基于SDAE和改进GWO-SVM的轴承缺陷识别方法与流程
本发明属于故障识别领域,特别涉及一种基于sdae和改进gwo-svm的轴承缺陷识别方法。
背景技术:
据统计,在机械设备发生的各类故障中,轴承故障占据30%的比重。如果故障发生在大型的舰船装备上,会造成重大安全事故和经济损失;如果故障发生在航空发动机上,可能会造成空中停车,机毁人亡的惨剧。及时的发现轴承的故障缺陷,为维修人员提供可靠设备缺陷信息,以制定合理的维修策略能够减少事故发生概率,提高设备的使用寿命和生产效率。
传统的缺陷识别方法和手段对单一系统故障发挥很好的作用,但对于复合型故障以及大型装备诊断效果不佳。而人工智能诊断不依赖具体的诊断对象和特定的数学模型,只通过学习历史数据训练缺陷识别模型,再结合在线数据实现对缺陷类型的判断和定位,从而实现大型装备的在线诊断。由于复杂系统的智能故障诊断往往需要更多的抽象,因此需要更深层的网络。
目前,设备的缺陷识别大多是通过监测与设备相关的振动信号等参数,并利用特征提取、信息融合和模式识别等方法来完成。例如用小波变换和支持向量机实现故障诊断,以及使用核主元分析和支持向量机实现缺陷识别。但是,上述两种方法只对单一振动信号进行分析,而振动信号往往是多个信号的混叠,受其他信号干扰较大,因此难以提取有效特征。将小波分析和d-s证据理论结合实现缺陷识别,以及将小波包、核主成分分析和svm结合,实现转子和轴承的缺陷识别,这两种方法是将振动信号和电流信号相结合,以弥补单一信号存在的缺点,但是其特征提取过程需要大量的先验知识、丰富的信号处理理论和实际经验作为支撑,而且将特征的提取过程和缺陷识别过程进行了完全隔离,使数据特征提取和模型训练失去联系。
近年来,svm在各种分类和回归问题中的应用越来越多,能解决设备数据小样本的学习问题和评估结果不确定性问题。但是svr的泛化能力主要由惩罚系数c、核函数参数σ决定,两个参数的选择会影响其识别率。采用遗传算法和粒子群算法等智能优化算法及其改进算法是目前优化svm参数的常用方法。
灰狼优化算法(greywolfoptimizer,gwo)由澳大利亚格里菲斯大学学者mirjalili等人于2014年提出来的一种群体智能优化算法。该算法模拟自然界中灰狼群体等级制度和捕食行为,通过群体搜索、包围和追捕攻击猎物等过程达到高效寻优的目的。因此这种方法适用于svm参数寻优。但是标准gwo算法存在后期收敛速度慢、易陷入局部最优,识别精度不高等特点,因此需要对其进行改进。
技术实现要素:
本发明要解决的技术问题是提供一种能够提高其收敛速度和识别精度,并解决其易陷入局部最优的缺点的基于sdae和改进gwo-svm的轴承缺陷识别方法。
为解决上述技术问题,本发明的技术方案为:一种基于sdae和改进gwo-svm的轴承缺陷识别方法,其创新点在于:包括以下步骤:
步骤1:收集轴承在正常情况和不同缺陷情况下的监测数据,并进行数据预处理,将处理后的数据进行特征提取和归一化处理,并把预处理后的每一类特征按照一定的比例随机分为训练样本和测试样本;
步骤2:建立一个网络层数为4的堆叠去噪自编码网络sdae,用于对训练数据和测试数据进行特征提取,并训练初始堆叠去噪自编码网络sdae;
步骤3:建立改进gwo-svm分类器模型,并将经过初始堆叠去噪自编码网络sdae提取的最深层数据特征作为gwo-svm分类器输入训练该分类器;
步骤4:利用反向传播bp算法对堆叠去噪自编码网络sdae参数进行微调,应用梯度下降算法进行权值的更新,并重新训练改进gwo-svm分类器,直到满足分类准确率;
步骤5:根据以上步骤得到基于sdae和改进gwo-svm分类器的数据提取和缺陷识别整体模型,利用该模型实现对轴承的深层特征提取和缺陷识别。
进一步地,所述步骤1中的数据进行特征提取,包括13个时域特征,4个频域特征和5个采用经验模态分解提取的时频域特征;其中,时域特征包括歪度、均值、方差、峰值、最小值、峰峰值、均方值7个有量纲时域特征,峭度、峰值因子、脉冲因子、波形因子、裕度因子、歪度因子6个无量纲的时域特征;频域特征包括均方频率、重心频率、频率方差、标准频率方差;时频域特征包括前4个imf能量指标和总能量指标。
进一步地,所述步骤2中4层堆叠去噪自编码网络sdae自下而上的结构为[44-22-11-5]:输入层的样本维数为22维,第一隐藏层神经元的个数为44,第二隐藏层神经元个数为22,第三隐藏层神经元个数为11,第四隐藏层神经元个数为5,输出层的样本维数为5;堆叠去噪自编码网络sdae的训练过程采用逐层堆叠学习,每个去噪自编码器dae无监督训练完成后,隐含层的输出作为下一个去噪自编码器dae的输入,即第一个去噪自编码器dae1训练完成;将隐藏层的数据特征1作为第二个去噪自编码器dae2的输入,对dae2进行无监督训练,得到数据特征2;将数据特征2作为第三个去噪自编码器dae3的输入,对dae3进行无监督训练,得到数据特征3;将数据特征3作为第三个去噪自编码器dae4的输入,对dae4进行无监督训练,得到数据特征4;特征数据4将作为gwo-svm分类器输入。
进一步地,在堆叠去噪自编码网络sdae中,在sdae最后一个特征表示层后添加改进gwo-svm分类器,训练完成的整个网络能够同时实现数据的特征提取和缺陷识别任务。
进一步地,所述步骤3中改进gwo-svm分类器模型利用改进后的灰狼算法gwo对svm惩罚因子c和核函数参数σ进行寻优,具体步骤如下:
步骤1:初始化改进gwo的参数,如种群规模n、最大迭代次数tmax、距离控制参数a的初始值ainitial和终止值afinal;初始化a、a、c;对种群进行初始化,得到n个初始灰狼位置x=[x1,x2,…,xn],其中xi=(ci,σi);
步骤2:计算种群每个个体适应度值,并对其排序,分别记录适应度最优的三个个体为α,β,δ,对应位置分别为xα,xβ,xδ;
步骤3:更新种群中其他灰狼个体的位置;
步骤4:更新收敛因子a和参数a、c的值;
步骤5:计算个体适应度f(xi(t)),并对灰狼种群进行降序排序,对排列在后10%的灰狼个体进行差分变异,计算变异后个体的适应度f(xi'(t)),比较变异前后的个体适应度,如果f(xi'(t))≥f(xi(t)),将变异后的灰狼个体代替变异前的个体,如果f(xi'(t))<f(xi(t)),保留变异前个体;
步骤6:判断是否达到最大迭代次数tmax,若没有达到tmax,则t=t+1,并返回步骤2,;若达到,则停止迭代,返回最优个体;
步骤7:根据最优的灰狼位置得到最优惩罚因子c和最优核函数参数σ,利用改进改进gwo-svm分类器进行缺陷识别。
进一步地,所述步骤1中种群初始化公式为:
其中
进一步地,所述步骤3中种群位置更新满足:
其中a和c是系数向量,xi(t)是当前个体位置,xi(t+1)是迭代更新后个体位置。
进一步地,所述步骤4中a更新满足:
t为当前迭代次数,随机变量λ=0.01;
系数向量a,c更新满足:
a=2a·r1-a
c=2·r2
其中r1和r2为[0,1]内的随机数。
进一步地,所述步骤5中差分变异公式为:
x'(t)=r[xα-x(t)]-r[xs(t)-x(t)],xs(t)其中为种群中随机选取的某一灰狼个体,r为[0,1]的随机数。
进一步地,所述步骤4中微调具体步骤如下:
步骤一:将训练样本输入预训练完成的初始堆叠去噪自编码网络sdae中,提取顶层特征,作为支撑改进gwo-svm分类器的训练样本,得到svm最优惩罚因子c和最优核函数参数σ;
步骤二:利用反向传播bp算法对网络参数进行微调,应用梯度下降算法进行权值的更新;
步骤三:将训练样本输入微调完成的堆叠去噪自编码网络sdae中,提取顶层特征,重新训练改进gwo-svm分类器,得到svm分类器的最优惩罚因子c和最优核函数参数σ;
步骤四:将顶层特征输入训练完成的最优svm分类器,判断是否满足终止条件,若满足,微调完成,停止迭代,sdae网络和改进gwo-svm分类器训练完成,若不满足,跳转到步骤二。
本发明的优点在于:本发明基于sdae和改进gwo-svm的轴承缺陷识别方法,采用堆叠去噪自编码网络sdae对数据进行特征提取,实现对高维深层故障特征的自适应挖掘,解决了轴承故障类型多、故障特征难以提取等问题并且sdae不仅学习到原始数据的特征,还能学习到被“破坏”后的退化特征具有更强的泛化性、鲁棒性;将数据特征提取和缺陷识别过程相结合,建立数据特征提取和缺陷识别过程的联系,解决了特征提取过程需要大量的先验知识、丰富的信号处理理论和实际经验作为支撑的缺点;对gwo算法进行改进,提高其收敛速度和识别精度并解决其易陷入局部最优的缺点,利用改进gwo对svm参数寻优,提高缺陷识别精度。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
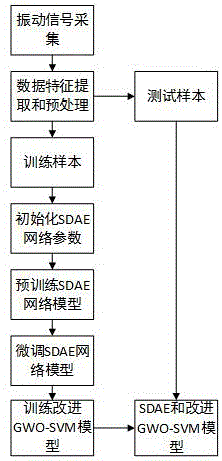
图1为本发明所述的一种基于sdae和改进gwo-svm的轴承缺陷识别方法流程图。
图2为本发明所述第一去噪自编码器的工作原理图。
图3为本发明所述的堆叠去噪自编码器sdae的结构图。
图4为本发明所述的堆叠去噪自编码器sdae微调流程图。
图5为本发明所述的改进gwo-svm流程图。
具体实施方式
下面的实施例可以使本专业的技术人员更全面地理解本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例
本实施例基于sdae和改进gwo-svm的轴承缺陷识别方法,如图1所示,主要包括以下步骤:
步骤1:收集轴承在正常情况和不同缺陷情况下的监测数据,并进行数据预处理,将处理后的数据进行特征提取,特征提取包括13个时域特征,4个频域特征和5个采用经验模态分解(emd)提取的时频域特征;其中时域特征包括歪度、均值、方差、峰值、最小值、峰峰值、均方值7个有量纲时域特征,(见表1);峭度、峰值因子、脉冲因子、波形因子、裕度因子、歪度因子6个无量纲的时域特征(见表2);频域特征包括均方频率、重心频率、频率方差、标准频率方差(见表3);时频域特征包括前4个imf能量指标和总能量指标。
表1有量纲时域特征参数
表2无量纲时域特征参数
表3频域特征参数
对以上数据进行归一化处理,对设备正常情况和不同的缺陷情况进行设定标签,每个标签对应各自的缺陷状态,并把预处理后的每一类特征按照一定的比例随机分为训练样本和测试样本。
步骤2:建立一个网络层数为4的堆叠去噪自编码网络sdae,用于对训练数据和测试数据进行特征提取,并训练初始堆叠去噪自编码网络sdae。
步骤3:建立改进gwo-svm分类器,并将经过初始堆叠去噪自编码网络sdae提取的最深层数据特征作为gwo-svm分类器输入训练该分类器。
步骤4:利用反向传播bp算法对网络参数进行微调,应用梯度下降算法进行权值的更新,并重新训练改进gwo-svm分类器,直到满足分类准确率。
步骤5:根据以上步骤得到基于sdae和改进gwo-svm分类器的数据提取和缺陷识别整体模型,利用该模型实现对轴承的深层特征提取和缺陷识别。
结合图2,图3所示,第一去噪自编码器由编码器、解码器和隐含层组成;去噪自编码器通过映射x′~qd(x′|x)对原始输入x添加一个随机噪声,数据集d通过加入噪声q,得到受损样本x',其中d为数据集,q为随机噪声;此时编码器输入为受损样本,通过编码函数fθ映射到隐含层y,可表示为:
y1=fθ1(x')=s(w1x'+b1)(1)
其中s为映射函数,w1是第一去噪自编码器的编码权值,b1是第一去噪自编码器的编码偏置,θ1是第一去噪自动编码机预训练好的编码参数;第一去噪自编码器隐含层的输出y1经过解码函数进行重构:
z1=gθ1'(y1)=s'(w1'y+b1')(2)
其中s'为映射函数,w1'是第一去噪自编码器的解码权值,b1'是第一去噪自编码器的解码偏置,θ1'是第一去噪自动编码机的解码参数。对于每一个输入xi映射到一个y1i,然后得到重构函数z1i,再不断地优化所有参数,最小化输入和重构解码的误差可得:
l(xi,z1i)=||xi-z1i||2(3)
第二去噪自编码器、第三去噪自编码器、第四去噪自编码器的工作原理均与第一去噪自编码器的工作原理相同。
实施例中,步骤2的4层堆叠去噪自编码网络sdae自下而上的结构为[44-22-11-5]:输入层的样本维数为22维,第一隐藏层神经元的个数为44,第二隐藏层神经元个数为22,第三隐藏层神经元个数为11,第四隐藏层神经元个数为5,输出层的样本维数为5;堆叠去噪自编码网络sdae的训练过程采用逐层堆叠学习,每个去噪自编码器dae无监督训练完成后,隐含层的输出作为下一个去噪自编码器dae的输入,即第一个去噪自编码器dae1训练完成;将隐藏层的数据特征1作为第二个去噪自编码器dae2的输入,对dae2进行无监督训练,得到数据特征2;将数据特征2作为第三个去噪自编码器dae3的输入,对dae3进行无监督训练,得到数据特征3;将数据特征3作为第三个去噪自编码器dae4的输入,对dae4进行无监督训练,得到数据特征4;数据特征4将作为gwo-svm分类器输入。
结合图4所示,堆叠去噪自编码网络sdae微调过程为以下步骤:
步骤一:将训练样本输入预训练完成的初始堆叠去噪自编码网络sdae中,提取顶层特征,作为支撑改进gwo-svm分类器的训练样本,得到svm最优惩罚因子c和最优核函数参数σ;
步骤二:利用反向传播bp算法对网络参数进行微调,应用梯度下降算法进行权值的更新;
步骤三:将训练样本输入微调完成的堆叠去噪自编码网络sdae中,提取顶层特征,重新训练改进gwo-svm分类器,得到svm分类器的最优惩罚因子c和最优核函数参数σ;
步骤四:将顶层特征输入训练完成的最优svm分类器,判断是否满足终止条件,若满足,微调完成,停止迭代,sdae网络和改进gwo-svm分类器训练完成,若不满足,跳转到步骤二。
结合图5所示,改进gwo-svm分类器利用改进后的灰狼算法gwo对svm惩罚因子c和核函数参数σ进行寻优,具体步骤如下:
步骤1:初始化改进gwo的参数,灰狼种群规模n、最大迭代次数tmax、距离控制参数a的初始值ainitial和终止值afinal;初始化参数a、a、c;假设第i(i=1,...,n])匹狼在第t次迭代的的位置为xi(t),灰狼群体中按等级机制从高到低可以分为首领狼α、副首领狼β、队长狼δ和其余个体狼ω;利用以下公式对所有灰狼个体进行初始化:
其中
步骤2:计算种群每个灰狼个体适应度值f(xi(t)),并对其排序,分别记录适应度最优的三个个体为α,β,δ,对应位置分别为xα,xβ,xδ,对应适应度值为f(xα(t)),f(xβ(t)),f(xδ(t))。
步骤3:更新种群中其他灰狼个体的位置且位置更新满足:
其中a和c是系数向量。
步骤4:更新收敛因子a和参数a、c的值,更新满足:
t为当前迭代次数,随机变量λ=0.01。
a=2a·r1-a(10)
c=2·r2(11)
其中,r1和r2为[0,1]内的随机数。
步骤5:计算灰狼个体适应度f(xi(t)),并对灰狼种群进行降序排序,对排列在后10%的灰狼个体进行差分变异:
xi'(t)=r[xα-xi(t)]-r[xs(t)-xi(t)](12)
其中xs(t)为种群中随机选取的某一灰狼个体,r为[0,1]的随机数。计算变异后个体的适应度f(xi'(t)),比较变异前后的个体适应度,如果f(xi'(t))≥f(xi(t)),将变异后的灰狼个体代替变异前的个体,如果f(xi'(t))<f(xi(t)),保留变异前个体。
步骤6:判断是否达到最大迭代次数tmax,若没有达到tmax,则t=t+1,并返回步骤2;若达到,则停止迭代,返回最优个体;
步骤7:根据最优的灰狼位置得到最优惩罚因子c和最优核函数参数σ,利用改进改进gwo-svm分类器进行缺陷识别。
以上显示和描述了本发明的基本原理和主要特征以及本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!