一种基于Bi-GRU的PM2.5数据处理与预测方法与流程
本发明属于空气污染数据处理与预测
技术领域:
,具体涉及一种基于bi-gru(bidirectional-gatedrecurrentunit,双向门控循环单元)的pm2.5数据处理与预测方法。
背景技术:
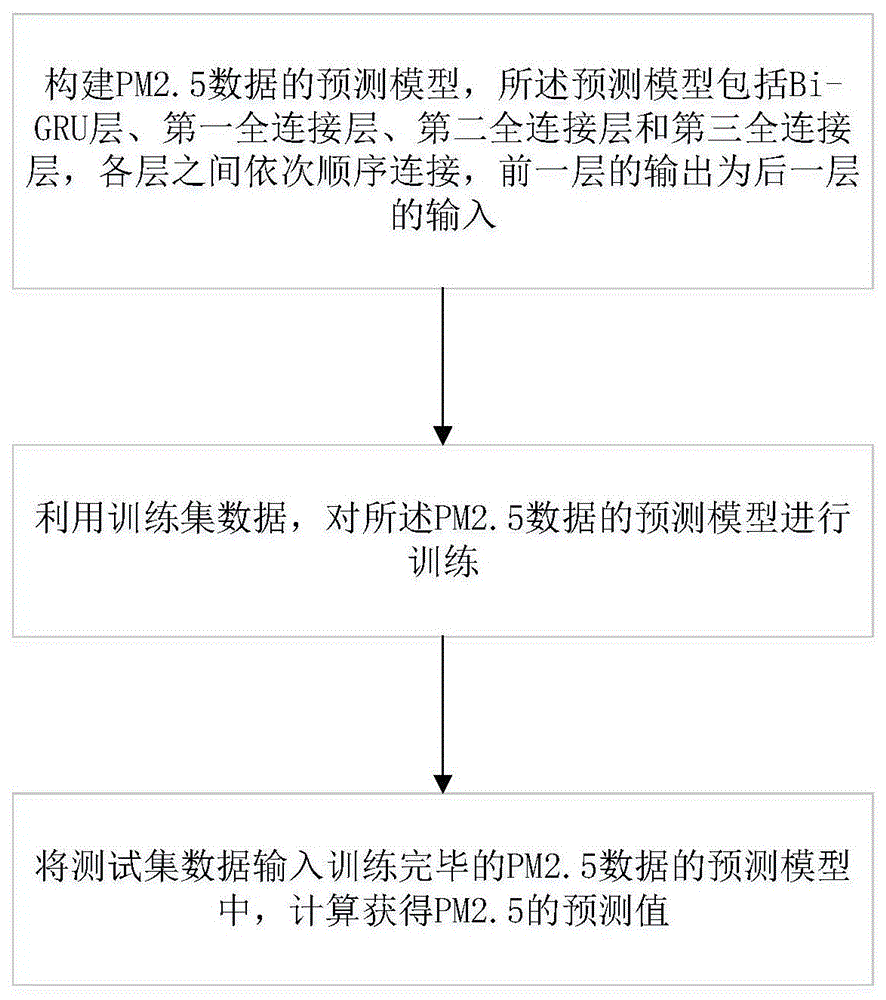
:空气污染问题已经成为了社会普遍关注的重要问题之一。每年空气污染会导致300万人死亡,并且这个人数还在不断上升。在中国,雾霾的影响日益增大,其中最为关键的pm2.5及以下的微粒。由于pm2.5在吸入人体以后,其中75%会在肺泡内沉积,导致呼吸系统感染,胎儿发育等严重健康问题。政府一直致力于如何减少空气污染以及对人们健康的影响。一方面,政府通过限制污染企业、提倡绿色清洁能源的使用,努力治理减少空气污染物排放的同时,另一方面通过提前预测未来pm2.5浓度信息发布公众,提醒人们在极端恶劣的条件下减少户外活动,能够给人们的身体健康给与最大限度的保护。因此,对于pm2.5污染浓度的预测研究尤为重要。目前对于pm2.5污染浓度的预测精度仍然不够,难以满足人们的需求。主要采用的方法有基于回归的预测、基于随机森林的预测、基于svm的预测以及基于神经网络的预测。近年来,随着人工智能技术的发展,越来越多的人发现基于神经网络的预测方法优势较为突出,能够取得较好效果。大量学者采用了lstm、con-lstm方法对空气污染浓度进行了预测,然而精度不够理想。并且实验证明,单纯的增加lstm或者con-lstm单元的个数并不能对预测精度进行提高。技术实现要素:有鉴于此,本发明的目的在于提供一种基于bi-gru的pm2.5数据处理与预测方法,通过连接两个gru(gatedrecurrentunit,门控循环单元)模型(正向gru和反向gru)形成的一个双向结构,在gru的基础上能够更加充分的获取序列数据的上下文信息,用于对pm2.5数据的预测有较好的效果。本发明的目的是这样实现的,包括以下步骤:步骤1,构建pm2.5数据的预测模型;步骤2,利用训练集数据,对所述pm2.5数据的预测模型进行训练;步骤3,将测试集数据输入训练完毕的pm2.5数据的预测模型中,计算获得pm2.5的预测值;所述预测模型包括bi-gru层、第一全连接层、第二全连接层和第三全连接层,各层之间依次顺序连接,前一层的输出为后一层的输入,所述bi-gru层由一个正向gru模型和一个反向gru模型并联形成一个双向结构,所述bi-gru层输出两个合并的gru信号,所述的第一全连接层的输出层为100,所述的第二全连接层的输出层为10,所述的第三全连接层的输出层为1;所述训练集数据包括影响因素数据和已知的pm2.5观测数据;所述的测试集数据为待预测的pm2.5数据的影响因素数据。具体地,所述影响因素数据包括predictionhours前历史pm2.5数据、光照强度、露点温度、空气湿度、气压、温度、风速、每小时降雨量、8小时历史总降雨量、时间、季节、风向共20栏数据;所述时间分为白天和黑夜2栏;所述的季节分为春季、夏季、秋季、冬季4栏,风向分为东风、南风、西风、北风、无风5栏;其中,predictionhours是一个预设参数,代表预测未来predictionhours小时的pm2.5浓度。优选地,对所述训练集数据根据不同时间或季节进行分类,使用不同类别的训练集分别训练不同类型下的pm2.5数据的预测模型;预测模型训练完成以后,针对当前测试集数据,利用测试集数据对应类型的预测模型,计算获得pm2.5的预测值。具体地,所述的bi-gru层中正向gru模型的中间输出反向gru模型的中间输出对正向gru模型和反向gru模型的中间输出的聚合操作,得到输出表示将正向gru模型的输出与反向gru模型输出进行合并连接,作为所述的bi-gru层的输出;其中z1t、为正向gru模型的中间值,z2t、为反向gru模型的中间值。具体地,步骤1中所述预测模型的输出值为所述输出值为未来predictionhours后的pm2.5浓度,w12o和b12o为模型参数,通过训练可得。优选地,所述预测模型中的损失函数采用标准归一化mse,激活函数采用relu函数,步骤2的训练过程中,通过adam函数进行学习,得到参数神经网络参数模型。本发明方法中的bi-gru层是一种改进的gru模型,通过连接两个gru模型(正向gru和反向gru)形成的一个双向结构,在gru的基础上能够更加充分的获取序列数据的上下文信息,用于对pm2.5的预测有较好的效果。附图说明图1为本发明方法的流程示意图;图2为本发明方法的预测模型结构图;图3为本发明实施例中gru的结构图;图4为本发明实施例中bi-gru模型的结构示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。如图1所示,一种基于bi-gru的pm2.5数据处理与预测方法,包括以下步骤:步骤1,构建pm2.5数据的预测模型;步骤2,利用训练集数据,对所述pm2.5数据的预测模型进行训练;步骤3,将测试集数据输入训练完毕的pm2.5数据的预测模型中,计算获得pm2.5的预测值;如图2所示,所述预测模型包括bi-gru层、第一全连接层、第二全连接层和第三全连接层,各层之间依次顺序连接,前一层的输出为后一层的输入,所述bi-gru层由一个正向gru模型和一个反向gru模型并联形成一个双向结构,所述bi-gru层输出两个合并的gru信号,所述的第一全连接层的输出层为100,所述的第二全连接层的输出层为10,所述的第三全连接层的输出层为1;所述训练集数据包括影响因素数据和已知的pm2.5观测数据;所述的测试集数据为待预测的pm2.5数据的影响因数数据。具体地,所述影响因素数据包括predictionhours前历史pm2.5数据、光照强度、露点温度、空气湿度、气压、温度、风速、每小时降雨量、8小时历史总降雨量、时间、季节、风向共20栏数据;所述时间分为白天和黑夜2栏;所述的季节分为春季、夏季、秋季、冬季4栏,风向分为东风、南风、西风、北风、无风5栏;其中,predictionhours是一个预设参数,代表预测未来predictionhours小时的pm2.5浓度。优选地,对所述训练集数据根据不同时间或季节进行分类,使用不同类别的训练集分别训练不同类型下的pm2.5数据的预测模型;预测模型训练完成以后,针对当前测试集数据,利用测试集数据对应类型的预测模型,计算获得pm2.5的预测值。gru模型是传统的在lstm模型上的一个改进版,其基本结构如图3所示,其中包含了遗忘门和更新门两个主要处理单元,该结构能够对时间序列的长时间依赖进行有效记忆和遗忘,从而保证时序数据的预测精度。其数学表达式如下:遗忘门的输出:ft=σ(wf[ht-1,xt]+bf),其中σ(x)=1/(1+e-x);在更新门中,zt=σ(wz[ht-1,xt]+bz),输出层:yt=wo·ht+bo,模型中需要训练的参数包括[wf,bf],[wz,bz],[wh,bh],[wo,bo]。bi-gru是一种改进的gru模型,通过连接两个gru模型(正向gru和反向gru)形成的一个双向结构,在gru的基础上能够更加充分的获取序列数据的上下文信息。其网络结构示意如图4所示。与gru不同之处在于,每一个bi-gru输出两个合并的gru信号,正向gru信号ht和反向gru信号h't,计算方式不变。具体地,所述的bi-gru层中正向gru模型的中间输出反向gru模型的中间输出对正向gru模型和反向gru模型的中间输出的聚合操作,得到输出表示将正向gru模型的输出与反向gru模型输出ht2进行合并连接,作为所述的bi-gru层的输出;其中z1t、为正向gru模型的中间值,z2t、为反向gru模型的中间值。正向gru模型中第一层遗忘门输出为:f1t=σ(w1f[h1t-1,xt]+b1f),f1t为numberofgrucells×20的2维中间矩阵,numberofgrucells代表正向gru模型的内部神经单元数量,xt为2维矩阵数据,维度为windowsize×20,windowsize为输入数据的长度;在正向gru更新门中,第一输出为:z1t=σ(w1z[h1t-1,xt]+b1z),z1t的数据格式同f1t一样,第二输出为:反向gru模型相应的第一输出为:z2t=σ(w2z[h2t-1,xt]+b2z),第二输出为:为numberofgrucells×20的2维中间矩阵。具体地,所述预测模型的输出值为输出值为未来predictionhours小时后的pm2.5浓度。优选地,所述预测模型中的损失函数采用标准归一化mse,激活函数采用relu函数,步骤2的训练过程中,通过adam函数进行学习,得到参数神经网络参数模型。对所述预测模型的的训练,包括对7对参数进行训练,正向gru模型参数:[w1f,b1f],[w1z,b1z],[w1h,b1h],反向gru模型参数:[w2f,b2f],[w2z,b2z],[w2h,b2h],以及各全连接层参数[w12o,b12o]。本实验采用广州的城市空气污染数据集,一共包括predictionhours前历史pm2.5数据、光照强度、露点温度、空气湿度、气压、温度、风速、每小时降雨量、8小时历史总降雨量、时间、季节、风向共20栏数据。数据样本每1小时采集一次。对已有的数据集主要做如下处理:1、样本数据中删除年份数据和月份数据,对小时数据进行分类,对应白天和黑夜,分为两类进行替换。2、对其中的缺失数据进行插值和删除处理,因为每个城市都包含了多个传感器的空气检测点,有些传感器空气检测点的数据是丢失的,因此采用横向插值法,将同一时刻距离较近的空气采集数据按照距离进行平均,插入到该数据项中。3、数据分类裂项处理:a)将代表类别的数据,例如季节、风向数据,按照每一个不同值增加一列数据项进行裂项处理;b)对于连续型数值,进行数据归一化到[0,1]间的值。本实验所采用的硬件为:电脑主要配置为:pentium(r)dual-core3.06cpu,8gram内存。效果评估:本实验的性能评估采用的参数包括rmse、mae、mape以及cc:rmse(rootmeansquareerror,均方根误差),其计算方式为:mae(meanabsolutelyerror,平均绝对误差),其计算方式为:mape(meanabsolutelypercentageerror平均绝对百分误差),其计算方式为:ccv(correlationcoefficientvalue),相关系数,其计算方式为:需要说明的是,rmse、mae以及mape都是对预测误差的衡量,其值越小代表越准确,而ccv参数代表两个序列数量的相关系数,其值越大,代表两个序列数据越为相关,预测效果越好。首先预测广州未来1小时的pm2.5的浓度,预测精度如下:表1不同算法的预测结果值模型名称rmsemaemapeccvlstm11.34288.31270.25960.8803gru12.59779.19210.30710.8500本发明方法11.29218.24520.23910.8979从表1中可以看出,在针对广州未来1小时的pm2.5浓度预测计算中,本发明方法中比起其他两种模型方法具有较好的性能。同理,下面分析在未来3小时的不同模型的性能差异。针对预测未来3小时的pm2.5的浓度,不同模型的计算精度如表2所示。表2未来3小时不同模型的预测精度模型名称rmsemaemapeccvlstm18.370213.34330.42360.6549gru22.727216.22150.53720.5335本发明方法19.031215.38010.39160.6699由
发明内容和实施例可知,本发明一种基于bi-gru的pm2.5数据处理与预测方法,gru模型是传统的在lstm模型上的一个改进版,其中包含了遗忘门和更新门两个主要处理单元,该结构能够对时间序列的长时间依赖进行有效记忆和遗忘,从而保证时序数据的预测精度,而bi-gru是一种改进的gru模型,通过连接两个gru模型(正向gru和反向gru)形成的一个双向结构,在gru的基础上能够更加充分的获取序列数据的上下文信息,用于对pm2.5数据的处理和预测有较好的效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1