一种基于气象因子的CA-NARX水质预测方法与流程
本发明涉及智能水质预测数据应用技术领域,尤其是一种基于气象因子的ca-narx水质预测方法,应用于水源地水质预测及管理。
背景技术:
水源地的水质情况与人民生活息息相关,运用科学的方法对水质指标进行预测是一种有效的水资源管理和保护方法。总磷、总氮含量是水体富营养化状态的重要评价指标,也是影响水体环境的重要因素。对水体中总磷、总氮含量的准确快速预测可为水环境的评估与预警提供理论支撑,同时也为相关部门提供决策依据,有助于水环境监控与管理工作的进行,保证居民饮水的安全性。
目前,世界上水质预测方面主要有三大方向:从大量的水质历史数据挖掘信息进而预测水质、建立先进准确的水动力数学模型预测水质、通过气象因子数据预测水质。在运用大量历史数据进行水质预测研究方面,alinajahahmed等提出了一种以ph值等水质参数历史数据为基础的神经模糊推理系统(wdt-anfis),并结合了小波增强去噪进行改进以减少数据误差对预测结果造成的影响;在建立先进准确的水动力数学模型方面,蒋晨韵等构建了三维水动力-水质模型研究气温、水温、风力对蓝藻水华的影响;唐旺等利用三维耦合模型研究了库区水温和水质的相互影响关系。但是对于像中国石河水库这种中小型水库来说,上述从大量的水质历史数据挖掘信息进而预测水质和建立先进准确的水动力数学模型预测水质的方法并不适用。首先,获取大量的历史数据并不容易。我国的中小型水库多是每月采样检测两次,周期长、反应慢,难以实现实时监测从而获取大量数据。其次,引进先进的模型及软件对于中小型水库而言,花费较高,有大材小用的弊端。水体中的氮、磷营养盐污染一般来源于点源和非点源污染,点源污染排放集中、位置固定,如工业废水、城市生活废水等,一般容易得到有效控制。非点源污染主要通过农施化肥、土壤侵蚀、地表径流以及大气干湿沉降等方式进入水体,排放方式多样、难以监测和控制,国内外研究较少。
技术实现要素:
本发明需要解决的技术问题是提供一种基于气象因子的ca-narx水质预测方法,是对数据的准确聚类并快速准确预测的方法,利用简便易测的气象因子气温、水温、降雨量、相对湿度来研究影响水质重要因素总磷、总氮的相关性,设计优化的聚类方法与前向型narx神经网络相结合的算法,实现对水质的准确快速预测。
为解决上述技术问题,本发明所采用的技术方案是:一种基于气象因子的ca-narx水质预测方法,包括以下步骤:
步骤1:将逐日水质数据、气象因子数据分别存入矩阵,并对数据进行min-max标准化;
步骤2:根据分类数对应分位数选取初始聚类中心;
步骤3:根据各样本观测点距初始聚类中心的欧氏距离进行初步聚类;
步骤4:根据各样本观测点距聚类中心的马氏距离进行按批迭代聚类,直至前后两次迭代的聚类中心欧式距离之差小于某数值;
步骤5:遍历某范围的聚类数,分别计算每类聚类数下的样本平均轮廓系数值,选取与1相差最小的轮廓系数对应的聚类数,得到最佳聚类情况;
步骤6:将分类后的气象因子数据和水质数据归一化,并转化为时间序列数据,创建数据集,并初始化输入、输出延时阶数,隐含层个数参数;
步骤7:采用交叉验证方法,将样本数据随机的分成m份,每次随机的选择m-3份作为训练集,剩下的1份做测试集,2份做验证集,当这一轮完成后,重新随机选择m-3份来训练数据算法,重复进行一定轮数;
步骤8:创建非线性自回归神经网络,确定训练函数、误差函数;
步骤9:进行网络训练,计算隐含层、输出层的输出,计算实际输出值与期望输出值的误差;
步骤10:进行权值、阈值更新,重复步骤8~步骤9,直至满足训练结果的平均误差小于某数值;
步骤11:输入相应影响因子数据,通过网络仿真输出总磷、总氮含量预测值。
本发明技术方案的进一步改进在于:步骤1中的逐日水质数据包括总磷、总氮含量;气象因子数据包括气温、水温、降雨量、相对湿度。
本发明技术方案的进一步改进在于:步骤1中具体的min-max标准化方法为:将n日的水质数据总磷、总氮含量数据存入矩阵y=[y1,y2],其中yi=[y1i,y2i…yni]′i=1,2,将四个气象因子气温、水温、降雨量、相对湿度数据存入矩阵x=[x1,x2,x3,x4],其中xi=[x1i,x2i…xni]′i=1,2,3,4,分别对两类数据进行min-max标准化,具体标准化公式为:
本发明技术方案的进一步改进在于:步骤2中选取初始聚类中心的具体方法为:设聚类数为k,设将样本分为k类,则第h个聚类中心为各变量的
本发明技术方案的进一步改进在于:步骤3中,进行初步聚类的具体方法为:根据n个观测值距k个聚类中心的欧氏距离进行第一次聚类,设y1,y2,…yn为n个样本,即yi=[yi1,yi2,…yim]′,则第j个样本与第h个聚类中心之间的欧氏距离为:
则分类准则为:
即将观测点归到距聚类中心欧式距离最小的类别。
本发明技术方案的进一步改进在于:步骤4中具体的方法包括如下步骤:
ⅰ:设第h类的观测个数为nh,计算每类数据的类均值
ⅱ:计算每次聚类前后新旧聚类中心之间的欧氏距离d,并以此作为目标值,如果新聚类中心下的目标值小于之前聚类中心下的目标值,则更新聚类中心,重复步骤ⅰ直至聚类中心不再更新。
本发明技术方案的进一步改进在于:步骤5中具体的方法包括如下步骤:
ⅲ:计算当前聚类个数的平均轮廓系数:
设样本i属于第h0类,则其到同类其他样本的平均距离a(i)计算公式为:
样本i的簇间不相似度b(i)的计算公式为:
b(i)=min{bi1,bi2,bi3…bik}(8)
样本的轮廓系数均值
a(i)为第i个样本值距同类别其他样本值的平均距离,即簇内不相似度,b(i)为第i个样本值距其它类他样本值的平均距离的最小值,即簇间不相似度,聚类目的为同类间距离尽可能小,不同类之间的差别尽可能大,故s(i)的值越接近于1,聚类效果越好,从而
ⅳ:依次确定聚类个数为3、4、5、6,重复ⅰ至ⅲ步,依次计算出不同聚类中心个数下的样本平均轮廓系数值,选择使样本平均轮廓系数值最接近1的聚类个数,并将其作为最终的聚类个数。
本发明技术方案的进一步改进在于:步骤6中具体的方法包括如下步骤:
ⅴ:构造时间序列数据:设输入因子x(k)表示为:
x(k)=x(μ1(k),μ2(k),μ3(k),μ4(k),μ5(k))(10)
其中μ1(k),μ2(k),μ3(k),μ4(k),μ5(k)分别表示第k天气温、水温、降雨量、湿度的情况,并以tp(k)、tn(k)表示第k天的总磷、总氮含量情况;
ⅵ:确定输入变量:同标准的narx动态回归神经网络不同,输入变量除去上述四个气象因子外,直接将已知的总磷、总氮含量作为输入变量,这样就将神经网络变成单纯的前向型神经网络,使网络化动态为静态;
ⅶ:确定延时阶数及隐含层神经元个数:根据经验进行初拟,并经过反复试凑确定输入、输出时延阶数为2,隐层神经元数目为12,并选取隐含层激活函数f1为tansig函数,输出层激活函数f2为purelin函数,函数具体表达式如下:
f2=x(12)。
本发明技术方案的进一步改进在于:步骤8中具体的方法为:建立非线性自回归模型:
tp(k+1)=f2f1(x(k-1),x(k),tp(k-1),tp(k))(13)
tn(k+1)=f2f1(x(k-1),x(k),tp(k-1),tn(k))(14)。
本发明技术方案的进一步改进在于:步骤9中具体的方法为:随机初始化隐含层和输出层各神经元的权值和偏置值,以trainlm作为训练函数,mse作为误差函数,根据每次训练误差情况对网络进行训练确定合适的权值和偏置值。
由于采用了上述技术方案,本发明取得的技术进步是:
1、本发明设计新型的聚类算法,运用数据标准化后的行和分位数确定初始聚类中心,在一定程度上保证了初始聚类中心的合理性,保证后续聚类迭代的聚类效果,并引入马氏距离作为迭代分类的判别准则,可以克服传统聚类算法对类间协差阵齐性的要求,同时引入平均轮廓系数值作为评判当前聚类数好坏的准则,克服传统动态聚类个数无法确定的缺点。
2、本发明引入前向型narx神经网络,直接将气象因子和前1-2天的水质数据作为输入因子,同时结合m折交叉验证方法进行神经网络的训练,节省训练时间,提高了训练的准确度,此方法的设计考虑了水质情况变化的逐步性,利用水质的过去情况预测将来情况。
3、本发明充分考虑了我国中小型水库获取大量的历史数据不容易,并且引进先进的模型及软件花费较高的情况,运用简便易测的气象因子及水质的过去情况快速准确的预测近期水质情况,为水库管理人员提供一定决策依据,并且本发明设计的分类预测可应用于其他需提前决策的领域,应用较广。
4、本发明提出的ca-narx算法,性能稳定,框架简洁,具有很强的通用性和可移植性,可以应用于相关领域的预测问题中,亦可以嵌入到别的算法中,不仅为水质预测问题提出了新的思路和方法,而且还有效拓展了聚类、narx神经网络算法的应用深度和广度。
附图说明
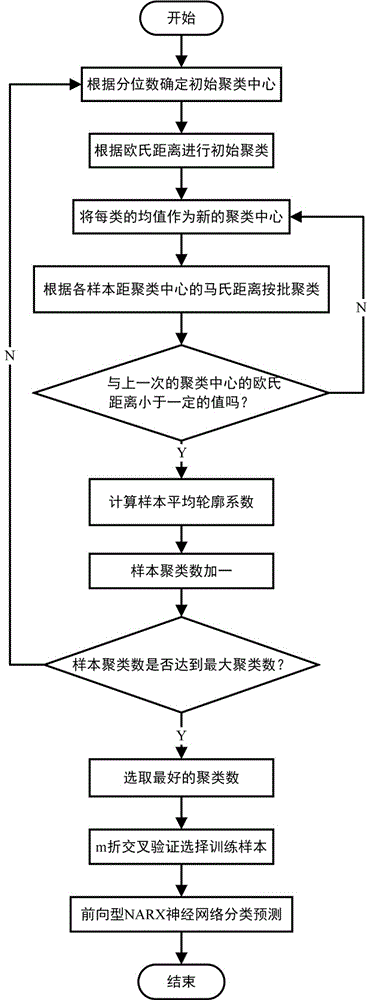
图1是本发明主要思想流程图;
图2是本发明前向型narx神经网络的具体结构图;
图3是本发明的详细算法流程图。
具体实施方式
本发明的关键技术是:①数据标准化后根据四个因素分位数选取初始聚类中心,根据各样本观测点距初始聚类中心的欧氏距离进行初步聚类,然后计算各类的类内方差,从而不断根据样本观测距各类中心的马氏距离进行迭代,直至前后两次迭代的总距离差小于一定数值,同时遍历一定范围的聚类数,根据样本平均轮廓系数(轮廓系数)值确定最佳聚类数。②根据分类数据运用前向型narx神经网络直接以四个气象因子和前1-2天的水质数据作为输入因子,结合m折交叉验证方法对网络进行训练,可以预测未来30天左右的总磷、总氮含量。
下面结合图1~3及实施例对本发明做进一步详细说明:
如图1所示,一种基于气象因子的ca-narx水质预测方法,包括以下步骤:
步骤1:将逐日水质数据、气象因子数据分别存入矩阵,并对数据进行min-max标准化;逐日水质数据包括总磷(mg/l)、总氮含量(mg/l);气象因子数据包括气温(度)、水温(度)、降雨量(mm)、相对湿度(mm);具体的min-max标准化方法为:将n日的水质数据总磷、总氮含量数据存入矩阵y=[y1,y2],其中yi=[y1i,y2i…yni]′i=1,2,将四个气象因子气温、水温、降雨量、相对湿度数据存入矩阵x=[x1,x2,x3,x4],其中xi=[x1i,x2i…xni]′i=1,2,3,4,分别对两类数据进行min-max标准化,具体标准化公式为:
步骤2:根据分类数对应分位数选取初始聚类中心;选取初始聚类中心的具体方法为:设聚类数为k,设将样本分为k类,则第h个聚类中心为各变量的
步骤3:根据各样本观测点距初始聚类中心的欧氏距离进行初步聚类;进行初步聚类的具体方法为:根据n个观测值距k个聚类中心的欧氏距离进行第一次聚类,设y1,y2,…yn为n个样本,即yi=[yi1,yi2,…yim]′,则第j个样本与第h个聚类中心之间的欧氏距离为:
则分类准则为:
即将观测点归到距聚类中心欧式距离最小的类别。
步骤4:根据各样本观测点距聚类中心的马氏距离进行按批迭代聚类,直至前后两次迭代的聚类中心欧式距离之差小于某数值;具体的方法包括如下步骤:
ⅰ:设第h类的观测个数为nh,计算每类数据的类均值
ⅱ:计算每次聚类前后新旧聚类中心之间的欧氏距离d,并以此作为目标值,如果新聚类中心下的目标值小于之前聚类中心下的目标值,则更新聚类中心,重复步骤ⅰ直至聚类中心不再更新。
步骤5:遍历一定范围的聚类数,分别计算每类聚类数下的样本平均轮廓系数值,选取与1相差最小的轮廓系数对应的聚类数,得到最佳聚类情况;具体的方法包括如下步骤:
ⅲ:计算当前聚类个数的平均轮廓系数:
设样本i属于第h0类,则其到同类其他样本的平均距离a(i)计算公式为:
样本i的簇间不相似度b(i)的计算公式为:
b(i)=min{bi1,bi2,bi3…bik}(8)
样本的轮廓系数均值
a(i)为第i个样本值距同类别其他样本值的平均距离,即簇内不相似度,b(i)为第i个样本值距其它类他样本值的平均距离的最小值,即簇间不相似度,聚类目的为同类间距离尽可能小,不同类之间的差别尽可能大,故s(i)的值越接近于1,聚类效果越好,从而
ⅳ:依次确定聚类个数为3、4、5、6,重复ⅰ至ⅲ步,依次计算出不同聚类中心个数下的样本平均轮廓系数值,选择使样本平均轮廓系数值最接近1的聚类个数,并将其作为最终的聚类个数。
步骤6:将分类后的气象因子数据和水质数据归一化,并转化为时间序列数据,创建数据集,并初始化输入、输出延时阶数,隐含层个数等参数;具体的方法包括如下步骤:
ⅴ:构造时间序列数据:设输入因子x(k)表示为:
x(k)=x(μ1(k),μ2(k),μ3(k),μ4(k),μ5(k))(10)
其中μ1(k),μ2(k),μ3(k),μ4(k),μ5(k)分别表示第k天气温、水温、降雨量、湿度的情况,并以tp(k)、tn(k)表示第k天的总磷、总氮含量情况;
ⅵ:确定输入变量:同标准的narx动态回归神经网络不同,输入变量除去上述四个气象因子外,直接将已知的总磷、总氮含量作为输入变量,这样就将神经网络变成单纯的前向型神经网络,使网络化动态为静态;
ⅶ:确定延时阶数及隐含层神经元个数:根据经验进行初拟,并经过反复试凑确定输入、输出时延阶数为2,隐层神经元数目为12,并选取隐含层激活函数f1为tansig函数,输出层激活函数f2为purelin函数,函数具体表达式如下:
f2=x(12)。
步骤7:采用交叉验证方法,将样本数据随机的分成m份,每次随机的选择m-3份作为训练集,剩下的1份做测试集,2份做验证集,当这一轮完成后,重新随机选择m-3份来训练数据算法,重复进行一定轮数;
步骤8:创建非线性自回归神经网络,确定训练函数、误差函数;具体的方法为:建立非线性自回归模型:
tp(k+1)=f2f1(x(k-1),x(k),tp(k-1),tp(k))(13)
tn(k+1)=f2f1(x(k-1),x(k),tp(k-1),tn(k))(14)。
步骤9:进行网络训练,计算隐含层、输出层的输出,计算实际输出值与期望输出值的误差;具体的方法为:随机初始化隐含层和输出层各神经元的权值和偏置值,以trainlm作为训练函数,mse作为误差函数,根据每次训练误差情况对网络进行训练确定合适的权值和偏置值。
步骤10:进行权值、阈值更新,重复步骤8~步骤9,直至满足训练结果的平均误差小于某数值;
步骤11:输入相应影响因子数据,通过网络仿真输出总磷、总氮含量预测值。
具体的使用方法:
(1)将n日的水质数据总磷、总氮含量数据存入矩阵y=[y1,y2],其中yi=[y1i,y2i…yni]′i=1,2.,将四个气象因子气温、水温、降雨量、湿度数据存入矩阵x=[x1,x2,x3,x4],其中xi=[x1i,x2i…xni]′i=1,2,3,4,分别对两类数据进行min-max标准化,具体标准化公式为:
(2)设聚类数为k,设将样本分为k类,则第h个聚类中心为各变量的
(3)根据n个观测值距k个聚类中心的欧氏距离进行第一次聚类,设y1,y2,…yn为n个样本,即yi=[yi1,yi2,…yim]′,则第j个样本与第h个聚类中心之间的欧氏距离为:
则分类准则为:
即将观测点归到距聚类中心欧式距离最小的类别。
(4)设第h类的观测个数为nh,计算每类数据的类均值
(5)计算每次聚类前后新旧聚类中心之间的欧氏距离d,并以此作为目标值,如果新聚类中心下的目标值小于之前聚类中心下的目标值,则更新聚类中心。重复步骤(4)直至聚类中心不再更新;
(6)计算当前聚类个数的平均轮廓系数:
设样本i属于第h0类,则其到同类其他样本的平均距离a(i)计算公式为:
样本i的簇间不相似度b(i)的计算公式为:
b(i)=min{bi1,bi2,bi3…bik}(8)
样本的轮廓系数均值
a(i)为第i个样本值距同类别其他样本值的平均距离,即簇内不相似度,b(i)为第i个样本值距其它类他样本值的平均距离的最小值,即簇间不相似度,聚类目的为同类间距离尽可能小,不同类之间的差别尽可能大,故s(i)的值越接近于1,聚类效果越好,从而
(7)依次确定聚类个数为3、4、5、6,重复步骤(4)至步骤(6),依次计算出不同聚类中心个数下的样本平均轮廓系数值,选择使样本平均轮廓系数值最接近1的聚类个数,并将其作为最终的聚类个数。
(8)构造时间序列数据:设输入因子x(k)表示为:
x(k)=x(μ1(k),μ2(k),μ3(k),μ4(k),μ5(k))(10)
其中μ1(k),μ2(k),μ3(k),μ4(k),μ5(k)分别表示第k天气温(temp)、水温(wt)、降雨量(prcp)、湿度(h)的情况,并以tp(k)、tn(k)表示第k天的总磷、总氮含量情况。
(9)确定输入变量:同标准的narx动态回归神经网络不同,输入变量除去上述四个气象因子外,直接将已知的总磷、总氮含量作为输入变量,这样就将神经网络变成单纯的前向型神经网络,使网络化动态为静态;
(10)确定延时阶数及隐含层神经元个数:根据经验进行初拟,并经过反复试凑确定输入、输出时延阶数为2,隐层神经元数目为12,并选取隐含层激活函数f1为tansig函数,输出层激活函数f2为purelin函数[17-20],函数具体表达式如下:
f2=x(12)
(11)对于每一类水质情况采用交叉验证方法,将样本数据随机的分成m份,每次随机的选择m-2份作为训练集,剩下的1份做测试集,2份做验证集。当这一轮完成后,重新随机选择m-2份来训练数据算法.重复进行一定轮数;
(12)建立非线性自回归模型:
tp(k+1)=f2f1(x(k-1),x(k),tp(k-1),tp(k))(13)
tn(k+1)=f2f1(x(k-1),x(k),tp(k-1),tn(k))(14)
(13)随机初始化隐含层和输出层各神经元的权值和偏置值,以trainlm作为训练函数,mse作为误差函数,根据每次训练误差情况对网络进行训练确定合适的权值和偏置值,重复步骤12-13,直至满足停止训练样本结果的平均误差小于一定值;
(14)重复步骤11-13;
(15)输入相应影响因子数据,通过网络仿真输出总磷、总氮含量预测值。
下面结合仿真实验对本发明进行进一步说明。
1、实验内容:采集秦皇岛石河水库2018年逐日水质数据和气象因子数据,进行未来一个月的水质预测。
2、实验结果:去噪后总氮含量317个样本中三类样本聚类中心分别为1.28、4.59、5.87(单位:mg/l),对应成员个数分别为165、93、59。对比分类情况我们将总氮含量分为1-6月、7-8月、9-12月三种水体富营养化情况。总磷变化情况基本同总氮。所以我们在对总磷、总氮含量进行预测时,均分三个阶段分别进行预测。考虑到均方误差mse代表训练输出值与目标值之间的误差情况,本发明以mse的值作为预测准确度的评价指标,其中均方误差mse的值越接近于零,代表神经网络的训练效果越好,其表达式如下:
n为训练集样本总数;y(t)为期望输出值,y′(t)为训练输出值。
为检验本发明的预测效果,将本发明ca-narx算法与应用广泛的传统bp神经网络、支持向量机(svm)预测方法进行对比,得到三种方法对三类水质的总磷、总氮含量预测的mse情况如下:
表1、svm、bp、ca-narx三种方法预测结果比较
通过表1结果可得,ca-narx算法的均方误差小于bp和支持向量回归机(svm)方法。可见本发明的预测精度较好。
综上所述,本发明在原始传统聚类算法的基础上加入按标准化数据后的变量分位数选取初始聚类中心,按轮廓系数值选取合适的聚类个数的优化聚类算法,并与交叉验证法下训练的前向型narx神经网络结合实现水质的分类预测;本发明提出的ca-narx算法性能稳定,框架简洁,具有很强的通用性和可移植性,可以应用于相关领域的预测问题中,亦可以嵌入到别的算法中,不仅为水质预测问题提出了新的思路和方法,而且还有效拓展了聚类、narx神经网络算法的应用深度和广度。
- 还没有人留言评论。精彩留言会获得点赞!