一种基于深度学习的裁判文书自动生成方法及系统与流程
本发明涉及自然语言处理领域,具体地,涉及一种基于深度学习的裁判文书自动生成方法及系统。
背景技术:
裁判文书是人民法院结合当事人的请求事项或者争议事项进行审理后,根据具体的案件情况向当事人下发的具有法律意义的文书。目前,裁判文书生成主要有两种方式:一种由审判人员人工“套改”已有类似案件的裁判文书生成;另一种使用ocr识别技术抓取起诉状、答辩状等诉讼材料中有限的信息生成。
现有裁判文书生成方法生成的文书类型、案号、当事人信息、审判人员信息等相对简单,可以较好生成固定部分的案由事实,但是无法有效处理核心部分的案由事实的生成。每个案件的案由事实都存在或多或少的差异,使用ocr技术识别起诉状、答辩状等诉讼材料抓取的部分事实信息,不仅文字识别正确率不高,且无法提供真正符合人民法院使用的案由事实,仍然需要审判人员做大量修改。
技术实现要素:
为了更加高效、准确地实现裁判文书的自动生成,解决使用ocr技术识别直接抓取信息的弊端,本发明充分研究不同类型裁判文书案由的通常表述,结合同类型案由的基本情况,根据每种类型案由的要素分类情况标注裁判文书涉及的案由要素,构建深度学习模型,通过案由要素实现裁判文书自动生成,达到更符合实际要求的目的。
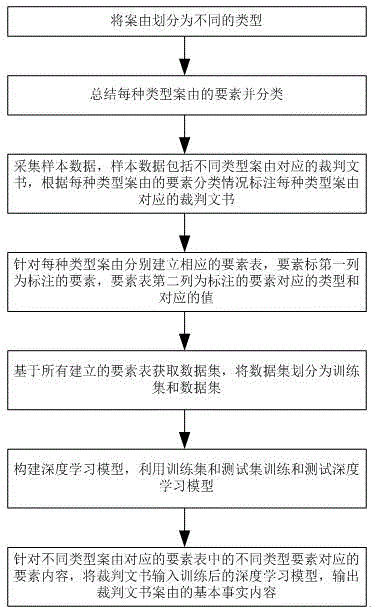
为实现上述发明目的,本发明一方面提供了一种基于深度学习的裁判文书自动生成方法,所述方法包括:
将案由划分为不同类型;
总结每种类型案由的要素并分类;
采集样本数据,样本数据包括不同类型案由对应的裁判文书,根据每种类型案由的要素分类情况标注每种类型案由对应的裁判文书;
针对每种类型案由分别建立相应的要素表,要素表第一列为标注的要素,要素表第二列为标注的要素对应的类型和值;
基于所有建立的要素表获取数据集,将数据集划分为训练集和测试集;
构建深度学习模型,利用训练集和测试集训练和测试深度学习模型;
针对不同类型案由对应的要素表中不同类型要素对应的要素内容,将裁判文书输入训练后的深度学习模型,输出裁判文书案由的基本事实内容。
其中,本发明的原理为:要素是归纳总结同一案由下案件后凝练的固定事项,是查明案件必不可少的因素。在案件庭审过程中,法官根据要素进行发问,原告、被告分别回答法官的发问,由此得到相关特定审判信息。本发明将要素填进一个表,本发明称之为要素表。本发明利用要素表的要素生成裁判文书案件基本事实内容。
优选的,在本方法中,案由类型包括:劳动争议案由、离婚案由、民间借贷案由。
优选的,在本方法中,将数据集按照比例8:2划分为训练集和测试集。
优选的,在本方法中,构建深度学习模型,利用训练集和测试集训练和测试深度学习模型,具体包括:
将sequence-to-sequence模型的编码器和解码器均定义为一系列长短期记忆网络;
将数据集的第一列数据作为编码器的输入,将对应的第二列文段作为解码器的输出,构建sequence-to-sequence模型;
sequence-to-sequence模型的编码器将输入的每个文字作为一个输入,输入内容以x=(x1,x2,…,xj)形式保存,其中j代表输入文字的总长度,编码器将输入的x转换成隐藏层的信息内容,同时解码器将隐藏层的信息内容作为输入,并输出y=(y1,y2,…,yt),其中t代表输出文字的总长度,通过反向传播学习模型参数,并利用测试集验证,得到训练后的模型。
优选的,在本方法中,劳动争议案由的要素类型分为五类:劳动者入职时间、劳动者离职时间、劳动合同约定工资、劳动者离职前12个月平均工资和劳动者离职原因;离婚案由的要素类型分为四类:确定恋爱的关系时间、登记结婚时间、婚姻登记机关和需要抚养的生育子女个数;民间借贷案由的要素类型分为六类:债权凭证签订日期、预扣利息具体金额、借款交付地点、借款交付日期、约定还款日期和借款金额。
优选的,本方法在步骤将案由划分为不同的类型之前还包括以下步骤:采用模板自动生成裁判文书的固定格式部分,使用规则自动生成裁判文书的判决结果部分。
优选的,本方法在步骤总结每种类型案由的要素并分类之后,以及采集样本数据步骤之前还包括以下步骤:
使用hmm算法计算出每种类型案由中所有要素之间的概率转移矩阵;
基于要素之间的概率转移矩阵,使用拓扑排序方法对新案件中的要素重排序。
优选的,使用拓扑排序方法对新案件中的要素进行重排序包括:首先通过前面的概率转移矩阵对抽取到的要素来构建子图,然后对从子图中选择一个要素作为头节点,然后开始拓扑排序,最后得到对要素顺序重新排序的列表。
优选的,使用hmm算法计算出每种类型案由中所有要素之间的概率转移矩阵,通过提取每种类型案由的历史裁判文件的要素,得到要素之间的先后顺序,每个裁判文书对应的要素顺序作为样本训练hmm模型,hmm实际上是分为两个部分的,一是马尔可夫链,由参数a描述,它利用一组与概率分布相联系的状态转移的统计对应关系,描述每个短时平稳段是如何转变到下一个短时平稳段的,这个过程产生的输出为状态序列;二是一个随机过程,描述状态与观察值之间的统计关系,用观察到的序列来描述隐含的状态,由b描述,其产生的输出为观察值序列。在hmm模型中的转移矩阵即为包含当前案由下所有要素的概率转移矩阵。实际情况中案由中的要素是从起诉状抽取出来和庭审过程中提取出来的,因此要素的前后顺序通常会存在着不太符合逻辑的情况,所以需要将提取出来的要素重新排序,使得下一步的文书生成的逻辑更加通顺。
另一方面,本发明还提供了一种基于深度学习的裁判文书自动生成系统,所述系统包括:
案由类型划分单元,用于将案由划分为不同类型;
案由要素分类单元,用于总结每种类型案由的要素并分类;
样本数据采集及标注单元,用于采集样本数据,样本数据包括不同类型案由对应的裁判文书,根据每种类型案由的要素分类情况标注每种类型案由对应的裁判文书;
要素表建立单元,用于针对每种类型案由分别建立相应的要素表,要素表第一列为标注的要素,要素表第二列为标注的要素对应的类型和值;
数据集获取单元,用于基于所有建立的要素表获取数据集,将数据集划分为训练集和测试集;
模型构建及训练单元,用于构建深度学习模型,利用训练集和测试集训练和测试深度学习模型;
基本事实内容生成单元,用于针对不同类型案由对应的要素表的不同类型要素对应的要素内容,将裁判文书输入训练后的深度学习模型,输出裁判文书案由的基本事实内容。
进一步的,在本系统中,案由类型包括但不限于:劳动争议案由、离婚案由、民间借贷案由。
进一步的,在本系统中,将数据集按照比例8:2划分为训练集和测试集。
进一步的,在本系统中,构建深度学习模型,利用训练集和测试集训练和测试深度学习模型,具体包括:
将sequence-to-sequence模型的编码器和解码器均定义为一系列长短期记忆网络;
将数据集的第一列数据作为编码器的输入,将对应的第二列文段作为解码器的输出,构建sequence-to-sequence模型;
sequence-to-sequence模型的编码器将输入的每个文字作为一个输入,输入内容以x=(x1,x2,…,xj)形式保存,其中j代表输入文字的总长度,编码器将输入的x转换成隐藏层的信息内容,同时解码器将隐藏层的信息内容作为输入,并输出y=(y1,y2,…,yt),其中t代表输出文字的总长度,通过反向传播学习模型参数,并利用测试集验证,得到训练后的模型。
进一步的,在本系统中,劳动争议案由的要素类型分为五类:劳动者入职时间、劳动者离职时间、劳动合同约定工资、劳动者离职前12个月平均工资和劳动者离职原因;离婚案由的要素类型分为四类:确定恋爱的关系时间、登记结婚时间、婚姻登记机关和需要抚养的生育子女个数;民间借贷案由的要素类型分为六类:债权凭证签订日期、预扣利息具体金额、借款交付地点、借款交付日期、约定还款日期和借款金额。
进一步的,本系统还包括固定格式生成单元,用于采用模板自动生成裁判文书的固定格式部分,还包括判决结果生成单元,用于使用规则自动生成裁判文书的判决结果部分。
优选的,本系统还包括:
转移概率矩阵计算单元,用于使用hmm算法计算出每种类型案由中所有要素之间的概率转移矩阵;
案由要素顺序重排序单元,用于基于要素之间的概率转移矩阵,使用拓扑排序方法对新案件中的要素进重排序,首先通过前面的概率转移矩阵对抽取到的要素来构建子图,然后对从子图中选择一个要素作为头节点,然后开始拓扑排序,最后得到对要素顺序重新排序的列表。
进一步的,本系统中使用hmm算法计算出每种类型案由中所有要素之间的概率转移矩阵,用于后续对案由重排序,通过提取每种类型案由的历史裁判文件的要素,得到要素之间的先后顺序,每个裁判文书对应的要素顺序作为一个样本训练hmm模型,hmm实际上是分为两个部分的,一是马尔可夫链,由参数a描述,它利用一组与概率分布相联系的状态转移的统计对应关系,描述每个短时平稳段是如何转变到下一个短时平稳段的,这个过程产生的输出为状态序列;二是一个随机过程,描述状态与观察值之间的统计关系,用观察到的序列描述隐含的状态,由b描述,其产生的输出为观察值序列。在hmm模型中的转移矩阵即为包含当前案由下所有要素的概率转移矩阵。实际情况中案由中的要素是从起诉状抽取出来和庭审过程中提取出来的,因此要素的前后顺序通常存在不太符合逻辑的情况,所以需要将提取出来的要素重新排序,使得下一步的文书生成的逻辑更加通顺。
本发明提供的一个或多个技术方案,至少具有如下技术效果或优点:
本发明采用序列模型,将lstm作为模型的编码器和解码器,通过案由要素实现裁判文书自动生成,可以有效提高裁判文书制作的效率与准确率,将法官从繁琐的文书制作中解放出来,从根本上缓解法院“案多人少”的矛盾。
进一步的,本发明还能够高速有效的生成一篇规范的裁判文书,本发明对相对固定的部分采用模板的形式处理,对裁判结果采用规则的方式进行文书生成,先提取相应的要素,然后采用hmm提供的转移矩阵使用拓扑排序对提取要素进行重新排序,然后将提取到的要素采用序列模型进行文本生成,实现案情事实部分的自动生成。
进一步的,本发明中的裁判文书生成的逻辑更通顺。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本发明的一部分,并不构成对本发明实施例的限定;
图1是本发明中一种基于深度学习的裁判文书自动生成方法的流程示意图;
图2是本发明中一种基于深度学习的裁判文书自动生成系统的组成示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
请参考图1,图1为本方法的流程示意图,本方法包括:
将案由划分为不同类型;
总结每种类型案由的要素并分类;
采集样本数据,样本数据包括不同类型的案由对应的裁判文书,根据每种类型案由的要素分类情况标注每种类型案由对应的裁判文书;
针对每种类型案由分别建立相应的要素表,要素表第一列为标注的要素,要素表第二列为标注的要素对应的类型和值;
基于所有建立的要素表获取数据集,将数据集划分为训练集和测试集;
构建深度学习模型,利用训练集和测试集训练和测试深度学习模型;
针对不同类型案由对应的要素表中不同类型要素对应的要素内容,将裁判文书输入训练后的深度学习模型,输出裁判文书案由的基本事实内容。
请参考图2,图2为本系统的组成示意图,本系统包括:
案由类型划分单元,用于将案由划分为不同类型;
案由要素分类单元,用于总结每种类型案由的要素并分类;
样本数据采集及标注单元,用于采集样本数据,样本数据包括不同类型的案由对应的裁判文书,根据每种类型案由的要素分类情况标注每种类型案由对应的裁判文书;
要素表建立单元,用于针对每种类型案由分别建立相应的要素表,要素表第一列为标注的要素,要素表第二列为标注的要素对应的类型和值;
数据集获取单元,用于基于所有建立的要素表获取数据集,将数据集划分为训练集和测试集;
模型构建及训练单元,用于构建深度学习模型,利用训练集和测试集训练和测试深度学习模型;
基本事实内容生成单元,用于针对不同类型案由对应的要素表中不同类型要素对应的要素内容,将裁判文书输入训练后的深度学习模型,输出裁判文书案由的基本事实内容。
本方法的具体实施步骤为:
具体步骤如下:
1.由于不同类型案由所涉及的法律关系存在差异,本发明以案由为维度分别进行要素总结,并根据案由特征将要素分类为不同类型。例如劳动争议案由的要素归纳为这五种类型:劳动者入职时间、劳动者离职时间、劳动合同约定工资、劳动者离职前12个月平均工资、劳动者离职原因;例如离婚案由的要素归纳为这四种类型:确定恋爱的关系时间、登记结婚时间、婚姻登记机关、需要抚养的生育子女个数;例如民间借贷案由的要素归纳为这六种类型:债权凭证签订日期、预扣利息具体金额、借款交付地点、借款交付日期、约定还款日期、借款金额;
2.针对劳动争议案由,本发明利用人工标注50000篇劳动争议裁判文书涉及的上述五类要素内容,例如劳动者入职时间,本发明标注对应时间,以劳动者入职时间【20xx年xx月xx日】保存;劳动者离职时间,本发明标注对应时间,以劳动者离职时间【20xx年xx月xx日】保存;劳动合同约定工资,本发明标注对应工资金额,以劳动合同约定工资【xx元】保存;劳动者离职前12个月平均工资,本发明标注对应工资金额,以劳动者离职前12个月平均工资【xx元】保存;劳动者离职原因,本发明标注对应文字内容,以劳动者离职原因【xxx】保存;
针对离婚案由,本发明同样选取50000份离婚案由裁判文书并人工标注其涉及的上述四类要素内容,例如确定恋爱的关系时间,本发明标注对应时间,以确定恋爱时间【20xx年xx月xx日】保存;登记结婚时间,本发明标注对应时间,以登记结婚时间【20xx年xx月xx日】保存;例如婚姻登记机关,本发明标注对应机关名称,以婚姻登记机关【xx】保存;例如需要抚养的生育子女个数,本发明标注子女个数,以需要抚养的生育子女个数【xx个】保存;
针对民间借贷案由,本发明同样选取50000份民间借贷案由裁判文书并人工标注其涉及的上述六类要素内容,例如债权凭证签订日期,本发明标注时间,以债权凭证签订日期【20xx年xx月xx日】保存;例如预扣利息具体金额,本发明标注具体金额,以预扣利息具体金额【xx元】保存;例如借款交付地点,本发明标注具体地点,以借款交付地点【xx】保存;例如借款交付日期,本发明标注具体时间,以借款交付日期【20xx年xx月xx日】保存;比如约定还款日期,本发明标注具体时间,以约定还款日期【20xx年xx月xx日】保存;比如借款金额,本发明标注具体金额,以借款金额【xx元】保存;
3.针对劳动争议案由,本发明将以上要素储存至excel表第一列,将上述五个要素类型及其值以一列排开,并裁判文书涉及要素的对应段落,即要生成的案件基本事实内容保存至第二列,最终形成50000行、2列的数据集;以此类推,针对离婚案由,本发明将获得50000行、2列的数据集;针对民间借贷案由,本发明将获得60000行、2列的数据集;
4.本发明分别将上述不同案由的数据集按照比例8:2划分为训练集和测试集;
5.本发明将sequence-to-sequence模型的编码器定义为一系列lstm,解码器也定义为一系列lstm;
6.本发明将训练集的第一列数据,即归纳的要素类型对应的要素值作为编码器的输入,将对应的第二列文段作为解码器的输出,构建sequence-to-sequence模型;
7.上述模型的编码器会将输入的每个要素对应的值,以每个文字作为一个输入,即将输入数据存储为x=(x1,x2,…,xj),其中j代表输入文字的总长度,编码器将x转换成隐藏层的信息内容,与此同时解码器将上述隐藏层的信息内容作为输入,并输出y=(y1,y2,…,yt),其中t代表输出文字的总长度,通过反向传播学习模型参数,并利用测试集验证,得到训练后的模型;
8.本发明将该模型运用在实际应用中,当获取到不同案由下要素表中不同类型的要素对应的要素内容时,即可利用该模型自动生成裁判文书的案件基本事实部分。
其中,在本发明实施例中,本方法在步骤将案由划分为不同的类型之前还包括以下步骤:采用模板自动生成裁判文书的固定格式部分,使用规则自动生成裁判文书的判决结果部分。
优选的,本方法在步骤总结每种类型案由的要素并分类之后,以及采集样本数据步骤之前还包括以下步骤:
使用hmm算法计算出每种类型案由中所有要素之间的转移概率矩阵;
案由要素顺序重排序,使用拓扑排序方法将新案件中的要素重排序。
优选的,使用hmm算法计算出每种类型案由中所有要素之间的转移概率矩阵,通过提取每种类型案由的历史裁判文件的要素,得到要素之间的先后顺序,每个裁判文书对应的要素顺序作为一个样本训练hmm模型,获得当前案由下所有要素的概率转移矩阵。实际情况中案由中的要素是从起诉状抽取出来和庭审过程中提取出来的,因此要素的前后顺序是通常会存在着不太符合逻辑的情况,所以需要对提取出来的要素重新排序,使得下一步的文书生成的逻辑更加通顺。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!