一种基于Python环境下的目标运动视频跟踪方法与流程
本发明涉及目标跟踪领域,尤其涉及一种在python环境下实现的运动目标跟踪方法。
背景技术:
随着互联网时代的到来,飞速发展的视频监控系统已广泛应用于各个领域,尤其是在交通安全、小区安保、银行监控、工业检测、医学成像分析等方面都有非常成熟的应用,可以说视频监控系统以及深入到我们生活的各个方面,并且已经是必不可少的一部分。虽然视频系统的应用已如此之广,技术也相对成熟,但是它依然有更大的前景,就目前来看,其在畜牧养殖领域的应用还不是那么普遍,技术也相对没有那么成熟,主要原因还是在于前期的环境安装和技术支持等花费相对于私人养殖户来说,成本较高,也并不能带来直接受益,故需要成本低廉且直观好用的系统用于养殖业。
智能监控不需要人为干预,能自动识别目标状况,在异常时还能提供警报,大大降低了人力,尤其是在人们精神不足需要休息的夜间,发挥着更大的作用。目前,无论是否是私人的养殖场,都不同程度的存在自动化水平低,大部分依旧是人工检测动物状态,对工人的工作时间和专业程度都要求较高的问题。因此,本发明以降低成本,效果直观,操作方便为目的,提出了一种基于python环境下的运动目标跟踪方法及系统,旨在为实现养殖场全面自动化智能监控打下基础。
技术实现要素:
本发明的目的是提供一种基于python环境下的运动目标跟踪方法,本发明成本低廉,可实现养殖场环境下对动物的实时跟踪,绘制其运动轨迹和位移图,实现对其的监控和健康管理。
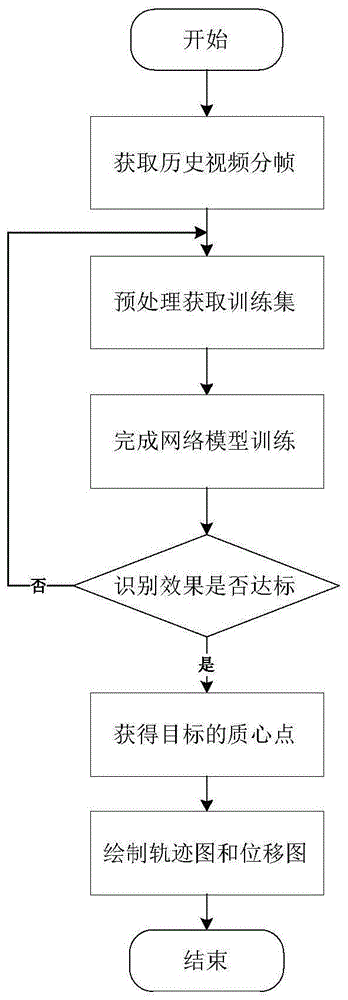
本发明提供的基于python环境下的运动目标跟踪方法,通过以下步骤实现:
步骤1:视频采集系统通过布置于运动目标正上方的海康ds-2cd7a27fwd/f-lz(s)网络摄像机,获取实时传输的高清视频至萤石云监控软件,并在网络硬盘中存储;接着获取各时间段内的部分历史视频进行分帧并保存所有图片;
步骤2:预处理步骤1中获取的图片,保证每张的大小和清晰度统一,并剔除目标不存在的所有图片,获取训练集和测试集;
步骤3:在python环境下,利用步骤2中的图片集,训练神经网络模型,训练完成后,在新的视频中自动获取所需目标测试效果,如不达标则返回步骤2,直至目标获取结果达到预期效果;
步骤4:在步骤3成功获取目标区域的基础上,利用相应公式计算出目标质心位置,进行实时的目标跟踪;
步骤5:根据步骤4中的质心点坐标以及其他相关参数,获得目标的运动轨迹和对应的时间参数;
步骤6:根据步骤5的结果,绘制运动轨迹图及位移图,以提供直观的数据,结束。
所述步骤1中视频采集系统通过物联网技术搭建,远程获取实时高清视频,并有大容量网络硬盘支持大量的历史数据存储。其中部分历史视频采用时间段随机获取方式,保存的图片包含所有筛选视频片段每一帧的图片。
所述步骤2中的图片预处理包括:图像大小统一裁剪,清晰度、亮度统一;获取训练集和测试集方式包括:人工手动删除目标不存在的图片以及人工设置所有集合的标注。
所述步骤3中的python环境下的神经网络模型训练,需要根据训练集的数据量和所需识别目标自身的特点,来设计适合的神经网络模型结构。
上述神经网络模型设计包括:
使用改进的vgg16网络模型,具体如下:
1)去掉原vgg16模型中的两个全连接层fc6和fc7,取而代之的是两个卷积层,conv6和conv7。
2)conv4_3作为检测的第一个特征图,在后面的卷积中总共获得大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)的6个特征图。
3)池化层pool5采用3*3-s1,conv6采用扩张率为6的扩展卷积。
4)去掉原来模型里防止过拟合的层以及一个全连接层,新增卷积层,并在此基础上稍微调整训练集。
其中额外增加的卷积层个数、卷积核的大小、池化区域大小、层数以及滑动间隔等参数,能够适应于本发明实验环境下。在应用场景发生改变的时候,都可以根据所需识别的目标在视频中的相对大小等因素设定,以从中确定使得检测效率和效果均较优的参数。
为了降低训练难度,本发明为每个单元设置了数量不同的预选框,最后检测结果的边界框将从这些预选框中选取置信度最高的作为预测边界框。预选框的位置用d=(dcx,dcy,dw,dh)来表示,其中(dcx,dcy)表示预选框的中心点坐标,(dw,dh)分别表示预选框的宽和高。边界框用b=(bcx,bcy,bw,bh)来表示,其中(bcx,bcy)表示边界框的中心点坐标,(bw,bh)分别表示边界框的宽和高。边界框的预测值的中心点坐标(lcx,lcy),宽lw和高lh遵循如下转换公式:
lw=log(bw/dw),lh=log(bh/dh)
每个单元的先验框的中心点分布在各个单元的中心,即:
其中i,j代表横轴坐标系参数,|fk|为特征图的大小,对于其大小,采用如下公式计算:
上述公式中,n为选择的特征图的个数,本发明实施例中n=5,可以看出这个大小遵循线性规则,即:特征图大小随着先验框的尺度增加而降低。
需要说明的是,第一个特征图的预选框尺寸比例需要设置,本发明设置为尺寸最小值为0.1,尺度为最小值的300倍,即30。后面的特征图尺度都按照最小和最大值同时扩大100倍来计算,可以算得每个特征图大小之间的差为17。带入上述公式可算出,当n=5,k取[1,5]时,特征图的大小分别为20,37,54,71,88。由于本文图片大小均为300*300,可最终得到预选框的尺度分别为:30,60,111,162,213和264。系统将从这6个预选框中最后确定边界框。
在python环境下训练神经网络模型的过程大致可分为数据准备、训练以及测试三个部分,具体如下:
(1)数据准备阶段:
1)在得到步骤2中的数据集后,在/home/服务器名/data/vocdevkit目录下建立自己的数据集文件夹,文件夹里包含annotations、imagesets、jpegimages三个子文件夹。其中annotations里存放xml格式数据文件,jpegimages中存放所有数据图片,imagesets目录下的main文件中用python生成4个数据集文件,分别为测试集test.txt,训练集train.txt,验证集val.txt以及交叉验证集trainval.txt。
具体过程为:在python里用import方法导入os模块和random模块,用于调用系统命令和随机数方法,接着分别定义交叉验证集占总图片的比例为0.66,训练集占交叉验证集的比例为0.5并用os.listdir()方法返回文件夹包含的文件及文件夹的名字列表,在main文件中利用random.sample()方法返回随机制定数量,最后用f.wirte()方法写入数据,这样就完成了对上述四种集合的生成。
2)在caffe-ssd/data录下创建文件夹与上述1)中vocdevkit目录下创建的文件夹名字相同的文件,把data/voc0712目录下create_list.sh、create_data.sh、labelmap_voc.prototxt三个文件拷贝至该文件夹下。再在caffe-ssd/examples目录下创建同名文件夹用于存放后续生成的lmdb文件;
3)在python里应用item方法修改labelmap_voc.prototxt的类别和te_list.sh、create_data.sh这两个文件中的相关路径。
4)运行命令./data/文件名/create_list.sh和./data/文件名/create_data.sh命令。后可在examples/文件名/下可以看到两个子文件夹,mydataset_trainval_lmdb和mydataset_test_lmdb这里面均包含data.dmb和lock.dmb。此时代表第一部分完成。
(2)训练阶段
训练程序为/examples/ssd/ssd_pascal.py,运行之前,还需要修改train_data、test_data、model_name、save_dir、snapshot_dir、output_result_dir、name_size_file、label_map_file的路径以及num_classes和num_test_image的数值。其中num_classes的值为类别数+1,num_test_image为测试集图片数量,考虑到训练设备的性能和gpu数量,可需修改gpus和batchsize的数值。
(3)测试部分
测试程序为/examples/ssd/ssd_detect.py,同样在运行前需要做一些修改,主要是修改parser.add_argument()函数中labelmap_file、model_def、model_weights和image_file的路径并将image_resize的预设值设为300,类型为整数。
所述步骤4中利用检测框得到目标质心点位置的具体方法如下:
(1)利用canny边缘检测算法,通过高斯滤波器平滑图像、计算梯度幅值和角度图像、非极大值抑制、双阈值处理和连接边缘几个步骤完成边缘检测。
(2)假设边缘图像为g(x,y),质心点位置为(xc,yc),则原点不变矩的计算公式为:
其中mpq定义为一个p*q阶矩阵,0阶矩m00是边缘图像的灰度值和,m和n分别为该边缘图像横纵坐标的最大值。
质心点的计算公式为:
所述步骤5中轨迹获得方法如下:
遍历视频片段中的每一帧,均按前述步骤获取目标和质心点,对于同一目标的质心点在相邻两帧之间的距离应该最短,根据邻近算法确定属于同一目标的质心点,按视频帧先后顺序相连,从而获取目标运动轨迹。
所述步骤6的轨迹图和位移图绘制方法如下:
由于本系统的摄像头位置固定,根据与地面的高度,按照实际大小为单位,以视频图像边缘左下角为原点,下边缘为横轴x轴,左边缘为纵轴y轴,建立直角坐标系。将质心作为跟踪点,计算每个时刻之间的位置差,则可利用如下公式得到目标每个时间段的位移量,把每个相邻质心点连接可得运动轨迹图,图中相邻质心点之间的距离由所述位移量体现。
其中di表示第i时刻的位移量,(xi,yi)表示i时刻的质心坐标,
本发明的有益效果:
1、本发明基于python环境,利用深度卷积模型训练所需识别目标,可进行针对性的模型训练,以提高跟踪系统对目标的识别精度和识别速度,确保养殖场环境下的检测和跟踪。
2、本发明由于前期训练完成后可以一直长期有效的使用,且相关硬件设备只有摄像头和与之相连的计算机,在达到减少相关养殖人员工作量的目的的同时,也可以达到节约成本的目的。
3、本发明提供的动物运动轨迹图像和时间位移图像,可以非常直观的显示其活跃度信息,便于养殖人员的浏览,达到养殖的管理要求。与此同时,本系统提供的活跃度信息可作为判断其健康与否的一个重要依据,以达到提早发现生病动物,降低养殖场损失的目的,为简化养殖管理工作提供一种有效的方式。
附图说明
图1是本发明的系统流程框图
图2是本发明的训练模型结构图
图3是本发明的边缘连接示意图
图4是本发明的运动跟踪实现示意图
图5是本发明的程序运行下猪只跟踪示意图
图6是本发明的跟踪轨迹图和位移图
具体实施方式
下面结合附图对本发明作进一步说明。
本发明用于在养殖场环境下对动物进行视频跟踪与分析,针对目前养殖户自动化监控水平不高等问题,结合图像处理和视频跟踪技术,特别是利用对深度学习神经网络模型的训练,基于视频的跟踪,绘制出目标的运动轨迹和位移图,得到动物的活跃度信息,以此来作为动物健康情况的判断方式之一,从而达到减少人员工作量,提高效率,节约成本,减少养殖场损失的目的。
一种基于python环境下的目标运动视频跟踪方法,如图1所示,主要包括以下几个过程:
过程1:监控环境建立及数据采集
主要是在养猪场的猪舍安装顶视摄像头,通过物联网技术远程获取和分析监控视频图像。由于数据采集过程中会出现光线干扰,异物遮挡等问题,所以在利用高清摄像头采集的过程中需要人工检测采集图像,达到精准筛选的目的。
过程2:数据预处理与模型训练
数据预处理主要是对图像的预处理,对过程1中筛选的图像进行图片大小和光线调整等操作,其中图像的大小统一调整为300*300的图像,保证猪只的躺卧和站立姿势明显,在这过程中可进行轻微的旋转调整,以达到训练集图片标准和清晰的目的,从而更好的训练模型。
训练模型的设计过程中要根据猪舍猪只的大小和特点以及图像的数量,针对性地设计训练模型和方式,如图2所示,预训练基础网络模型采用vgg16,改动的主要内容包括:额外增加的卷积层个数,卷积核的大小,池化区域大小、层数以及滑动间隔等参数。
模型训练时要结合数据集设置相关训练参数,包括:训练模式、学习率、迭代次数等等。在使用预训练模型(如voc,coco等)时需要根据需要抽取自己需要的类别进行加权,利用加权后的新模型训练自己的数据集,从而在数据量较低的情况下提高精度和效率。
过程3:获取目标的质心点
利用的相关方法包括:canny边缘检测算法,高斯滤波器平滑图像、计算梯度幅值和角度图像、非极大值抑制、双阈值处理,连接边缘等完成边缘检测,如图3所示,连接边缘。
边缘图像为g(x,y),质心点位置为(xc,yc),原点不变矩的计算公式为:
其中mpq定义为一个p*q阶矩阵,0阶矩m00是边缘图像的灰度值和,m和n分别为该边缘图像横纵坐标的最大值。
质心点的计算公式为:
利用上述方法,可在程序中直接抓取生猪质心。
过程4:获取并绘制运动轨迹和位移图
如图4所示,建立笛卡尔坐标系,利用红线连接生猪质心,绘制运动轨迹并保存至笛卡尔坐标系中。绘制轨迹结果如图5和图6所示。
如果测试跟踪结果不理想,则再调整相关参数重新开始训练,直到达到应用要求。达到后将应用于实验场进行辅助养殖人员监控生猪活动情况。
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!