数据处理系统、中央运算处理装置和数据处理方法与流程
1.本发明涉及数据处理系统、中央运算处理装置和数据处理方法。
2.本申请针对在2018年10月19日向日本申请的日本特愿2018
‑
197945号要求优先权,将其内容援引于此。
背景技术:
3.近年,在网络的领域中,虚拟化受到注目。通过虚拟化,能够在逻辑上利用构成网络的装置而不管实际的物理硬件结构如何。讨论了为虚拟化而通过通用硬件来构成以往在光接入系统中通过专用的硬件所制作的olt(optical line terminal,光线路终端)等装置并用软件来安装功能的结构。通过用软件实现功能,装置的功能变得可替换,另外,谋求装置的共同化或资源共享化。因此,能够期待capex(capital expenditure,资本支出)的削减。此外,考虑通过软件来使功能的更新或设定变更变得容易由此导致capex削减。
4.在此,作为用于使接入系统的软件区域扩大到包括纠错功能的物理层处理的讨论,示出了利用接入系统具有的gpu(graphics processing unit,图形处理单元)的安装技术。物理层处理的运算量很大,因此,以往,安装于专用芯片的asic(application specific integrated circuit,专用集成电路)。一般,通用硬件难以高速处理。因此,在物理层处理中仅利用cpu(central processing unit,中央处理单元)的情况下,吞吐量的性能达成是困难的。此外,作为通用处理器的动向,cpu的性能也达到了顶点。于是,通过与具有多核、可实现以高水平的并行化的gpu、fpga(field
‑
programmable gate array,现场可编程门阵列)等加速器进行组合,从而进行了性能提高。像这样,通过使用gpu等加速器来谋求性能达成的实现。
5.10g
‑
epon(10gigabit ethernet(注册商标) passive optical network,无源光网络)(例如,参照非专利文献2)系统中的站侧装置即olt(optical line terminal)通过图4所示的功能来实现编码处理。也就是说,物理层由pma(physical medium attachment;物理介质连接部)、pmd(physical medium dependent;物理介质依赖部)、pcs(physical coding sublayer;物理编码子层)、rs(reconciliation sublayer;调和子层)构成。进行编码的功能相当于pcs。pcs内的功能包括加扰处理、报头添加、0添加/去除、fec(forward error correction:前向纠错)编码等。
6.在此,讨论了使pcs的功能软件化。关于pcs中的编码,可并行处理的功能与不可并行处理的功能混在一起。gpu能够针对可并行处理的功能实现大幅高速化。可是,针对不可并行处理的功能,对于串行处理有效的cpu处理比利用gpu的处理更加能够高速化。因此,需要可实现cpu和gpu的协调处理的架构。进而,在通信处理中利用cpu和gpu时,需要连续地将信号转送到cpu或gpu的技术。
7.从上述两点出发,需要能够通过cpu和gpu协调地处理的且能够连续地流送信号的架构、以及这样的架构的控制方法。另外,需要将信号连续地转送到外部且经由cpu、gpu的方法。
8.在图像处理等的高速化中提出了利用cpu和gpu的协调处理系统。在这样的协调处理系统中,采取重复从cpu向gpu的存储器的转送和对转送到gpu的数据的处理的结构。
9.图5示出了在olt内将通过cpu进行了计算的信号直接转送到外部的方法(例如,参照非专利文献1)。该图所示的olt例如使用通用服务器来实现。在该图所示的方法中,在cpu中确保了多个发送用缓冲器。每当转送时,cpu依次变更对发送到if板的主信号进行存储的缓冲器的地址来进行主信号的转送。仅cpu进行对主信号的运算。
10.图6示出在olt内将外部信号连续地直接转送到gpu的方法(例如,参照非专利文献2)。该图所示的olt例如使用通用服务器来实现。在该图所示的方法中,在gpu中确保了多个接收用缓冲器。每当转送时,olt依次变更对gpu接收的信号进行存储的缓冲器的地址来进行转送。仅由gpu进行对主信号的运算。
11.现有技术文献非专利文献非专利文献1:takahiro suzuki, sang
‑
yuep kim, jun
‑
ichi kani, ken
‑
ichi suzuki, akihiro otaka, "real
‑
time demonstration of phy processing on cpu for programmable optical access systems", 2016 ieee global communications conference (globecom 2016), 2016年;非专利文献2:takahiro suzuki, sang
‑
yuep kim, jun
‑
ichi kani, toshihiro hanawa, ken
‑
ichi suzuki, akihiro otaka, "demonstration of 10
‑
gbps real
‑
time reed
‑
solomon decoding using gpu direct transfer and kernel scheduling for flexible access systems", journal of lightwave technology, 2018年5月, vol.36, no.10, p.1875
‑
1881。
技术实现要素:
12.发明要解决的课题然而,在上述的图5所示的技术中,仅cpu进行对主信号的运算,在图6所示的技术中,仅gpu进行对主信号的运算。像这样,这些并不是加速器与中央运算处理装置(cpu)协作地进行对主信号的运算的技术。
13.鉴于上述情况,本发明的目的在于,提供能够使加速器与中央运算处理装置协调地进行数据处理的数据处理系统、中央运算处理装置和数据处理方法。
14.用于解决课题的方案本发明的一个方式是一种数据处理系统,其中,具备:接口电路,与外部装置通信;加速器,进行第一数据处理;以及中央运算处理装置,控制所述加速器和所述接口电路,所述中央运算处理装置具备:数据处理执行部,进行第二数据处理;外部转送控制部,进行控制为使得从所述接口电路向所述加速器或该中央运算处理装置转送从所述外部装置接收的数据的处理、以及控制为使得从所述加速器或该中央运算处理装置向所述接口电路转送向所述外部装置发送的数据的处理中的至少任一个;数据处理控制部,控制为使得针对从所述外部装置接收的所述数据或向所述外部装置发送的所述数据来执行利用所述加速器的所述第一数据处理和利用所述数据处理执行部的所述第二数据处理;以及处理结果复制部,进行向所述中央运算处理装置输出所述第一数据处理的处理结果即第一处理结果来将
所述第一处理结果作为所述第二数据处理的处理对象的控制、以及向所述加速器输出所述第二数据处理的处理结果即第二处理结果来将所述第二处理结果作为所述第一数据处理的处理对象的控制中的至少一个。
15.本发明的一个方式是一种中央运算处理装置,其中,具备:存储部,存储从外部装置接收的数据或向所述外部装置发送的数据;数据处理执行部,使用所述存储部中存储的所述数据来进行数据处理,将处理结果存储在所述存储部中;外部转送控制部,进行控制为使得从接口电路向加速器或所述存储部转送从所述外部装置接收的数据的处理、以及控制为使得从所述加速器或所述存储部向所述接口电路转送向所述外部装置发送的数据的处理中的至少任一个;数据处理控制部,控制为使得针对从所述外部装置接收的所述数据或向所述外部装置发送的所述数据来执行利用所述加速器的数据处理和利用所述数据处理执行部的所述数据处理;以及处理结果复制部,进行向所述存储部转送利用所述加速器的所述数据处理的处理结果即第一处理结果来将所述第一处理结果作为所述数据处理执行部中的所述数据处理的处理对象的控制、以及从所述存储部向所述加速器转送利用所述数据处理执行部的所述数据处理的处理结果即第二处理结果来将所述第二处理结果作为利用所述加速器的所述数据处理的处理对象的控制中的至少一个。
16.本发明的一个方式是数据处理系统执行的数据处理方法,其中,具有:第一数据处理步骤,加速器进行第一数据处理;第二数据处理步骤,中央运算处理装置进行第二数据处理;外部转送步骤,中央运算处理装置进行控制为使得从接口电路向所述加速器或该中央运算处理装置转送从外部装置接收的数据的处理、以及控制为使得从所述加速器或该中央运算处理装置向所述接口电路转送向所述外部装置发送的数据的处理中的至少任一个;数据处理控制步骤,中央运算处理装置控制为使得针对从所述外部装置接收的所述数据或向所述外部装置发送的所述数据来执行利用所述第一数据处理步骤的所述第一数据处理和利用所述第二数据处理步骤的所述第二数据处理;以及处理结果复制步骤,中央运算处理装置进行向所述中央运算处理装置输出所述第一数据处理的处理结果即第一处理结果来将所述第一处理结果作为所述第二数据处理的处理对象的控制、以及向所述加速器输出所述第二数据处理的处理结果即第二处理结果来将所述第二处理结果作为所述第一数据处理的处理对象的控制中的至少一个。
17.发明效果利用本发明,能够使加速器与中央运算处理装置协调地进行数据处理。
附图说明
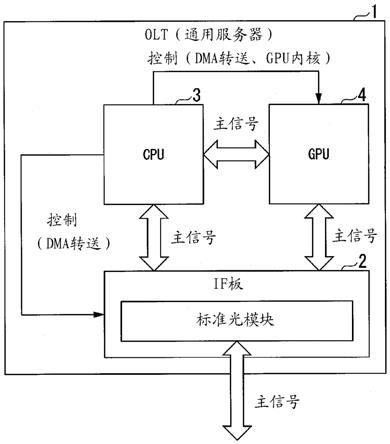
18.图1是示出根据本发明的第一实施方式的olt的结构的图。
19.图2是示出根据该实施方式的olt的处理的流程图。
20.图3是示出根据第二实施方式的olt的下行信号的处理相关的结构的图。
21.图4是示出现有技术的olt中的编码处理相关的功能的图。
22.图5是示出现有技术的olt中的信号转送的图。
23.图6是示出现有技术的olt中的信号转送的图。
具体实施方式
24.以下,一边参照附图一边详细地说明本发明的实施方式。
25.在本实施方式的数据处理系统中,if(接口)板以周期性的定时启动cpu(central processing unit;中央运算处理装置)的中断处理程序(interrupt handler)。中断处理程序指定从cpu或if板向gpu转送数据时的gpu上的转送目的地存储器、和从gpu向if板或cpu转送数据时的gpu上的转送源存储器,进而,进行cpu的函数启动、gpu的内核(kernel)启动、cpu与gpu间的存储器复制、gpu与if板或if板间的dma(direct memory access,直接存储器访问)转送的命令。
26.根据本实施方式的数据处理系统,能够在cpu
‑
gpu间进行协调的处理并且还能够进行向外部的连续信号转送。因此,通过将本实施方式的数据处理系统应用于通信装置,从而能够实现包括可并行处理的功能和不可并行处理的功能这两方的通信处理的高速化,进而能够实现功能整体的软件化。以下,以数据处理系统是接入系统的终端站装置的情况为例,说明详细的实施方式。
27.[第一实施方式]图1是示出根据本实施方式的olt1的结构的图。olt1是数据处理系统的一例。olt1例如使用通用服务器来实现。通过该图所示的结构,olt1进行cpu
‑
gpu协调运算。olt1具备if板2、cpu3、以及gpu4。
28.if板2例如是通过fpga(field
‑
programmable gate array)、专用板等实现的接口电路。if板2进行外部装置与处理器之间的信号的输入输出。例如,外部装置是onu(optical network unit,光网络单元)和上位装置,处理器是cpu3和gpu4。if板2周期性地启动cpu3的中断处理程序。if板2依照来自cpu3的中断处理程序的控制来进行dma转送。即,if板2将从外部装置接收的信号中包括的主信号转送到cpu3和gpu4。此外,if板2从cpu3保持的存储器或gpu4保持的存储器取得发给外部装置的主信号,将所取得的主信号输出到外部装置。if板2具有进行电信号与光信号的变换的标准光模块。标准光模块将经由光传送路从onu接收的光信号变换为电信号。此外,标准光模块将发给onu的电信号变换为光信号,将光信号输出到光传送路。
29.cpu3通过来自if板2的中断而启动中断处理程序。中断处理程序针对if板2执行用于进行cpu3和gpu4与if板2之间的dma转送的控制。此外,中断处理程序针对gpu4执行用于进行cpu3与gpu4之间的dma转送的控制、以及gpu4的内核的启动的控制。由此,主信号不仅在if板2和处理器之间,还在cpu3
‑
gpu4之间进行收发。此外,cpu3针对if板2接收到的或从if板2发送的主信号进行pcs(physical coding sublayer)中包括的数据处理之中的串行处理。
30.gpu4是加速器的一例。gpu4依照来自cpu3的控制而执行内核。gpu4通过内核针对从if板2或cpu3转送的主信号进行pcs(physical coding sublayer)中包括的数据处理之中的可并行处理的数据处理。
31.图2是示出olt1中的处理的流程图。使用该图来说明olt1的if板2、cpu3和gpu4的功能。首先,if板2在完成了从外部的信号输入或向外部的信号输出的准备时,向cpu3发送中断信号(步骤s11)。
32.cpu3当从if板2接收到中断信号时,启动中断处理程序。中断处理程序首先通过进
行存储器控制来决定对cpu3的函数作为运算对象的数据进行存储的cpu3的存储器区域、对gpu4的内核作为运算对象的数据进行存储的gpu4的存储器区域(步骤s12)。再有,存储输入数据的存储器区域和存储输出数据的存储器区域可以是不同的。接着,中断处理程序向if板2通知cpu3的存储器地址和gpu4的存储器地址中的一者或两者,进而向if板2指示外部转送(步骤s13)。if板2向所通知的地址的cpu3的存储器和gpu4的存储器中的一者或两者转送主信号的数据(步骤s14)。
33.在接下来的中断周期内,if板2向cpu3发送中断信号(步骤s15)。cpu3当从if板2接收到中断信号时,启动中断处理程序。中断处理程序针对在步骤s12中决定的存储器地址的存储器区域进行函数启动或内核启动(步骤s16)。再有,中断处理程序在步骤s14中向cpu3的存储器转送了数据的情况下进行函数启动,在向gpu4的存储器转送了数据的情况下进行内核启动。此外,在启动gpu4的内核的情况下,中断处理程序向gpu4通知在步骤s12中决定的gpu4的存储器地址、由gpu4并行执行的处理等。
34.在步骤s16中进行了函数启动的情况下,cpu3针对存储器地址所示出的cpu3的存储器区域中存储的主信号进行函数运算,将该函数运算的运算结果写入到cpu3的存储器区域中。另一方面,在步骤s16中进行了内核启动的情况下,gpu4启动内核,针对gpu4的存储器区域中存储的主信号并行地执行从cpu3的中断处理程序所指示的处理。gpu4将这些并行执行的处理的执行结果写入到gpu4的存储器区域中(步骤s17)。
35.接着,中断处理程序指示cpu3
‑
gpu4之间的存储器复制(步骤s18)。cpu3和gpu4依照中断处理程序的指示来进行dma转送(步骤s19)。即,当检测到结束了在步骤s16中启动的函数运算时,中断处理程序将步骤s17中的函数运算的执行结果被存储的cpu3的存储器区域的内容复制到在步骤s12中决定的gpu4的存储器区域。或者,当检测到结束了在步骤s16中启动的gpu4的并行处理时,中断处理程序将步骤s17中的gpu4的并行处理的执行结果被存储的gpu4的存储器区域的内容复制到在步骤s12中决定的存储器地址所示出的cpu3的存储器区域。再有,中断处理程序既可以通过从gpu4接受通知来检测gpu4中的并行处理的结束,也可以通过检测在并行处理的结束时写入到gpu4的存储器的结束标志来检测gpu4中的并行处理的结束。
36.之后,cpu3和gpu4根据需要,重复步骤s16~步骤s19的处理(步骤s20~步骤s23)。即,中断处理程序任意地重复函数启动和内核启动,重复cpu3和gpu4各自中的运算,在cpu3和gpu4之间复制运算结果的数据。
37.最后,当olt1进行与步骤s16和步骤s17同样的处理时(步骤s24和步骤s25),中断处理程序通过将dma启动的命令送到if板2来开始if板2的dma(步骤s26)。此时,中断处理程序将步骤s25中的函数运算的执行结果被存储的cpu3的存储器地址、或步骤s25中的并行处理的执行结果被存储的gpu4的存储器地址作为数据转送源,通知给if板2。if板2从数据转送源复制数据(步骤s27)。if板2将从cpu3或gpu4转送的数据发送到onu或上位装置。该数据是主信号。连续地重复if板2中的中断(步骤s28)。
38.如上所述,根据本实施方式,能够通过将依照cpu3的存储器复制命令的cpu3
‑
gpu4之间的dma的执行加入到信号转送的流中,来在cpu3
‑
gpu4之间进行dma转送(主信号)。此外,cpu3在指示外部转送时,能够选择是cpu3
‑
if板2之间的转送还是gpu4
‑
if板2之间的转送、以及是向if板2的转送还是来自if板2的转送。因此,cpu3和gpu4均能够进行与if板2之
间的双方向的dma转送(主信号的转送)。进而,通过重复存储器复制和函数/内核启动任意次数,能够以任意的顺序将任意的处理分配给cpu、gpu。
39.[第二实施方式]在本实施方式中,以从处理器向if板的方向(下行)的信号处理为例,说明olt1的详细的结构例。
[0040]
图3是示出olt1中的下行的信号处理相关的结构的图。10g
‑
epon、ng
‑
pon2、xgs
‑
pon等pon规范的olt采取与该图同样的结构。
[0041]
cpu3具有主存储器31、中断处理程序32、以及函数执行部33。主存储器31是存储从外部装置接收的主信号或向外部装置发送的主信号的存储部的一例。主存储器31具有输入输出用的存储器区域h_output。中断处理程序32具备存储器控制部321、函数启动部322、存储器复制部323、内核启动部324、以及外部转送控制部325。存储器控制部321进行对函数作为运算对象的cpu3的存储器地址、以及由gpu4的内核所启动的并行处理作为运算对象的gpu4的存储器地址进行决定的存储器控制。函数启动部322向函数执行部33指示函数的执行。存储器复制部323进行if板2或gpu4与主存储器31之间的数据的复制。内核启动部324向gpu4指示内核启动。外部转送控制部325指示if板2与cpu3或gpu4之间的dma转送。
[0042]
gpu4具备全局存储器41、以及内核执行部42。全局存储器41具有输入用的存储器区域d_input、以及输出用的存储器区域d_output。内核执行部42启动内核来执行并行处理。
[0043]
if板2具备dma执行部21、以及外部转送部22。dma执行部21接受来自cpu3的指示,从cpu3或gpu4复制主信号的数据。外部转送部22将dma执行部21复制的主信号变换为光信号,发送到onu。
[0044]
接着,说明olt1中的下行信号的处理。
[0045]
在本实施方式中,主信号的输入被保持在cpu3的主存储器31内的存储器区域h_output中。存储器区域h_output具有n个缓冲器。利用index的值来特别指定是这n个缓冲器中的哪个。每当主信号的输入时,cpu3一边使示出存储器区域h_output的缓冲器的地址的index发生变化一边在cpu3上执行作为串行功能的加扰。
[0046]
具体而言,当if板2启动cpu3的中断处理程序32时,存储器控制部321决定在主存储器31中使用的存储器区域h_output的地址、以及在全局存储器41中使用的存储器区域d_input和存储器区域d_output的地址。外部转送控制部325向if板2通知示出存储器区域h_output的地址的index,进而向if板2指示以使得转送主信号。if板2的外部转送部22向index所示出的存储器区域h_output的缓冲器转送主信号。
[0047]
在向主存储器31转送主信号的接下来的周期内,cpu启动中断处理程序32时,函数启动部322向函数执行部33通知存储器区域h_output的index,进而,向函数执行部33指示加扰的启动。加扰进行替换数据列的比特位置的处理。函数执行部33将从index所示出的存储器区域h_output的缓冲器中读出的主信号用作输入数据,执行具有加扰功能的函数,将函数的执行结果写入到该缓冲器中。
[0048]
全局存储器41的存储器区域d_input和存储器区域d_output也分别具有n个缓冲器。利用index的值来特别指定是这n个缓冲器中的哪个。再有,存储器区域h_output具有的缓冲器的数量、存储器区域d_input具有的缓冲器的数量、以及存储器区域d_output具有的
缓冲器的数量也可以是不同的。存储器控制311通过下述的式子来决定示出gpu4的输入用/输出用的存储器地址的索引index。gpu4一边依次地使全局存储器41中的存储器区域d_input和存储器区域d_output各自的index发生变化一边进行数据的转送。
[0049]
在此,n是gpu4具有的缓冲器的个数,mod示出求余运算。之后,存储器复制部323针对存储器控制部321决定的存储器地址,从cpu3向gpu4进行存储器复制。进而,内核启动部324针对gpu4指定转送的存储器的地址,进行内核启动。gpu4启动内核,并行地执行作为可并行处理的功能的报头添加、fec、填补、抑制,将计算结果储存在输出用的存储器区域d_input中。
[0050]
具体而言,在加扰处理的结束后,存储器复制部323向gpu4输出主存储器31的索引、以及全局存储器41的存储器区域d_input的索引,进而,向gpu4指示存储器复制。gpu4基于所通知的这些索引,从主存储器31的存储器区域h_output的缓冲器向全局存储器41的存储器区域d_input的缓冲器复制主信号。
[0051]
接着,中断处理程序32向gpu4通知全局存储器41的存储器区域d_input和存储器区域d_output各自的index,进而,向gpu4指示报头添加、fec编码、填补和抑制的并行执行。报头添加是向主信号添加报头的处理。填补是向发送中使用的字段的空区域附加规定模式的数据的处理。抑制是删除向数据前头附加的0等附加到规定位置的多余数据的处理。gpu4的内核执行部42使用所通知的索引所示出的存储器区域d_input的缓冲器中存储的数据,来并行地执行报头添加、fec编码、填补和抑制的处理。内核执行部42将各并行处理的处理结果写入到所通知的index所示出的存储器区域d_output的缓冲器中。
[0052]
cpu3的外部转送控制部325向if板2通知示出全局存储器41的存储器区域d_output的缓冲器的index,进而,向if板2发送外部转送的命令。if板2的dma执行部21开始dma,从所通知的index所示出的存储器区域d_output的缓冲器转送主信号。外部转送部22将从gpu4读出的主信号变换为光信号,将光信号输出到onu等外部装置。
[0053]
根据上述的实施方式,利用可通过cpu和gpu协调地处理的架构,连续地进行可实现信号转送的控制。因此,能够实现包括如pcs的编码处理那样的可并行处理的功能和不可并行处理的功能这两方的通信处理的高速化,能够扩大接入系统的软件区域。
[0054]
根据以上说明的实施方式,数据处理系统具备与外部装置通信的接口电路、进行第一数据处理的加速器、以及控制加速器和接口电路的中央运算处理装置。例如,数据处理系统是olt1,加速器是gpu4,中央运算处理装置是cpu3。中央运算处理装置具备数据处理执行部、外部转送控制部、数据处理控制部、以及处理结果复制部。例如,数据处理执行部是函数执行部33,外部转送部是外部转送控制部325,数据处理控制部是函数启动部322和内核启动部324,处理结果复制部是存储器复制部323。数据处理执行部进行第二数据处理。外部转送部进行控制为使得从接口电路向加速器或中央运算处理装置转送从外部装置接收的数据的处理、以及控制为使得从加速器或中央运算处理装置向接口电路转送向外部装置发送的数据的处理中的至少任一个。数据处理控制部控制为使得针对从外部装置接收的数据或向外部装置发送的数据来执行利用加速器的第一数据处理、以及利用数据处理执行部的第二数据处理。处理结果复制部进行向中央运算处理装置的存储部输出第一数据处理的处理结果即第一处理结果来将输出的第一处理结果作为第二数据处理的处理对象的控制、以
及从存储部向加速器输出第二数据处理的处理结果即第二处理结果来将输出的第二处理结果作为第一数据处理的处理对象的控制中的至少一个。
[0055]
例如,加速器进行的第一数据处理是并行处理,中央运算处理装置进行的第二数据处理是串行处理。在数据处理系统是pon系统中的终端站装置的情况下,第一数据处理是报头添加、前向纠错编码、填补和抑制的并行处理,第二数据处理是包括加扰处理的处理。
[0056]
以上,参照附图详述了本发明的实施方式,但是,具体的结构并不限于本实施方式,还包括不脱离本发明的主旨的范围的设计等。
[0057]
产业上的利用可能性能够利用于具有中央运算处理装置和加速器的装置。
[0058]
附图标记的说明1
…
olt,2
…
if板,3
…
cpu,4
…
gpu,21
…
dma执行部,22
…
外部转送部,31
…
主存储器,32
…
中断处理程序,33
…
函数执行部,41
…
全局存储器,42
…
内核执行部,321
…
存储器控制部,322
…
函数启动部,323
…
存储器复制部,324
…
内核启动部,325
…
外部转送控制部。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1