一种文本类型确定方法及装置与流程
本发明涉及文本处理领域,尤其涉及一种文本类型确定方法及装置。
背景技术:
随着通信技术的发展,越来越多的人拥有了通信设备。通过通信设备,用户之间可以方便的进行对话。
用户之间的对话常携带有大量的有用信息,例如:可以对某角色的对话进行分类。当获得该角色的对话内容后,可以根据该对话内容确定该角色的对话的类型。例如:专利代理师常需要和专利委托方进行电话沟通,则可以将专利代理师的对话内容进行分类,例如:分为:沟通电学领域技术方案、沟通化学领域技术方案、沟通机械领域技术方案、沟通生物领域技术方案等。
上述对话内容类型,对于后续进行对话的统计分析十分重要,但是现在还没有确定对话的对话内容类型的方法。
技术实现要素:
鉴于上述问题,本发明提供一种克服上述问题或者至少部分地解决上述问题的一种文本类型确定方法及装置,技术方案如下:
一种文本类型确定方法,包括:
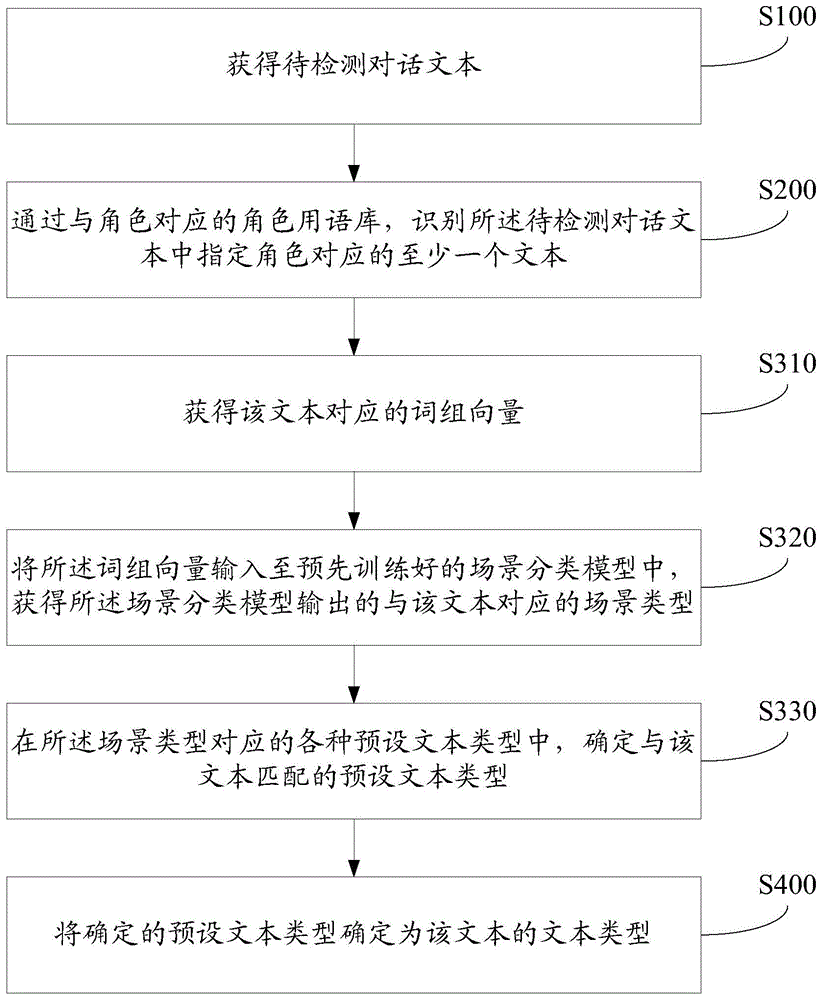
获得待检测对话文本;
通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本;
对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量,将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型,在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型;
将确定的预设文本类型确定为该文本的文本类型。
可选的,所述获得待检测对话文本包括:
获得对话语音;
对所述对话语音进行语音识别,获得语音识别结果;
将所述语音识别结果转化为待检测对话文本。
可选的,所述获得该文本对应的词组向量,包括:
对该文本进行结巴分词处理,获得分词结果向量;
对所述分词结果向量进行停用词过滤处理,获得词组向量。
可选的,所述场景分类模型的训练过程可以包括:
获得携带有场景类别标记的训练对话文本;
对所述训练对话文本进行结巴分词处理,获得训练分词结果向量;
对所述训练分词结果向量进行停用词过滤处理,获得训练词组向量;
对所述训练词组向量进行机器学习,获得场景分类模型,其中,所述场景分类模型的输入为:文本对应的词组向量,输出为:与该文本对应的场景类型。
可选的,所述在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型,包括:
在所述场景类型对应的每种预设文本类型的词库:确定该文本是否包含该词库中的词汇,如果是,则确定该文本与该预设文本类型匹配。
可选的,所述在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型,包括:
在所述场景类型对应的每种预设文本类型的文本模板库:确定该文本与该文本模板库中各文本模板的相似度,当该文本与该文本模板库中至少一个文本模板的相似度大于预设阈值时,则确定该文本与该预设文本类型匹配。
可选的,所述在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型,包括:
将该文本输入该文本对应的场景类型的文本类型识别模型中,获得文本类型识别模型输出的文本类型。
一种文本类型确定装置,包括:对话文本获得单元、指定角色文本获得单元、词组向量获得单元、场景类型获得单元、文本类型匹配单元和文本类型确定单元,
所述对话文本获得单元,用于获得待检测对话文本;
所述指定角色文本获得单元,用于通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本;
所述词组向量获得单元,用于对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量;
所述场景类型获得单元,用于将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型;
所述文本类型匹配单元,用于在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型;
所述文本类型确定单元,用于将确定的预设文本类型确定为该文本的文本类型。
可选的,所述对话文本获得单元包括:对话语音获得子单元、语音识别结果获得子单元和对话文本转化子单元,
所述对话语音获得子单元,用于获得对话语音;
所述语音识别结果获得子单元,用于对所述对话语音进行语音识别,获得语音识别结果;
所述对话文本转化子单元,用于将所述语音识别结果转化为待检测对话文本。
可选的,所述词组向量获得单元包括:分词结果向量获得子单元和词组向量获得子单元,
所述分词结果向量获得子单元,用于对该文本进行结巴分词处理,获得分词结果向量;
所述词组向量获得子单元,用于对所述分词结果向量进行停用词过滤处理,获得词组向量。
借由上述技术方案,本发明提供的一种文本类型确定方法及装置,可以获得待检测对话文本;通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本;对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量,将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型,在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型;将确定的预设文本类型确定为该文本的文本类型。本发明可以通过场景分类的技术手段确定对话文本的文本类型。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了本发明实施例提供的一种文本类型确定方法的流程示意图;
图2示出了本发明实施例提供的另一种文本类型确定方法的流程示意图;
图3示出了本发明实施例提供的另一种文本类型确定方法的流程示意图;
图4示出了本发明实施例提供的另一种文本类型确定方法的流程示意图;
图5示出了本发明实施例提供的一种文本类型确定装置的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
如图1所示,本发明实施例提供的一种文本类型确定方法,可以包括:
s100、获得待检测对话文本。
其中,待检测对话文本可以是包括至少两个角色的对话内容的文本。例如:待检测对话文本可以是老师和学生之间的对话文本,也可以是客服和客户之间的对话文本。可以理解的是,待检测对话文本是至少两个人之间的对话文本。本发明实施例可以从聊天工具的聊天记录中提取获得待检测文本,也可以从通话录音中识别获得待检测文本。在待检测文本中,各角色对应的文本可以按照时间先后顺序进行排列。在待检测文本中,不同角色对应的文本可以分开展示。例如,待检测文本的第一段为与老师对应的文本,待检测文本的第二段为与学生对应的文本。
可选的,如图2所示,步骤s100可以包括:
s110、获得对话语音。
本发明实施例可以通过已保存的通话录音中获得对话语音,也可以从至少两个角色的实时通话中获取对话语音。
s120、对所述对话语音进行语音识别,获得语音识别结果。
s130、将所述语音识别结果转化为待检测对话文本。
本发明实施例可以通过现有的语音识别技术和语音转文本技术,将对话语音进行语音识别后以文本的形式对语音识别结果进行输出,获得待检测对话文本。本发明实施例通过应用语音转文本技术,扩展了获得待检测对话文本的方式。
可选的,本发明实施例还可以使用现有的声纹识别技术,在对话语音中识别不同声纹所产生的语音,并在将语音转化为文本的过程中,将不同声纹产生的语音转化的文本分开进行展示。
s200、通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本。
其中,本发明实施例可以预先根据用户的实际需要构建角色用语库。例如,用户需要在待检测文本中区分老师和家长,则可以对老师和家长分别对应一个或多个关键词。例如:老师对应的关键词可以为:爸爸、妈妈、3班等,家长对应的关键词可以为:老师你好、我家孩子等。当待检测文本为:“小明爸爸,你好,我是3班的王老师。”“老师你好,请问有什么事吗?”时,本发明实施例可以将“小明爸爸,你好,我是3班的王老师”识别为老师对应的文本,将“老师你好,请问有什么事吗?”识别为家长对应的文本。当然,若用户只需在待检测文本中识别到特定角色对应的文本,也可以在角色用语库中只将该特定角色对应一个或多个关键词。例如:用户需要在待检测文本中识别出保险顾问对应的文本,则角色用语库只需包括与保险顾问对应的关键词,关键词可以为先生、女士和保险顾问等,当待检测文本为:“喂你好”“噢您好,请问是张先生吗?我是保险顾问,王某某,嗯有看到您是有在刚刚的时候预约咨询这个重大疾病保险还有印象吧?”“唉你好你好”时,本发明实施例可以将“噢您好,请问是张先生吗?我是保险顾问,王某某,嗯有看到您是有在刚刚的时候预约咨询这个重大疾病保险还有印象吧?”识别为保险顾问对应的文本。可以理解的是,上述举例仅为便于理解本发明的技术方案可选的实施方式,本发明的技术方案还以除上述举例以外其他的实施方式,本发明在此不作限定。
s310、对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量。
本发明实施例可以通过word2vec、语言技术平台云(ltpcloud)等词组向量获得模型对文本进行分词后获得与该文本对应的词组向量。
可选的,如图3所示,步骤s310可以包括:
对所述指定角色对应的所述至少一个文本中的任一个文本:s311、对该文本进行结巴分词处理,获得分词结果向量。
其中,结巴(jieba)分词是python中文分词组件,可以对中文文本进行分词、词性标注、关键词抽取等功能,并且支持自定义词典。本发明实施例可以通过对文本进行结巴分词,获得分词结果向量。例如:当文本为“小明酒后开车,把小红的车撞了。”时,则本发明实施例对该文本进行结巴分词处理,获得的分词结果向量为[“小明”,“酒后”,“开车”,“把”,“小红”,“的”,“车”,“撞”,“了”]。
s312、对所述分词结果向量进行停用词过滤处理,获得词组向量。
其中,本发明实施例可以预先设置停用词表,停用词表中包括一个或两个以上的停用词。本发明实施例可以依据停用词表,将分词结果向量中存在的停用词删掉,获得词组向量。例如:当文本为“一旦确诊了,确诊说这个客户他是得了重大疾病了,保险公司这边拿到材料以后会就会把这个钱先行打到客户的账户上”时,经过结巴分词和停用词过滤后获得的词组向量可以为[“确诊”,“确诊”,“说”,“客户”,“重大疾病”,“保险公司”,“拿到”,“材料”,“钱”,“先行”,“打到”,“客户”,“账户”]。
s320、将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型。
可选的,如图4所示,所述场景分类模型的训练过程可以包括:
s001、获得携带有场景类别标记的训练对话文本。
其中,场景类别可以是用户根据自身需求确定的一种或多种类别。例如:训练对话文本可携带的场景类别标记可以包括沟通电学领域技术方案标记、沟通化学领域技术方案标记、沟通机械领域技术方案标记和沟通生物领域技术方案标记在内的至少一种标记。训练对话文本可携带的场景类别标记可以包括理赔告知有误标记和违禁词标记在内的至少一种标记。
s002、对所述训练对话文本进行结巴分词处理,获得训练分词结果向量。
s003、对所述训练分词结果向量进行停用词过滤处理,获得训练词组向量。
步骤s002至步骤s003与步骤s311至步骤s312的原理相同,可参考上述对步骤s311至步骤s312的说明,本发明在此不作赘述。
s004、对所述训练词组向量进行机器学习,获得场景分类模型,其中,所述场景分类模型的输入为:文本对应的词组向量,输出为:与该文本对应的场景类型。
其中,场景分类模型可以是卷积神经网络模型。本发明实施例可以对携带有场景类别标记的训练对话文本进行机器学习,将学习到的文本特征与场景类别标记对应的场景类别匹配,当需要确定某文本的场景类别时,将该文本的词组向量输入至训练好的场景分类模型中,确定该文本对应的场景类型。
s330、在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型。
其中,预设文本类型可以是在某场景类别下具体的一个或多个场景子类型。例如:当场景类型为沟通电学领域技术方案时,与该场景对应的预设文本类型可以包括电气工程、测控技术和电气自动化等。当场景类型为理赔告知有误时,该场景类型对应的预设文本类型可以包括:理赔金额错误、理赔期限错误和理赔条件错误等。本发明实施例提供包括以下三种确定文本匹配的预设文本类型的方式:
方式一:在所述场景类型对应的每种预设文本类型的词库:确定该文本是否包含该词库中的词汇,如果是,则确定该文本与该预设文本类型匹配。
本发明实施例可以对每种预设文本类型预先构建对应的词库,其中,不同预设文本类型的词库中的词汇可以不同或部分相同。本发明实施例可以根据词汇匹配的方式,查找文本中是否包含某一预设文本类型对应词库中的词汇,如果是,则确定该文本与该预设文本类型匹配。需要注意的是,在不同预设文本类型的词库中的词汇部分相同时,可以确定文本与多个预设文本类型匹配。例如:电气工程对应的词库和测控技术对应的词库都包括词汇:电路设计,当文本中出现“电路设计”时,可以确定该文本与电气工程和测控技术匹配。
可选的,预设文本类型可以是违规文本类型,违规文本类型的词库包含一个或多个违规词,当文本中出现违规词时,可以确定该文本与违规文本匹配。例如:在文本对应的场景类型为理赔告知有误时,确定该文本是否包含理赔告知有误对应的违规文本类型的词库中的违规词,如果有,则确定该文本与违规文本类型匹配。可以理解的是,当该文本不包含违规词时,确定该文本与不违规文本类型匹配。
方式二、在所述场景类型对应的每种预设文本类型的文本模板库:确定该文本与该文本模板库中各文本模板的相似度,当该文本与该文本模板库中至少一个文本模板的相似度大于预设阈值时,则确定该文本与该预设文本类型匹配。
具体的,本发明实施例可以对文本的词组向量构建word2vec模型,得到该词组向量在预设维度上映射的向量表达。例如:当词组向量为[“拿到”,“医院”,“诊断”,“报告”,“理赔”]时,该词组向量中的各个词在预设维度上映射的向量可以依次为wordembedding[“拿到”]、wordembedding[“医院”]、wordembedding[“诊断”]、wordembedding[“报告”]和wordembedding[“理赔”],则该词组向量在预设维度上映射的向量表达可以为各个词在预设维度上映射的向量的加和平均:(wordembedding[“拿到”]+wordembedding[“医院”]+wordembedding[“诊断”]+wordembedding[“报告”]+wordembedding[“理赔”])/5。本发明实施例可以通过词组向量在预设维度上映射的向量表达与文本模板在预设维度上映射的向量表达进行余弦相似度计算,计算确定该文本与文本模板之间的相似度。
其中,预设阈值可以是用户根据实际需要确定的相似度阈值。需要注意的是,文本可以与多个文本模板的相似度均大于预设阈值,在此情况下,本发明实施例可以确定该文本与该多个文本模板对应的预设文本类型匹配。
方式三、将该文本输入该文本对应的场景类型的文本类型识别模型中,获得文本类型识别模型输出的文本类型。
其中,本发明实施例可以对每个场景类型单独训练一个文本类型识别模型。当某个文本确定场景类型后,将该文本输入至于该场景类型对应的文本类型识别模型中,确定该文本的文本类型。
其中,文本类型识别模型的训练过程可以包括:
获得携带有文本类别标记的训练对话文本;
对所述训练对话文本进行结巴分词处理,获得训练分词结果向量;
对所述训练分词结果向量进行停用词过滤处理,获得训练词组向量;
对所述训练词组向量进行机器学习,获得文本类型识别模型,其中,所述文本类型识别模型的输入为:文本对应的词组向量,输出为:与该文本对应的文本类型。
本发明实施例可以通过以上三种方式的其中一种确定文本匹配的预设文本类型。
s400、将确定的预设文本类型确定为该文本的文本类型。
本发明实施例提供的一种文本类型确定方法,可以获得待检测对话文本;通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本;对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量,将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型,在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型;将确定的预设文本类型确定为该文本的文本类型。本发明可以通过场景分类的技术手段确定对话文本的文本类型。
与上述方法实施例相对应,本发明实施例还提供一种文本类型确定装置,其结构如图5所示,可以包括:对话文本获得单元100、指定角色文本获得单元200、词组向量获得单元300、场景类型获得单元400、文本类型匹配单元500和文本类型确定单元600。
所述对话文本获得单元100,用于获得待检测对话文本。
所述指定角色文本获得单元200,用于通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本。
所述词组向量获得单元300,用于对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量。
所述场景类型获得单元400,用于将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型。
所述文本类型匹配单元500,用于在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型。
所述文本类型确定单元600,用于将确定的预设文本类型确定为该文本的文本类型。
可选的,所述对话文本获得单元100包括:对话语音获得子单元、语音识别结果获得子单元和对话文本转化子单元。
所述对话语音获得子单元,用于获得对话语音。
所述语音识别结果获得子单元,用于对所述对话语音进行语音识别,获得语音识别结果。
所述对话文本转化子单元,用于将所述语音识别结果转化为待检测对话文本。
可选的,所述词组向量获得单元300包括:分词结果向量获得子单元和词组向量获得子单元。
所述分词结果向量获得子单元,用于对该文本进行结巴分词处理,获得分词结果向量。
所述词组向量获得子单元,用于对所述分词结果向量进行停用词过滤处理,获得词组向量。
可选的,所述文本类型匹配单元500具体用于在所述场景类型对应的每种预设文本类型的词库:确定该文本是否包含该词库中的词汇,如果是,则确定该文本与该预设文本类型匹配。
可选的,所述文本类型匹配单元500具体用于在所述场景类型对应的每种预设文本类型的文本模板库:确定该文本与该文本模板库中各文本模板的相似度,当该文本与该文本模板库中至少一个文本模板的相似度大于预设阈值时,则确定该文本与该预设文本类型匹配。
可选的,所述文本类型匹配单元500具体用于将该文本输入该文本对应的场景类型的文本类型识别模型中,获得文本类型识别模型输出的文本类型。
本发明实施例提供的一种文本类型确定装置,可以获得待检测对话文本;通过与角色对应的角色用语库,识别所述待检测对话文本中指定角色对应的至少一个文本;对所述指定角色对应的所述至少一个文本中的任一个文本:获得该文本对应的词组向量,将所述词组向量输入至预先训练好的场景分类模型中,获得所述场景分类模型输出的与该文本对应的场景类型,在所述场景类型对应的各种预设文本类型中,确定与该文本匹配的预设文本类型;将确定的预设文本类型确定为该文本的文本类型。本发明可以通过场景分类的技术手段确定对话文本的文本类型。
在本申请中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!