用于低周期存储器访问和附加功能的宽边随机访问存储器的制作方法
相关申请的交叉参考
本申请要求于2018年5月30日提交的美国临时申请号62/677,878和2018年12月30日提交的美国临时申请号62/786,479的优先权,这两个申请通过引用全文并入本文。
本公开总体上涉及一种工业控制子系统,该工业控制子系统可以形成为集成电路的一部分,诸如数字信号处理器(dsp)、片上系统(soc)、专用集成电路(asic)或现场可编程门阵列(fpga)。更具体地,本公开涉及此种工业控制子系统的宽边(broadside)随机访问存储器(bs-ram)部件。
背景技术:
跨不同工业和细分市场存在许多不同的通信协议,以解决用于在专有开发的处理装置(诸如soc、dsp、asic和fpga)上运行的数据交换的实时通信。尝试提供能够以适合工业用例的速度进行任务切换,同时保持根据多种协议进行通信的灵活性的处理装置并不是令人满意的。因此,在本领域中存在改善的空间。
技术实现要素:
本公开的至少一个示例包括一种计算装置,该计算装置包括:处理器,该处理器具有寄存器;耦合到寄存器的接口;以及耦合到接口的宽边随机访问存储器(ram),其中接口被配置为在处理器的单个时钟周期中将加速器状态数据加载到寄存器;该接口还被配置为当处理器执行存储操作时,使32字节的信息能够在处理器的三个时钟周期内存储在宽边ram中或从宽边ram中检索;以及其中处理器被配置为在执行存储操作期间对32字节的信息的至少一部分执行一个或多个数学运算。
本公开的至少一个另外示例包括计算机实现的方法,该方法包括:在耦合到寄存器的处理器的单个时钟周期中,使用接口将加速器状态数据加载到寄存器;使用处理器执行存储操作,其中执行存储操作包括:在少于处理器的四个时钟周期的情况下,将32字节的信息存储到耦合至接口的ram中;以及在执行存储操作期间,使用处理器对32字节的信息的至少一部分执行一个或多个数学运算。
本公开的至少一个另外示例包括片上系统,该片上系统包括:可编程实时单元,该可编程实时单元包括寄存器;耦合到寄存器的接口电路;以及耦合到接口电路的随机访问存储器(ram),其中接口电路被配置为在可编程实时单元的单个时钟周期中将加速器状态数据加载到寄存器;接口电路还被配置为当可编程实时单元执行存储操作时,使32字节的信息能够在可编程实时单元的一个时钟周期内存储在ram中或从ram中检索;以及其中可编程实时单元被配置为在执行存储操作期间对32字节的信息的至少一部分执行一个或多个数学运算。
附图说明
现将参考附图用于详细描述各种示例,在附图中:
图1示出了具有根据本公开的架构的系统的示例的框图;
图2a至图2c示出了结合来自图1的许多部件的示例工业通信子系统;
图3示出了图2a至图2c的处理器与共享存储器之间的示例关系;以及
图4示出了图2a至图2c的处理器与宽边ram之间的示例关系。
具体实施方式
下面描述本公开的一个或多个具体示例。这些示例仅是当前公开的技术的示例。另外,为了提供对这些示例的简要描述,可能未在说明书中描述实际实施方式的所有特征。在任何此类实施方式的开发中(如在任何工程或设计项目中),都会做出许多特定于实施方式的决策,以实现开发人员的特定目标,诸如遵守与系统相关的约束和与业务相关的约束,这些约束可能因实施方式而异。此外,应当理解,此类开发工作可能是复杂且耗时的,但是对于受益于本公开的普通技术人员而言,这将是设计、制作和制造的例行任务。
当介绍本公开的各种示例的要素时,冠词“一”、“一个”和“该”旨在表示存在要素中的一个或多个。术语“包括”、“包含”和“具有”旨在是包括性的,并且意味着除所列要素外,还可以有其他要素。下面讨论的示例旨在本质上是说明性的,并且不应解释为意味着本文所述的特定示例本质上是优选的。
在本公开中描述的示例既不是相互排斥的也不是集体穷举的。对“一个示例”或“示例”的引用不应被解释为排除也结合所叙述特征的其他示例的存在。
当在本文中使用时,术语“介质”涉及一种或多种非暂时性物理介质,其一起存储被描述为存储在其上的内容。示例可以包括非易失性辅助存储装置、只读存储器(rom)和/或随机访问存储器(ram)。
如本文所用,术语“应用程序”和“功能”指代一个或多个计算模块、程序、过程、工作负载、线程和/或由计算系统执行的一组计算指令。应用程序和功能的示例实施方式包括软件模块、软件对象、软件实例和/或其他类型的可执行代码。
如前所述,跨不同工业和细分市场开发了许多不同的通信协议,以解决用于在专用开发的处理装置(诸如soc、dsp、asic和fpga)上运行的数据交换的实时通信。本公开的示例针对提供和/或实现用于此类处理装置之间的通信的多协议灵活性。本公开的至少一个示例涉及以1千兆位/秒或更快的速度提供和/或实现实时以太网通信。
本公开的至少一个示例是用于工业通信子系统(icss)的架构,其解决了多协议通信的灵活性要求和实时千兆以太网的性能要求。通过集成到目录处理器上,该架构使工业通信像标准以太网一样容易。icss具有混合架构。在至少一个示例中,icss包括四个32位精简指令集计算机(risc)核心,这些核心称为可编程实时单元(pru),其与一组紧密集成的硬件加速器耦合。在本公开内,硬件加速器包括专门制造的硬件,以比使用在通用中央处理单元(cpu)上运行的软件可能实现的功能更有效地执行一些功能。精简指令集计算机(risc)是这样的计算机,其指令集架构(isa)使其与复杂指令集计算机(cisc)相比,每条指令的周期(cpi)更少。
本文所述的128/256千兆位/秒数据传递与4纳秒(ns)的确定性编程分辨率的组合是对通信接口的高度区分的方法。在图2a至图2c中提供了与128/512千兆位/秒数据总线架构相组合的硬件加速器的详细视图。这些加速器可具有多个状态,并且对应于那些状态的数据可在单个时钟周期中加载到pru寄存器中。
本公开的示例涉及可编程实时单元(pru)子系统和工业通信子系统(icss),其由双32位risc核心(pru)、数据和指令存储器、内部外围模块和中断控制器(intc)组成。pru-icss的可编程性质及其对引脚、事件和所有soc资源的访问权限在实现快速实时响应、专用数据处理操作、自定义外围接口中并在卸载来自soc的其他处理器核心的任务中提供了灵活性。
对于工业以太网使用情况,本公开的示例icss在可编程性(灵活性)与保持线速分组负载的需求之间提供了平衡。在至少一个示例中,pru基于250mhz时钟运行,并因此在一些情况下,固件预算被限制为每个分组大约84个周期(对于最小大小的传输和接收帧)。对于在1ghz速率处理的完全802.1d兼容分组,此预算可能不足。因此,示例icss包括用于耗时的桥接任务的硬件加速器,诸如宽边(bs)512位/1024位硬件加速器和宽边随机访问存储器(bs-ram)。
根据公开的示例,pru微处理器核心具有到外部存储器的加载/存储接口。使用数据输入/输出指令(加载/存储),可以从外部存储器读取数据或将数据写入外部存储器,但是以在访问发生时使核心停顿为代价。常规地,读取n个32位字通常需要3+n个周期,而写入则需要大约2+n个周期。对于某些应用程序,这些读取和写入速率太慢(例如,读取32字节可能需要大约11个周期)。本公开的示例解决了这些问题。
根据所公开的实施例,可编程核心还具有宽的寄存器加载/存储/交换接口(称为宽边),其允许对于加速器的一个周期访问。固件使用一组特殊的指令(xin/xout/xchng)(它们使用宽边标识符、用于传递的起始寄存器以及要传递的字节数作为参数)以访问此接口。我们的解决方案是将ram附接到该宽边接口。通过这种方法,固件可以以少得多的周期将32字节的数据传递到ram或从ram传递该数据;通常,存储32字节花费1-2个周期,并且加载32字节花费2-3个周期。
在至少一个示例中,针对32字节的宽传递,优化了宽边ram和/或宽边接口。通过将大小填充到32字节,可以支持较低的传递宽度。在至少一个示例中,首先使用xout宽边指令将读取位置写入到附接的ram,并然后使用xin宽边指令读取数据。因此,读取操作将始终花费两个周期。对于写传递,地址被放置在紧接着保存32字节数据的寄存器的寄存器中,并且数据加地址在一个xout指令中传递到附接的ram。在至少一个示例中,该方法具有额外的优点,即还能够对数据执行操作,这可能与传递并行。
除了在传统系统中将写入速度提高至少十倍,并且在32字节传递中将读取速度提高五倍外,本公开的示例还提供了优点诸如宽边(bs)接口的能力,以在本地存储由bs接口最后访问的ram地址,这允许自动递增操作模式,因此固件不必不断更新地址(对于批量读取特别有用)。本公开的示例使得能够使用该接口与写入操作并行地对数据进行有用的操作。例如,直通(cut-through)数据可以通过校验和电路运行以计算分组的运行校验和,同时将分组存储在ram中。在至少一个示例中,处理器可以以各种数据大小边界对分组内的数据执行字节序翻转。在至少一个示例中,可以使用bs接口执行数据枢转(pivot)/交换操作,例如以将寄存器r2-r5与r6-r9交换。当在具有不同块大小的接口之间移动数据时(例如,从32字节的先进先出(fifo)接收器(rx)fifo到16字节的分组流接口),数据枢转/交换操作非常有用。在至少一个示例中,通过使用不同的bs标识符(id)(宽边指令的参数)将组织与附接的存储器相关联,或通过不同的固件任务启用独立的存储器“视图”。宽边id可以映射到不同的读或写存储器地址(由胶合逻辑维护),使得数据结构,诸如先进先出(fifo)和队列可以通过附接的ram以灵活的和固件管理的方式实现。至少一个示例利用嵌入式处理。在至少一个示例中,ram和宽边接口之间的胶合逻辑本地存储最后访问的ram地址,其允许自动递增操作模式,使得pru的固件不必不断更新ram地址。pru的自动递增模式可用于批量数据读取。
在本公开的至少一个示例中,硬件部件可访问宽边ram以执行诸如创建一个或多个转发数据库之类的操作。
在本公开的至少一个示例中,硬件过滤器和分类器使得能够以最小的网桥延迟来接收和转发与分组有关的决策。在一个示例中,内容、时间窗口和数据速率的组合为以太网桥接提供了强大的入口分类,同时保持了最小的网桥延迟。本公开的示例实现了小于微秒的网桥延迟。
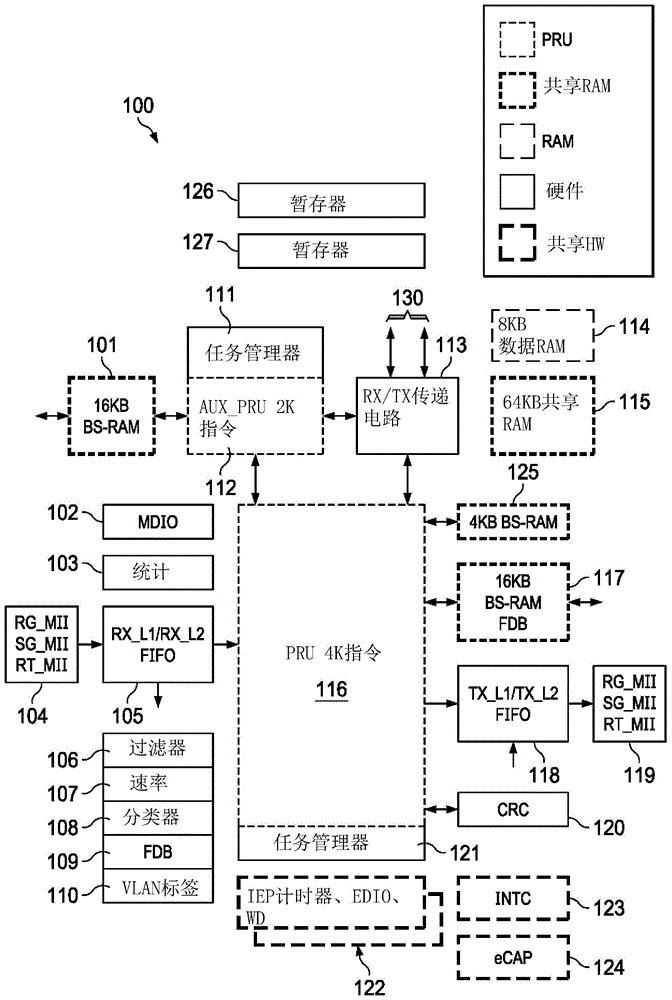
图1是根据本公开的一个示例的基于icss架构的系统100(其可以是soc130的部件)的功能框图。在图1中,16千字节的宽边随机访问存储器(bs-ram)101耦合到aux_pru112(与其信号通信)。bs-ram101经由aux_pru112耦合到pru116。bs-ram101可以在系统100的一个时钟周期中传递32字节的数据。bs-ram101具有超高带宽和超低等待时间。在本公开内,耦合的部件(例如,电路)能够彼此通信。连接的部件是经由直接连接或间接连接被耦合的那些部件。在本公开内,除非提供相反的指示,否则彼此耦合的部件也是连接的。
如图1所示,通过接口电路104(其为实时接口)传入的数据转到fifo接收电路105。当数据通过接收电路105时,分类器108被应用于该传入数据。过滤器106、速率计数器107和分类引擎108的组合逻辑被应用于接收到的数据分组。
管理数据输入/输出(mdio)电路102是媒体接口。mdio电路102使用pru116与外部简化的千兆位媒体独立接口(rgmii)物理层和媒体独立接口(mii)物理层(接口电路104、接口电路119)通信。mdio电路102具有低等待时间并且专用于pru116。如图1所示,系统100还包括统计计数器电路103,其跟踪实时接口电路104的以太网端口的统计信息,诸如分组大小、错误等。包括rgmii、串行千兆位媒体独立接口(sgmii)和实时媒体独立接口231、259(rtmii)的实时接口电路104是连接到系统100的输入/输出(io)诸如mdio电路102的硬件层。实时接口电路104耦合到fifo接收电路105,其包括一级先进先出(fifo)接收层(rx_l1)和二级fifo接收层(rx_l2)。fifo接收电路105可以接收一级fifo数据和二级fifo数据。
如上所述,系统100包括过滤器106,其为用于八个过滤器类型1数据流和/或十六个过滤器类型3数据流的过滤器。过滤器106确定给定的数据分组是否为数据分组的特定“类型”。过滤器类型3数据分组具有可变的起始地址,取决于分组是否与虚拟lan通信。系统100还包括速率跟踪器107。在至少一个示例中,系统100包括八个速率跟踪器107。基于过滤器类型命中率,速率跟踪器107计算fifo接收电路105的吞吐率。系统100还包括过滤器数据库(fdb)109。fdb109用于路由和冗余。接收电路105包括一级接收层(rx_l1)和二级接收层(rx_l2),其包括物理接收端口。接收电路105的一级接收层(rx_l1)和二级接收层(rx_l2)可访问fdb109,以基于ieee802.1q学习桥模式1管理接收和转发决策。fdb109包含查找表(lut),其存储可给予pru116以帮助pru116做出数据路由决策的结果。在至少一个示例中,系统100还包括虚拟局域网标签(vlantag)电路110。(标签(也称为“id”)是分配给一条信息(诸如,互联网书签、数字图像、数据库记录、计算机文件或vlan)的关键字或术语。统计跟踪器103、过滤器106、速率跟踪器107、分类器108、fdb109和vlantag110是接收电路105的各个方面。
mdio电路102根据开放系统互连(osi)模型控制与系统的外部物理层(未示出)的交互。物理层将诸如媒体访问控制器(mac)的链路层装置(参见图2a的206(266)和220(290),以及图2c的266和290)连接到主机(例如246)装置/系统的物理介质,子系统200是主机的部件或子系统200与主机耦合。物理层包括物理编码子层(pcs)功能和物理媒体相关(pmd)层功能两者。soc130外部有收发器,其中嵌入了系统100。mdio电路102配置一个或多个外部物理层(未示出)并且用于使icss的等待时间最小化。
每个中央处理单元(cpu),诸如可编程实时单元116,都包括任务管理器电路(例如,任务管理器电路111)。在至少一个示例中,任务管理器电路111和任务管理器电路121可以识别200个或更多事件。事件对应于硬件状态信号,诸如来自过滤器106、来自速率跟踪器107或来自中断控制器123的硬件状态信号。aux_pru112负责控制。例如,基于起动器帧,pru-rtu112检测到新的分组将发送到数据处理器pru116,并且与数据处理器收集数据并行,pru-rtu112将根据发送到主机(130、246)的分组的需要设置每个分组的地址和直接存储器访问(dma)。在将数据推送到bs-ram117的同时,也可以将数据推送到校验和加速器诸如crc120。因此,crc120可以挂在bsram117之外。传递电路113与aux_pru112和pru116通信。如图1中的符号“rx/tx”所指示,传递电路113可以接收(rx)和传输(tx)信息。传递电路113配置有dma,其使得aux_pru112和pru116两者能够访问主系统100存储器。当aux_pru112或pru116启动事务时,传递电路113将管理到soc130存储器的数据移动,以拉取或推送数据。因此,传递电路113是可用于数据传递的一般资产。在至少一个示例中,在图1的架构中,当pru116推送数据时,aux_pru112可以控制地址位置。因此,该架构是灵活的,因为单个cpu例如(112、116)既不负责数据管理又不负责控制功能。
在至少一个示例子系统100中,存在具有本地存储器的结构。图1的示例子系统100中的结构可以是4字节宽。但是,有两组数据存储器114专用于每个cpu(例如112、116),并且另一组较大的存储器115在cpu(112、116)之间共享。数据存储器114可以与暂存器(scratchpad)126和暂存器127一起使用,而共享存储器115用于链路列表,该链路列表用于dma或用于存储元数据。暂存器126、127相似于bs-ram101、117。然而,暂存器126和暂存器127与bs-ram101和bs-ram117的不同之处在于暂存器126、127在切片之间共享(参见图2a的slice_0(切片-0)和图2c的slice_1),并且暂存器126、127比bs-ram101、117更灵活。暂存器(例如126、127)可以保存和/或恢复寄存器组。暂存器126、127可用于片对片通信并执行桶移位或将寄存器组重新映射到物理位置。bs-ram117类似于bs-ram101,例外的是bsram117还具有包括查找表的fdb。当分组进入接收电路105处的系统100时,硬件执行对fdb109的查找并将数据呈现给pru116。基于bs-ram117的fdb的响应,pru116做出路由决策,诸如,是否经由传递电路113将接收到的分组路由到主机和/或诸如通过传输电路118路由到不同的端口。pru116还访问bs-ram125。pru116充当交换机,而bsram117使动作能够同时执行。因此,bs-ram117是双重用途的部件。硬件可以连接到bs-ram117,而bs-ram117为pru116执行针对fdb109的查找。就像ram(例如114)被加载的同时可以由crc120执行校验和一样,当bs-ram125与硬件交互时,bs-ram117可以为pru116执行fdb操作。
传输电路118处理来自pru116的数据的外出。传输电路118执行抢占、标签插入和填充。传输电路118使固件能够干净地终止分组。此后,如果所讨论的分组很小,则任务管理器电路121将执行必要的步骤以生成最终的crc,并且传输电路118将执行填充。传输电路118可以插入标签,使得pru116不必跟踪分组。因此,传输电路118能够辅助soc130的硬件。传输电路118耦合到接口电路119。接口电路119是最终层。在传输电路118外部,存在不同的媒体无关接口,例如rgmii、sgmii和实时mii(参见104、119、225(295))。在本公开内,系统100上的其他类型的接口也是可能的。fifo传输电路118与此类接口无关。接口电路119是解复用器。接口电路119为传输电路118提供协议转换,使传输电路118并因此pru116能够以适合一件给定硬件的协议与该硬件进行通信。因此,pru116和传输单元118不被限制为以仅对应于一个协议的方式操作,使得pru116和传输电路118比不存在接口电路119时具有更多的通用性。在本公开的至少一个示例中,系统100查明接口电路119的数据流以连接到外部物理层。参考开放系统互连(osi)模型的级别,传输电路118具有一级fifo传输层(tx_l1)和二级fifo传输层(tx_l2)。一级(或“层”)对应于osi模型的物理层,并且二级对应于osi模型的数据链路层。这种双层连接提供了选项。例如,可以绕过二级fifo传输层(tx_l2),并且可以将数据发送到一级fifo传输层(tx_l1),这减少了等待时间。在至少一个示例中,与一级fifo传输层(tx_l1)相比,二级fifo传输层(tx_l2)具有更宽的接口。在至少一个示例中,二级fifo传输层(tx_l2)具有32字节的接口,而一级fifo传输层(tx_l1)具有4字节的接口。在至少一个示例中,如果在接收电路105处数据分组从一级接收层(rx_l1)到达二级接收层(rx_l2)272(257),并且pru116在二级接收层(rx_l2)访问该分组,则数据将被首先推送到fifo传输电路118的二级fifo传输层(tx_l2),并然后fifo传输电路118的硬件将数据分组直接推送到一级fifo传输层(tx_l1)。然而,在与超低等待时间接口(诸如ethercat)进行通信时,可以绕过二级fifo传输层(tx_l2);从pru116输出的数据可以直接推送到一级fifo传输层(tx_l1)(如上所述,其具有4字节的宽度)。
接口电路104和接口电路119连接到物理层(osi模型的“零级”)。因此,数据通过接口电路104以零级进入系统100,从零级移至fifo接收电路105的一级接收层(rx_l1)或fifo接收电路105的二级接收层(rx_l2)272(257),到pru116(存在于一级和二级两者处),并从pru116的一级或二级通过fifo传输电路118,并在接口电路119处降回到零级。在至少一个示例中,循环冗余校验(crc)电路120是加速器,其辅助pru116执行计算。pru116通过bs-ram117与crc电路120接合。crc电路120将哈希函数应用于pru116的数据。crc电路120用于验证数据分组的完整性。例如,所有以太网分组都包括crc值。crc电路120对分组执行crc校验以查看该分组的crc值是否与crc电路120所计算的结果一致。即,分组包括crc签名,并且在计算签名之后,结果与附接到分组的签名进行比较以验证分组的完整性。
系统100还包括中断控制器(intc)123。intc123聚合和cpu(例如,aux_pru112、pru116)级事件到主机(例如,130、146)事件。例如,可能有十个主机事件。intc123确定应将给定的一组从属级事件聚合、映射并分类为单个实体。单个实体可以被路由到pru116或任务管理器电路121并由其使用以引起主机(130、146)的事件。从这个意义上讲,intc123既是聚合器又是路由器。
增强/外部捕获(ecap)电路124是计时器,其使pru116能够基于与工业以太网外围装置(iep)电路122的时间匹配来生成输出响应,并捕获系统100外部事件的事件时间。
iep电路122具有两组独立的计时器,它们使得能够进行时间同步、加时间戳和服务质量以用于使数据从系统100外出。若干个独立的捕获电路与iep电路122相关联。例如,如果存在接收(rx)起动器帧事件,并且在特定时间将该帧推送到主机很重要,则iep电路122可以对该事件加时间戳以指示该特定时间。如果事件是用于出口电路118的时间触发的发送,则如果期望在精确的时间(2-3纳秒内)传递分组,则在计时器到期时独立于pru116而开始传输分组。因此,分组的传递有效地与pru116退耦。
除了所描述的计时器,iep电路122还包含增强的数字输入/输出接口(edio)。edio与通用输入/输出(gpio)接口类似,但更智能,并且针对以太网通信进行了更好的校准。例如,传输开始或接收开始的帧可能引起edio上的事件,其进而可能引起soc130外部的事件。同步输出和锁存是时间同步的一部分。iep120也可以接收帧并捕获模拟电压。在常规系统中,这将需要读取操作。但是使用edio,捕获可以被事件触发和/或时间触发,因此使捕获比常规系统中更精确。edio使系统100能够精确地确定传入帧何时到达,这继而使系统100能够对一个或多个特定值(诸如温度、电压等)进行采样并在采样时进行精确跟踪,因为由iep电路122进行加时间戳。可以增强所讨论的帧。当帧由传输电路118传输时,该帧可以包含被加时间戳的采样值,而不会增加(leaning)开销或等待时间。iep电路122还包括看门狗(wd)计时器。某些事件应在正常操作条件下发生。当此类事件发生时,pru116通常将清零wd计时器。如果wd计时器启动,则表示pru116没有及时清零wd计时器,或者没有及时重置wd计时器,这指示存在停滞或某种类型的等待时间,这是不期望的。因此,wd计时器用于跟踪错误。
如上所述,任务管理器电路111和任务管理器电路121可以识别大量事件。pru116是系统100的主数据引擎。当帧开始时,系统100开始准备和服务接收电路105。一旦帧在传输电路118中,就可以开始下一个分组的输入。因为pru116是主处理器,所以pru116需要实时访问所有事件。与pru116相关联的另一操作是加水印。可以在接口电路105、接收电路105、传输电路118和接口电路119处创建水印。较不利的是在加载或卸载分组之前也等待直到fifo已满或已空。在本公开的至少一个示例中,当达到一定量的空度(或满度)时,任务管理器电路121将发出信号,并且pru116将确定该分组是否将被加水印。
bs-ram117的一个方面在于,它使得pru116能够在系统100将情境和变量保存在bs-ram117的同时窥探数据分组;可以无开销代价对情境和变量执行操作,因为分组的数据不需要移动两次。在本公开的至少一个示例中,可以将传入的数据分组移动到存储位置,并且同时对数据进行操作。这不同于常规系统,常规系统将传入的分组移至处理电路并随后移至存储位置。因此,系统100执行单个操作,而常规系统将执行两个操作。
如上所述,aux_pru112与bs-ram101交互。aux_pru112具有任务管理器电路111,其可以基于某些事件或情境交换的发生而抢占pru116。aux_pru112还与传递电路113交互。在至少一个示例中,根据本公开的系统100还包括8kb的数据ram114和64kb的共享ram115。aux_pru112和传递电路113两者均与pru116交互。任务管理器电路121基于fifo水印输入用于接收和传输处理的实时任务。pru116还耦合到16kbbs-ram过滤器数据库117。来自pru116的输出去往fifo传输电路118。继而,来自fifo传输电路118的输出去往实时接口电路119。pru116还与计算以太网分组内的校验和的crc120交互。在至少一个示例中,系统100包括(一个或多个)iep/计时器/edio/wd电路122。如上所述,系统100还可以包括中断控制器(intc)123和ecap电路124。
图2a至图2c示出了示例工业通信子系统(icss)(在下文中简称为子系统200)。图2a至图2c示出了与图1所示相同的许多部件,但是细节有所变化。关于图1阐述的描述与图2a至图2c紧密相关,并且反之亦然。内部总线248和外部总线247的左侧上的slice_0201与右侧上的slice_1261对称。(注意,相似的字母符号指示相似的部件。)slice_0201中的部件的描述适用于slice_1261中的对应部件。子系统200包括处理硬件元件,诸如辅助可编程实时单元(aux_pru_0)205,以及pru_0219,其包含一个或多个硬件处理器,其中每个硬件处理器可以具有一个或多个处理器核心。在至少一个示例中,处理器(例如,aux_pru_0205、pru_0219)可以包括至少一个共享高速缓存,该共享高速缓存存储由处理器(aux_pru_0205、pru_0219)的一个或多个其他部件所利用的数据(例如,计算指令)。例如,共享高速缓存可以是存储在存储器中的本地高速缓存数据,以供组成处理器(aux_pru_0205、pru_0219)的处理元件的部件更快访问。在一些情况下,共享高速缓存可以包括一个或多个中级高速缓存,诸如2级高速缓存、3级高速缓存、4级高速缓存或其他级别的高速缓存、最后一级高速缓存或其组合。处理器的示例包括但不限于cpu微处理器。尽管在图2中未明确示出,但是组成处理器aux_pru_0205和处理器pru_0219的处理元件还可以包括一种或多种其他类型的硬件处理部件,诸如图形处理单元、asic、fpga和/或dsp。pru_1的另一个加速器是bswap电路224(294)。bswap电路224(294)可以根据所讨论的分组的大小、小字节序和/或大字节序来交换字。bswap电路224(294)可以根据字大小对分组中的字节重新排序。
子系统200包括由图2c中的slice_1镜像的slice_0201。从图2a中可以看出,slice_0201具有多个部件。主要部件是辅助pru(aux_pru_0)205、pru_0219和mii25。aux_pru_0205具有编号或加速器(也称为小部件)。aux_pru_0205用作slice_0201的控制处理器。在整个本公开中,术语“控制处理器”、“aux_pru”和“rtu_pru”是同义的和可互换的,除非另有指示或由它们出现的情境决定,尽管它们的功能和配置可以不同。
图2a示出了存储器(例如204(264))可以可操作地并且通信地耦合到aux_pru_0205。存储器204(264)可以是被配置为存储各种类型的数据的非暂时性介质。例如,存储器204(264)可以包括一个或多个存储装置,其包括易失性存储器。易失性存储器,诸如随机访问存储器(ram),可以是任何合适的非永久性存储装置。在某些情况下,如果分配的ram不足以容纳所有工作数据,则可以使用非易失性存储装置(未示出)来存储溢出数据。当选择加载到ram中的程序用于执行时,此种非易失性存储装置也可以用于存储此类程序。
可以针对各种软件平台和/或操作系统,以各种计算语言开发、编码和编译软件程序,并且随后由aux_pru_0205加载和执行。在至少一个示例中,软件程序的编译过程可以将以编程语言编写的程序代码变换为另一种计算机语言,使得aux_pru_0205能够执行该编程代码。例如,软件程序的编译过程可以生成可执行程序,其为aux_pru_0205提供编码指令(例如,机器代码指令)以完成特定的非通用计算功能。
在编译过程之后,然后可以将编码后的指令作为计算机可执行指令或过程步骤从存储装置220(290)、从存储器210加载到aux_pru_0205和/或嵌入aux_pru_0205内(例如,经由高速缓存或板载rom)。在至少一个示例中,aux_pru_0205被配置为执行所存储的指令或过程步骤以执行指令或过程步骤以将子系统200变换为非通用且经特殊编程的机器或设备。在计算机可执行指令或过程步骤的执行期间,aux_pru_0205可以访问所存储的数据,例如由存储装置220(290)存储的数据,以指示子系统200内的一个或多个部件。
图2b示出了由图2a的slice_0201和图2c的slice_1共享的部件和资源。图2c包括与图2a相同的硬件。slice_0201和slice_1261关于图2b对称。在本公开内关于图2a的描述比照(mutatismutandis,做适当修改)适用于图2c。子系统200包括slice_0201处的端口253和slice_1261上的对应端口276。存在第三端口(参见图2b),即主机端口245;主机端口245将子系统200连接到主机246,其中子系统200可以是部件。端口253和端口276都可以连接到以太网。子系统200因此可以用作三端口交换机。主机246可以是本地源/同步或soc(130)。虽然子系统200选项本身可以是soc(130),但在一些实施方式中,子系统200将是更大soc(130)的子部件。在一些示例中,主机246将是来自英国英格兰剑桥的armholdingsplc的cpu。在至少一个示例中,主机246包括若干个cpu。存在各种各样的cpu。小型cpu的一个示例是armcortex-r5-cpu。大型cpu的一个示例是armcortex-a57-cpu。在至少一个示例中,子系统200可以由另一个此种cpu控制。
子系统200包括xfr2tr电路202(图2a),其与内部可配置总线阵列子系统(cbass)248(图2b)交互。xfr2tr电路202(280)中的“xfr”代表传递。xfr2tr电路202(280)具有宽边接口。xfr2tr电路202(280)经由xfr2tr电路202(280)的宽边接口邻接于aux_pru_0205。aux_pru_0205的内部寄存器组暴露于加速器mac206、crc207(267)、sum32电路208(268)、字节交换(bswap)电路203(263)和bs-ram204(264)。在本公开的至少一个示例子系统200中,aux_pru_0205的内部寄存器组直接暴露于加速器(诸如上面引用的那些加速器),与常规系统的架构不同。在常规系统中,aux_pru_0205需要结构上的负载存储操作以访问加速器。但是,在图2所示的示例中,加速器实际上是aux_pru_0205的数据路径的一部分。aux_pru_0205可以基于给定寄存器的宽边id将其寄存器文件导入和导出到给定的加速器(也称为“小部件”)。例如,作为dma一部分的xfr2tr电路202(280)可以执行传递请求。传递请求(tr)可以从起始地址开始,以开始数据移动,指定要移动的数据量(例如200字节)。xfr2tr电路202(280)可执行smem235的简单dma存储器副本,其包含预定传递请求(tr)的列表。在aux_pru_0205上运行的软件知道smem235的预先存在的tr的列表。在操作中,aux_pru_0205向dma引擎发送指令以移动数据。由于传递指令可能非常复杂化和/或复杂,因此预定义指令位于存储在smem235中的“工作命令池”内。基于所讨论的分组类型,aux_pru_0205确定应使用哪些“工作命令”,以及以什么顺序导致分组发送到正确的目的地。xfr2tr电路202(280)可以由aux_pru_0205引导来创建工作命令列表,并且一旦创建了工作命令列表,xfr2tr电路202(280)就将通知dma引擎(未示出)。然后,dma引擎将从smem235中拉取指定的工作命令并执行所拉取的工作命令。因此,xfr2tr202(280)最小化了构建dma列表(如执行数据移动的链路列表)所需的计算开销和传递。tr代表传递请求。
aux_pru_0的另一个加速器是bswap电路203(263)。bswap电路203(263)可以根据所讨论的分组的大小、小字节序和/或大字节序来交换字。bswap电路203(263)可以根据字大小对分组中的字节重新排序。因此,bswap电路203(263)是将自动执行此类交换的加速器。bs-ram204(264)对应于关于图1讨论的bs-ram101。bs-ram204(264)紧密耦合到aux_pru_0205。当aux_pru_0205将数据元素推送到bs-ram204(264)时,可以通过crc207(267)同时计算该元素的crc,或者通过校验和电路208同时计算该数据元素的校验和。基于数据分组的id,aux_pru_0205将同时窥探(一个或多个)必要事务(例如,校验和、乘法、累加等),这意味着将数据元素推送到bs-ram204(264)并执行加速器动作构成单个事务,而不是双重事务。bs-ram204(264)实现操作的同时性,因为bs-ram204(264)可以在将数据传递到物理ram(例如,图1所示的数据ram114和共享ram115)时启用和/或禁用小部件的功能。
外围bswap203(263)、xfr2tr电路202(280)、mac206(266)、crc207(267)和sum32208,虽然出于说明目的被图示为在bs-ram204(264)外部,但在大多数操作条件下,被嵌入在bs-ram204(264)内。乘法累加器(mac)206(266)是简单的加速器,包括32位乘32位的乘法器和64位的累加器。循环冗余校验(crc)电路207(267)循环执行冗余校验。crc电路207(267)支持不同的多项式。校验和电路208相似于crc电路207(267),不同之处在于校验和电路208在执行对aux_pru_0205处的有效载荷的校验和之前使用哈希运算来确定有效载荷的完整性。
任务管理器电路209是aux_pru_0205的关键部分。任务管理器电路可以基于检测到196个(或更多)事件中的哪个而提示aux_pru_0205执行给定功能。
有两种方法可以将数据移入和移出子系统200,以及移入和移出soc130存储器和/或移入外部装置。一种方式是通过分组流接口(psi)211(281),其提供了将数据推送到主机(例如246)和从主机(例如246)拉取数据的能力。psi211(281)的此动作与读取请求不同。相反,将psi211(281)的主(书写器)部件附接到aux_pru_0205。将接收到的分组映射到目的地。在正常操作条件下,目的地将准备好接收分组。为此,psi211(281)不读取数据,而是将数据传输到目的地端点。psi211(281)从导航子系统(navss)210接收数据以及将数据发送到导航子系统(navss)210。navss210实现复杂的数据移动。navss210具有dma引擎和称为重新引擎的高级tr。navss210支持psi211(281),并且可以将psi211(281)映射到其他装置,诸如经由外围部件互连高速。使用psi211(281),数据可以直接从icss去往外围部件互连高速,而绕过主机和/或主dma引擎,从而实现使数据从一个以太网接口(例如,接口电路225(295))流向另一个接口,诸如通用串行总线或外围部件互连高速。
aux_pru_0205与处理器间通信暂存器(ipcspad)212(282)通信,其继而还与pru_0219通信。ipcspad212(282)不是单个cpu拥有的临时spad。至少出于ipcspad212(282)的目的,ipcspad212(282)能够跨aux_pru_0205和pru_0219传递数据或完整的控制器状态。传递到虚拟总线电路(xfr2vbus)电路213(或简称为“传递电路213”)对应于图1所示的传递电路113,并且以与传递电路113相同的方式操作。传递电路213(283)附接到bs-ram214(284)。传递电路213(283)具有与外部cbass247、内部cbass248和自旋锁电路249的宽边接口。传递电路213可以请求从存储器(例如204、214)到宽边以及从宽边到存储器的读取和写入。此读/写功能不同于诸如在专用存储器(dmem0)233处的读/写操作。常规的dma复制操作会将soc(130)存储器中的信息移至dmem0233或共享存储器smem235。内部cbass248是用于子系统200的片上网络。
内部cbass248为4字节宽。在至少一个访问内部cbass248中,必须执行加载和存储操作,这是高等待时间低吞吐量的操作。然而,由于传递电路213(283)的宽边宽度,使用紧密耦合且更直接的传递电路213(283)减少了等待时间和开销,同时还提供了更大的带宽。因此,传递电路213(283)可以充当从寄存器文件到子系统200存储器(例如233)的直接映射。中间存储器位置被绕开并且传递电路213(283)直接进入寄存器文件,这减少了等待时间。
如aux_pru_0205所述,pru_0219也具有加速器。pru_0219对应于图1的pru116。与pru116一样,pru_0219具有任务管理器电路223。aux_pru_0205和pru_0219之间的主要区别在于pru_0219与接口电路104、接收电路105、传输电路118和接口电路119(参见图1)交互,它们在图2a至图2c中共同示出为接口电路225(295)。接口电路225(295)包括接收电路270,其包括一级fifo传输层(tx_l1)226(296)和二级传输层(tx_l2)262(256)(参见图1,118)。传输电路271包括一级接收层(rx_l1)和二级接收层(rx_l2)272(257)(参见图1,105)。
aux_pru205的pru_0219的bs-ram214(284)与bs-ram204(264)相同。通用输入/输出(gpio)电路215(285)使子系统200能够访问soc(例如130、246)的额外硬线。∑-δ电路216(286)是模数转换器,其与一个或多个外部传感器(未示出)交互。∑-δ电路216(286)将来自传感器的模拟数据流转换为数字数据流。∑-δ电路216(286)是过滤器。来自传感器的数据流对应于外部装置诸如电动机处的电压或温度。∑-δ电路216(286)向pru_0219通知某些事件,例如是否存在电流尖峰、电压尖峰或温度尖峰。pru_0219确定由于尖峰需要采取什么动作(如果有的话)。
外围接口217(287)用于在子系统200的控制下检测装置诸如电动机或机器人关节的位置或定向。外围接口217(287)例如使用协议来确定臂的精确径向位置。∑-δ电路216(286)和外围接口217(287)因此用于装置控制,诸如机器人控制。∑-δ电路216(286)和外围接口217(287)紧密耦合到pru_0219,这使子系统200能够用于工业场景。
219的分组流接口psi218(288)相似于205psi的psi211(281)。211(281)和psi218(288)与导航子系统(navss)psi210交互。但是,尽管psi211(281)具有四个接收(rx)输入和一个传输(tx)输出,但是psi218(288)具有单个传输(tx)输出。如上所述,pru_0219可以将pru_0219的寄存器文件直接移动到以太网线(端口)253中。因此,数据分组通过接收电路271的一级接收层(rx_l1)227和接收电路271的二级接收层(rx_l2)272(257)进入;无需读取存储器或通过dma。相反,数据分组可以在单个数据周期中立即弹出(推送)到pru_0219。如有必要,可以在下一个时钟周期中将数据分组推送到一级传输层(tx_l1)226(296)或二级传输层(tx_l2)262(256),这可以称为“桥到层直通”操作。在至少一个桥到层直通操作中,该操作比存储和转发操作更快。视情况而定,可以在经由pru_0219和端口245将数据分组推送到主机246(例如soc130)或推送到slice_1261时执行桥到层直通操作。
pru_0219是risccpu,其寄存器文件访问以太网缓冲器,而无需访问或通过其他存储器。接口228(298)、接口229(299)和接口230(258)是物理媒体接口,并且包括至少一个rgmii。实时媒体独立接口228(298)是4位接口。接口229(299)为千兆位宽。接口229(299)是简化的千兆位媒体接口(rgmii)。接口230(258)是串行千兆位媒体独立接口(sgmii)。在这些识别的接口的一个或多个示例中,实时执行。
以太网接口电路225(295)包括接收(rx)分类器电路232(108),其取得速率数据(107)和过滤器数据(106)和其他数据,并基于预定义的映射函数(诸如时间函数),分类器电路232(108)根据该映射函数对分组进行分类。分组的分类将确定分组的优先级,这将指定分组将放入哪个队列(高优先级队列、低优先级队列等)。接口225(295)的端口253本质上是专用于以太网接口电路225(295)的导线。端口253将子系统200连接到物理层。宽边接口252(255)是pru_0219和以太网接口电路225(295)之间的接口。如上所述,270(273)和271(274)是fifo配置的电路。fifo传输电路270(273)对应于图1的传输电路118,且fifo接收电路271(274)对应于图1中的电路105。分类器电路232对数据进行操作,同时将数据推送到fifo电路270(273)中。
slice_0201和slice_1261共享诸如图2b所示的数字资源301。slice_0201和slice_1261经由内部cbass248彼此耦合。内部cbass248与中断控制器236耦合。中断控制器236是聚合事件实例的聚合器(回想有196个可能的事件)。事件中的一些可以来自主机(130)246,尽管大多数事件是子系统200的内部事件。由于存在大量可能的事件,因此必须将事件聚合或合并为较少数量的超级分组,以便与来自主机(例如246)的数据详尽地共享。在pru_0219上运行的软件确定源到输出目的地的映射。
如上所述,子系统200包括内部可配置总线阵列子系统(cbass)248作为共享资源。内部cbass248经由32位从端口从外部cbass247接收数据。内部cbass248与专用存储器_0233、专用存储器_1234和共享存储器(smem)235(115)进行通信。smem235是通用存储器。smem235可用于直接存储器访问(dma)操作、用于dma指令集和其他功能。dma相似于暂存器(126、127)并可以包含控制和状态信息。内部cbass248还与增强捕获模块(ecap)237通信,增强捕获模块237也与外部可配置总线阵列子系统(cbass)247通信。增强捕获模块237是用于对诸如电动机之类的外部装置进行时间管理的计时器。
在本公开的至少一个示例中,子系统200具有不同的操作模式。aux_pru_0205和pru_0219各自具有存储器映射寄存器。主机246将信息写入配置管理器电路238。例如,如果主机246需要启用rgmii模式,则配置管理器238将启用rgmii229(299),其为配置寄存器的一个示例。
通用异步接收器-发射器(uart)239是用于异步串行通信的硬件装置,其中数据格式和传输速度是可配置的。电信令电平和方法由uart239外部的驱动器电路处理。uart必须以特定的波特率工作,这需要固定的时钟速率。异步网桥(avbusp2p)240与内部cbass248和uart239通信。uart239继而与外部cbass247通信。avbusp2p240是允许对uart239进行独立计时的网桥。外部cbass247与工业以太网peripheral_0(iep0)241和工业以太网peripheral_1(iep1)273耦合。iep0241和iep1273各自包括计时器、edio和wd(122)。iep0241和iep1273共同使两个时域管理能够同时运行。相似于ap237的计时器搜索iepo的计时器,并且iip2必须在给定的频率(例如200兆赫兹)上操作,但是pru可以与这些频率退耦。同样,如有必要,avbusp2p240、avbusp2p242和avbusp2p243是允许uart239、iep0241和iep1273在不同频率下操作的耦合器。
如图2b所示,在iep0241和内部可配置总线阵列子系统(cbass)248之间通信地插入第二avbusp2p电路242。还在iep1273和内部cbass248之间通信地插入第三avbusp2p243。子系统200还包括脉宽调制器(pwm)244,其通信地插入内部cbass248和外部部件之间。
部件236、237、238、239、241、273和244各自连接到特定的soc导线。也就是说,它们各自与主机246的io通信。
图2b还示出了子系统200可以包括自旋锁249、aux_spad250和pru_spad275。自旋锁249是硬件机构,其提供子系统200的各个核心(例如205、219)与主机246之间的同步。常规地,自旋锁是一种锁,其引起试图自动获取该锁的线程在循环(“自旋”)中简单地等待,同时反复检查该锁是否可用。由于线程保持活动但未执行有用的任务,因此使用此锁是一种繁忙的等待。一旦获得了自旋锁,通常将保留这些自旋锁,直到明确释放它们为止,尽管在某些实施方式中,如果正在等待的线程(持有锁的线程)阻塞或“进入睡眠”,则可以自动释放自旋锁。锁是同步机构,用于在存在许多执行线程的环境中对访问资源实施限制。锁强制执行互斥并发控制策略。基于该原理,自旋锁249为子系统200部件的操作提供了自动化。例如,自旋锁249使子系统的核心(例如aux_pru_0205)中的每个能够访问共享的数据结构,诸如存储在smem235中的数据结构,其确保了同时更新各个核心。各个核心的访问由自旋锁249序列化。
如示例子系统200中所示,辅助暂存器(pruspad)250和auxspad275各自容纳30个32位寄存器的三组。子系统200还包括过滤器数据库(fdb)251(109),其包括两个8kb的组和过滤器数据库控制电路。fdb251是aux_pru_0205和pru_0219访问的宽边ram。硬件引擎∑-δ216(286)和外围接口217(287)也可以访问fdb251。接收电路271(其包括一级接收层(rx_l1)227(297)和二级接收层(rx_l2)272(257))也可以访问fdb251。fdb251相对于aux_pru_0205和pru_0219读取和写入条目是宽边ram,但硬件也使用fdb251提供通过端口253到达的分组的加速压缩视图。硬件将使用散列机制查询fdb251的存储器,并将结果与分组一起递送到pru_0219。确定分组接下来到达的位置是路由功能。aux_pru_0205和pru_0219经由fdb251的宽边接口访问fdb251以添加信息和删除信息。接收硬件225(295)也可以访问fdb251。
子系统200还可以包括通信接口225(295),诸如网络通信电路,其可以包括可以通信地耦合到处理器205的有线通信部件和/或无线通信部件的。接口电路225可以使用多种专有或标准化网络协议(诸如以太网、tcp/ip)(列举许多协议中的几种)中的任一种以实现装置之间的通信。网络通信电路还可以包括利用以太网、电力线通信wi-fi、蜂窝和/或其他通信方法的一个或多个收发器。
如上所述,在本公开的示例中,以实时确定性的方式处理数据分组,这与常规以太网或ieee以太网处理不同,传统以太网或ieee以太网处理定义了更多的“尽力而为”业务系统,其中取决于给定网络的负载发生分组丢失。尽管常规的以太网管理对于许多应用(诸如视频流)是可接受的,但是在工业设置中(例如,机器人装配线),已发送的数据分组(在理想条件下)将根据预定的计划准确地递送。在工业世界中,必须根据严格时间表来处理分组。当然,分组丢失可能在工业环境中发生,但是在层(高于本公开的示例所属的一级和二级)中有不同的手段来照顾分组丢失。
当在一级接收层(rx_l1)227和/或二级接收层(rx_l2)272(257)从物理层(未示出)接收到分组时,分组分类器232(108)分析该分组,并标识分组的哪一部分是内容(也称为“有效载荷”)。然后,分组分类器(也称为“分组分类引擎”)232做出关于如何处理该分组的即时决策。以太网桥225(295)做出关于(经由接收电路271和/或入口253)接收到的每个分组的转发和接收决策。在常规的ieee以太网桥中,以“存储和转发方式”执行此类转发和接收操作,其中在第一步中接收传入的数据分组,并且一旦接收到数据分组,然后在第二步中检查内容。在常规的ieee以太网桥中,一旦完全接收到分组并检查了内容,就做出第三步转发和接收确定。在做出转发和接收确定之后,然后将数据分组提供给机械传输层(诸如,经由传输元件226(296)。在本公开的至少一个示例中,以最小化等待时间和抖动的方式简化这些步骤。在至少一个示例中,分类引擎232(260)被配置为以重叠的方式执行常规ieee以太网桥的过程,由此到在271(272)接收到分组已经完成的时间为止,分类引擎232(260)已经确定需要对分组进行什么操作,需要将分组发送到什么目的地以及通过什么路由/路线。
在本公开的示例中,网桥延迟是数据分组到达端口253并在另一端口276上离开之间的时间量。在数据分组的进入与数据分组的外出之间的时间期间如所提到的,子系统200做出切换决策(确定)并然后执行传输功能。在标准以太网ieee世界中,切换功能是使用必须具有可变等待时间的存储和转发结构执行的。在可变等待时间条件下,无法保证在时间零处在传入端口253(104、105)上接收到数据分组时,该数据分组将在固定(已知先验)时间在不同端口(例如276、245)上离开。子系统200的至少一个好处是分类引擎232可以知道如果在时间零处接收到数据分组,则该分组将在预定的(确定性)时期内通过另一个端口(例如245)发送出去。在至少一个示例中,该时期是一微秒。在至少一个示例中,当部件(诸如slice_0201)具有如此短的切换时间时,该部件被认为是实时部件,能够“实时”执行其分配的功能。在本公开的示例中,实时计算(rtc)描述了经受例如从事件到系统响应的“实时约束”的硬件和软件系统。例如,实时程序必须保证在指定的时间限制(也称为“最后期限”)内做出响应。在本公开内的一些示例中,实时响应为毫秒量级。在本公开内的一些示例中,实时响应为微秒量级。
本公开的示例涉及在实时系统中操作的通信桥。通信桥是实时控制系统,其中以确定性的方式交换输入数据和输出数据。本公开的示例包括控制装置(例如217(287)、244)和多个从装置(未示出)或实时消耗来自控制装置217(287)、244的输入/输出数据的装置(未示出)。实时系统100、200具有通信桥255实时能力。因此,转发分组的时间量是确定性的,具有最小的抖动和等待时间。在至少一个示例中,通过硬件计时器(未示出)将抖动和等待时间最小化(到几纳秒的范围),该硬件计时器定义了分组离开物理端口253、252(255)的时间。子系统200的实时可操作性不同于标准以太网,在标准以太网中,至少几十微秒的抖动是常见的。在此类常规系统中,做出转发/路由确定所花费的时间量根据分组到达的时间、数据分组的接收速率以及分组的内容而变化。在本公开的实时系统(例如200)中,循环执行切换功能。例如,可以每31微秒在子系统200中交换新数据。预定的交换速率(诸如31微秒)用作时间参考。取决于分组(例如,经由端口253)进入的时间,以确定的等待时间(在此示例中为31微秒)转发分组,或可替代地根据存储和转发方式处理数据分组,相似于上述针对常规系统的描述。因此,分组到达时间可以是子系统200如何处理给定数据分组的判别器。接收(rx)分类器232在确定如何处理传入分组时考虑的另一个因素是通常与所讨论的分组类型相关联的数据(传输)速率。例如,如果接收到的分组的平均数据速率超过某个数据速率阈值,则系统可以丢弃(较少结果)数据分组,以帮助确保有足够的带宽用于较高优先级的分组。在至少一个示例中,分类器232至少部分地基于分组的有效载荷来确定给定数据分组的重要性。
在至少一个示例中,分类器232通过首先访问分组中的位置(诸如分组的以太网媒体访问控制(mac)地址)来检查分组内容。装置的mac地址是分配给网络接口控制器(nic)的唯一标识符,用于在网段的数据链路层进行通信。mac地址被用作用于大多数ieee802网络技术的网络地址,包括以太网、wi-fi和蓝牙。在至少一个示例中,在子系统200的媒体访问控制协议子层中使用mac地址。根据本公开,mac地址可识别为六组的两个十六进制数字,由连字符、冒号或使用其他符号系统分隔。
数据分组可以由过滤器106基于其指定的递送地址(未示出)进行过滤。数据分组包括六字节的源和目的地地址。在至少一个示例中,接口电路225(295)基于该信息来过滤(106)分组。例如,接口电路225(295)可以读取分组的网络地址并确定是接受分组、转发分组还是丢弃分组。在至少一个示例中,接受转发丢弃决策可以基于分组的mac报头。在至少一个示例中,在做出接受转发丢弃确定时,接口电路可以进一步进入分组中到有效载荷,并且基于有效载荷中的名称来做出过滤106确定。在soc200的一些实施方式中,装置的名称被连接在有效载荷中,并然后内容过滤器106查看有效载荷。当pru_0219执行存储操作时,bs-ram214(404)和pru_0219之间的连接的宽边性质使得能够在三个时钟周期内在宽边ram214中存储或从宽边ram214中检索32字节的信息。在执行存储操作期间,pru_0219可以对部分或全部相同的32字节的信息执行多项数学运算。
在本公开的实施方式中,数据分组通常将包含多个数据报。数据报的这种多重性要求将分组或其部分转到多个地址。换句话说,以太网分组中可以有多个子分组。由于子分组可以各自具有其自己的地址,因此必须对地址进行解析。在一个分组中有多个地址的情况下,并且子系统200将在每次检测到子地址时重新开始解析。因此,接口电路225(295)将具有用于过滤器106的可变起始偏移,以使接口电路225(295)能够将多个子分组放置在单个以太网分组中。在至少一个示例中,这意味着从单个数据分组派生的子分组被发送到不同的装置(例如,通过外围接口217(287));在本公开的示例中,单个以太网分组可以包含子分组,子分组中的一个或多个子分组旨在用于(寻址到)不同的装置。除非另有指示,否则本公开的通信(分组交换)不是点对点通信。本公开的通信基于主装置到从装置架构。在本公开的实施方式中,单个主装置(例如,主机246)控制数十个、数百个或甚至数千个从装置。
由于主装置和从装置之间的这种不对称关系(1对n,其中n可以是非常大的数字),并且要求实时通信,提供了包括入口过滤器硬件106的接口电路225(295)。入口过滤器106(及其伴随的逻辑)与入口分类器232组合,实现用于实时转发和处理的硬件决策。在本公开的示例中,为了进行关于分组的转发和接收确定而必须读取的所有信息位于分组的前32字节中。一旦读取了其中的前32字节,pru_0219可以查找报头和附加报头,这取决于分组所遵循的协议。可以实时查找报头(诸如在过滤器数据库251中)。因此,如上所述,一旦接口电路225(295)已经接收到分组的前32字节,接口电路225(295)就具有足够的信息来确定是否转发分组或者是否接收分组。应当注意,所描述的32字节报头大小是示例报头大小。本公开的系统100、200可以被配置为与具有其他报头大小的分组一起工作。
如上所述,(分组)接收处理是实时完成的。在本公开的实施方式中,aux_pru_0205、pru_0219和接口电路225(295)是可编程的,并且被配置为使得所有分组处理都是完全确定性的。在接口电路225(295)中以64千兆位/秒的速度接收32字节的报头信息,这使得接口电路225(295)能够向前发送32字节的信息或接收32字节的信息。在可以移动它们以过滤分组的特定部分的范围内,本公开的过滤器106非常灵活。如果存在多个子分组,则可以根据需要由接口电路225(295)重新加载过滤器106。另外,接口电路225(295)可以应用掩码以设置分组的范围或分组和/或子分组中的地址。通过使用大于和小于操作对分组进行分组,接口电路225(295)可以例如确定当分组具有从15到29的地址号时,该分组将被接收。在一些示例中,可以应用二进制掩码,使得转发具有以偶数开头的地址的子分组,如8-7,不转发(至少不是立即)具有以奇数开头的地址的子分组。因此,具有用于子分组地址分类的大于/小于操作可能是有利的。在一些示例中,可以将不同的过滤器(诸如106和107)与其他部件(诸如mac206(266)、220(290))操作地组合,以通过分组的mac地址进一步处理分组。
如上所述,可以将多个过滤器组合用于接口电路225(295),以做出切换确定。也可以应用附加逻辑。例如,分类器232可以对分组进行分类,并且应用与分类相关的逻辑,如“对于分组类型a,如果条件1、2和3为真,则将接收该分组。”作为另一示例,如果分组分类为类型b,如果条件1为真并且条件2为假,则该分组将被丢弃。子系统200可以被配置为使得条件还可以包括其中接收到分组的时间窗口。例如,接口电路225(295)可以确定在某个时间点,接口电路225(295)将仅允许转发非常重要(更高优先级)的输入/输出数据。接口电路225(295)可以被配置为使得在指定时期期间(例如,在发生预定事件之后),将应用一组过滤器组合,而在其他时间期间,可以允许所有类型的数据业务。这种所描述的可编程性在工业设置中是有利的,因为工业通信基于硬时间窗口进行操作(例如,与电话会议相反)。
在本公开的示例中,可以将多个硬件过滤器与速率过滤器107组合,使得也可以根据速率对数据分组进行分类。所使用的过滤器106、107和硬件220(290)操作可以累积地执行。可以使用内容、时间和速率的任何组合来过滤分组——全部实时。给定的过滤器106可以为分组多次重启。过滤器106可以具有起始地址,该起始地址的值至少部分地基于给定分组/子分组的内容和/或内容的类型来确定。
在本公开的至少一个示例中,接口电路225(295)被配置为自动检测分组是否包含虚拟局域网(vlan)标签。一些以太网分组在分组中间或尾随mac地址处具有标签字节的标签。可能发生的是,如果将过滤器应用于尾随mac地址的数据,则mac地址将被不期望地移位四个字节。本公开的示例接口电路225(295)通过自动检测分组是否具有vlan标签,并且如果分组确实包含vlan标签,则使用vlan标签的位置作为起始地址来重启相关过滤器106来解决该问题。此后,接口电路225(295)做出确定,诸如是否使用组合逻辑来接收或丢弃分组,该组合逻辑可以涉及and(与)、or(或)或过滤器标志的任何适当的组合。在本公开的一个或多个示例中,速率计数器107可以是硬件速率计数器,其取决于所讨论的业务的类型和针对分组的类型的预定时间窗口来确定速率。因此,对于高优先级分组可以有一定的时间,并且对于非实时分组可以有不同的时间,并且可以根据情况应用不同的过滤器。在一些示例中,在接收时间(即时)处理期间产生立即结果的过滤器106将转发所讨论的分组,而与该分组的长度无关。该操作能力与常规以太网形成了鲜明的对比,在常规以太网中,首先接收分组,查询一个或多个查找表,并然后最终做出切换决策。在本公开的一些示例中,分组大小是预定的,并且通信以每个分组的固定速率发生。在其他示例中,关于分组长度的信息被包含在分组的报头内。在任一种情况下,分组长度都是硬实时即时确定的。
本公开中描述的架构的至少一个技术益处在于,即使对于长度达十二微秒的分组,它们也使得能够在单个微秒内完成切换/转发确定。基于时间和数据速率的接口电路225(295)的组合逻辑使得分类引擎232能够以健壮的方式执行。子系统200重新启动过滤器106以在分组中多次应用过滤器106的能力增强了子系统200实时做出分组切换决策的能力。在一个示例实施方式中,过滤器106的长度受到限制。如果分组比过滤器更长,则将需要重新加载过滤器106。如果包含子分组的以太网分组,则过滤器106可以与单个分组一起重新用于多个位置。在一些示例中,子分组将各自具有其自己的地址。例如,如果分组包含三个子分组,则可以将地址过滤器106加载三次,以将相同的地址过滤器106应用于每个子分组。pru_0219经由接口252(255)将数据写入tx_l2中,并然后数据沿着通信路径253离开slice_0201。所描述的实时处理支持以下描述的资源可用性和分配管理。
本公开的示例涉及到用于向多核通信的实时任务管理器(例如,任务管理器电路223)的资源可用性事件消息传递。本公开的至少一个实施方式是一种系统,该系统有效地管理用于工业通信的多核处理系统中的多个实时任务之间的资源共享。在至少示例中,子系统(例如,子系统200)使通常与资源共享相关联的停顿周期最小化,诸如当资源当前不可用时,需要执行的任务的相关联的硬件以轮询资源可用性并浪费pru周期结束。在本公开的示例中,此类pru周期可以用于其他实时任务,并且当资源变得可用时,可以恢复被抢占的任务。因此,减少了等待时间。
在至少一个示例中,实时地将硬件部件需要执行的任务挂起到用于64个自旋锁标志的不可用资源上。当资源变得可用时,与任务管理器(例如,任务管理器电路209)对应的事件被路由到任务管理器,然后该任务管理器对该事件进行操作并取决于等待资源的任务相对于其他任务的优先级触发等待资源的任务。使用自旋锁249标志可以在同一不可用资源上挂起多个任务。在本公开的示例中,关键任务在资源可用性上立即执行,并且消除了停顿周期,因此充分使用了pru周期。
本公开的至少一个示例在具有多个pru的系统(例如200)中使用pru的宽边指令。在至少一个示例中,具有中断分派器的实时任务管理器(例如,任务管理器电路209)提供低等待时间的任务切换。使多个任务能够针对同一资源挂起的能力以及在资源可用性上进行等待时间任务切换的能力使传统系统中出现的停顿周期最小化。
本公开的示例的至少一个技术益处在于,这些示例使高速工业以太网和类似的pru固件能够通过避免当计算资源当前不可用于一个或多个电路(因为该计算资源当前被一个或多个其他电路使用)时避免停顿来节省pru周期。本公开的示例包括硬件支持使pru(例如205)固件能够避免轮询资源可用性,这是不确定的。增强的系统确定性使切换千兆位以太网分组具有固定的等待时间和最小抖动。因此,本公开的示例优化了用于多核处理系统(例如,子系统200)中的资源共享的pru周期使用。在至少一个示例中,使用64个自旋锁标志来避免停顿周期,该停顿周期将用于连续轮询常规系统中的资源可用性。在各种示例中,第一硬件部件(例如,pru205)的固件将仅检查一次任务的资源可用性,并然后将期望资源的使用作为用于另一硬件部件(例如,pru_0219)的另一任务产生。当资源由等待的硬件部件(例如,pru205)免费使用时,将由实时任务管理器(例如,任务管理器电路209)重新触发挂起的任务。
本公开的示例涉及pru任务管理器(例如,任务管理器电路112)与自旋锁电路(例如,249)的互操作性,以管理对共享资源的访问(一般参见图2b)。在大多数情况下,此类任务管理器(例如209)将实时操作。在各种示例中,为了能够以千兆位以太网速度操作,任务管理器(例如223)的fw利用寄存器。为了适应不同的任务,诸如涉及分组切换的任务(例如,分组接收、传输和后台任务,如源地址学习),任务管理器被配置为需要在机制之间进行切换。与自旋锁电路249配合使用,任务管理器电路(例如223)将抢占当前pru执行/任务,保存密钥寄存器并在硬件事件触发新任务后十纳秒内起动优先级高于当前任务的新任务。在一个或多个实施例中,由于任务管理器将被配置为响应不同的硬件事件并且可以对任务进行不同的优先级排序,因此固件映射多个(诸如64或70个)硬件事件中的哪个会引起任务交换发生,这实现对于给定任务管理器(代表任务管理器的相应pru)而言最佳的紧密实时任务交换。连接150、152、154、156、158、160、162、164、252和255是宽边连接。连接150、152、154、156、158、160、162、164、252和255各自包括至少一个宽边接口。这些宽边接口实现在单个时钟周期内跨接口传递32字节的存储器。
图3示出了访问存储器302的处理器(pru核心(pru0))301的示例。图3示出了pru301(诸如图2a的aux_pru_0205和pru_0219),以及共享存储器302(诸如图2b的smem235)之间的数据路径。pru301经由vbus-p303与共享存储器302交互,vbus-p303对应于图2b的内部cbass248。因此,图3示出了处理器301如何可访问共享存储器的示例。诸如pru301之类的处理器可以具有专用的加载存储指令,在图3中由加载指令304和存储指令305表示。
图4示出了访问存储器的处理器(pru核心)401(205、219、301)的可替代示例。然而,与图3不同,存储器是bs-ram404。pru核心404是可编程的。尽管为了便于说明而图示为在pru核心401的外部,但是mux402可以是pru核心401的部件,并且在pru核心401的内部。可替代地,mux402可以是接口电路(例如225、295)的部件。除了bs-ram404的存储器方面之外,处理器401还可以使用额外功能403。额外功能403包括由诸如图2b中的mac220、crc221和bswap224之类的加速器执行的此类功能。bs-ram404还包括一个或多个内部地址寄存器405,每个地址寄存器405存储一个或多个地址,诸如地址-x0406、地址-x1407、地址-x2408和地址-x3409。具有多个地址使bs-ram404通用。在至少一个示例中,在核心(例如aux_pru_0205)内部为不同的地址分配了不同的任务级别。在至少一个示例中,具有多个地址允许将逻辑结构覆盖到存储器(例如,bs-ram214)上。地址406、407、408和409可以以fifo逻辑结构布置。
在本公开的至少一个示例中,经由处理器宽边指令访问bs-ram404。xin将数据从宽边ram404加载到处理器寄存器中,而xout将数据从过程寄存器存储到bs-ram404。每个指令都有xid参数,该参数用于将加载/存储路由到正确的宽边附接电路。在一个示例中,针对队列用例,将三个xid分配给bs-ram404。xid可用于在队列模式下配置bs-ram404并返回队列状态。xout到xid-s将设置队列的地址范围,诸如在地址x和y(例如405、406)之间。bs-ram404中维护两个地址,一个用于头指针,并且一个用于尾指针。在至少一个示例中,xid-h与头指针一起使用并且xid-t与尾指针地址一起使用。通过如此配置的bs-ram404,bs-ram404可以在队列模式下操作。
在本公开的至少一个示例中,实现了队列弹出,其中尾指针将自动递增1并回绕到预定地址,尾指针地址值超过预定地址值。
尽管在整个以上公开中主要使用soc作为芯片的示例类型,但是应当理解,本文所述的技术可以应用于设计任何类型的ic芯片。例如,此类ic芯片可包括基于x86、risc或其他架构的通用或专用(asic)处理器,现场可编程门阵列(fpga)、图形处理器(gpu)、数字信号处理器(dsp)、片上系统(soc)处理器、微型控制器和/或相关芯片组。仅作为示例,ic芯片可以是可从德克萨斯州达拉斯的德克萨斯仪器股份有限公司获得的数字信号处理器、嵌入式处理器、soc或微型控制器的型号。
在整个说明书和权利要求书中已经使用了某些术语来指称特定的系统部件。本领域技术人员会认识到,不同方可能通过不同的名称来指代部件。本文档不意图在名称不同但功能相同的部件之间加以区分。在本公开和权利要求书中,术语包括“包括”和“包含”以开放形式使用,并因此应解释为意味着“包括但不限于...”。而且,术语“耦合”或“耦接”意图意味着间接或直接的有线或无线连接。因此,如果第一装置耦合到第二装置,则该连接可以通过直接连接或通过经由其他装置和连接的间接连接。叙述“基于”意图意味着“至少部分地基于”。因此,如果x基于y,则x可以是y和任何数量的其他因素的函数。
上面的讨论意在说明本公开的原理和各种实施方式。一旦完全认识以上本公开,许多变化和修改对于本领域技术人员将是明显的。意图所附权利要求被解释为涵盖所有此类变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!