一种电商评论分析场景下细粒度属性分析方法与流程
本发明属于自然语言处理技术领域,尤其涉及一种电商评论分析场景下细粒度属性分析方法。
背景技术:
目前,业内常用的现有技术是这样的:随着网络普及物流行业日益完善,所带来的电商行业蓬勃发展,越来越多的用户选择通过网购获取各类日常用品乃至食品、电子产品。相较于线下,电商渠道提供了快捷便利的产品反馈机制——用户评论。电商用户评论搭建起了一个连接用户及品牌方的高速通道,单一商品动辄十万乃至百万计的用户评论无疑对品牌及产品提升拥有极高的价值。如此庞大的数据量显然是无法依靠人工进行细致统计的。仰赖于以深度学习为代表的人工智能领域的高速发展,如今的自然语言处理技术已经足以为电商评论数据提供足够精度的细粒度情感分析服务,将自然语言描述提取为结构化数据,使得海量的电商评论金矿有了合适的开采手段。
在细粒度情感分析解决案例中,普遍做法是根据电商行业选定一个评论数据集,通过人工阅读这些评论,对这些文本进行标注,得到这一数据集中业务所关注的目标属性以及对应的情感。使用一定量的标注数据对选定的模型进行训练,使模型习得该数据集的特征,进而对海量的评论数据进行预测。目前机器学习领域一个常见瓶颈问题在于标注数据的获取成本高昂,如何降低标注成本,提升标注速度,从而加快模型上线速度成为业界关注的焦点。
综上所述,现有技术存在的问题是:目前机器学习领域中,标注数据的获取成本高昂。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种电商评论分析场景下细粒度属性分析方法。
本发明是这样实现的,一种电商评论分析场景下细粒度属性分析方法包括:
步骤一、使用两个同构而独立训练的序列标注模型对电商评论分别进行目标属性及情感的抽取;
步骤二、使用一个关系分类模型对步骤一中模型抽取得到的目标属性及情感进行关系分类;
步骤三、模型的训练数据使用一种高效标注策略进行,使用该策略标注的数据用于步骤一和步骤二中模型的训练,经检验该方案的预测准确率在电商分析场景下效果佳;
步骤四、用于整合各模型输出的目标属性及情感的规则匹配关系模块:本关系模块与步骤二中的关系模型协同完成属性及情感关系的配对;
步骤五、用于整合规则匹配关系模块输出以及关系分类模型输出的后处理模块。
进一步,在步骤一中,使用双向循环神经网络辅以条件随机场作为模型基础结构,模型同时使用字向量及词向量的拼接作为模型的输入特征;
其中rnn部分选用包括长短记忆神经网络或门控循环单元。
进一步,对输入文本进行分字及分词,每个字的特征由该字的字向量以及其所在单词的词向量首尾拼接所构成。
进一步,在步骤二中,使用双向循环神经网络辅以字、词注意力层作为网络基础结构。
进一步,所述字、词向量另外拼接一个属性实体在句中的位置向量以及一个情感实体在句中的位置向量作为模型输入;
进一步,该抽取模型仅对关系的有无做二分类推断,抽取模型仅对规则匹配关系模块未匹配之目标属性及情感进行关系分类。
进一步,在步骤三中,针对满足特定规则的评论文本进行一体式共现标注,并以此区别于传统的序列标注仅仅对目标属性或情感进行单一标注。
进一步,在步骤三中,标注时以目标属性及其相关情感在单一标注文本中共现为目标,将文本同时标记为目标属性及情感;
对于例外所产生的孤立标注文本,通过跨子句建立关系标注;
对于例外所产生的孤立目标属性及孤立情感,在后处理流程中根据业务逻辑进行配置。
进一步,在步骤四中,
对属性及情感模型预测得到的属性及情感实体进行穷举组合;
若属性及情感实体对的序列范围有重叠时,直接将两者认定为有关联;
序列范围没有重叠的属性及情感实体对将转由所述关系模型进行判别;
该模块主要目的在于利用经验获得可靠关系,并且降低了所述关系模型的训练及预测开销;
该模块所使用之经验规则依赖于所述之数据标注方式,传统标注方式将无法使用本模块之经验规则。
进一步,在步骤五中,
使用独立训练的属性及情感标注模型获得独立的预测结果,根据两个模型的输出,将基于规则以及基于关系模型的属性和情感关系对进行汇总;
针对客户的需求进行包括关键词过滤、映射以及属性实体的层级映射等简单业务规则在内的后处理适配。
综上所述,本发明的优点及积极效果为:通过本发明提供的解决方案,在保证细粒度情感预测结果准确率的前提下,简化了细粒度情感标注任务的复杂度,提升了标注效率。缓解数据标注成本这一深度学习项目落地的瓶颈问题,并大大缩短了电商评论分析产品的上线周期。
附图说明
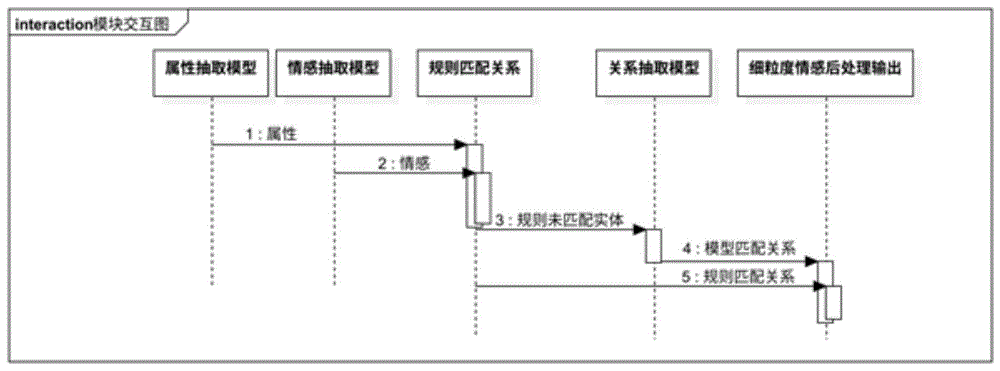
图1是本发明实施例提供的除标注流程外其他各模块的交互关系概略图。
图2是本发明实施例提供的电商评论分析场景下细粒度属性分析方法流程图。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下。
针对现有技术存在的问题,本发明提供了一种电商评论分析场景下细粒度属性分析方法,下面结合附图1对本发明作详细的描述。
一种电商评论分析场景下细粒度属性分析方法包括:
s101、使用两个同构而独立训练的序列标注模型对电商评论分别进行目标属性及情感的抽取;
s102、使用一个关系分类模型对步骤一中模型抽取得到的目标属性及情感进行关系分类;
s103、模型的训练数据使用一种高效标注策略进行,使用该策略标注的数据用于步骤一和步骤二中模型的训练,经检验该方案的预测准确率在电商分析场景下效果佳;
s104、用于整合各模型输出的目标属性及情感的规则匹配关系模块:本关系模块与步骤二中的关系模型协同完成属性及情感关系的配对;
s105、用于整合规则匹配关系模块输出以及关系分类模型输出的后处理模块。
进一步,在s101中,使用双向循环神经网络辅以条件随机场作为模型基础结构,模型同时使用字向量及词向量的拼接作为模型的输入特征;
其中rnn部分选用包括长短记忆神经网络或门控循环单元。
进一步,对输入文本进行分字及分词,每个字的特征由该字的字向量以及其所在单词的词向量首尾拼接所构成。
进一步,在s102中,使用双向循环神经网络辅以字、词注意力层作为网络基础结构。
进一步,所述字、词向量另外拼接一个属性实体在句中的位置向量以及一个情感实体在句中的位置向量作为模型输入;
进一步,该抽取模型仅对关系的有无做二分类推断,抽取模型仅对规则匹配关系模块未匹配之目标属性及情感进行关系分类。
进一步,在s103中,针对满足特定规则的评论文本进行一体式共现标注,并以此区别于传统的序列标注仅仅对目标属性或情感进行单一标注。
进一步,在s103中,标注时以目标属性及其相关情感在单一标注文本中共现为目标,将文本同时标记为目标属性及情感;
对于例外所产生的孤立标注文本,通过跨子句建立关系标注;
对于例外所产生的孤立目标属性及孤立情感,在后处理流程中根据业务逻辑进行配置。
进一步,在s104中,对属性及情感模型预测得到的属性及情感实体进行穷举组合;
若属性及情感实体对的序列范围有重叠时,直接将两者认定为有关联;
序列范围没有重叠的属性及情感实体对将转由所述关系模型进行判别;
该模块主要目的在于利用经验获得可靠关系,并且降低了所述关系模型的训练及预测开销;
该模块所使用之经验规则依赖于所述之数据标注方式,传统标注方式将无法使用本模块之经验规则。
进一步,在s105中,使用独立训练的属性及情感标注模型获得独立的预测结果,根据两个模型的输出,将基于规则以及基于关系模型的属性和情感关系对进行汇总;
针对客户的需求进行包括关键词过滤、映射以及属性实体的层级映射等简单业务规则在内的后处理适配。
该电商评论分析场景下细粒度属性分析方法的模块基本交互逻辑,该交互逻辑包括以下步骤:
步骤一、调用“属性抽取模块”(序列标注模型)对电商文本进行分析,得到电商文本中的目标属性实体集合,发往“规则匹配关系模块”;
步骤二、同时,调用“情感抽取模块”(序列标注模型)对电商文本进行分析,得到电商文本中的情感实体集合,发往“规则匹配关系模块”;
步骤三、“规则匹配关系模块”根据输入的属性1与情感2的实体位置交集关系,确定规则未匹配的属性及情感实体,并发往“关系抽取模块”;
步骤四、“关系抽取模块”(关系分类模型)针对未匹配的目标属性及情感实体进行关系分类预测,预测结果发往“细粒度情感后处理输出模块”;
步骤五、同时,“规则匹配关系模块”中的规则匹配关系一同发往“细粒度情感后处理输出模块”进行整合输出。
该电商评论分析场景下细粒度属性分析方法使用两个基于brnn-crf框架的序列标注模型对电商评论分别进行目标属性及情感的抽取:
步骤一、brnn通过一个前向网络结构,为句中的每个字向量进行编码,每个字得到一个前向编码向量,且该向量具有该字在之前所有字所提供的语境下的语义,其同时通过一个反向网络结构,获得句中每个字的反向编码向量,使得该向量具有该字之后所有字所提供的语境下的语义;
步骤二、将每个字的前向和反向编码向量拼接,得到双向编码向量,其拥有了每个字在完整语境下的语义信息;
步骤三、根据该双向编码向量,通过一个线性全连接层及softmax激活函数得到每个字的序列标注分类;
步骤四、为了保证序列连贯的天然属性,使用crf求得最大化的序列路径。
使用一个基于brnn-attention框架的关系分类模型对抽取的目标属性及情感进行关系分类:
步骤一、brnn部分与brnn-crf模型中完全一致;
步骤二、brnn的输入与序列标注模型稍有不同,在字、词向量的基础上,还拼接了该句中所包含的一个属性实体的位置向量以及该句中所包含的一个情感实体的位置向量;
步骤三、attention部分通过为句中的每个字两两之间建立一个权重矩阵,在误差反向传递的过程中,使得语义表达相关的文字拥有更高的权重;
步骤四、使用上一步获得的attention权重对brnn编码进行加权后,通过一个线性全连接层及softmax激活函数得到该属性情感实体对在该语句语境下的关系分类结果。
为了更好的捕获评论中的语义要素,上述模型的输入均使用字向量与词向量首尾拼接作为基本输入特征(其中brnn-attention模型的输入特征还另外包括属性实体位置向量以及情感实体位置向量);
为提升标注人员的工作效率,本发明针对电商评论文本的特点,使用了一种高效的一体式共现标注策略,该策略在绝大多数情况下将标注工作中的属性,情感,关系标注简化为了“属性-情感对”标注,而仅有较少(约占总数据量的10%)的“属性”及“情感”不在同一个语句片段的情况将沿用传统的“属性-情感-关系”三元标注,从而简化标注流程以提升标注效率。
同时,本发明给出了一套与标注及模型架构相匹配的模型预测后处理整合策略以保证细粒度情感分析整体任务的准确度。
以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!