具有非易失性突触阵列的神经网络电路的制作方法
背景
本发明涉及神经网络电路,且更具体地涉及具有使用模拟值的非易失性突触阵列的神经网络电路。
背景技术:
人工神经网络(ann)是模仿人脑的计算模型的神经网络。可以将神经网络描述为许多神经元,这些神经元之间通过突触相互连接。连接的强度或每个突触的权重参数可以通过学习过程进行调整作为可训练参数。近年来,使用ann的人工智能(ai)已应用于各个领域,诸如视觉和听觉检测/识别、语言翻译、游戏、医疗决策、财务或天气预报、无人机、无人驾驶汽车等。
传统上,神经网络的计算需要具有多个中央处理单元(cpu)和/或图形处理单元(gpu)的高性能云服务器,这是因为:由于移动设备的有限的功率和计算资源,计算的复杂性禁止移动设备在本地运行ai程序。与这样的基于通用cpu和gpu的方法相比,通过专用的互补金属氧化物半导体(cmos)逻辑来加速神经网络的计算的其他现有的专用集成电路(asic)或现场可编程门阵列(fpga)方法可以是功率高效的,但是仍然要浪费不必要的功率和等待时间来将数据移至及移出对经训练的权重参数进行存储的单独的片外非易失性存储器(nvm)。如此,需要消耗明显更少的计算资源的神经网络电路。
技术实现要素:
在本发明的一个方面,一种非易失性神经网络的突触电路,包括:输入信号线;参考信号线;输出线;以及用于生成输出信号的单元。该单元包括:上选择晶体管,该上选择晶体管具有电耦合至输入信号线的栅极;以及电阻改变元件,该电阻改变元件具有串联连接至上选择晶体管的一个端部以及电耦合至参考信号线的另一端部。电阻改变元件的值能够编程为改变输出信号的大小。上选择晶体管的漏极电耦合至输出线。
在本发明的另一方面,一种突触电路,包括:第一输入信号线和第二输入信号线;参考信号线;第一输出线和第二输出线;第一单元和第二单元;以及交叉耦合式锁存电路。交叉耦合式锁存电路包括第一反相器和第二反相器以及第一信号节点和第二信号节点。第一反相器的输入端子在第一信号节点处耦合至第二反相器的输出端子,并且第二反相器的输入端子在第二信号节点处连接至第一反相器的输出端子。所述单元中的每个单元包括:第一上选择晶体管,该第一上选择晶体管在其栅极处电耦合至第一输入信号线;以及第二上选择晶体管,该第二上选择晶体管电耦合至第二输入信号线。第一上选择晶体管和第二上选择晶体管的源极端子耦合至公共节点。在第一单元中,第一上选择晶体管和第二上选择晶体管的漏极端子分别耦合至第一输出信号线和第二输出信号线。在第二单元中,漏极端子反向(reversed),其中,第一上选择晶体管连接至第二输出线,并且第二上选择晶体管连接至第一输出线。第一单元的公共节点连接至交叉耦合式锁存电路的第一信号节点,并且第二单元的公共节点连接至交叉耦合式锁存电路的第二信号节点。参考信号线耦合至交叉耦合式锁存电路的第一反相器和第二反相器。
附图说明
将参考本发明的实施方式,本发明的实施方式的示例可以在随附附图中示出。这些图旨在为说明性的,而非限制性的。尽管在这些实施方式的上下文中总体上描述了本发明,但是应当理解的是,不旨在将本发明的范围限制为这些特定实施方式。
图1示出了根据本公开的实施方式的神经网络的示意图。
图2示出了根据本公开的实施方式的突触阵列的示意图。
图3示出了根据本公开的实施方式的突触的示意图。
图4示出了根据本公开的实施方式的另一突触的示意图。
图5示出了根据本公开的实施方式的另一突触的示意图。
图6示出了根据本公开的实施方式的另一突触的示意图。
图7示出了根据本公开的实施方式的另一突触的示意图。
图8示出了根据本公开的实施方式的另一突触的示意图。
图9a至图9b示出了用于对阈值电压(vth)进行编程的常规方法与根据本公开的实施方式的方法的比较。
图10a至图10b示出了根据本公开的实施方式的用于对浮置栅极节点的阈值电压(vth)进行编程的另一种方法。
图11示出了根据本公开的实施方式的用于对浮置栅极节点的阈值电压(vth)进行编程的说明性过程的流程图。
图12a至图12c示出了根据本公开的实施方式的差分信令。
图13示出了包括根据本公开的实施方式的神经网络的芯片的示意图。
图14示出了包括根据本公开的实施方式的非易失性突触阵列的神经网络的示意图。
图15示出了根据本公开的实施方式的另一突触的示意图。
图16示出了说明图15的输入线和输出线上的用于实现根据本公开的实施方式的二进制乘法的信号的表格。
图17示出了根据本公开的实施方式的另一突触的示意图。
图18示出了根据本公开的实施方式的另一突触的示意图。
图19示出了根据本公开的实施方式的另一突触的示意图。
图20示出了根据本公开的实施方式的另一突触的示意图。
图21示出了根据本公开的实施方式的另一突触的示意图。
图22示出了根据本公开的实施方式的另一突触的示意图。
图23示出了现有技术中的常规神经网络系统的示意图。
图24示出了根据本公开的实施方式的由包括片上非易失性神经网络的soc和外部神经网络加速器设备构成的分层神经网络计算系统的示意图。
图25示出了根据本公开的实施方式的由多个soc构成的分布式神经网络系统的示意图。
图26示出了根据本公开的实施方式的逻辑友好型nvm集成神经网络系统的示意图。
图27示出了根据本公开的实施方式的另一逻辑友好型nvm集成神经网络系统的示意图。
具体实施方式
在以下描述中,出于说明的目的,阐述了具体细节以提供对本公开的理解。然而,对于本领域技术人员将显而易见的是,可以在没有这些细节的情况下实践本公开。本领域技术人员将认识到,以下描述的本公开的实施方式可以以各种方式且使用各种手段来执行。本领域技术人员还将认识到,在本公开可以提供实用性的其他领域中及其范围内存在其他改型、应用和实施方式。相应地,以下描述的实施方式说明了本公开的特定实施方式,并且意在避免使本公开含糊不清。
说明书中对“一个实施方式”或“实施方式”的引用意味着结合该实施方式描述的特定特征、结构、特性或功能包括在本公开的至少一个实施方式中。说明书中各个地方出现的短语“在一个实施方式中”、“在实施方式中”等不一定全都指同一实施方式。
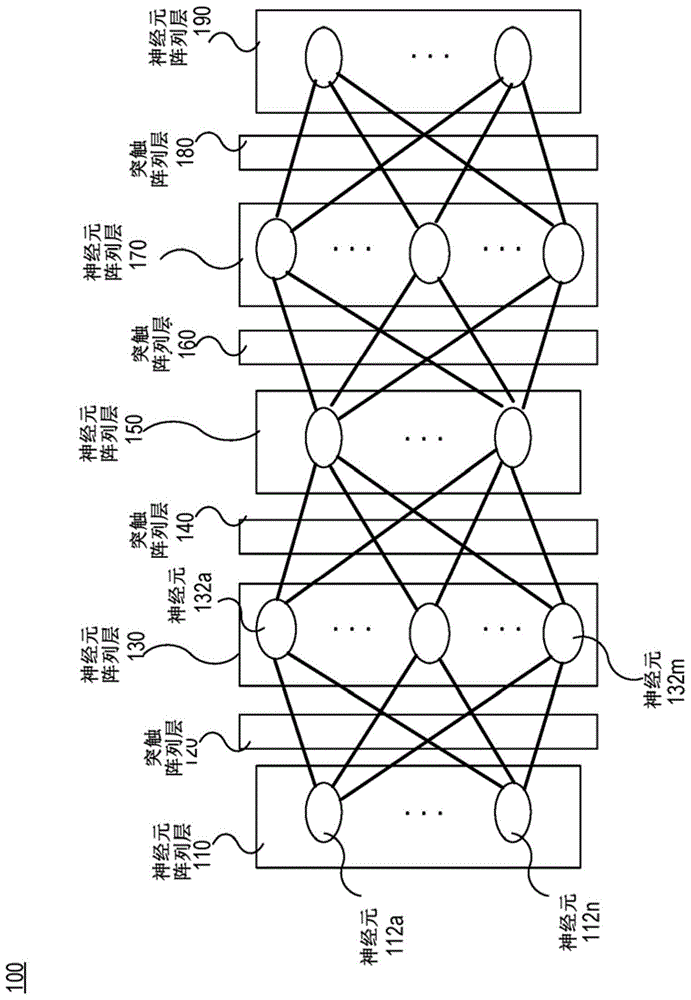
图1示出了根据本公开的实施方式的神经网络100的示意图(在整个说明书中,相同的附图标记表示相同的元件)。如所描绘的,神经网络100可以包括五个神经元阵列层(或简称为神经元层)110、130、150、170和190,以及突触阵列层(或简称为突触层)120、140、160和180。神经元层中的每个神经元层(例如110)可以包括适当数量的神经元。在图1中,仅示出了五个神经元层和四个突触层。然而,对于本领域普通技术人员而言应当显而易见的是,神经网络100可以包括其他适当数量的神经元层,并且突触层可以设置在两个相邻的神经元层之间。
要指出的是,神经元层(例如,110)中的每个神经元(例如,112a)可以通过突触层(例如,120)中的m个突触连接至下一神经元阵列层(例如,130)中的神经元(例如,132a至132m)中的一个或更多个神经元。例如,如果神经元层110中的神经元中的每个神经元电耦合至神经元层130中的所有神经元,则突触层120可以包括n×m个突触。在实施方式中,每个突触可以具有描述两个神经元之间的连接强度的可训练的权重参数(w)。
在实施方式中,输入神经元信号(a输入)与输出神经元信号(a输出)之间的关系可以通过具有以下等式的激活函数来描述:
a输出=f(w×a输入+bias)(1)
其中,a输入和a输出分别是表示至突触层的输入信号和来自突触层的输出信号的矩阵,w是表示突触层的权重的矩阵,并且bias是表示a输出的偏差信号的矩阵。在实施方式中,w和bias可以是可训练的参数并且被存储在逻辑友好型非易失性存储器(nvm)中。例如,训练/机器学习过程可以与已知数据一起使用以确定w和bias。在实施方式中,函数f可以是非线性函数,诸如s型(sigmoid)、双曲正切(tanh)、修正线性单元(relu)、带泄露修正线性单元(leakyrelu)等。在实施方式中,当(w×a输入+bias)大于特定阈值时,可以激活a输出。
作为示例,等式(1)中描述的关系可以示出用于具有两个神经元的神经元层110、突触层120和具有三个神经元的神经元层130。在该示例中,表示来自神经元阵列层110的输出信号的a输入可以被表示为2行乘1列的矩阵;表示来自突触层120的输出信号的a输出可以被表示为3行乘1列的矩阵;表示突触层120的权重的w可以被表示为具有6个权重值的3行乘2列的矩阵;并且表示添加至神经元层130的偏差值的bias可以被表示为3行乘1列的矩阵。应用于等式(1)中的(w×a输入+bias)的每个元素的非线性函数f可以确定a输出的每个元素的最终值。作为另一示例,神经元阵列层110可以接收来自传感器的输入信号,并且神经元阵列层190可以表示响应信号。
在实施方式中,神经网络100中可能有许多神经元和突触,并且等式(1)中的矩阵乘法和求和可能是会消耗大量计算资源的过程。在常规的内存中处理(processing-in-memory)计算方法中,计算设备使用模拟电气值而不是使用数字逻辑和算术组件来在nvm单元阵列内执行矩阵乘法。这些常规设计旨在通过减少cmos逻辑与nvm组件之间的通信来减少计算负荷并降低功率要求。然而,由于大规模nvm单元阵列中的电流输入信号路径上的大的寄生电阻,这些常规方法易于在至每个突触的电流输入信号上具有大的变化。而且,通过大阵列中的半选择单元的潜电流(sneakcurrent)改变了经编程的电阻值,从而导致不希望的编程干扰和神经网络计算精度的下降。
与常规方法不同,在实施方式中,功率高效的神经网络可以基于具有差分架构的逻辑友好型非易失性突触,其中,差分架构可以包括选择晶体管和逻辑友好型nvm。在实施方式中,全差分突触架构可以使作为乘法器的突触电路的运算范围加宽。与常规架构相比,在实施方式中,轻微的乘法误差对于补偿经训练的权重参数的某些水平的量化噪声可能是有益的。
如以下详细讨论的,在实施方式中,至突触层120、140、160和180中的每个突触的输入信号可以被引导至突触的选择晶体管的栅极端子,从而抑制乘法噪声。在实施方式中,乘法器电流可以大约是栅极端子电压乘以可变电阻器或nvm的电阻电平。
图2示出了根据本公开的实施方式的突触阵列200的示意图。如所描绘的,突触阵列200可以包括:布置成行和列的非易失性突触210;分别电耦合至列选择晶体管263的正输出电流线(位线)266;分别电耦合至列选择晶体管268的负输出电流线(位线反向线(位线互补线,bitlinebarline))267。在实施方式中,列选择晶体管263的漏极端子可以电耦合至感测电路250的正电流端口241,并且列选择晶体管268的漏极端子可以电耦合至感测电路250的负电流端口242。
在实施方式中,每个非易失性突触210可以存储一个正权重值和一个负权重值。在实施方式中,每个非易失性突触210可以电耦合至:信号线(或等效地为参考信号线)(例如,sl1)264,以接收参考电压输入201;字线(或等效地为输入信号线)(例如,wl1)265,以接收信号电压输入202;正输出线(例如,bl1)266,以输出正电流输出203;以及负输出线(例如,blb1)267,以输出负电流输出204。
在实施方式中,信号电压输入202和参考电压输入201中的每一者可以分别与正权重值和负权重值两者相关联,并且正电流输出203可以与正权重值相关联,并且负电流输出204可以与负权重值相关联。
在实施方式中,存储在每个非易失性突触210中的正(或负)权重值可以被表示为可变电阻值的倒数,并且信号电压输入202和参考电压输入值201可以是电压值。在实施方式中,正电流输出203的值可以是正权重值与信号电压输入202的乘积的结果,并且负电流输出204的值可以是负权重值与信号电压输入202的乘积的结果。
如图2所描绘的,非易失性突触阵列200的每行可以共享参考电压线sl264和信号电压线wl265,其中,每个sl可以向相对应的行中的非易失性突触提供参考电压输入201,并且每个wl可以向相对应的行中的非易失性突触提供信号电压输入202,使得行中的非易失性突触可以基本上接收相同的信号电压输入和相同的参考电压输入。
如上文所论述的,非易失性突触阵列200的每列可以共享正输出电流线(bl)266和负输出电流线(bl-反向)267,即,该列的突触的每个正电流输出203可以由相对应的bl266收集,并且该列的突触的每个负电流输出204可以由相对应的bl-反向线267收集。如此,bl线266上的电流可以是来自该列的突触的正电流输出203的总和。类似地,在实施方式中,bl-反向线267上的电流值可以是来自该列的突触的负电流输出204的总和。
在实施方式中,每个正输出电流线(bl)266可以电耦合至相对应的列选择晶体管263的源极端子,并且每个负输出电流线(bl-反向)267可以电耦合至相对应的列选择晶体管268的源极端子。在实施方式中,一对bl线263和bl-反向线268的列选择晶体管可以在栅极端子处接收来自外部列选择电路(图2中未示出)的相同的列选择信号。在实施方式中,来自列选择晶体管263的漏极端子的线可以电耦合至感测电路250的正电流输入241。在实施方式中,来自列选择晶体管268的漏极端子的线可以电耦合至负电流输入242。
在实施方式中,正电流端口241的电流值(ibl)261可以是正输出电流bl266上的值,该正输出电流bl接收其相应的列选择晶体管263上的列选择信号。同样,负电流输入242的电流值(ibl-反向)262可以是负输出电流线bl-反向267,该负输出电流线bl-反向接收其相应的列选择晶体管268上的列选择信号。
在实施方式中,突触210的行中的一个或更多个行可以在wl265上具有固定的输入信号电压,并且这样的行上的突触可以为其列存储偏差值。在实施方式中,突触阵列可以实现等式(1)中的矩阵乘法
w×a输入+bias
其中,w可以是突触阵列,并且a输入是表示wl输入的矩阵。
在实施方式中,每个非易失性突触210可以具有存储负权重和正权重的两个电路(或等效地为单元)。在实施方式中,如上文所讨论的,权重值可以由可变电阻的倒数值分别表示为1/rn=w_负和1/rp=w_正。阵列200中的每行突触可以接收输入信号a输入作为电压。响应于输入信号,阵列200中的每个突触可以产生通过bl(例如,bl0266)的正输出电流和通过blb(例如,267)的负输出电流,其中,正输出电流blc的值可以被表示为:blc=a输入×w_正,并且负输出电流blbc可以被表示为:blbc=a输入×w_负。
在实施方式中,可以在单独的训练阶段中确定(计算和调整)用于神经网络100的每个突触层的权重值w。然后,可以在推断阶段将输入信号a输入施加至神经网络100,其中,可以使用预定权重来生成输出值。在实施方式中,可以在训练阶段期间确定的权重值在推断阶段期间可以不改变。
在实施方式中,如上文所论述的,bl(例如,bli)可以电耦合至突触阵列200的列中的突触的所有输出线,并且bl-反向线(例如,blbi)可以电耦合至突触阵列200的突触的所有输出线。这种配置可以使每个bl266(或blb267)上的电流值为阵列200中的突触的相对应的列的单独计算的电流值的总和。在实施方式中,线bln和线blbn上的输出电流可以被表示为:
对于第n列的行,bln=∑(w_正-行×a输入-行)(2a)
对于第n列的行,blbn=∑(w_负-行×a输入-行)(2b)
在实施方式中,阵列200的行中的一个或更多个行可以具有固定的输入信号电压,并且这些行上的突触可以为其列存储偏差值。在这种情况下,bln和blbn上的总电流可以被表示为:
bln=∑(w_正-行×a输入-行)+bias_正(3a)
blbn=∑(w_负-行×a输入-行)+bias_负(3b)
在实施方式中,在感测电路250中,来自突触阵列的电流输入信号(isig=ibl261或iblb262)可以使用电容性跨阻抗放大器(capacitivetransimpedanceamplifier,ctia)转换为电压信号(vsig),并且进一步使用模拟数字转换器(adc)进行处理以生成数字信号。在实施方式中,adc可以具有使用偏移抵消列比较器和计数器的单斜率列adc架构。与诸如流水线型或逐次逼近型adc之类的其他adc架构相比,这种设计可以使用最小的面积和功率消耗。
在实施方式中,神经网络100中的每个突触层(例如,120)可以具有电气组件(图2中未示出),该电气组件可以电耦合至bl266和blb267并且对bl和blb线上的输出电流进行电处理。例如,该电气组件可以提供差分感测,将输出电流信号转换为电压信号,进一步转换为数字信号,并且在累加器中对数字信号进行求和。在另一示例中,该电气组件可以对累加的值执行其他各种处理运算,诸如归一化和激活,从而实施用于等式(1)的a输出的激活函数。在实施方式中,最终的a输出可以被存储在数据缓冲器中并且用于生成用于神经网络100中的下一神经阵列层的输入信号。
要指出的是,在实施方式中,单独的电路(图2中未示出)可以被包括在神经网络100中以执行诸如下述各者之类的辅助功能:(1)路由器/控制器,该路由器/控制器将神经网络100的逻辑神经元突触结构映射至突触阵列200的物理地址映射;(2)驱动电路,该驱动电路将输入信号驱动至一配置的突触的适当行;(3)选择电路,该选择电路为由多于一列突触共享的感测电路提供列选择;(4)电压生成器,该电压生成器生成用于选择突触的参考电压;以及(5)存储装置,该存储装置存储用于路由器控制器和感测电路250的配置。
图3示出了根据本公开的实施方式的突触300的示意图。在实施方式中,突触300可以用作图2中的突触210。如所描绘的,突触300可以包括:一对输入晶体管311和312;以及一对非易失性电阻改变元件r_p313和r_n314(在下文中,术语“非易失性电阻改变元件”和“电阻器”可互换地使用)。换言之,突触300可以具有一对1t-1r(一个晶体管-一个电阻器)结构。在实施方式中,电阻器r_p313和r_n314可以是逻辑友好型非易失性电阻改变元件。在实施方式中,突触300可以被认为具有两个单元332和334,其中,每个单元可以具有一个输入晶体管311(或312)和电阻器r_p312(或r_n314)。
在实施方式中,逻辑友好型非易失性电阻改变元件r_p313(或r_n314)可以与突触300可以记忆/存储的正(或负)权重参数相关联。在实施方式中,每个电阻器可以电耦合至输入晶体管(例如,311)的源极端子,并且参考信号线264可以将参考信号施加至电阻器。在实施方式中,字线(wl)265可以将输入信号电压施加至输入晶体管(例如,311)的栅极端子。
在实施方式中,可以在训练阶段中将电阻值r(=r_p或r_n)编程到电阻改变元件中。当将突触输入信号施加在wl265上时,突触输出电流可以对权重(由1/r表示)与来自前一个神经元的输入值a输入的乘积进行近似,其中,a输入可以由wl265上的电压表示。
在实施方式中,存储在突触阵列200中的神经网络参数可以具有大约相似数量的正权重参数和负权重参数。阵列200中的未使用的电阻元件可以被编程为具有比预设值高的电阻值。通过每个未使用的电阻元件的电流应当基本上为零,使得单元的输出电流基本上不被添加至单元的bl(或blb)上的输出电流。因此,使未使用的电阻元件对计算的影响最小化,并降低了功率消耗。经训练的权重参数可以被量化并编程到电阻改变元件中,而不会使神经网络计算的精确度降低很多。当在训练阶段中对电阻器r_p313(或r_n314)的电阻值r进行编程并且通过wl265施加缩放的突触输入信号wl时,bl266(或blb267)上的突触输出电流ic可以由等式(4)和(5)描述:
dic/dwl=~gm/(1+gm*r)=~1/r(当r足够大于1/gm时)(4)
其中,gm是输入晶体管的电导,并且
ic=~wl/r=~wa输入(其中w=1/r,a输入=wl)(5)
其中,w和a输入可以近似地产生其乘法结果ic。
如等式(5)所示,输出电流ic可以对输入信号(输入电压a输入)与权重(w)的乘积进行近似。与常规系统不同,在突触300中发生的等式(5)的这种模拟乘法运算不需要使用复杂的数字逻辑门,从而显著降低了突触结构的复杂性和对计算资源的使用。
在实施方式中,输入信号a输入可以是来自前一个神经元的输出信号(如图1所示)并且被驱动至输入晶体管311(或312)的栅极。将输入信号a输入驱动至栅极可以使大突触阵列中的由寄生电阻产生的噪声最小化,这是因为没有静态导通电流流入到选择晶体管的栅极中。相反,在常规系统中,输入信号被驱动至突触的选择器或电阻改变元件,由于在运算期间的静态电流流动和大阵列中的大寄生电阻,这容易导致至每个突触的电流输入信号具有较大的变化。
在常规系统中,当对电阻改变元件进行编程时,通过大阵列中的半选择单元的潜电流会改变先前编程的电阻值,从而导致不希望的编程干扰。相反,在实施方式中,可以使输入晶体管311(或312)能够将编程脉冲仅驱动至大阵列中的所选择的电阻器313(或314)。因此,在实施方式中,未选择的突触可以不干扰对所选择的突触的编程,其中,可以通过将合适的偏差条件应用于bl(或blb)和sl节点来对所选择的突触进行编程。
作为示例而非限制,突触阵列200可以位于突触层120中,其中,来自神经元阵列层110中的前一个神经元(例如,112a)的输出信号可以输入至突触阵列200的突触300,并且来自突触300的bl266和blb267的输出信号可以输入至神经元阵列层130中的接下来的神经元(例如,132a至132m)中的一个或更多个神经元。
在实施方式中,电阻器313(或314)可以利用诸如非易失性mram、rram或pram或者单层多晶嵌入式闪存之类的各种电路(或存储器)来实现,其中,电路可以被编程为记忆(存储)可以由电阻的倒数表示的关联参数。要指出的是,在实施方式中,可以在具有模拟值的突触内完成乘法运算,而无需使用数字逻辑和算术电路。
图4示出了根据本公开的实施方式的另一突触400的示意图。在实施方式中,突触400可以示出图3中的电阻器313和314的示例性实现方式。换言之,在实施方式中,电阻器313可以由图4中的框452中的组件来实现。
如图4所描绘的,突触400包括一对逻辑兼容的嵌入式闪存单元432和434,其中,闪存单元中的浮置栅极节点fg_p和fg_n可以分别与该突触400所记忆/存储的正权重参数和负权重参数相关联。
在实施方式中,wl420上的突触输入信号能够在可以汲取bl406和blb407上的差分突触输出电流(ibl和iblb)的两个分支之间共享。在实施方式中,编程字线(或简称为编程线pwl)418、写入字线(或简称为写入线wwl)416和擦除字线(或简称为擦除线ewl)414可以用于提供用于逻辑兼容的嵌入式闪存单元432和434的编程、写入和擦除运算的附加控制信号。
在实施方式中,存储单元432和434可以包括逻辑晶体管,以消除标准逻辑过程之外的任何额外过程支出。在实施方式中,直接连接至pwl418的耦合晶体管422(和423)可以被增大尺寸,以用于将浮置栅极节点(fg_p和fg_n)与通过pwl418提供的控制信号进行更高的耦合。在实施方式中,直接耦合至pwl418的耦合晶体管422(或423)可以比写入晶体管424(或425)相对更大。在高编程电压被驱动至pwl418和wwl416的情况下,可以通过在向bl406(或blb407)施加0伏的同时将电子注入到fg_p中来选择存储单元432(或434)并对其进行编程,而可以通过将vdd施加至blb407(或bl406)并将vdd施加至wl420以由此使未选择的单元434(或432)的选择晶体管截止来使未选择的单元434(或432)被禁止编程。在下文中,术语“选择晶体管”是指具有电耦合至bl406或blb407的栅极的晶体管。
在实施方式中,在仅将高擦除电压驱动至wwl416的情况下,可以通过从fg注射电子来对所选择的wl进行擦除。在编程和擦除运算期间,未选择的wl可能不会被驱动至任何高于vdd的电压;因此,未选择的wl中没有干扰。在实施方式中,fg节点电压可以是pwl418、wwl416上的信号和在fg节点中存储的电子数量的函数。可以通过控制pwl418和wwl416处的电压以及存储在fg节点处的电荷来对电耦合至fg的读取晶体管(例如,462)的电导进行编程。
在实施方式中,当对嵌入式闪存单元432(或434)的阈值电压进行编程时,并且当通过wl420提供缩放的突触输入信号时,可以存在阈值电压的特定范围,使得在单元输出电流(=ibl和iblb)与经编程的权重参数以及输入信号成比例的情况下可以近似满足等式(5)。
在实施方式中,神经网络100可以对随机误差或权重参数的小变化具有鲁棒性。在实施方式中,当在神经网络100的计算期间对预训练的权重参数w进行量化时,只要乘法误差在特定范围内,就可以利用来自等式(5)的轻微的乘法误差来对神经网络性能或推断精度进行优化。此外,来自所提出的近似乘法器的轻微的乘法误差可以补偿神经网络100的经训练的权重参数的量化噪声。然而,为了避免在对神经网络进行重复训练之后由于大的单元阈值电压偏移而导致的严重的单元保留误差,可以通过wwl416施加有意的自愈电流,这是因为有意的自愈电流可以修复(cure)电耦合至嵌入式闪存单元432和434的wwl416的设备的受损的栅极氧化物。在实施方式中,可能不需要每次训练或推断都施加自愈电流,因此对性能或功率消耗具有最小的影响。
在实施方式中,每个单元(例如,432)可以包括耦合晶体管422、写入晶体管424和上(或第一)选择晶体管460、读取晶体管462和下选择晶体管464。要指出的是,突触400中的单层多晶嵌入式闪存可以用作电阻改变元件,并且电耦合至闪存的浮置栅极(fg)的读取晶体管(例如,462)的电导可以用作电阻改变元件。在实施方式中,读取晶体管(例如,462)的电导可以由其各自的fg节点fg_p或fg_n的阈值电压vth确定。可以首先使用平衡阶跃脉冲编程方法来对fg节点fg_p或fg_n的vth进行粗略编程,然后具有降低的电压的后续恒定脉冲编程步骤可以对vth值进行微调,以对待存储在突触400中的权重值进行精确编程。结合图10a至图10b对编程步骤进行描述。
图5示出了根据本公开的实施方式的突触500的示意图。在实施方式中,突触500可以用作图2中的突触210。如所描绘的,突触500可以具有三对1t-1r,其中,三个字线wla、wlb和wlc可以电耦合至六个晶体管的栅极。要指出的是,突触500可以具有其他合适数量的输入晶体管和电阻器以及电耦合至输入晶体管的字线。例如,在实施方式中,突触500可以被修改成使得可以删除字线wla和1t-1r单元550和551中的组件,即,每个单元可以具有两对1t-1r。在另一示例中,在实施方式中,突触500可以被修改成使得每个单元可以具有四对1t-1r和四个字线(输入信号线)wl。
在实施方式中,突触500的sl、bl和blb可以具有与突触300的突触300中的sl、bl和blb类似的功能。突触300与突触500之间的不同在于,突触500可以通过三个字线wla、wlb和wlc接收来自前一个神经元的输入信号。更具体地,来自每个wl的信号可以被驱动至相对应的输入晶体管的栅极端子。
要指出的是,每个突触500可以电耦合至三个字线wla、wlb和wlc,而图2中的每个突触210被示出为耦合至一个字线265。因此,要指出的是,图2中的每个字线265共同指电耦合至包括一个或更多个输入晶体管的突触的一个或更多个字线。
在实施方式中,突触500可以被认为具有两个单元532和534,其中,每个单元可以具有三对1t-1r(一个晶体管-一个电阻器),并且每个1t-1r对可以电耦合至wl和sl。
要指出的是,突触500中的每个电阻器可以由诸如非易失性mram、rram或pram或者单层多晶嵌入式闪存之类的各种电路(或存储器)来实现,其中,电路可以被编程为记忆(存储)可以由电阻表示的关联参数。在实施方式中,突触500中的每个电阻器可以由图4中的框452中的组件来实现,其中,每个突触500可以以与突触400类似的方式电连接至pwl、wwl和ewl。
图6示出了根据本公开的实施方式的另一突触600的示意图。在实施方式中,突触600可以用作图2中的突触210。如所描绘的,单元632和634中的每个单元可以包括两个晶体管(例如,602和606)和一个电阻器(例如,613),并且电耦合至两个输入信号(或字)线、字线(wl)和反向字线(互补字线,worklinebar,wlb)以及一个参考信号线sl。要指出的是,每个突触600可以电耦合至两个字线,而图2中的每个突触210被示出为耦合至一个字线265。因此,如上文所论述的,图2中的每个字线265共同指电耦合至包括一个或更多个输入晶体管的突触的一个或更多个字线。
在实施方式中,突触电阻器r_p613和r_n614、参考信号线sl、输出电流线bl和blb可以具有与图3中的突触230的相对应的组件类似的功能。例如,电耦合至wl和相应的电阻器r_p613和r_n614的输入选择晶体管602和604可以分别对应于输入选择晶体管211和212。
与图3中的突触300相比,突触600可以电耦合至另一输入信号线wlb,其中,wlb可以提供相对于wl的差分输入信号电压。在实施方式中,附加的输入选择晶体管606和608可以通过其栅极端子电耦合至wlb。在实施方式中,输入选择晶体管606和608的源极端子可以分别电耦合至电阻器r_p613和r_n614。在实施方式中,晶体管602的漏极端子可以电耦合至bl,并且晶体管606的漏极端子可以电耦合至blb。同样,晶体管604的漏极端子可以电耦合至blb,并且晶体管608的漏极端子可以电耦合至bl。
在实施方式中,突触600可以接收差分输入信号,其中,wl(向共模参考)提供正输入信号电压a_正,而wlb(向共模参考)提供负输入信号电压a_负。在实施方式中,r_p613可以存储正权重w_正,并且r_n614可以存储负权重w_负。因此,在实施方式中,bl上的输出信号电流(blo)可以是来自两个单元532和534的两个输出信号的总和:
blo=a_正×w_正+a_负×w_负(6)
同样,blb上的输出信号电流(blbo)可以是来自两个单元532和534的两个输出信号的总和:
blbo=a_正×w_负+a_负×w_正(7)
因此,与图3所描绘的在突触300的wl上具有单端信令的其他实施方式相比,如所描绘的在wl和wlb上具有差分信令的一些实施方式可以在bl和blb上具有更大范围的输出电流。另外,如所描绘的具有差分输入信令的实施方式可以抑制晶体管偏移噪声以及由于电源电压或温度的变化所引起的共模噪声。
要指出的是,突触600中的每个电阻器可以由诸如非易失性mram、rram或pram或者单层多晶嵌入式闪存之类的各种电路(或存储器)来实现,其中,电路可以被编程为记忆(存储)关联参数。图7示出了根据本公开的实施方式的另一突触700的示意图。在实施方式中,突触700可以示出图6中的电阻器613和614的示例性实现方式。换言之,框752中的组件可以对应于图6中的电阻器613。
如图7所描绘的,突触700可以包括两个单元732和734。在实施方式中,单元732(或734)可以类似于突触400的单元432(或434),不同之处在于,单元732(或734)可以包括附加的上选择晶体管720(或722)和附加的输入信号线wlb。在实施方式中,晶体管720(或722)的栅极可以电耦合至输入信号线wlb,并且晶体管720(或722)的漏极可以电耦合至输出信号线blb。
图8示出了根据本公开的实施方式的另一突触800的示意图。在实施方式中,突触800可以用作图2中的突触210。如所描绘的,突触800可以包括两个单元832和834,其中,每个单元可以包括三个电阻器和六个晶体管。突触800可以具有2t-1r结构,即,每个单元可以包括三组2t-1r单元802。突触800可以电耦合至六个输入信号线:三个字线wla、wlb和wlc;以及三个反向字线wlab、wlbb和wlcb。要指出的是,突触800的每个单元可以包括其他合适数量的2t-1r单元802。在实施方式中,每对wl和wlb(例如,wla和wlab)可以向单元832和834提供差分输入信号。
在实施方式中,参考信号线sl可以向单元832和834提供参考信号。在实施方式中,输出信号线bl和blb中的每一者可以从单元832中的三个晶体管的漏极端子和单元834中的三个晶体管的漏极端子收集输出信号。在实施方式中,突触800可以接收差分输入信号,其中,每个wli提供正输入信号电压a_正_i,并且每个wlbj提供负输入信号电压a_负_j。在实施方式中,每个r_p可以存储正权重w_正_i,并且每个r_n可以存储负权重w_负_j。在实施方式中,bl上的输出信号电流(blo)可以是来自两个单元832和834的六个输出信号的总和:
blo=∑(a_正_i×w_正_i)+∑(a_负_j×w_负_j)(8)
同样,blb上的输出信号电流(blbo)可以是来自两个单元832和834的六个输出信号的总和:
blbo=∑(a_正_i×w_负_j)+∑(a_负_j×w_正_i)(9)
要指出的是,突触800中的每个电阻器可以由诸如非易失性mram、rram或pram或者单层多晶嵌入式闪存之类的各种电路(或存储器)来实现,其中,电路可以被编程为记忆(存储)关联参数。在实施方式中,突触800中的每个电阻器可以由图7中的框752中的组件来实现。其中,每个突触800可以以与突触700类似的方式电连接至pwl、wwl和ewl。
通常,可以通过将电子注入到浮置栅极中来改变读取晶体管(例如,462)的电导。图9a至图9b示出了用于对浮置栅极节点的阈值电压(vth)进行编程的两种常规方法(列910和914)与根据实施方式的方法(列912)的比较。图9a示出了表格900,其包括在对浮置栅极单元(432)进行编程运算期间向端子pwl和wwl施加的信号的电压高度和宽度,从而将电子注入到浮置栅极中。如所描绘的,表格900包括分别对应于施加电压信号的三种方法的三个列910、912和914。
列910示出了常规的增量阶跃脉冲编程方法,其中,每个后续编程步骤的编程电压与前一个步骤相比增加了具有恒定脉冲宽度(t_脉冲)的量delta。列912示出了根据实施方式的平衡阶跃脉冲编程方法,其中,第一步骤具有比列910中的编程方法长特定设计参数(m)的编程脉冲宽度。列914示出了常规的恒定脉冲编程方法。其中,每个步骤具有相同的编程电压和编程脉冲宽度。
图9b示出了根据图9a中的三种方法的浮置栅极单元(432或434)的vth950的曲线。在图9b中,三个曲线960、962和964分别对应于三种方法910、912和914,并且图9b中的每个曲线示出了图9a中的相对应的方法的每个步骤之后的浮置栅极单元(432或434)的vth。
基于曲线950,在这三种方法中,根据本公开的实施方式的平衡阶跃脉冲编程方法可以是优选的。每个步骤将vth增加大约相同的量delta,因此可以对vth进行精确编程,从而导致与其他方法相比更窄的vth变化。
图10a至图10b示出了根据本公开的实施方式的用于对浮置栅极单元(432或434)的阈值电压(vth)进行编程的另一方法。图10a示出了表格1000,其包括在对浮置栅极单元(432或434)进行编程运算期间向端子pwl和wwl施加的信号的电压高度和宽度,从而将电子注入到浮置栅极中。图10b示出了在图10b的每个步骤处存储在浮置栅极单元(432或434)中的vth的曲线1050。
如所描绘的,对于若干初始步骤(在此,直至步骤4),可以使用平衡阶跃脉冲编程方法(也结合图9a和图9b提及)将单元vth粗略编程为不超过目标vth的值。在一些实施方式中,直至这些初始步骤(直至步骤4)可以以可接受的余量实现目标vth。在一些其他实施方式中,可能需要对目标vth进行更精细的编程。在这些实施方式中,当前vth与目标vth之间的差可以小于每个步骤处的vth的可用增量(图10b中的delta)。然后,进一步应用后续恒定脉冲编程步骤以对vth进行精确编程。
在实施方式中,后续恒定脉冲编程步骤使用减小的编程脉冲高度(在图10a中为alpha)、但增加的脉冲宽度(t_脉冲*n,n不小于1.0)将vth设置为目标。结果,图10a至图10b中的编程方案可以将最终编程的单元阈值电压控制为低于由来自目标vth的片上基准电压参考所产生的可用电压阶跃(=delta)。
图11示出了根据本公开的实施方式的用于对浮置栅极节点的阈值电压(vth)进行编程的说明性过程的流程图1100。在步骤1102处,可以向浮置栅极单元(432或434)的pwl和wwl端子施加具有第一高度(例如,vpgm)和第一宽度(t_脉冲*m,m不小于1.0)的电压脉冲(例如,图10a中的步骤1),从而将电子注入到浮置栅极中。在步骤1104处,可以在将每个脉冲的高度相比于前一个脉冲增加预设值(例如,delta)的同时向pwl和wwl端子施加第一电压脉冲序列(诸如,图10a中的步骤2至4)。
在步骤1106处,可以确定在施加第一脉冲序列之后是否达到目标vth。如果确定的答案是肯定的,则过程进行至步骤1108。在步骤1108处,过程停止。否则,在步骤1110处,可以向pwl和wwl端子施加第二电压脉冲序列(诸如,图10a中的步骤5至19)。在实施方式中,第二脉冲序列的每个脉冲具有可以不比先前步骤中的脉冲(t_脉冲)窄的宽度(t_脉冲*n,n不小于1.0)。在实施方式中,第二脉冲序列具有比第一高度低的高度(vpgm-alpha),并且第二脉冲序列具有不比第二宽度(t_脉冲)窄的宽度(t_脉冲*n)。在实施方式中,作为示例,该值可以是:m=9.0,n=5.0,alpha=0.8v,delta=0.1v,并且vpgm=7.2v。
要指出的是,图9a至图11中的用于对浮置栅极节点的vth进行编程的方法可以应用于单元732和734。更具体地,与图9a中的列912相关联的方法和/或结合图10a至图10b描述的方法可以用于对单元732和734的vth进行编程。
图3至图8中的每个突触可以通过两个输出信号线bl和blb生成两个输出信号,其中,可以应用差分信令技术来生成两个输出信号。差分信令可以降低对晶体管偏移的敏感性以及来自电源电压和温度的变化的共模噪声,其会在用于加权和计算的突触或设备的现有技术设计中向输出电流引入严重的误差。
图12a至图12c示出了根据本公开的实施方式的差分信令。如图12a所描绘的,ibl线1212和ibl-反向线1214可以分别是通过突触的输出信号线bl(例如,106)和blb(例如,107)的输出电流。作为示例,取决于r_p和r_n的电阻值,每个输出电流可以在0.5(a.u.)的最小值至1.5(a.u.)的最大值的范围内。在实施方式中,ibl线1212可以是第一电流信号1224和偏移电流信号1220的总和,而ibl线1214可以是偏移电流1220和第二电流信号1226的总和。如所描绘的,偏移电流1220可以包括晶体管偏移和共模噪声。
如图12b所描绘的,通过对两个输出信号线1212和1214应用差分信令技术,可以消除偏移电流1220,并且可以获得输出电流信号1224和1226的值。作为示例,输出电流信号1224和1226可以在0.0(a.u.)至1.0(a.u.)的范围内。
此外,在实施方式中,第一电流信号1224可以具有与第二电流信号1226相反的极性。如图12c所描绘的,通过在两个输出电流上使用差分信令,两个信号ibl-ibl-反向1216之间的差可以在-1.0的最小值至+1.0的最大值的范围内,即,组合信号的范围可以是单个输出的范围的两倍大。
图13示出了包括根据本公开的实施方式的神经网络的芯片1300的示意图。如所描绘的,芯片1300可以具有片上系统(soc)结构,并且包括:非易失性神经网络1316;cpu1312,其用于控制芯片1300上的元件;传感器1314,其用于向非易失性神经网络1316提供输入信号;以及存储器1318。在实施方式中,神经网络1316可以类似于图1中的神经网络100。在实施方式中,芯片1300可以是硅芯片,并且组件1312至1318可以集成在芯片1300上。
图14示出了用于对根据本公开的实施方式的非易失性突触阵列进行运算的系统1400的示意图。如所描绘的,系统1400可以包括:非易失性突触阵列1410;参考生成器1402;配置存储1404;行驱动器1406,其用于在非易失性突触阵列1410中选择一行突触;路由器/控制器1408;列选择器1412,其用于在非易失性突触阵列1410中选择一列突触;感测电路1414;累加器1416,其用于从非易失性突触阵列1410收集输出值;归一化/激活/池化功能块1418;以及数据缓冲器1420,其用于对来自非易失性突触阵列1410的数据进行缓冲。在实施方式中,非易失性突触阵列1410可以类似于非易失性突触阵列200,并且感测电路1414可以类似于图2中的感测电路250。
参考生成器1402提供由行驱动器1406所使用的输入信号线(例如,图2至图8中的wl)和参考信号(例如,图2至图8中的sl)所需的电压电平。配置存储1404存储用于由路由器/控制器1408所使用的有限状态机的数据、权重参数与突触阵列200内的突触位置的物理映射、以及用于感测电路的其他配置参数。在该实施方式中,配置存储可以被实现为片上非易失性存储器。路由器/控制器1408实现有限状态机以通过行驱动器1406控制行选择序列。感测电路1414包括电压调节器和模数转换器,以将来自所选择的列的输出电流信号转换成电压信号并进一步转换成数字值。来自感测电路的结果在累加器1416中进行求和。归一化/激活/池化功能块1418对累加器值执行所需的信号处理运算。可以包括多个专用dsp或嵌入式cpu内核,以并行执行这样的数字运算。
在一些实施方式中,神经网络设计可以将权重和输入参数的值二值化为1或-1。在这样的实施方式中,突触600可以修改成使得可以使用交叉耦合式锁存电路来代替一对非易失性电阻改变元件。图15示出了根据本公开的实施方式的另一种突触1500的示意图。如所描绘的,突触1500可以包括交叉耦合式锁存电路1510,其中,交叉耦合式锁存电路1510可以包括反相器1514,该反相器1514的输入端子电耦合至第二反相器1518的输出端子,并且该反相器1514的输出端子电耦合至第二反相器1518的输入端子。在实施方式中,交叉耦合式锁存器可以将数字信号存储在位于1518的输出与1514的输入之间的s节点上和位于1514的输出与1518的输入之间的sb节点上。在实施方式中,当s节点具有电信号值时,sb节点可以具有互补信号值,并且由于反相器耦合,当sb节点具有电信号值时,s节点可以具有互补信号值。
如图15所描绘的,突触1500的单元1532和1534中的每一者可以包括在其栅极端子处电耦合至两个输入信号(或字)线,字线(wl)和反向字线(wlb)的两个输入选择晶体管(例如,1502和1506)。输入选择晶体管的源极端子可以电耦合至公共节点,该公共节点进一步电耦合至交叉耦合式锁存电路1510的节点。单元1532可以电耦合至交叉耦合式锁存器1510的sb节点,并且单元1534电耦合至1510的s节点。
在实施方式中,晶体管1502的漏极端子可以电耦合至输出线bl,并且晶体管1506的漏极端子可以电耦合至输出线blb。同样,晶体管1504和1508的漏极端子可以分别电耦合至blb和bl。
在实施方式中,参考信号线sl可以电耦合至交叉耦合式锁存器1510的反相器1514和1518中的每一者,并且参考电压输入信号201可以被提供给反相器1514和1518。
应当指出的是,交叉耦合式锁存器1510可以由诸如非易失性组件之类的各种电路(或存储器)来实现,或者在电源(诸如电池)可用的情况下其可以利用易失性存储组件来实现。
图16示出了显示wl和wlb上的输入电压值、由s节点和sb节点上的由电压信号表示的权重值、以及bl和blb线上的由电流值表示的输出之间的关系的表格。对于表格中的输入,(wl=高,wlb=低)可以为1,并且(wl=低,wlb=高)可以为-1。对于表格中的权重,(sb=高,s=低)可以为1,并且(sb=低,s=高)可以为-1。表格中的输入和权重的“低”电压值是比“高”电压值低的电压值。对于表格中的输出,(bl=低,blb=高)可以为1,并且(bl=高,blb=低)可以为-1。对于表格中的输出,“低”电流值是比“高”电流值低的电流值。
在该表格中,bl和blb上的输出可以表示输入(wl,wlb)和权重(sb,s)的乘积,其中,1×1=1,1×-1=-1,-1×1=-1,并且-1×-1=1。因此,二值化输入与权重之间的乘法运算可以得出算术上正确的结果。
图17、图18和图19分别示出了根据本公开的实施方式的突触1700、1800和1900的示意图。如图17所描绘的,突触1700可以仅包括单元1732,单元1732可以对应于图16中的突触600中的单元632。类似地,图18描绘了可以仅包括单元1832的突触1800,单元1832可以对应于图7所描绘的突触700中的单元732。图19中的突触1900可以仅包括单元1932,单元1932可以对应于图8的突触800中的单元832。在突触1700、1800和1900中,负权重w_负可以等于零,即,负权重可以已经分别从突触600、700和800中除去。由于wlb信号可以向blb线提供负输入信号,因此可以保留blb线。
在实施方式中,突触1700和1800的输出信号电流blbo可以是:
blbo=a_负×w_正(10)
同样,突触1900的输出电流信号blbo可以是:
blbo=∑(a_负j×w_正_i)(11)
图20示出了根据本公开的实施方式的突触2000的示意图。如所描绘的,突触2000可以类似于突触300,不同之处在于只有可以与图3中的单元332相对应的单元2032中的正权重可以被包括在突触2000中并且图3中的单元334和blb线267可以除去。
图21示出了根据本公开的实施方式的突触2100的示意图。如所描绘的,突触2100可以类似于突触400,不同之处在于只有可以与图4的单元432相对应的一个单元2132可以使用,并且图4的单元434和blb输出线可以除去。
图22示出了根据本公开的实施方式的突触2200的示意图。如所描绘的,突触2200可以类似于图5中的突触500,不同之处在于只有与图5的单元532相对应的单元2232可以使用,并且图5中的单元534和blb输出线可以除去。
应当指出的是,图17至图22中的突触可以如图2中所示的那样以二维阵列格式布置,即,图17至图22中的突触可以对应于突触210。
根据本发明,该实施方式中的逻辑友好型nvm指的是非易失性存储组件(具有零待机功率),该非易失性存储组件可以通过比诸如分离栅极闪存或eeprom之类的常规nvm组件少的处理步骤来生产。由于该实施方式中的nvm与cpu或神经网络计算引擎中的逻辑组件相比可能仅需要几个附加的处理步骤,因此将实施方式中的nvm与cpu或神经网络引擎嵌入在相同的芯片上是可行的。相反,将常规nvm组件与cpu或神经网络引擎嵌入在相同的芯片上是不可行的,因为生产这样的芯片将需要过多的附加处理。
在该实施方式中使用的逻辑友好型nvm的示例包括可能只需要比逻辑组件更少的处理步骤的stt-mram、rram、pram或fefet组件。该实施方式中的逻辑友好型nvm的另一示例是单层多晶嵌入式闪存。单层多晶闪存与逻辑组件相比不需要任何进一步的处理,并且特别适合与cpu、神经网络引擎嵌入在相同的芯片上。与常规nvm一样,逻辑友好型nvm可以在断电时维持存储的数据。
在图23所示的常规神经网络系统中,外部nvm芯片2319单独附接至集成了通过系统总线2330连接的各种电路块(诸如cpu1312、传感器1314和神经网络计算引擎2320)的片上系统(soc)2310。cpu1312和传感器1314对应于与图13中具有类似附图标记的组件。当系统电源关闭时,神经网络权重参数被存储在外部nvm芯片2319中。由于系统总线2330的性能受soc2310的引脚数限制,因此访问外部nvm芯片2319较慢。由于外部导线电容,访问外部nvm还消耗大量功率。另外,当在soc2310与外部nvm2319之间传输与隐私相关的神经网络参数时,安全性是一个问题。
图24图示了根据本发明的用于神经网络的分层系统,该神经网络由图13中描述的soc1300和外部神经网络加速器设备2470组成。在该实施方式中,片上非易失性神经网络模块1316通过高性能系统总线2430与soc1300内的cpu1312、传感器1314和存储器1318块集成在一起。
在该实施方式中,高性能系统总线2430的宽度不受soc1300的引脚数的限制。因此,通过高性能系统总线2430的通信比通过图23的现有技术设计中的系统总线2330的通信快得多。外部神经网络加速器设备2470可以通过片外互连2480连接,该片外互连可以是本地布线的或远程访问的。本地布线方法可以包括tsv、3d叠置、引线键合或通过pcb布线。远程访问方法可以包括lan、wi-fi、蓝牙。外部神经网络加速器设备可以包含其自身的cpu和高密度存储器(dram、闪存、scm等)并且可以位于云服务器处。
在该实施方式中,通过将整个神经网络分为soc1300和外部神经网络加速器设备2470,可以使用非易失性神经网络模块1316在soc1300内执行某些关键层,而其他其余层可以使用片外加速器2470来执行。外部神经网络加速器设备2470可以使用低成本和高密度的存储器,诸如如3d-nand。例如,神经网络的早期层可以用片上处理,而其余层可以用外部神经网络加速器设备2470处理。因为仅从片上非易失性神经网络提取或编码的特征在片外进行通信,因此与soc内没有神经网络模块的情况相比,外部通信的数据量可以减少。来自片上神经网络的中间结果可以提供低等待时间的部分结果,这对于早期预测最终结果可能是有用的,因为用于执行的必要参数存储在片上非易失性神经网络1316中。通过仅在soc1300与外部神经网络加速器设备2470之间与编码信息进行片外通信来显著减少隐私问题。
图25图示了根据本发明的由soc1300a和1300b的多个管芯组成的分布式神经网络系统。在该实施方式中,soc1300a和1300b类似于图13和图24中描述的soc1300。片外互连2480与图24的片外互连2480类似。通过将整个神经网络分为多个soc设备,可以并行执行神经网络的计算,从而提高性能。例如,某些早期层可以使用一个soc的片上神经网络模块进行处理,而其余层可以使用另一soc进行处理。仅从第一soc提取或编码的特征在片外进行通信。来自第一soc的中间结果可以提供低等待时间的部分结果,这对于早期预测最终结果可能是有用的,因为用于执行的必要参数存储在片上非易失性神经网络1316中的每个片上非易失性神经网络中。通过仅在soc1300a和1300b之间与编码信息进行片外通信来显著减少隐私问题。
图26示出了片上系统,其中,逻辑友好型nvm2619与其他电路块(诸如cpu1312、传感器1314和神经网络计算引擎2320)集成在soc2600中,并通过根据本发明的高性能系统总线2430连接。具有类似附图标记的组件表示图23的相对应的组件。在该实施方式中,通过将soc中的逻辑友好型nvm2619与中等密度神经网络计算引擎集成在soc中,与图23中的现有技术设计相比,能量耗散、等待时间耗费可以得到改善。此外,由外部nvm访问引起的安全问题减少。该实施方式的单逻辑芯片解决方案具有成本效益,并且对于具有安全地存储神经网络参数的逻辑兼容的嵌入式闪存的iot应用有吸引力。
在该实施方式中,总线宽度不受芯片的可用引脚数的限制。因此,宽的i/o和低等待时间的存储器接口可以用于在逻辑友好型nvm与soc2600中的其他块之间进行通信。因此,与使用外部闪存的现有技术系统相比,神经网络计算引擎2320可以快速访问来自逻辑友好型nvm2619的数据。
图27示出了本发明的神经网络系统,其中,逻辑友好型nvm2719集成在神经网络引擎2720内的soc2700中。神经网络计算引擎2720与图26中的神经网络计算引擎2620类似。与图23中的现有技术相比,神经网络计算引擎2720可以在无需cpu干预的情况下访问逻辑友好型nvm2719,以提高性能和功率效率。
图24至图27中描述的本发明提出的具有片上非易失性神经网络的架构具有各种优点,诸如与现有技术相比更低的功率消耗和更高的性能。而且,在该实施方式中,当个人用户数据用于执行神经网络时,通过限制片外访问来显著减少隐私问题。
该实施方式中的这种增强隐私的神经网络可以用于创新的个人设备。例如,在该实施方式中,可以通过使用片上非易失性神经网络的手持式教育设备或智能玩具交互式地创建个人的新任务、问题或答案。该实施方式对于在限制片外访问的同时通过图像或声音识别来鉴别个人可能是有用的。特别地,家庭或儿童保育设备可能不需要高度复杂的神经网络模型,因为声音必须被网络识别的人数是有限的。然而,这样的设备可能需要高度的个性化,并且关于隐私有严格的要求。而且,该实施方式中的片上非易失性神经网络可以提高军用设备或网络防火墙的安全性,因为用于这种类型的应用的关键神经网络层可以在没有关键信息的任何片外通信的情况下执行。
在本发明的另一方面,通过在片上存储和计算个性化信息,可以在安全的个性化视觉/运动/语音识别设备中使用所提出的片上非易失性神经网络系统。例如,设备可以识别特定人员的手势或语音,而无需在片外传输任何亲自训练的神经网络参数,因为所有神经网络计算都是在片上进行的。这样的视觉/运动/语音识别神经网络设备可以代替笨重的用户接口设备(例如,pc的键盘或鼠标、电视的遥控器)。例如,键盘触摸显示器可以用神经网络引擎代替,该神经网络引擎可以识别设备所有者的每个文本字符的手势。通过将个性化信息存储在片上非易失性神经网络中,仅特定的人员能够与设备进行交互。
此外,所提出的片上非易失性神经网络可以用于增强其他soc构建块(诸如cpu、存储器和传感器)的性能和可靠性。例如,由于晶体管的老化效应和变化的工作条件诸如温度,需要在soc的整个生命周期中适应地控制工作电压和频率。手动调节这些参数是神经网络可以优化的一项艰巨任务。然而,片外神经网络加速器可能无法满足性能要求,并且需要过多的附加功率。对于给定的性能和功率要求,可以使用非易失性神经网络来优化其自身芯片的其他组件的这些参数。
尽管本发明易于做出各种改型和替代形式,但是已经在附图中示出并且在本文中详细描述了本发明的具体示例。然而,应当理解的是,本发明不限于所公开的特定形式,相反,本发明将覆盖落入所附权利要求的范围内的所有改型、等同方案和替代方案。
- 还没有人留言评论。精彩留言会获得点赞!