基于地图数据的时空联合模型的行人重识别方法及系统与流程
本发明属于行人重识别技术领域,涉及一种基于地图数据的时空联合模型的行人重识别技术方案。
背景技术:
随着智慧城市的提出,城市建设开始向信息高度集中化转变。借助物联网、大数据和云计算等技术实现城市数据感知、分析与整合,来建设公共安全系数更高的智能化管理体系也是未来的发展趋势。
监控摄像头遍布公共场所,如机场、学校、火车站等,因此借助监控摄像头实现对重点行人进行检测,来判断该行人的运动轨迹和范围,是安防任务中的重要一环。然而,实际场景中,公共场所人流量大,仅依靠人工审查,很容易错过视频中的事件,同时效率低下,因此实现跨镜头的行人重识别,进而分析未授权人的行人或重点行人的运动轨迹,并进行实时跟踪是打击违法犯罪,构建平安城市的重要一环。
一直以来,从最开始的基于手工特征的行人重识别(从简单的颜色纹理特征到hog特征、sift特征等),到如今的基于深度学习的行人重识别方法,都通过挖掘数据中的先验信息,来获得更好的性能。基于深度学习的行人重识别方法可以分为,基于表征学习、基于度量学习、基于局部特征、基于视频序列和基于对抗生成网络(generativeadversarialnets,gan)的方法。
而挖掘数据先验信息的方法也从最开始的只包括行人身份信息,开始逐渐扩展到包括行人运动信息、背景信息、属性信息(行人的性别、头发、衣着等属性)、和人体姿态关键点等信息。基于gan的行人重识别方法分支,通过对抗生成网络实现不同数据集之间的相机风格迁移来生成额外的行人图像数据集,增加先验信息,不仅能够有效模型过拟合,同时也有效提升了网络的性能。
基于时空信息的跨域行人重识别方法,通过构建多模态网络,结合视觉概率和空间概率,有效地提升了行人重识别的准确率,但是这种方法只适用于运动规律的标准数据集。实际场景中的运动较标准数据集更加复杂,而且空间环境也更加复杂。因此,本发明提供了一种基于地图数据与孪生网络的贝叶斯时空联合模型的行人重识别方法,通过引入新的多模态数据——地图数据,通过摄像机网络进行地理时空建模,从而对视觉相似概率进行优化。
技术实现要素:
针对现有行人重识别技术存在的不足,本发明的目的是提供一种基于地图数据的时空联合模型的行人重识别方法。
本发明提供一种基于地图数据的时空联合模型的行人重识别方法,包括以下步骤:
步骤a,监控视频数据的采集,包括采集城市区域的监控视频数据,提取包括行人的图像帧;
步骤b,基于步骤a得到的行人图像进行预处理,将每张图像和其他图像配对,构建用于训练孪生网络的图像对;
步骤c,构建孪生网络学习输入图像对的视觉特征;
步骤d,使用交叉熵损失函数对网络计算损失;
步骤e,使用adam优化方法对网络进行优化,更新孪生网络中的权重和偏置项;
步骤f,构建基于地图数据的时间概率模型;
步骤g,利用步骤c得到的视觉概率,和步骤f得到的时空概率,计算最终的联合时空概率,得到行人重识别结果。
而且,步骤c中,设有图像对x(i),x(j),孪生网络包括5层卷积,通过第一个全连接层将图像对的卷积特征图转化为列向量f(x(i))和f(x(j)),计算图像队特征列向量之间的相似性向量χ(x(i),x(j)),输入到第二个全连接层,通过激活函数进行非线性处理,得到视觉特征相似概率p(x(i),x(j))。
而且,步骤f的实现方式为,
对图像涉及到的摄像机进行空间建模,将摄像机位置对应到地图数据中,获取两地之间运动的最小时间差τmin,
根据图像中携带的时空信息,时空概率
其中,pi,pj分别表示图像i,j对应的身份信息,ci,cj表示拍摄图像i,j的相应摄像头的id编号,k用于标识时间段,
而且,对时间概率模型使用高斯分布函数进行光滑处理。
而且,步骤g中,设步骤c得到视觉概率记为p,步骤f得到时空概率记为pst,最终的联合概率pjoint表示为贝叶斯联合概率如下,
其中,γ,φ为用于平衡视觉概率和时空概率的超参数。
本发明提供一种基于地图数据的时空联合模型的行人重识别系统,包括以下模块:
第一模块,用于监控视频数据的采集,包括采集城市区域的监控视频数据,提取包括行人的图像帧;
第二模块,用于基于第一模块得到的行人图像进行预处理,将每张图像和其他图像配对,构建用于训练孪生网络的图像对;
第三模块,用于构建孪生网络学习输入图像对的视觉特征;
第四模块,用于使用交叉熵损失函数对网络计算损失;
第五模块,用于使用adam优化方法对网络进行优化,更新孪生网络中的权重和偏置项;
第六模块,用于构建基于地图数据的时间概率模型;
第七模块,用于利用第三模块得到的视觉概率,和第六模块得到的时空概率,计算最终的联合时空概率,得到行人重识别结果。
而且,第三模块中,设有图像对x(i),x(j),孪生网络包括5层卷积,通过第一个全连接层将图像对的卷积特征图转化为列向量f(x(i))和f(x(j)),计算图像队特征列向量之间的相似性向量χ(x(i),x(j)),输入到第二个全连接层,通过激活函数进行非线性处理,得到视觉特征相似概率p(x(i),x(j))。
而且,第六模块的实现方式为,
对图像涉及到的摄像机进行空间建模,将摄像机位置对应到地图数据中,获取两地之间运动的最小时间差τmin,
根据图像中携带的时空信息,时空概率
其中,pi,pj分别表示图像i,j对应的身份信息,ci,cj表示拍摄图像i,j的相应摄像头的id编号,k用于标识时间段,
而且,对时间概率模型使用高斯分布函数进行光滑处理。
而且,第七模块中,设第三模块得到视觉概率记为p,第六模块得到时空概率记为pst,最终的联合概率pjoint表示为贝叶斯联合概率如下,
其中,γ,φ为用于平衡视觉概率和时空概率的超参数。
相比于现有方法,本发明的优势和积极效果:传统的基于时空信息的行人重识别网络,只考虑了理想场景下的行人数据。然而,真实场景中的运动更加复杂,同时可参考的时空先验信息较少。而本发明借助现有的地图数据,挖掘数据中的时空信息,结合孪生网络获取的视觉特征信息,得到更精确的识别结果。
附图说明
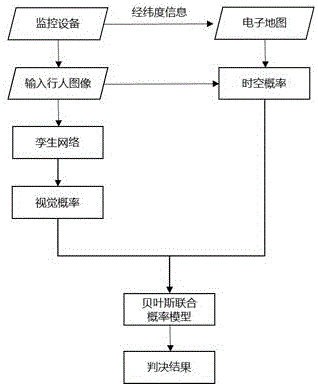
图1为本发明实施例基于地图数据与孪生网络的贝叶斯时空联合模型的行人重识别流程图。
图2为本发明实施例孪生网络结构图。
具体实施方式
下面结合附图和实施例对本发明技术方案做进一步说明。
本发明实施例所使用的环境:服务器的cpu为intelxeone5-2665,gpu为nvidiagtx108ti,操作系统为ubuntu16.04,编译环境为pytorch1.1.0,python3.5,cuda9.0以及cudnn7.1。本发明的实施例是行人重识别,具体流程参照图1,本发明实施例提供一种基于地图数据时空联合模型的行人重识别,包括步骤如下:
步骤a:数据采集与预处理
监控视频数据的采集。本发明所需采集的数据为城市区域监控视频数据,对于采集到的视频数据,需要通过解码器或者代码获得每帧图像,并通过现有的行人检测技术,来提取图像中的行人,本发明不予赘述。行人的标记信息包括行人身份信息、摄像机的编号、图像拍摄的时间信息,同时采集监控摄像头在城市中所处在的位置信息。
步骤b:构建图像对用于训练
孪生网络训练需要使用图像对以及对应的标签信息y,因此需要对数据进行预处理。将每张图像和其他图像配对,身份信息相同,则标签为y=1,即为正样本对,身份信息不同,标签则为y=0,即为负样本对。
步骤c:构建一个孪生网络学习图像的特征向量,即学习输入图像对的视觉特征
由于获取到的行人图像大小不一,需要将图像对x(i),x(j)归一化到统一大小,即72×72×3。其中,i和j表示图像身份信息。参见图2,实施例中,其结构为孪生网络模块,包括5层卷积:第一层的卷积核维度为7×7×64×3,其中卷积核的大小为7×7,通道数为64;第二层的卷积核维度为5×5×128×64,其中卷积核的大小为5×5,通道数为128;第三层的卷积核维度为5×5×256×128,其中卷积核的大小为5×5,通道数为256;第四层的卷积核维度为3×3×512×256,其中卷积核的大小为3×3,通道数为512;第五层的卷积核维度为3×3×512×512,其中卷积核的大小为3×3,通道数为512,网络使用relu作为激活函数。通过第一个全连接层将图像对的卷积特征图转化为128×1的列向量f(x(i))和f(x(j)),基于χsquaresimilarity函数计算图像队特征列向量之间的相似性向量χ(x(i),x(j)),该过程用公式表示为:
将所得χ(x(i),x(j))作为特征向量输入到第二个全连接层,通过激活函数sigmoid进行非线性处理,得到视觉特征相似概率p(x(i),x(j))(即后文步骤g需采用的视觉概率p),该过程用公式表示为:
ω为全连接层的权重项,b为全连接层的偏置项,σ(x)为输入像素x经过激活函数sigmoid的输出,e为自然对数的底。则预测的标签
步骤d:计算损失阶段,使用交叉熵损失函数对网络计算损失
使用交叉熵损失函数作为孪生网络的损失函数,该过程用公式表示为:
其中n表示训练样本对的数量,y表示真实标签,
步骤e:权重更新阶段,使用交叉熵损失函数对网络计算损失
使用adam方法作为孪生网络的优化器,其中优化器的初始化参数β1=0.9,β2=0.999,学习率为lr=0.0001。
步骤f:构建基于地图数据的时间概率模型
对图像涉及到的摄像机进行空间建模,将摄像机位置对应到地图数据中,通过直接调用现有地图软件api来获取两地之间运动的最小时间差τmin(包括不同交通工具,以及不同运动路径和轨迹)。例如通过调用两地之间的3条最短路线l1,l2,l3,以及每条线路采用步行、骑行和驾车不同方式需要的时间,最短时间记为τmin。
根据图像中携带的时空信息,那么其时空概率
其中,pi,pj分别表示图像i,j对应的身份信息,ci,cj表示拍摄图像i,j的相应摄像头的id编号。k用于表示第k个时间段(实施例中设100帧为一个时间段)。
由于概率估计模型中存在较多的抖动,因此为了减小抖动造成的干扰,使用高斯分布函数进行光滑处理,过程表示如下:
其中
步骤g,利用步骤c得到的视觉概率p,和步骤f得到的时空概率pst,计算最终的联合时空概率,得到行人重识别结果。
时空概率和视觉概率分布是独立的,本发明提出通过时空概率对视觉概率进行约束,从而获得更精确的识别精度。
由于时空概率和视觉概率量级可能存在差异,因此需要通过sigmoid激活函数对它们进行平衡。实施例步骤g中,利用步骤c得到的视觉概率p,和步骤f得到的时空概率pst,最终的联合概率pjoint可表示为贝叶斯联合概率:
其中γ,φ为用于平衡视觉概率和时空概率的超参数,其中γ=5,φ建议取值范围为[50,70]。通过地图数据中的先验信息约束视觉特征,能有效对行人在时间空间进行约束,从而进行更加高效的行人实时跟踪。
具体实施时,以上流程可采用计算机软件技术实现自动运行流程。本发明实施例也相应提供一种基于地图数据的时空联合模型的行人重识别系统,包括以下模块:
第一模块,用于监控视频数据的采集,包括采集城市区域的监控视频数据,提取包括行人的图像帧;
第二模块,用于基于第一模块得到的行人图像进行预处理,将每张图像和其他图像配对,构建用于训练孪生网络的图像对;
第三模块,用于构建孪生网络学习输入图像对的视觉特征;
第四模块,用于使用交叉熵损失函数对网络计算损失;
第五模块,用于使用adam优化方法对网络进行优化,更新孪生网络中的权重和偏置项;
第六模块,用于构建基于地图数据的时间概率模型;
第七模块,用于利用第三模块得到的视觉概率,和第六模块得到的时空概率,计算最终的联合时空概率,得到行人重识别结果。
各模块实现可参见相应步骤,本发明不予赘述。
本文中所描述的具体实例仅仅是对本发明作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!