预训练的gru神经网络的训练步骤包括:构建训练集,所述训练集包括医院的基础特征对应的历史时间序列和医院的历史费用;构建gru神经网络;如图4所示;将训练集输入到gru神经网络中,输出训练好的gru神经网络。进一步地,所述预训练的lstm模型的训练步骤包括:构建训练集;所述训练集包括历史综合特征向量和历史医院费用;构建lstm模型;将训练集,输入到lstm模型中进行训练;采用反向传播算法训练lstm模型中的参数,完成模型的训练;lstm模型训练完成后,将测试样本集的数据输入到lstm模型中,将输出的预测医院费用与实际真实医院费用进行对比,进一步优化lstm模型的参数,最终得到优化后的lstm模型作为最终的预训练lstm模型输出。进一步地,所述s14中,将s12获取的基础特征与s13获取的基础特征进行合并,获得综合特征向量;具体步骤包括:采用注意力机制设置各个基础特征的权重,将s12获取的基础特征与s13获取的基础特征进行合并,获得综合特征向量。进一步地,所述s15中,通过lstm实现医院费用预测。即被定义为:y=lstm{(f1,f2),θlstm}(16)其中,θlstm表示的是lstm的参数;f1表示的是步骤b中获得的基础特征;f2表示的步骤c和d中未来是否存在极端事件的判断。对待测试样本进行医院费用预测,将预测结果进行推送,并与实际医院费用进行结果对比,表6描述了医院费用预测中方法的准确性。本实施实例中,采用均方根误差(rootmeansquarderror,rmse)作为度量指标,rmse越小,预测的性能就越好。rmse的定义为:其中yi表示的是真实值,y′i表示的是预测值,n表示的是预测数量。表6医院费用预测的rmse结果比较methods医院-a医院-b医院-carima0.1950.2760.089lstm0.1870.2480.077gru0.1720.2150.036time-lstm0.1800.2230.048mem+evl0.1690.2040.033lstm+extreme0.1610.1930.029基于表6中的结果可得,本实施例所提出的医院费用模型(lstm+extreme)的性能优于其他方法。因为本实施例所提出lstm+extreme模型不仅考虑了极端事件对医院费用预测的影响,而且考虑了没有相似序列匹配的情况。实施例二,本实施例还提供了面向医院医保限额分配的数据交互方法;面向医院医保限额分配的数据交互方法,包括:某个医院信息系统的医院办公服务器将包含医院唯一编码的医保限额分配请求发送给对应的私有云服务器,私有云服务器将所述医保限额分配请求上传给公有云服务器,公有云服器将所述医保限额分配请求发送给医保中心服务器;医保中心服务器根据医保限额分配请求,对当前医院的社保限额分配额度进行计算,将计算得到的医保限额分配额度依次通过公有云服务器和私有云服务器发送给对应的医院办公服务器。以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1