一种神经网络电影知识智能对话方法与流程
本发明涉及一种神经网络电影知识智能对话方法,属于自然语言处理对话领域。
背景技术:
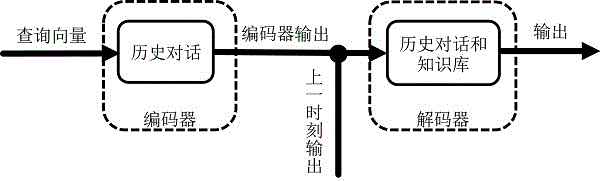
:电影产业的不断发展,产生了海量的电影数据。这为研究有关电影知识对话方法提供了丰富的数据支持。传统的任务型对话系统是由几个流水线模块构成的:(1)自然语言理解(naturallanguageunderstanding,nlu),理解给定的语句并将其映射到预定义的语义槽中,用来检测用户意图。(2)对话状态跟踪器(dialoguestatetracking,dst),它管理每个回合的输入以及对话历史并输出当前对话状态。(3)对话政策学习(dialoguepolicylearning,dpl),它根据当前的对话状态学习下一个动作。(4)自然语言生成(naturallanguagegeneration,nlg),它将选定的操作映射到其表面并生成响应。但是传统的任务型对话系统存在几个问题:一个是信用分配问题,其中最终用户的反馈很难传播到每个上游模块。第二个问题是在将一个组件调整到新环境或使用新数据重新训练时,需要相应地调整所有其他组件以确保全局优化,插槽和功能可能会相应更改。这个过程需要大量的人力。端到端的面向任务的对话系统能够直接在对话数据上对模型进行训练,循环神经网络(recurrentneuralnetwork,rnn)为端到端的模型做出来巨大贡献,因为他们能联系上下文信息,创建潜在的状态表示,免去了人工判断状态标签。端到端的记忆神经网络(memorynaturalnetwork,memnn)及其变体在阅读理解任务上表现出了良好的效果。他们的输出是生成的一个序列或者是通过选择一组预定义的话语。序列到序列(seq2seq)模型用于面向任务的对话系统时,表现出更好的语言建模能力,但它们在知识库检索中不能很好地工作。即便使用复杂的注意力模型,seq2seq也无法将正确的实体映射到输出。为了缓解这个问题,gu,jiatao,eric,mihail等人使用了复制增强的seq2seq模型。这些模型通过直接从知识库复制相关信息来输出响应。复制机制也被用于阅读理解,机器翻译和自动摘要等。虽然与对话系统无关,但与本发明工作相关的是基于memnn的解码器和非循环生成模型:1)用于访问存储器的mem2seq查询生成阶段可被视为存储器增强神经网络(mann)中使用的存储控制器。然而,电影知识对话模型与这些模型的不同之处在于:它结合复制机制使用多跳注意,而其他模型使用单个矩阵表示。2)仅依赖自我注意机制的非复发生成模型与memnn中使用的multi-hops注意机制有关。另外,神经知识扩散模型(naturalknowledgediffusion,nkd)中为了增加生成响应的多样性,在解码器部分增加了一个控制门。技术实现要素:本发明针对电影知识对话的特点:1)响应中涉及大量的专有名词(如人名,地名等);2)一条响应中可能涉及到多条知识,提出了一种神经网络电影知识智能对话方法。为达到上述目的,本发明采用如下技术方案:一种神经网络电影知识智能对话方法,具体操作步骤如下:1)将收集的电影数据,以三元组的形式存储成电影知识库,并构建电影知识对话数据集;2)用记忆神经网络编码器将历史对话编码;3)将门控循环单单元(gru)与记忆神经网络编码器结合,用gru的隐藏状态作为记忆神经网络的动态查询向量,直到响应生成。所述步骤1)先将收集到电影知识存储成知识三元组的形式,再通过模板填充的方式构建电影知识对话数据集。所述步骤2)中的编码器是标准的相邻权重复制模式的memnn;编码器的输入是分词后的历史对话,嵌入矩阵将输入的历史对话编码成两个向量mi,ci,u是查询向量q的嵌入表示,接着计算u和记忆向量m的匹配程度pi:pi=softmax(utmi)(1)第k层输出向量为ok:ok=∑ipici(1)下一层输入uk+1为当前层的输出ok和当前层查询向量uk的加和,如公式(3)所示:uk+1=uk+ok(2)所述步骤3)中的解码部分用了rnn的变体gru和memnn;因为要生成适当的响应,既需要用到历史对话的信息也要用到知识库的信息,所以解码器中memnn存储的信息为历史对话和相关的知识三元组,gru被用来作为memnn的动态查询向量,对于每一步gru的输入为上一时刻的输出和上一时刻生成的查询向量,如公式(4)所示:其中ht作为查询向量传递给memnn,是memnn生成单词,其中查询向量ht初始化为编码器的输出向量o,在每个时刻,都有两个概率分布产生,一个是所有词汇的概率分布(pvocab),另一个是包含历史对话和知识三元组的所有记忆内容的概率分布(pptr),因为我们更倾向于产生比较松散的词汇表的概率分布,所以在第一跳的时候产生pvocab,更具体的讲,在第一跳的时候我们的注意力将放在检索记忆内容;由于我们倾向产生一个更加清晰明确的pptr概率分布,所以在第三跳的时候产生pptr的概率分布,具体来说,最后一跳会选择受指针监督的清晰具体的词汇;具体的pvocab的计算如公式(5)所示:其中,w1是训练的权重参数,pptr的计算如公式(6)所示:解码器通过指向memnn中的输入字来生成词汇,这与指针网络中使用的注意力类似。控制门:若生成的词汇不在记忆内容中,pptr产生休止符‘#’。一旦休止符被选中,模型就会从pvocab分布中生成词汇,反之休止符没有被选中,则产生的词汇来源于记忆内容中。所以休止符就相当于一个硬门,控制着每一时刻输出的词汇应该从词汇表中产生还是从记忆内容中产生。鉴于电影数据一个属性可能有多个属性值的特点,mem2seq方法产生的响应会出现实体被过度使用的情况,因此,如果知识库中的某个词被指针选中输出后,就减小该词出现的概率,我们提出一种解决方法:在解码器输出部分加上一个控制门,把已经输出过的知识库中的实体的概率乘上一个非常小的系数来降低它的概率,以保证在前面出现过的实体词,不会在后面出现,增加响应的多样性。与现有技术相比,本发明具有如下的突出的实质性特点和显著的优点:本发明方法首先构建电影知识库和电影知识对话数据集,然后编码器部分采用3-hops记忆神经网络,用来计算输入问题与历史对话的相似度;最后,解码器部分将gru和3-hops记忆神经网络相结合,用gru的隐藏状态作为3-hops的动态查询向量,指导响应生成。结果显示本发明方法不仅解决了生成无意义响应的问题,又能保证生成响应的多样性。附图说明图1是电影知识对话方法的整体流程图。图2是基于3-hops记忆神经网络的编码器网络结构图。图3是基于3-hops记忆神经网络和gru的解码器网络结构图。图4是生成结果两组示例。具体实施方式本发明的优先实施例结合附图说明如下:一种神经网络电影知识智能对话方法,整体方法流程如图1,具体操作步骤如下:1)将收集的电影数据,以三元组的形式存储成电影知识库,并构建电影知识对话数据集;电影知识库数据:本实施例一共采集了21098条电影数据,每条电影数据包含电影名称,电影id,导演,演员,类型,产地,上映时间等属性。将这些数据按照知识三元组的形式存储,即(主体,关系,客体)的形式。电影知识对话数据:在电影知识数据的基础上,以字符串相加的方式生成。部分问题模板如表1所示:表1电影知识库及电影知识对话示例这些问题涉及了电影的导演,演员,类型,产地,上映时间等信息,每组对话有5轮,我们一共生成了10000组对话,如表2所示:图2数据集大小实体每组对话论数对话组数783596510000此数据集易于扩展,可以更换不同的模板来生成新的对话,例如:模板一:用户:<电影名字>的导演是谁?响应:<电影名字>的导演是<导演名字>用户:它是谁演的?响应:是<演员1>,<演员2>,<演员3>,<演员4>用户:它是什么类型的?响应:<类型1>,<类型2>用户:什么时候上映的?响应:<上映时间>用户:哪里产的?响应:<地区1>/<地区2>模板二:用户:<电影名字>的谁导的?响应:<电影名字>的导演是<导演名字>用户:它的演员有谁啊?响应:是<演员1>,<演员2>,<演员3>,<演员4>用户:大概是什么类型的?响应:<类型1>,<类型2>用户:什么时候出的?响应:<上映时间>用户:哪个国家的?响应:<地区1>/<地区2>2)用记忆神经网络编码器将历史对话编码;如图2所示,编码器是标准的相邻权重复制模式的memnn;编码器的输入是分词后的历史对话,嵌入矩阵将输入的历史对话编码成两个向量mi,ci,u是查询向量q的嵌入表示,接着计算u和记忆向量m的匹配程度pi:pi=softmax(utmi)(1)第k层输出向量ok为:ok=∑ipici(6)下一层输入uk+1为当前层的输出ok和当前层查询向量uk的加和,如公式(3)所示:uk+1=uk+ok(7)3)将gru与记忆神经网络编码器结合,用gru的隐藏状态作为记忆神经网络的动态查询向量,直到响应生成。如图3所示,解码部分用了rnn的变体gru和memnn;因为要生成适当的响应,既需要用到历史对话的信息也要用到知识库的信息,所以解码器中memnn存储的信息为历史对话和相关的知识三元组,gru被用来作为memnn的动态查询向量,对于每一步gru的输入为上一时刻的输出和上一时刻生成的查询向量,如公式(4)所示:其中ht作为查询向量传递给memnn,是memnn生成单词,其中查询向量ht初始化为编码器的输出向量o,在每个时刻,都有两个概率分布产生,一个是所有词汇的概率分布(pvocab),另一个是包含历史对话和知识三元组的所有记忆内容的概率分布(pptr),因为我们更倾向于产生比较松散的词汇表的概率分布,所以在第一跳的时候产生pvocab,更具体的讲,在第一跳的时候我们的注意力将放在检索记忆内容;由于我们倾向产生一个更加清晰明确的pptr概率分布,所以在第三跳的时候产生pptr的概率分布,具体来说,最后一跳会选择受指针监督的清晰具体的词汇;具体的pvocab的计算如公式(5)所示:其中,w1是训练的权重参数,pptr的计算如公式(6)所示:解码器通过指向memnn中的输入字来生成词汇,这与指针网络中使用的注意力类似。控制门:若生成的词汇不在记忆内容中,pptr产生休止符‘#’。一旦休止符被选中,模型就会从pvocab分布中生成词汇,反之休止符没有被选中,则产生的词汇来源于记忆内容中。所以休止符就相当于一个硬门,控制着每一时刻输出的词汇应该从词汇表中产生还是从记忆内容中产生。鉴于电影数据一个属性可能有多个属性值的特点,mem2seq方法产生的响应会出现实体被过度使用的情况,因此,如果知识库中的某个词被指针选中输出后,就减小该词出现的概率,我们提出一种解决方法:在解码器输出部分加上一个控制门,把已经输出过的知识库中的实体的概率乘上一个非常小的系数来降低它的概率,以保证在前面出现过的实体词,不会在后面出现,增加响应的多样性。类似的方法在文献中也使用过。记忆内容:本文把历史对话分词后存储成<单词对话轮数说话者身份>的结构,例如,“让子弹飞t1$u”表示用户在第一轮对话中说了“让子弹飞”这个词。对于知识库,本文的存储方式如表1,例如,当指针选择“让子弹飞||导演||姜文”时,“姜文”被作为响应输出。在每组对话中,只有与该组对话相关的知识才会被加载到内存中,减少了冗余数据,大大加快了计算时间。最后,解码器生成结果如图4所示。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1