一种提升异常数据挖掘筛选的方法与流程
本发明属于数据分析领域,可广泛应用于经融、教育、科研、电商等行业,例如教学考评数据、综合素质评测数据、效益评估数据、产品定向推送分析数据等,特别涉及数据聚类、数据挖掘、数据异常分析、局部偏离度量等技术。
背景技术:
信息技术不断发展的阶段,各类数据统计决策对数据质量的要求越来越高。要提高数据质量就得有好的数据处理方法,由于系统各种误差带来劣质数据不可避免,一方面是有效数据,另一方面是劣质数据。在这种情况下,更应该考虑如何找出这样的劣质数据并加以剔除,才能提高数据的质量并得到准确的分析的结果
基于此就提出了异常数据挖掘的概念,异常数据挖掘处理是异常数据筛选领域一个重要的部分,通常一个数据集中异常数据被认为是与其他数据有着明显差异的数据。在越来越多的应用领域中异常数据的挖掘筛选有着非凡的意义
随着数据挖掘领域的不断扩展,在对异常数据的不断研究中发现了不少有价值的东西,近些年来异常数据挖掘成了热门的话题,也陆续出现了不少异常数据挖掘的方法,如分步法、聚类法、距离法、密度法等基于局部偏离因子(localoutlierfactor)出现了很多局部偏离程度的度量算法,这些算法大多基于静态环境数据库,然而在现今不少应用领域,如经融、教育、政务、科研、电商等大部分业务数据库的数据都是动态增加的、不断变化的,新增加的数据是会影响其他某些对象的局部偏离程度的,在对数据进行再次挖掘时将计算所有数据对象的局部偏离因子,相对来说计算的时间复杂度偏高,这些算法在动态增加的数据环境中实现起来很困难。
技术实现要素:
为解决上述技术问题,本发明提出一种提升异常数据挖掘筛选的方法,可以很大程度上降低计算时间加快异常数据挖掘筛选的进度,提升数据质量。
本发明采用的技术方案为:一种提升异常数据挖掘筛选的方法,包括:
a1、从业务数据库中获取数据集,所述数据集包括若干数据对象;
a2、采用传统的聚类算法,对步骤a1所获取的数据集进行聚类,得到初始化的簇与初始化的异常数据集;
a3、获取当前输入的新的数据对象与步骤a2所述各簇的核心对象的距离最小值;
a4、若步骤a3所计算的到的距离最小值小于设定的半径,则将输入的新的数据对象并入距离最小值对应簇;否则将输入的新的数据对象加入异常数据集。
步骤a2具体过程为:
a21、对于数据集中未被访问的数据对象,且该数据对象未被归入某个簇或被标记为异常数据,检查其r邻域,如果其r邻域内包含的数据对象数目大于或等于mindn,则建立新簇c,并将该数据对象及邻域内包含的数据对象并入c中;
所述r为设定的半径;
a22、如果c中存在未被处理的数据对象,检查其r邻域,如果其r邻域内包含的数据对象大于或等于mindn,将该数据对象及邻域内包含的点并入c;
a23、重复步骤a22,直到c中的对象都分别处理过;
a24、若数据集中所有数据对象都被访问过,则结束;否则返回步骤a21。
所述设定半径的确定过程为:
首先,确定一个簇中至少应包含的数据对象的数目mindn;
然后,根据mindn,计算每个数据对象与他的第mindn个数据对象之间的距离k-dis;
其次,对该数据集中的每个数据对象按照其对应的k-dis从小到大排序;
最后,根据排序结果确定半径。
步骤a3所述核心对象为簇中所有聚类对象的均值。
mindn取值为步骤a1所述数据集中数据对象总数的10%。
核心对象为聚类簇中每个聚类对象的均值。
本发明的有益效果:本发明的方法通过首先采用传统的聚类算法对数据集进行聚类,获得初始的聚类簇与异常数据集;对于新增的数据对象计算它和这些簇核心对象的距离,然后计算最小距离所在的簇,加入最小距离小于给定的半径r,则将该新增的数据对象并入该簇中,如果新增的数据队形没有并入到任何初始簇中,则将该数据加入异常数据集中;通过本发明的方法不必再次调用原算法对整个数据集进行重新的聚类,大大的节省了计算时间,从此可以看出改进的挖掘筛选算法在动态增量数据的环境下比传统的聚类算法,效率和速度提升很大。
附图说明
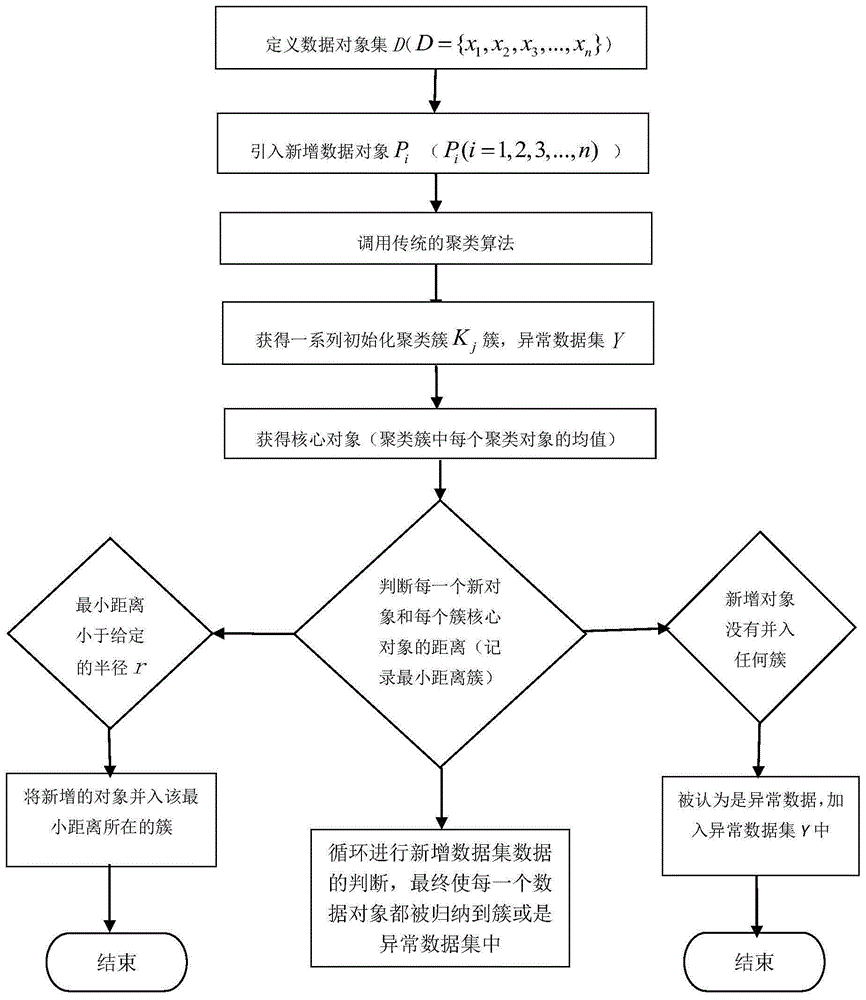
图1为本发明的方案流程图。
具体实施方式
为便于本领域技术人员理解本发明的技术内容,首先对以下技术进行说明:
1、局部偏离因子lof
定义参数最少邻居数为k和最近邻距离来确定邻域。通过计算对象k-距离、可达距离、可达密度lrdk(p),获得的数据对象邻域的平均可达密度与数据对象本身的可达密度之比即lof(局部偏离因子):
对象p的局部偏离因子表示对象p的异常程度,局部偏离因子的值越大异常的可能性就会越大;反之则可能性较小。
注:q的定义(p的最近k个邻居集合为nk-dis(p),即包含所有与p的距离小于等于k-dis(p)的数据对象q)
2、传统的基于密度的聚类算法
对于簇中的每一个数据对象在给定半径r范围内至少包含给定数目mindn的数据对象,该算法聚类的速度较快,能在带有异常数据集中快速的发现任意形状的聚类,具体算法过程为:
1)检查数据集中未被访问的数据对象p,且这个数据对象没有被归入某个簇或是被标记为异常数据,检查他的r邻域ng(p),如果其ng(p)邻域内包含的数据对象数目大于等于mindn,则建立新簇c,并将p及邻域内包含的数据对象并入c中;
2)如果c中有未被处理的数据对象q,检查他的r邻域ng(q),如果其ng(q)邻域内包含的数据对象大于等于mindn,将q及邻域内包含的点并入c;
3)重复步骤2,直到c中的对象都分别处理过;
4)重复步骤1-3直到所有数据对象都被访问过,并且所有数据对象都被标记为族或是都被认为为异常数据。
这种聚类算法结果受参数r和mindn的影响较大,给定mindn选择的r越小,发现簇的密度越高,但是如果选择的r过小,则会导致大量的数据对象被误认为是异常数据对象;如果选择的r过大,则会将很多异常数据对象错误的归并为某些簇,给定r,选择的mindn越大,发现簇的密度越高,但是过大的mindn会使得一些包含数据对象较少的簇被丢失,容易将正确的数据对象误认为为异常的数据对象;如果选择的mindn过小会将异常的数据对象错误的归并为某些簇。
可以采取一种可视化方法辅助r的确定,首先固定mindn=k,计算每个对象与他的第k个最近的对象之间的距离k-dis,然后对数据集中对象按照k-dis由大到小进行排序,然后根据“排序k-dis图”确定参数r,这样可以获得很好的聚类效果,异常数据对象是少数的,通常只占数据集的10%不到,为了使异常数据集中包含的正确的异常数据对象较多,选择mindn的大小为数据集中数据对象的总数乘以10%,然后根据排序k-dis图确定参数r。
但是传统的局部偏离因子的算法存在计算的时间复杂度高(在数据集中需要计算每一个数据对象的k-距离邻域以及局部偏离因子lof)的缺陷,异常数据在数据集中只有很少的部分,对于非异常数据,计算局部偏离因子没有意义,此情况下,应该尽量避免计算所有数据对象的局部偏离因子。在动态增量数据库的环境下,新增加的数据对象可能会影响原有数据对象的局部偏离因子的值,再次进行挖掘异常数据时,如果对整个数据集重新调用偏离因子的算法进行局部偏离因子的计算,将很大程度上浪费了计算时间降低了效率。
在动态数据新增的情况下,新增的数据对象在不断的变化可能会影响到原来的聚类分析结果造成数据分析的不准确,介于此类情况按照现有的方法则需要进行再次计算重新进行聚类计算量相对比较大,但实际情况下新增的数据对象往往只会影响到它周围的邻居对象簇,基于此情况本发明提出了一种改进的异常数据挖掘筛选算法,在原基于密度的聚类算法基础上进行了部分改进,通过调用原算法形成初始化的簇和异常数据对象集,对于新增的数据对象计算它和这些簇核心对象的距离(核心对象为聚类簇中每个聚类对象的均值),然后计算最小距离所在的簇,加入最小距离小于给定的半径r,则将该新增的数据对象并入该簇中,如果新增的数据队形没有并入到任何初始簇中,则将该数据加入异常数据集中。
如图1所示,本发明的一种提升异常数据挖掘和筛选效率的算法,包括如下步骤:
s1、定义n个数据对象x的数据集d,数据集定义为d={x1,x2,x3,...,xn};
s2、簇中至少包含的数据对象数目mindn;
s3、半径范围r;
s4、设定pi(i=1,2,3,...,n)表示一些新增的数据对象;
s5、调用传统的聚类算法形成一些初始化的簇和初始化的异常数据集u,kj表示一系列初始化聚类簇;
s6、当新的数据对象到达时,计算它和这些初始化的簇的核心对象mj的距离dis(pi,mj)
s7、判断mj距离,加入的数据最小距离小于给定的半径r,则将该新增的数据对象并入该簇中,如果新增的数据队形没有并入到任何初始簇中,则将该数据加入异常数据集中
s8、输出一系列聚类簇和异常数据集y
步骤s1具体为:
定义初始化输入的n个数据对象x的数据集d(d={x1,x2,x3,...,xn}),设定pi为一些新增的数据对象,变量i的值可以为1到n(i=1,2,3,...,n)表达式:
pi(i=1,2,3,...,n)
步骤s2具体为:
簇中至少包含的数据对象数目mindn:此值用于和计算出的邻域包含的数据对象数目做对比,如果邻域中包含的数据对象数目大于或等于mindn的值则新建簇c,并将被检查的数据集中的数据对象p及其邻域内包含的数据对象并入新的簇c中;如果邻域中包含的数据对象小于mindn的值,则将数据对象p及其邻域内包含的数据对象并入原簇中。
步骤s3具体为:
对于簇而言,每一个数据对象在给定的半径范围r内至少包含给定数目的mindn对象。半径范围的值会影响传统的算法聚类,r的值越小发现簇的密度越高,过小又会导致大量的数据对象被误识别为异常的数据对象;选择过大,又会遗漏将很多异常数据归并到某些簇中。如果给定r的值,mindn选择越大,发现簇的密度越高,选择过大会使得一些包含数据对象较少的簇丢弃也容易将正常的数据对象误认为是一次数据对象,先择的mindn过小会将异常数据对象错误的归并到某些簇中。
为解决此类问题,本发明首先定义:
mindn=k
然后计算簇中每一个对象与它的第k个最近对象之间的距离k-dis,对得到的数据对象按照k-dis值由大到小的顺序进行排序,然后绘制排序的k-dis图像,然后根据排序图来确定r参数(取每个对象k-dis距离的均值),这样可以获得很好聚类效果。异常数据针对正常数据而言是少量的,一般情况下都不会超过总数据集的10%,为了使异常数据集中包含的异常数据更加准确,我们定义mindn的大小为数据集中数据对象个数乘以10%。
步骤s4具体为:
调用传统的聚类算法,得到一些初始化的簇和初始化的异常数据集y,kj(j=1,2,3,...,n)示一系列初始化聚类簇。
步骤s5具体为:
新的数据对象被输入时,进行数据对象的从i=1ton比对(计算对象与初始化簇的核心对象mj的距离dis(pi,mj))
if(dis(pi,mj)是最小的&&dis(pi,mj)≤r)
kj=kjypi
else
if(dis(pi,mj)是最小的&&dis(pi,mj)>r)
then
将pi加入y的集合中
endif
endif
endfor
注:&&代表并列条件
步骤s6具体为:重复执行步骤5,直到新增的数据对象都能被标记为某一个簇或是被认为异常数据对象。
步骤s7具体为:
改进的算法,在新的数据对象达到时,可以进行改进的挖掘筛选算法,不必再次调用原算法对整个数据集进行重新的聚类,大大的节省了计算时间,从此可以看出改进的挖掘筛选算法在动态增量数据的环境下比传统的聚类算法,效率和速度提升很大。
传统的挖掘筛选算法缺点是在面临动态增量数据的情况下,计算时间负责度很高。数据集中需要计算每一个数据对象的k-距离邻域以及局部偏离因子,异常数据在数据库中所占的比例不高只有极少部分,对于非异常数据计算局部偏离因子没有意义。我们为了提高整体效率,应该尽量避免计算所有数据的局部偏离因子。同时在增量数据动态增加的情况下,新增加数据会影响原数据的偏离因子的值,在二次数据挖掘的时候,我们需要调用原算法对整个数据集进行局部偏离因子的计算,浪费大量的计算时间严重降低效率。
改进的算法首先进行聚类算法对数据集进行聚类,形成聚类簇和异常数据集。然后对聚类簇计算其簇中核心和簇中所有数据队形的距离的平均值,然后对簇中每一个数据对象计算其和簇心的距离,距离小于这个平均值,数据对象是正常的,否则数据对象是异常的。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!