一种基于大数据的车货匹配方法及系统与流程
本发明涉及大宗商品物流领域,尤其涉及一种基于大数据的车货匹配方法及系统。
背景技术:
物流企业不定期的需要货车运力来运输自己的大宗商品。货车司机不会一直在线关注货源信息网站。货源和司机的匹配度不高,导致常规的广告手段效率低下,对司机造成骚扰,同时浪费企业资源。
技术实现要素:
为了解决上述问题,本发明提供了一种基于大数据的车货匹配方法及系统,一种基于大数据的车货匹配方法,主要包括以下步骤:
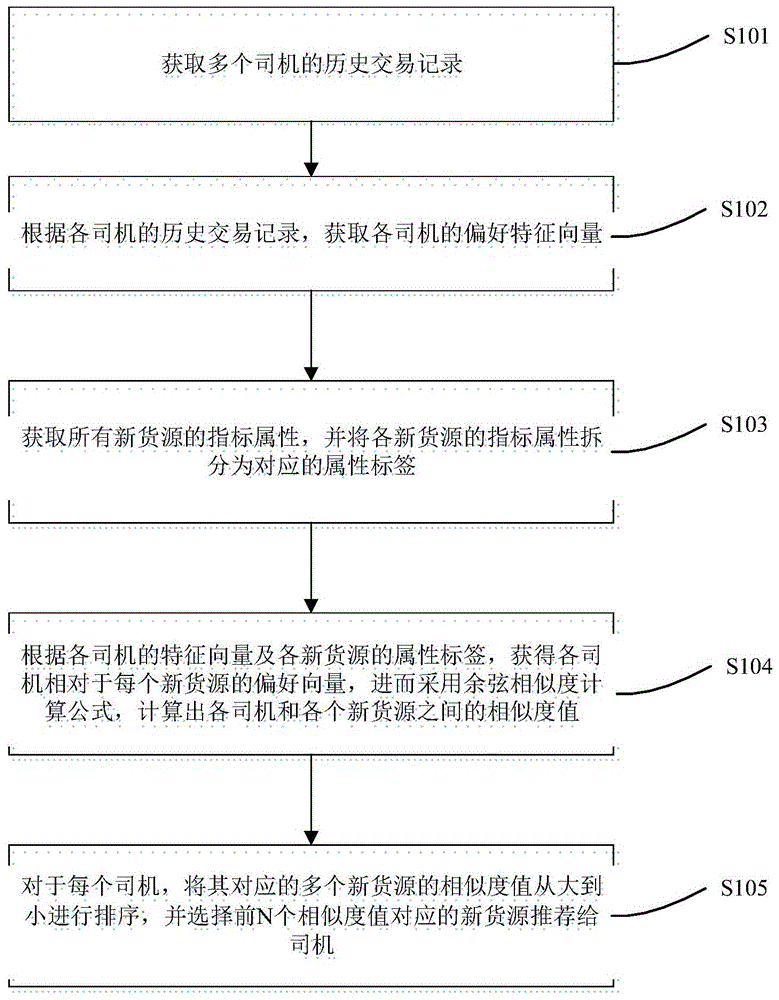
s101:获取多个司机的历史交易记录;
s102:根据各司机的历史交易记录,获取各司机的偏好特征向量;
s103:获取所有新货源的指标属性,并将各新货源的指标属性拆分为对应的属性标签;所述新货源有多个,每个新货源对应多个属性标签;
s104:根据各司机的特征向量及各新货源的属性标签,获得各司机相对于每个新货源的偏好向量,进而采用余弦相似度计算公式,计算出各司机和各个新货源之间的相似度值;
s105:对于每个司机,将其对应的多个新货源的相似度值从大到小进行排序,并选择前n个相似度值对应的新货源推荐给司机;其中,n为预设值,且n大于0。
进一步地,步骤s101中,通过大数据平台,抽取线上系统的数据到数据仓库,进而提取司机历史交易记录;所述历史交易记录中包括对应司机交易过的所有历史货源集合;所述历史货源集合中包括多个货源,每个货源对应有多个属性标签。
进一步地,步骤s102中,针对某个司机,根据所述历史交易记录,获取该司机的特征向量的方法如下:
计算所述历史货源集合中每个货源下各属性标签的偏好情况,得出对应指标后,进行权重的计算,再得出该司机对某一具体标签的权重偏好,即根据司机过去喜欢什么样的货源来产生刻画此司机喜好的特征向量,把司机所有交易过的货源对应的向量的平均值作为此用户的特征向量;具体步骤如下:
s201:将该司机的历史货源集合表示为d=[d1,d2,…,dj,…,dn];其中,dj表示第j个货源,j=1,2,…,n,n为历史货源集合中的货源总数;
s202:将每个货源的属性标签集合表示为t=[t1,t2,…,ti,…,tm];其中,ti表示该货源的第i个属性标签;i=1,2,…,m,m为货源的属性标签总数;
s203:结合s201和s202,将该用户对货源dj的喜好的特征向量表示为:dj=[w1j,w2j,…,wij,…,wnj];其中,wij表示第j个货源的第i个属性标签在货源dj中所占的权重大小;其中,wij的计算公式如公式(1)所示:
s204:把司机与历史货源集合中所有货源对应的特征向量的平均值作为此司机的偏好特征向量w;即,w=[w1,w2,…,wi,…,wm];其中,表示司机对第i个属性标签的偏好值,将司机对所有历史货源的第i个属性标签的权重大小的平均值作为其对第i个属性标签的偏好值,即
进一步地,步骤s104中,针对某个司机和某个新货源之间的偏好向量r,计算公式如式(2)所示:
r=[x1,x2,…,xi,…,xm](2)
上式中,xi为该司机对该货源的第i个属性标签的偏好值,xi的值等于该司机的偏好特征向量中的wi的值。
进一步地,步骤s104中,采用余弦相似度计算公式,计算各司机和各个新货源之间的相似度值时;针对司机s和某个新货源a之间的相似度值rsa的计算公式如式(3)所示:
上式中,ai表示司机s对货源a的第i个属性标签的偏好值;bi为新货源a对于第i个属性标签的权重定义值,为预设值。
进一步地,一种基于大数据的车货匹配系统,其特征在于:包括以下模块:
记录获取模块,用于获取多个司机的历史交易记录;偏好特征向量获取模块,用于根据各司机的历史交易记录,获取各司机的偏好特征向量;
属性标签获取模块,用于获取所有新货源的指标属性,并将各新货源的指标属性拆分为对应的属性标签;所述新货源有多个,每个新货源对应多个属性标签;
相似度计算模块,用于根据各司机的特征向量及各新货源的属性标签,获得各司机相对于每个新货源的偏好向量,进而采用余弦相似度计算公式,计算出各司机和各个新货源之间的相似度值;
推荐模块,用于对于每个司机,将其对应的多个新货源的相似度值从大到小进行排序,并选择前n个相似度值对应的新货源推荐给司机;其中,n为预设值,且n大于0。
进一步地,偏好特征向量获取模块中,通过大数据平台,抽取线上系统的数据到数据仓库,进而提取司机历史交易记录;所述历史交易记录中包括对应司机交易过的所有历史货源集合;所述历史货源集合中包括多个货源,每个货源对应有多个属性标签。
进一步地,偏好特征向量获取模块中,针对某个司机,根据所述历史交易记录,获取该司机的特征向量的方法如下:
计算所述历史货源集合中每个货源下各属性标签的偏好情况,得出对应指标后,进行权重的计算,再得出该司机对某一具体标签的权重偏好,即根据司机过去喜欢什么样的货源来产生刻画此司机喜好的特征向量,把司机所有交易过的货源对应的向量的平均值作为此用户的特征向量;具体包括如下单元:
历史货源集合单元,用于将该司机的历史货源集合表示为d=[d1,d2,…,dj,…,dn];其中,dj表示第j个货源,j=1,2,…,n,n为历史货源集合中的货源总数;
属性标签集合单元,用于将每个货源的属性标签集合表示为t=[t1,t2,…,ti,…,tm];其中,ti表示该货源的第i个属性标签;i=1,2,…,m,m为货源的属性标签总数;
喜好特征向量获取单元,用于结合历史货源集合单元和属性标签集合单元,将该用户对货源dj的喜好的特征向量表示为:dj=[w1j,w2j,…,wij,…,wnj];其中,wij表示第j个货源的第i个属性标签在货源dj中所占的权重大小;其中,wij的计算公式如公式(4)所示:
偏好特征向量获取单元,用于把司机与历史货源集合中所有货源对应的特征向量的平均值作为此司机的偏好特征向量w;即,w=[w1,w2,…,wi,…,wm];其中,表示司机对第i个属性标签的偏好值,将司机对所有历史货源的第i个属性标签的权重大小的平均值作为其对第i个属性标签的偏好值,即
进一步地,相似度计算模块中,针对某个司机和某个新货源之间的偏好向量r,计算公式如式(5)所示:
r=[x1,x2,…,xi,…,xm](5)
上式中,xi为该司机对该货源的第i个属性标签的偏好值,xi的值等于该司机的偏好特征向量中的wi的值。
进一步地,相似度计算模块中,采用余弦相似度计算公式,计算各司机和各个新货源之间的相似度值时;针对司机s和某个新货源a之间的相似度值rsa的计算公式如式(6)所示:
上式中,ai表示司机s对货源a的第i个属性标签的偏好值;bi为新货源a对于第i个属性标签的权重定义值,为预设值。
本发明提供的技术方案带来的有益效果是:本发明所提出的技术方案可以优选匹配度高的司机进行通知,以此提高成单率和叫车效率。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例中一种基于大数据的车货匹配方法的流程图;
图2是本发明实施例中余弦相似度计算方法的计算原理示意图;
图3是本发明实施例中一种基于大数据的车货匹配系统的模块组成示意图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
本发明的实施例提供了一种基于大数据的车货匹配方法。
请参考图1,图1是本发明实施例中一种基于大数据的车货匹配方法的流程图,具体包括如下步骤:
s101:获取司机的历史交易记录;所述司机有多个,每个司机均对应有一个历史交易记录;
s102:根据各司机的历史交易记录,获取各司机的偏好特征向量;
s103:获取所有新货源的指标属性,并将各新货源的指标属性拆分为对应的属性标签;所述新货源有多个,每个新货源对应多个属性标签;
s104:根据各司机的特征向量及各新货源的属性标签,获得各司机相对于每个新货源的偏好向量,进而采用余弦相似度计算公式,计算出各司机和各个新货源之间的相似度值;
s105:对于每个司机,将其对应的多个新货源的相似度值从大到小进行排序,并选择前n个相似度值对应的新货源推荐给司机;其中,n为预设值,且n大于0。
步骤s101中,通过大数据平台,抽取线上系统的数据到数据仓库,进而提取司机历史交易记录;所述历史交易记录中包括对应司机交易过的所有历史货源集合;所述历史货源集合中包括多个货源,每个货源对应有多个属性标签。
所述历史交易记录中还包括:司机的注册身份信息,注册车辆信息,手机设备信息,历史接单时间,活跃地点,跑单里程,货源类型等等。
步骤s102中,针对某个司机,根据所述历史交易记录,获取该司机的特征向量的方法如下:
计算所述历史货源集合中每个货源下各属性标签的偏好情况,得出对应指标后,进行权重的计算,再得出该司机对某一具体标签的权重偏好,即根据司机过去喜欢什么样的货源来产生刻画此司机喜好的特征向量,把司机所有交易过的货源对应的向量的平均值作为此用户的特征向量;具体步骤如下:
s201:将该司机的历史货源集合表示为d=[d1,d2,…,dj,…,dn];其中,dj表示第j个货源,j=1,2,…,n,n为历史货源集合中的货源总数;
s202:将每个货源的属性标签集合表示为t=[t1,t2,…,ti,…,tm];其中,ti表示该货源的第i个属性标签;i=1,2,…,m,m为货源的属性标签总数;
s203:结合s201和s202,将该用户对货源dj的喜好的特征向量表示为:dj=[w1j,w2j,…,wij,…,wnj];其中,wij表示第j个货源的第i个属性标签在货源dj中所占的权重大小;其中,wij的计算公式如公式(1)所示:
s204:把司机与历史货源集合中所有货源对应的特征向量的平均值作为此司机的偏好特征向量w;即,w=[w1,w2,…,wi,…,wm];其中,表示司机对第i个属性标签的偏好值,将司机对所有历史货源的第i个属性标签的权重大小的平均值作为其对第i个属性标签的偏好值,即
根据各司机的偏好特征向量,可以分析得到司机的企业偏好,货源偏好,地点偏好,业务模式偏好等。
如下表所示,为某司机的偏好特征向量表示例:
上表中,子标签即为属性标签,权重值即为司机对第属性标签的偏好值。
步骤s104中,针对某个司机和某个新货源之间的偏好向量r,计算公式如式(2)所示:
r=[x1,x2,…,xi,…,xm](2)
上式中,xi为该司机对该货源的第i个属性标签的偏好值,xi的值等于该司机的偏好特征向量中的wi的值。
比如,某个货源a共有五个指标(属性标签),分别是装货地、卸货地、运费总价、运输里程和运输时限;其中,装货地是湖北,卸货地是湖北,运费总价是7000,运输里程为500km,运输限时为30天,然后对应的权重设置为1~5(此处仅为示例,以更便于理解);
司机张某:对于装货地是湖北的权重偏好值为3,对于卸货地是湖北的偏好值为1,对运费总价是7000偏好值为4,对运输里程为500km的偏好值为5,对运输限时为30天的偏好值为0,则司机张某可以用向量表示为ra(3,1,4,5,0);
司机李某:对装货地是湖北的权重偏好值为3,对卸货地是湖北的偏好值为4,对运费总价是7000偏好值为5,对运输里程为500km的偏好值为0,对运输限时为30天的偏好值为2,则司机李某可用向量表示为rb(3,4,5,0,2)。
步骤s104中,采用余弦相似度计算公式,计算各司机和各个新货源之间的相似度值时;针对司机s和某个新货源a之间的相似度值rsa的计算公式如式(3)所示:
上式中,ai表示司机s对货源a的第i个属性标签的偏好值;bi为新货源a对于第i个属性标签的权重定义值,为预设值。
余弦相似度计算方法的计算原理如图2所示,通过衡量两个向量间的夹角大小,通过夹角的余弦值表示结果,余弦相似度的值本身是一个0~1的值,0代表完全正交,1代表完全一致。在[-1,1]中,绝对值越大表示越相似。
请参阅图3,图3是本发明实施例中一种基于大数据的车货匹配系统的模块组成示意图;包括顺次连接的记录获取模块11、偏好特征向量获取模块12、属性标签获取模块13、相似度计算模块14和推荐模块15;
记录获取模块11,用于获取司机的历史交易记录;所述司机有多个,每个司机均对应有一个历史交易记录;
偏好特征向量获取模块12,用于根据各司机的历史交易记录,获取各司机的偏好特征向量;
属性标签获取模块13,用于获取所有新货源的指标属性,并将各新货源的指标属性拆分为对应的属性标签;所述新货源有多个,每个新货源对应多个属性标签;
相似度计算模块14,用于根据各司机的特征向量及各新货源的属性标签,获得各司机相对于每个新货源的偏好向量,进而采用余弦相似度计算公式,计算出各司机和各个新货源之间的相似度值;
推荐模块15,用于对于每个司机,将其对应的多个新货源的相似度值从大到小进行排序,并选择前n个相似度值对应的新货源推荐给司机;其中,n为预设值,且n大于0。
偏好特征向量获取模块12中,通过大数据平台,抽取线上系统的数据到数据仓库,进而提取司机历史交易记录;所述历史交易记录中包括对应司机交易过的所有历史货源集合;所述历史货源集合中包括多个货源,每个货源对应有多个属性标签。
偏好特征向量获取模块12中,针对某个司机,根据所述历史交易记录,获取该司机的特征向量的方法如下:
计算所述历史货源集合中每个货源下各属性标签的偏好情况,得出对应指标后,进行权重的计算,再得出该司机对某一具体标签的权重偏好,即根据司机过去喜欢什么样的货源来产生刻画此司机喜好的特征向量,把司机所有交易过的货源对应的向量的平均值作为此用户的特征向量;具体包括如下单元:
历史货源集合单元,用于将该司机的历史货源集合表示为d=[d1,d2,…,dj,…,dn];其中,dj表示第j个货源,j=1,2,…,n,n为历史货源集合中的货源总数;
属性标签集合单元,用于将每个货源的属性标签集合表示为t=[t1,t2,…,ti,…,tm];其中,ti表示该货源的第i个属性标签;i=1,2,…,m,m为货源的属性标签总数;
喜好特征向量获取单元,用于结合历史货源集合单元和属性标签集合单元,将该用户对货源dj的喜好的特征向量表示为:dj=[w1j,w2j,…,wij,…,wnj];其中,wij表示第j个货源的第i个属性标签在货源dj中所占的权重大小;其中,wij的计算公式如公式(4)所示:
偏好特征向量获取单元,用于把司机与历史货源集合中所有货源对应的特征向量的平均值作为此司机的偏好特征向量w;即,w=[w1,w2,…,wi,…,wm];其中,表示司机对第i个属性标签的偏好值,将司机对所有历史货源的第i个属性标签的权重大小的平均值作为其对第i个属性标签的偏好值,即
相似度计算模块14中,针对某个司机和某个新货源之间的偏好向量r,计算公式如式(5)所示:
r=[x1,x2,…,xi,…,xm](5)
上式中,xi为该司机对该货源的第i个属性标签的偏好值,xi的值等于该司机的偏好特征向量中的wi的值。
相似度计算模块14中,采用余弦相似度计算公式,计算各司机和各个新货源之间的相似度值时;针对司机s和某个新货源a之间的相似度值rsa的计算公式如式(6)所示:
上式中,ai表示司机s对货源a的第i个属性标签的偏好值;bi为新货源a对于第i个属性标签的权重定义值,为预设值。
本发明的有益效果是:本发明所提出的技术方案可以优选匹配度高的司机进行通知,以此提高成单率和叫车效率。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!