基于深度圈视图的无监督3D物体识别与检索方法与流程
本发明涉及一种基于无监督的3d物体识别与检索技术,通过全新的3d数据渲染方式采集出深度圈视图数据,并创造性的进行无监督训练。涉及随机混合,最优匹配,圈特征过滤等相关优化检索性能的技术。
背景技术:
随着3d数据采集的方式和设备不断的升级,越来越多的3d数据出现在我们的生活之中,在诸多应用中都需要处理3d数据,如无人驾驶,vr虚拟现实。因此关于3d数据的识别与检索成为了当下的研究热点。回顾一些经典的3d数据识别与检索的办法,可以分为两种,一是基于点云的系列方法,二是基于多视图的方法。
基于点云的方法。点云数据是一种无网格的非结构化数据,它是分布在空间中的一系列xyz点。这些点在空间上分布不规则,彼此之间没有联系。因此将点云用于深度学习具有很大的挑战性。在点云上应用深度学习的直接方法是将数据转换为体积表示,例如体素网格。这样我们就可以用3d滤波器来训练一个cnn。(网格提供了结构,网格的转换解决了排列问题,体素的数量也是不变的)。但是,这有一些不利因素,因体积数据变得非常大,导致处理训练的时间过长。而当采用较低的分辨率去处理时又将带来很大的量化误差。pointnet,创造性的在每个点上训练了一个mlp(在各点之间分享权重)。每个点被“投影”到一个1024维空间。然后,他们用点对称函数解决了点云顺序问题。在pointnet之后不久,引入了pointnet++,它本质上是pointnet的分层版本。每个图层都有三个子阶段:采样,分组和pointnet层。在第一阶段,选择质心,在第二阶段,把他们周围的邻近点(在给定的半径内)创建多个子点云。然后他们将它们给到一个pointnet网络,并获得这些子点云的更高维表示。然后,他们重复这个过程(样本质心,找到他们的邻居和pointnet的更高阶的表示,以获得更高维表示)。pointnet++这种分层设计能够更高效,稳健地处理点集,获得更佳的效果。
基于多视图的方法,通过在不同角度,视点放置摄像机,采集出同一模型的不同视点下的多张视图来表征原3d模型。这其中,最典型的便是mvcnn,mvcnn将渲染出的多张视图输入共享权重的cnn模型中,最后以一个max-pooling将得到的特征进行融合。之后,人们又提出了gvcnn,通过神经网络自动学习多张视图之间的关系并对它们进行打分然后分组融合,这种分组融合的方法有效的解决了多张视图之间的顺序问题,减少了max-pooling融合的片面性。seqviews2seqlabels则提出一种新奇的视图融合方式,它创造性的采用了递归循环神经网络去融合多视图,并引入了seq2seq模型的selfattention去衡量各视图的重要性。这种方法不光保留了各视图的语义信息,同时也保留了各视图之间的空间信息。
以上方法虽然已经取得了很好的分类与检索效果,但是无论是在数据采集方面还是进行人工标注方面,都需要耗费巨大的人力和财力。首先,3d数据一般以off文件格式存储,并不能直接展示其具体内容,所以在打标签时需要专业人员将其转化为多视图格式或者点云格式,转化为点云还需要再额外处理点云数据将其可视化。可见3d数据在人工标注上耗时耗力。为了解决以上问题,我们首次在3d领域提出无监督训练的方法,避免了大量的人工标注并取得了不错的分类检索效果。
技术实现要素:
本发明的目的在于针对现有技术的不足,提出一种基于深度圈视图的无监督3d物体识别与检索方法。
本发明解决实现无监督训练所采用的技术方案包括以下步骤:
步骤1、多圈数据采样;
1-1.给定一个分配有唯一标签的3d模型,围绕其过圆心的截面旋转一圈并等间隔采样得到一圈序列化多视图数据;如此等间隔均匀旋转多圈,即可得到分配有唯一标签的多圈视图数据;
1-2.以每个3d模型为基本单位,获取多个分配有唯一标签的多圈视图数据,记为数据集s,表示为s={s1,s2,...,si,...,sn},其中n表示为模型的个数;
步骤2、训练基于圈数据的多视图深度网络模型;
将获取的分配有唯一标签的多圈视图数据按对取出,随机混合输入多视图深度网络模型(例如mvcnn和gvcnn)进行训练;
步骤3、相似性匹配与检索;
利用训练好的多视图深度网络模型提取各圈视图的特征,并对所有圈视图进行相似性距离计算;通过采用最大池化、均值池化、注意力池化以及最优匹配的方式优化多视图深度网络模型;基于相似性距离,进行排序检索;
步骤4、圈特征过滤与融合;
采取圈特征过滤和圈注意力策略滤除重要性低于指定阈值的圈特征,从而在保证识别精度的同时有效减少计算量。
本发明有益效果如下:
本发明公开了基于圈视图的无监督的3d物体识别与检索技术。该方法的优点在于提出了新的二维视图采集渲染方式并用其进行无监督训练,在不采用任何人工标注的情况下依然获得了可观的检索精度。极大的节省了人工标注成本。
本发明采取圈特征过滤和圈注意力策略滤除重要性较低的圈特征,可以在保证识别精度的同时有效减少计算量。
附图说明
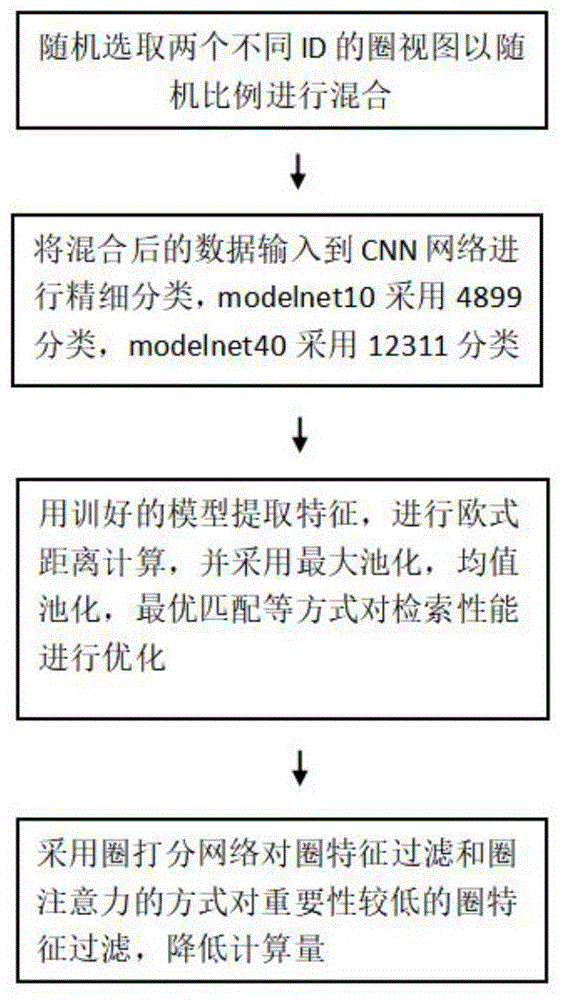
图1为本发明流程图;
图2为本发明深度圈特征评分网络图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图1和2所示,基于深度圈视图的无监督3d物体识别与检索方法,具体实现过程如下:
步骤1、多圈数据采样。
1-3.给定一个分配有唯一标签的3d模型,围绕其过圆心的截面旋转一圈并等间隔采样得到一圈序列化多视图数据;如此等间隔均匀旋转多圈,即可得到分配有唯一标签的多圈视图数据;
1-4.以每个3d模型为基本单位,获取多个分配有唯一标签的多圈视图数据,记为数据集s,表示为s={s1,s2,...,si,...,sn},其中n表示为模型的个数;
步骤2、训练基于圈数据的多视图深度网络模型。
将获取的分配有唯一标签的多圈视图数据按对取出,随机混合输入多视图深度网络模型(例如mvcnn和gvcnn)进行训练。
步骤3、相似性匹配与检索。
利用训练好的多视图深度网络模型提取各圈视图的特征,并对所有圈视图进行相似性距离计算;通过采用最大池化、均值池化、注意力池化以及最优匹配的方式优化多视图深度网络模型。基于相似性距离,进行排序检索。
步骤4、圈特征过滤与融合。
采取圈特征过滤和圈注意力策略滤除重要性低于指定阈值的圈特征,从而在保证识别精度的同时有效减少计算量。
以下结合附图对本发明作进一步详细描述。
步骤1中对多圈视图数据分配唯一的标签,具体实现如下:
将每个模型看作一类并分配唯一的标签。将modelnet10数据集的4899个模型看作是4899个类别,进行4899路分类,即可以以无监督的方式随机为每个模型分配1个唯一的标签。同样地,在modelnet40数据集可以上进行12311路分类。
步骤2中将数据随机混合方法,具体如下:
2-1.从数据集s={s1,s2,...,sn}中任意两个模型中随机取出一个圈视图,组成一对圈视图数据vi和uj,其中vi和uj属于不同的模型,分别具有唯一标记符号yi和yj。其中i表示模型中的第i个圈视图数据;j表示模型中的第j个圈视图数据;
2-2.根据给出的圈视图数据vi和uj,按以下公式将二者进行数据和标签混合:
v=vi·α+uj·(1-α);(1)
y=yi·α+yj·(1-α);(2)
其中,v、y分别表示混合后的圈视图数据和标签;α∈[0,1]为随机生成的混合比率。
然后,将混合后的圈视图数据和标签作为多视图深度网络模型的输入,采用kl散度损失函数学习网络参数:
其中,p(x)表示样本的真实分布,q(x)表示我们的方法预测出来的概率分布。
利用训练好的多视图深度网络模型提取各圈视图的特征,并对所有圈视图进行相似性距离计算;通过采用最大池化、均值池化、注意力池化以及最优匹配的方式优化多视图深度网络模型。基于相似性距离,进行排序检索。
步骤3中所述的最优匹配和池化方法,具体如下:
3-1.3d模型相似性匹配度量:
3-1-1.计算一对圈视图数据vi和uj对应的特征
3-1-2.选取数据集s中任意一个圈视图vk和单个3d模型s′之间的距离d2,其中将在每个3d模型上采样多个圈视图序列;
3-1-2.定义两个3d模型s1和s2之间的最优匹配距离d3。
其中,n1指代数据集s中某一个3d模型中圈视图的圈数。
3-2.通过最大池化、平均池化和注意力池化分别将提取出的多圈视图数据的特征进行融合,获取融合特征ⅰ、融合特征ⅱ和融合特征ⅲ;再将融合特征ⅰ、融合特征ⅱ和融合特征ⅲ通过欧式距离计算,从而度量两个模型之间的相似性。
所述的圈视数据特征为多视图深度网络模型最后一层输出。
步骤4中的圈视数据特征的过滤和圈注意力融合的方法,具体如下:
4-1.设计一种能够给各圈特征评分的深度圈特征评分网络,其流程如附图文件图2所示,具体深度圈特征评分网络如下:
4-1.深度圈特征评分网络:
4-1-1.使用多视图深度网络模型的最后一层提取出来的特征作为深度圈特征评分网络的输入,为1536维的圈视图特征向量;
4-1-2.通过一层全连接层(fc1),使大小为2048维向量;
4-1-3.通过一层全连接层(fc2),使大小为2048维向量;
4-1-4.将4-1-3层出来的特征连接起来,并输入1x1卷积层、全连接层(fc4)、标准化层(norm)得出每一圈视图特征的分值;
4-1-5.将各圈视图特征与分值对应相乘并求和的结果输入到softmax分类器进行分类训练。
通过深度圈特征评分网络得到每个圈视图数据特征的重要性评分并对评分进行排序,其中分值越小则越重要。
4-2.依据评分过滤出前
所述的评分公式如下,其中θ是fc4层的输出:
α=sigmoid(log(|θ|))
所述的圈视图数据特征的过滤有两种方式:一是通过评分去过滤fc3层输出的深度圈视图数据特征;另一种是过滤fc1层输出的深度圈视图数据特征;
4-3.过滤后将选出m个圈视图数据特征,其中m<n,n是指原有圈视图特征总数,接着进行欧氏距离相似性计算,过滤使得计算量从n×n下降到m×m,节省了大量的计算时间。
4-4.圈注意力融合是通过深度圈特征评分网络打分,将多个圈视图数据特征依据分值进行加权求和融合,然后进行欧式距离计算。加权融合的公式如下:
其中,θ指代3d模型融合后的最终特征;θk指圈视图数据特征,αk指每个圈视图数据特征的重要性分值。
- 还没有人留言评论。精彩留言会获得点赞!