计算集群的制作方法
本实用新型涉及计算机领域,特别涉及计算集群。
背景技术:
为了释放cpu的压力,服务器多采用在通用计算机主板上插pcie加速卡的方式,由pcie加速卡来提供加速处理。
深度神经网络是近几年机器学习领域的流行话题,在许多任务上取得了先进的成果。深度神经网络算法的执行需要较多的计算资源,而一张pcie加速卡所能提供的计算资源是有限,有时不能满足日益增长的计算需求。
技术实现要素:
有鉴于此,本实用新型实施例提供计算集群,以满足日益增长的计算需求。
为实现上述目的,本实用新型实施例提供如下技术方案:
一种计算集群,用于提供深度神经网络算法计算;
所述计算集群包括至少一个基本计算模块;所述至少一个基本计算模块中的任一基本计算模块与相邻基本计算模块间通过线缆互联;
所述基本计算模块包括:
pcb互联桥接卡;
通过所述pcb互联桥接卡点对点全互联的m个pcie加速卡;m为不小于2的自然数。
可选的,所述任一基本计算模块表示为基本计算模块p,与所述任一基本计算模块相邻的基本计算模块表示为基本计算模块q;所述基本计算模块p中的n个pcie加速卡,分别通过线缆与所述基本计算模块q中的n个pcie加速卡互联;所述n为不小于所述m的自然数。
可选的,所述pcie加速卡包括:pcb基板;布置在所述pcb基板上的人工智能芯片;布置在所述pcb基板上的连接器;所述连接器通过第一链接线束与所述人工智能芯片相连接;所述第一链接线束包含至少一对高速差分屏蔽线。
可选的,所述基本计算模块p的n个pcie加速卡中的任一pcie加速卡表示为pcie加速卡x;所述基本计算模块q中与所述pcie加速卡x互联的pcie加速卡表示为pcie加速卡y;所述pcie加速卡x与所述pcie加速卡y间的线缆为目标线缆;所述目标线缆的一端与所述pcie加速卡x的连接器相连,另一端与所述pcie加速卡y的连接器相连。
可选的,所述线缆包括至少一对高速差分屏蔽线。
可选的,所述pcb互联桥接卡上设置有与所述m个pcie加速卡一一对应的卡槽;任一pcie加速卡通过至少一个第二链接线束连接至相应的卡槽;所述第二链接线束包含至少一对高速差分屏蔽线。
可选的,所述第二链接线束的接头部件为金手指,任一卡槽内设置有夹持金手指的弹针。
可见,本实用新型实施例所提供的计算集群包括至少一个基本计算模块,基本计算模块中的pcie加速卡可提供内存和计算能力。在基本计算模块内部,pcie加速卡间通过pcb互联桥接卡实现点对点全互联,在相邻基本计算模块之间,则是通过线缆实现跨模块互联。
上述基本计算模块的互联方式,可实现根据计算需求增加基本计算模块,从而满足日益增长的计算需求。
附图说明
图1为本实用新型实施例提供的基本计算模块的示例性结构;
图2为本实用新型实施例提供的pcie加速卡点对点全互联的示意图;
图3为本实用新型实施例提供的基本计算模块之间通过线缆连接的示意图;
图4为本实用新型实施例提供的基本计算模块之间芯片级点对点连接的示意图;
图5为本实用新型实施例提供的pcie加速卡示例性结构;
图6为本实用新型实施例提供的连接器和线缆的示例性结构;
图7为本实用新型实施例提供的pcb互联桥接卡背面的一种示例性结构;
图8为本实用新型实施例提供的互联网络示意图;
图9为本实用新型实施例提供的两基本计算模块的机箱安装在服务器上的连接关系示意图;
图10为本实用新型实施例提供的两基本计算模块间通过线缆和连接器连接的立体示意图;
图11为本实用新型实施例提供的同一机箱内相邻基本计算模块间的芯片级点对点互联示意图;
图12为本实用新型实施例提供的多机柜情况下pcie加速卡间的点对点连接示意图。
具体实施方式
为了引用和清楚起见,下文中使用的技术名词、简写或缩写总结如下:
pcb:printedcircuitboard,印制电路板;
pcie:peripheralcomponentinterconnectexpress,高速串行计算机扩展总线标准;
金手指:goldenfinger,金手指由众多金黄色的导电触片组成,因其表面镀金而且导电触片排列如手指状,所以称为“金手指”。
本实用新型提供深度神经网络算法计算的计算集群,以满足日益增长的计算需求。
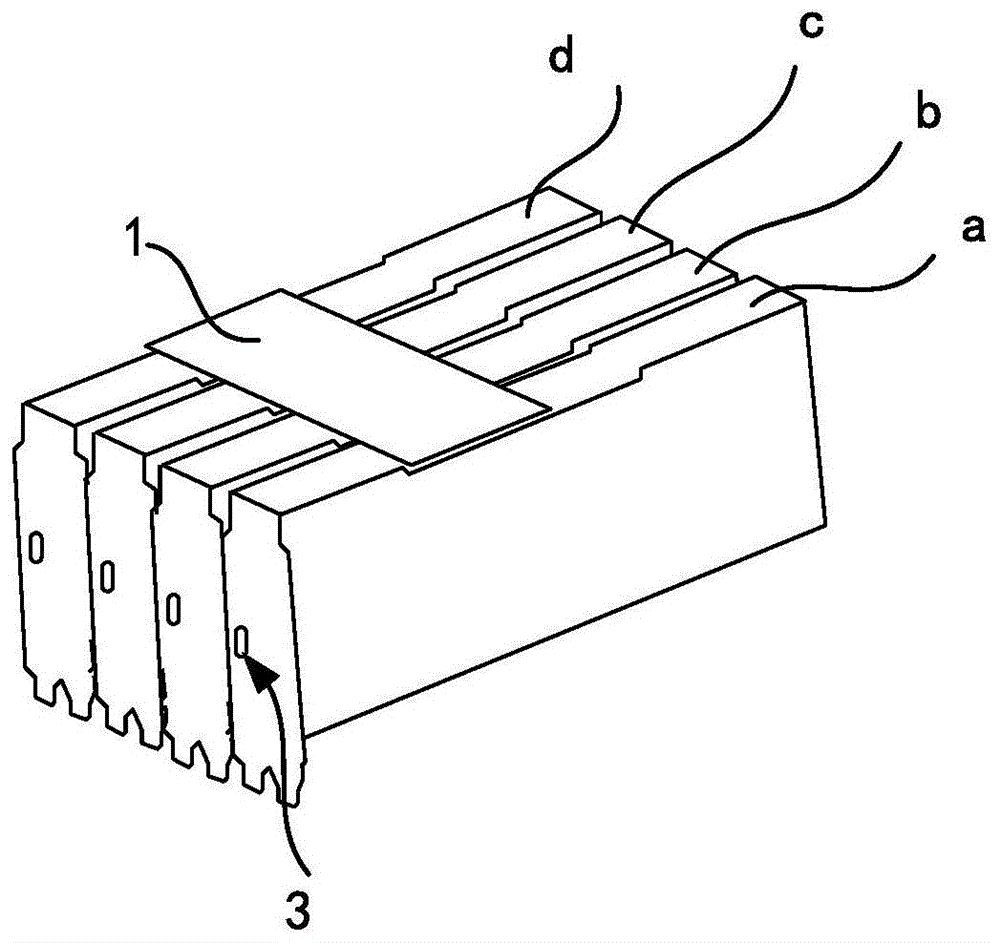
上述计算集群包括至少一个基本计算模块。图1示出了基本计算模块的示例性结构,包括:
pcb互联桥接卡1,通过pcb互联桥接卡1点对点全互联的m个pcie加速卡。其中,m为不小于2的自然数。本领域技术人员可根据需要灵活设计m的取值,在此不作赘述。
需要说明的是,图1示出的是4个pcie加速卡,分别以a-d表示。pcie加速卡a-d点对点全互联的示意图可参见图2。本文后续还将介绍pcb互联桥接卡1如何实现点对点全互联。
在上述计算集群中,任一基本计算模块与相邻基本计算模块间通过线缆互联。
为方便起见,可将上述任一基本计算模块称为基本计算模块p,将与基本计算模块p相邻的基本计算模块称为基本计算模块q;
在一个示例中,基本计算模块p中的n个pcie加速卡,可分别通过线缆与基本计算模块q中的n个pcie加速卡互联(n为不小于m的自然数)。
图3即示了m=4,n=1情况下,基本计算模块p与基本计算模块q之间通过线缆连接的情况:
在图3中,基本计算模块p的4个pcie加速卡表示为p0-p3,而基本计算模块q的4个pcie加速卡表示为q4-q7,其中,p3与q4间通过线缆2连接。
基本计算模块p与基本计算模块q之间的点对点全互联的示意图可参见图4。在图4中,以带三角的示意线表示基本计算模块p与基本计算模块q间的芯片级点对点连接。
可见,在本实用新型实施例中,计算集群包括至少一个基本计算模块,基本计算模块中的pcie加速卡可提供内存和计算能力。在基本计算模块内部,pcie加速卡间通过pcb互联桥接卡实现点对点全互联,而在相邻基本计算模块之间,则是通过线缆实现跨模块互联。上述基本计算模块的互联方式,可实现根据计算需求增加基本计算模块,从而满足日益增长的计算需求。
下面介绍上述pcie加速卡和pcb互联桥接卡的具体结构。
请参见图5,pcie加速卡示例性地可包括:
壳体(未示出);
pcb基板51;pcb基板51位于壳体内;
布置在pcb基板51上的人工智能芯片52;
在一个示例中,人工智能芯片包括但不限于:cpu(centralprocessingunit,中央处理器)gpu(graphicsprocessingunit,图形处理器)、fpga(field-programmablegatearray,现场可编程门阵列)、asic(applicationspecificintegratedcircuits,专用集成电路)以及类脑芯片。
布置在pcb基板51上的(高速)连接器3;请参见图3,从壳体外面观察可见连接器3的接口部分。
从内部来看,连接器3通过第一链接线束(图3中以link2表示)与人工智能芯片52相连接。
具体的,link2一端与连接器3的针脚,另一端连接人工智能芯片52的通信针脚。
link2包含至少一对差分屏蔽线(信号线)。
上述差分屏蔽线具体为高速差分屏蔽线。通常认为,信号线长度小于信号有效波长的1/6时为低速,而大于信号有效波长的1/6为高速。
在一个示例中,link2可包含16对高速差分屏蔽线,用于串行传输数据。所包含的差分屏蔽线对数越高,带宽越大。本领域技术人员可根据需要设计高速差分屏蔽线的对数,在此不作赘述。
与之相对应,前述的线缆2也包括至少一对高速差分屏蔽线,线缆2与link2所包含的高速差分屏蔽线的对数是相同的。
若将基本计算模块p前述n个pcie加速卡中的任一pcie加速卡表示为pcie加速卡x,将与pcie加速卡x互联的pcie加速卡表示为pcie加速卡y;将pcie加速卡x与pcie加速卡y间的线缆2称为目标线缆,则目标线缆的一端与pcie加速卡x的连接器3相连,另一端与pcie加速卡y的连接器3相连。
需要说明的是,连接器类似于一个插座,线缆的两端类似与插座适配的插头,插座和插头可以多种方式设计,只要保证可进行高速信号传输即可。
通过上述线缆、连接器和第一链接线束,可在相邻基本计算模块之间实现芯片级的直接点对点互联,无需中间层传输,为基本计算模块间的高速、低时延的数据交换提供了硬件支持。
图6示出了连接器3和线缆2的一种示例性结构。线缆2中的16对高速差分屏蔽线采用双排设计(图6只显示出了一排),其接头部件裸露了两排金手指。
而连接器3的外壳中设置有夹持金手指的弹针或卡槽。
此外,为了连接不易松动,线缆2和连接器3上配置了卡接机构。
此外,仍请参见图5,人工智能芯片52还通过至少一个第二链接线束连接至pcb互联桥接卡2的卡槽。
与第一链接线束相类似,第二链接线束包含至少一对高速差分屏蔽线。
以m=4为例,为实现基本计算模块内部各pcie加速卡间的点对点互联,每一pcie加速卡中的人工智能芯片52需要使用三个第二链接线束连接至pcb互联桥接卡2的卡槽,在图5中,上述三个第二链接线束分别表示为link0、link1和link3。
为了实现点对点互联,pcb互联桥接卡2上设置有与m个pcie加速卡一一对应的卡槽(也即m个卡槽)。以m=4为例,图7示出了pcb互联桥接卡的一种示例性结构,在pcb互联桥接卡2的背面(以封装后pcb互联桥接卡可见的一面为正面)设置有4个卡槽,这4个卡槽分别对应pcie加速卡p0-p3,每一pcie加速卡的三个第二链接线束(link0、link1和link3)均连接至相应的卡槽。
更具体的,上述第二链接线束的接头部件为金手指,而卡槽内设置有夹持金手指的弹针。
在pcb互联桥接卡2的内部,具有互联网络,互联网络与插入槽内的第二链接线束连接,以实现点对点全互联连接。
在一个示例中,请参见图8,互联网络实现了如下连接:
pcie加速卡p0的link0与pcie加速卡p3的link0互联;
pcie加速卡p1的link0与pcie加速卡p2的link0互联;
pcie加速卡p0的link1与pcie加速卡p2的link1互联;
pcie加速卡p1的link1与pcie加速卡p3的link1互联;
pcie加速卡p0的link3与pcie加速卡p1的link3互联;
pcie加速卡p2的link3与pcie加速卡p3的link3互联。
在实际应用中,可将至少一个基本计算模块安装在机箱中,机箱内安装的基本计算模块可以是以下数量的任意一种:2,4,8,16…2n(n为不小于1的自然数)。
前述提及计算集群包括至少一个基本计算模块,则在本实施例中,一个计算集群可包括一个或多个机箱,或者,一个计算集群可包括一个机箱内的部分基本计算模块。
以一个机箱中包括两基本计算模块,每一基本计算模块包括芯片级点对点全互联的4个pcie加速卡为例,则一个机箱中包括8个pcie加速卡(以p0-p3,q4-q7表示)。
图9即示出了包括两基本计算模块的机箱安装在服务器上的连接关系示意图,图10则示出了两基本计算模块间通过线缆2和连接器3连接的立体示意图。
为进一步节省空间,在本实用新型其他实施例中,上述一个或一个以上的机箱可安装在同一个机柜中。
并且,在本实施例中,相邻机箱间通过芯片级点对点连接实现互联。当需要使用多个机柜时,相邻机柜间亦可通过芯片级点对点连接实现互联。
以一个机箱中包括两个基本计算模块,一基本计算模块包括芯片级点对点全互联的4个pcie加速卡为例,上述4个pcie加速卡中,除2个pcie加速卡上的连接器3用于机箱内部的点对点互联外,其余2个pcie加速卡上的连接器3可用于机箱间或机柜间的芯片级点对点连接。
若以p0-p4,q5-q7表示一个机箱内的8个pcie加速卡,则请参见图11,pcie加速卡p2、p3、q4、q5上的连接器可用于同一机箱内相邻基本计算模块间的芯片级点对点互联;pcie加速卡p0、p1、p2、q6、q7上的连接器可用于通过带矩形的示意线连接到相邻机箱或者机柜对应的端口。
在多机柜情况下,pcie加速卡间的点对点连接可参见图12。在图12中,一机柜示例性地包含了4个机箱(以机箱1-4表示),同一机箱中的8个pcie加速卡则以0-7表示。
需要说明的是,在现有的计算集群中,基本计算模块之间无法建立芯片间的点对点互联,这意味着只能在同一模块内实现互联,无法跨模块互联,更无法实现跨系统的点对点互联。从而限制了pcie加速卡点对点互联的数量和规模以及拓扑结构,进而降低了整个集群的性能。
而在本实用新型中,通过连接器和线缆可支持跨模块互联、跨系统(机箱或机柜)互联,多系统互联,具有更加灵活和多样的互联拓扑,为高速、低时延的数据交换提供了硬件支持。
对所公开的实施例的说明,使本领域专业技术人员能够实现或使用本实用新型。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本实用新型的精神或范围的情况下,在其它实施例中实现。因此,本实用新型将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!