一种使用语义补全神经网络来解决视频时序定位问题的方法与流程
本发明涉及视频时序定位的学习,尤其涉及种使用语义补全神经网络来解决视频时序定位问题的方法。
背景技术:
视频时序定位指的是根据一段自然语言描述从给定的视频中提取出符合这段描述的特定视频片段,这是信息提取和计算机视觉中的一个重要主题,在最近几年吸引了越来越多的关注。该技术可以高效地提取出视频中的信息,帮助用户更快地定位到视频中的特定片段。
现有的视频时序定位的方法中,有使用一个滑动窗口选择视频,并将窗口内片段与自然语言描述粗融合进行语义相关性判断的(gaoetal.2017;hendricksetal.2017;2018),有使用交互器逐帧挑选出置信度最高的视频片段的(chenetal.2018),也有使用强化学习方式来进行时序定位的(wang,huang,andwang2019),它们都取得了不错的效果。但是,现有的这些方法大多数是采用完全监督学习的方式,在数据集中,对于每个自然语言查询,都需要标注对应视频的起始时间和终止时间。这种完全监督学习的方法需要大量的人力成本和数据集标注时间,甚至在有些时候,如果原始视频还没有经过裁剪,视频片段的起始时间和终止时间就更加难以被确定。相反地,如果采用半监督学习的方法,数据集只需要输入一个视频和对应的自然语言描述,就可以高效、低成本地获取数据集。
技术实现要素:
为了克服现有技术中对数据集的数量要求较高,训练成本昂贵的问题,本发明提出了一种新颖的视频时序定位的弱监督学习方法来解决视频时序定位问题,这个方法训练时仅仅需要粒度较粗的视频级别的标注数据集。本发明将首先使用一个候选产生模块,用于结合给定的自然语言文本,生成每个时间点对应的候选视频片段以及每个视频片段的置信度;然后设计一种特定的算法来从这些生成的候选视频片段中挑选出k个优先级最高的候选视频片段;接下来使用一个语义补全模块来计算挑选出来的候选视频片段与给定的自然语言描述之间的匹配程度,然后根据匹配程度计算激励,反馈给候选产生模块,使候选产生模块调整置信度计算的参数。在经过足够的训练之后,将会生成一个有效的候选产生模块。本发明在activitycaptions数据集和charades-sta数据集上都取得了优异的效果。
本发明所采用的具体技术方案是:
一种使用语义补全神经网络来解决视频时序定位问题的方法,包含如下步骤:
1.构建语义补全神经网络,包括候选产生模块和语义补全模块;所述的候选产生模块包括c3d模块、文本编码器和图像解码器,文本编码器和图像解码器均包括若干个多头注意力层以及一个全连接的反馈神经网络层;所述的语义补全模块包括c3d模块、图像编码器和文本解码器;
2.针对于一个视频和一段自然语言描述,通过候选产生模块生成候选视频片段集合及每一个候选视频片段对应的置信度;
3.设计一种挑选算法,从步骤2所述的候选视频片段集合中挑选出k个优先级最高的候选视频片段;
4.通过语义补全模块计算步骤3挑选出来的k个优先级最高的候选视频片段与给定的自然语言描述之间的匹配程度,根据匹配程度计算对应于每一个候选视频片段的激励,并反馈给候选产生模块;
5.重复步骤2-步骤4,不断地输入对应的一个视频和一段自然语言描述,对整个神经网络进行训练,最终得到训练好的语义补全神经网络;
6.将待处理的一个视频和一段自然语言描述输入到步骤5)得到的训练好的语义补全神经网络中,输出自然语言描述相关的特定视频片段对应的起始帧下标和结束帧下标。
本发明具备的有益效果是:
本发明提出一个候选产生模块,可以使用一个文本编码器和图像解码器,来获取一个视频中各个视频片段对应给定的自然语言描述的置信度;提出一种基于非极大值抑制的挑选算法,挑选出k个候选视频片段,这个算法可以同时考虑视频的全局特征和局部特征;提出一个语义补全模块,可以使用一个文本解码器和图像编码器,来通过一个视频片段来补全一段被遮掩的自然语言描述。本发明使用的数据集中,每个视频只需要标注对应的一段自然语言描述,不需要为这段自然语言描述标注对应的视频片段的起始下标和结束下标,可以大大地节省数据集标注的成本。
附图说明
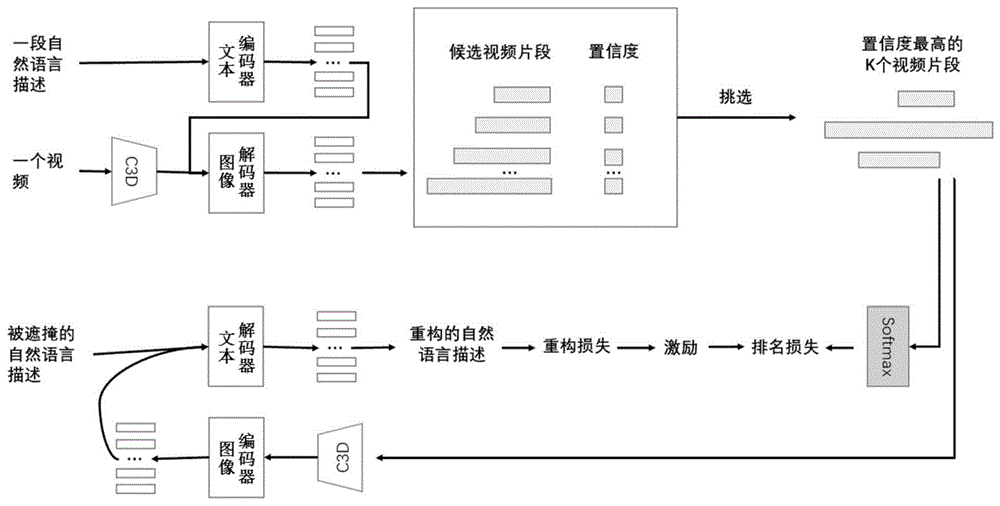
图1是语义补全神经网络的整体架构;
图2是文本/图像编码器的网络结构;
图3是文本/图像解码器的网络结构。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
图1为本发明的语义补全神经网络的整体架构,使用语义补全神经网络来解决视频时序定位问题,具体实施方案如下:
步骤一、针对于一个视频和一段自然语言描述,通过一个结合文本编码器encq和图像解码器decv组成的候选产生模块来生成候选的视频片段及对应的置信度。
在本发明的一个具体实施中,给定一个未修剪的视频
给定一个对应的自然语言描述
视频时序定位问题是为了从视频中提取出与这段自然语言描述相关性最高的视频片段
采用文本编码器encq获取
c=decv(v,encq(q))
所述的文本编码器encq和图像解码器decv均包括若干个多头注意力层以及一个全连接的反馈神经网络层;
定义每个时间点对应的候选视频片段ct,计算公式如下:
其中,rk是第k个候选视频片段对应的长度比例,rk∈(0,1);nk是第t个时间点对应的候选视频片段的数量;(t-rk*nv)和t分别是第t时间点第k个候选视频片段的起始帧下标和结束帧下标;
进一步得到整个视频的候选视频片段集合
将得到的视频和文本的交叉描述
sct=σ(ws*ct+bs)
其中,
步骤二、使用结合随机化算法,并考虑非极大值抑制的算法,从这些生成的候选视频片段中挑选出k个优先级最高的候选视频片段。
在本发明的一个具体实施中,设计一种挑选算法,所述挑选算法同时考虑全局特征和局部特征;采用所述挑选算法从候选视频片段集合
所述挑选算法具体为:每次挑选候选视频片段时,有1-p的概率会挑选剩余置信度最高的候选视频片段,有p的概率会从剩余所有的候选视频片段中随机挑选一个,p的计算公式如下所示:
p=λ1*exp(-nupdate/λ2)
其中,λ1,λ2是超参数,用于调节这个衰减函数,nupdate是模型中参数更新的次数,因此,当模型刚开始训练时,每次挑选视频片段会倾向于随机化挑选,当模型训练到后期时,每次挑选视频片段会倾向于挑选置信度最高的候选视频片段;在每次挑选完成后,使用非极大值抑制算法将与这一次挑选出来的候选视频片段重叠度高的剩余候选视频片段去除掉。
步骤三、结合文本解码器decq和图像编码器encv来组成语义补全模块,用于计算挑选出来的候选视频片段与给定的自然语言描述之间的匹配程度,然后计算给这些候选视频片段的激励,并反馈给候选产生模块,从而对其参数进行调整。
在本发明的一个具体实施中,通过一个预训练好的c3d的三维卷积神经网络,获取步骤2)挑选出来的k个优先级最高的候选视频片段
将特征向量
将一段自然语言描述表示为
根据fk,通过一个全连接层计算每一个候选视频片段gk对应的初始文本描述每个位置的单词概率分布
其中,
定义一个重构损失函数
其中,
定义对应于每一个候选视频片段gk的激励rk,用来提高重构损失较小的候选视频片段gk的优先级;所述rk的具体计算方法是:根据k个候选视频片段集合
步骤四、重复以上的步骤,不断地输入对应的一个视频和一段自然语言描述,从候选产生模块得到的视频片段中得到优先级最高的k个视频片段,并通过语义补全模块得到反馈,然后不断调整候选产生模块的参数,直到训练得到效果良好的候选产生模块。
在本发明的一个具体实施中,定义一个排名损失函数
根据排名损失函数和步骤4)得到的重构损失函数,得到一个总的多任务损失函数l,计算公式如下:
其中,β是一个超参数,用来平衡两个损失函数;
将多任务损失函数l作为语义补全神经网络的损失函数,对于不断输入的一组视频和自然语言描述,重复步骤2)~步骤4)进行训练,直到多任务损失函数l的值下降到阈值范围内,得到训练好的语义补全神经网络。
在本发明的一个具体实施中,所述语义补全神经网络包括候选产生模块和语义补全模块;所述的候选产生模块包括c3d模块、文本编码器和图像解码器,文本编码器和图像解码器均包括若干个多头注意力层以及一个全连接的反馈神经网络层;所述的语义补全模块包括c3d模块、图像编码器和文本解码器。
如图2所示,图2表示的是图像编码器和文本编码器的基本结构,其主要包含了一个多头注意力层和一个全连接的反馈神经网络层;输入的图像特征向量或文本特征向量首先经过一个多头注意力层,获取其在不同子空间下的特征,然后将其加起来并正则化后,再通过一个反馈神经网络,并加总、正则化后得到输出。
如图3所示,图3表示的是图像解码器和文本解码器的基本结构,其主要包含了两个多头注意力层和一个全连接的反馈神经网络层解码器,多增加了一个输入。输入的图像特征向量或文本特征向量首先经过一个多头注意力层,加总、正则化后,与输入的另一种特征向量再次经过一个多头注意力层,加总、正则化后通过一个反馈神经网络,再加总、正则化后得到输出。
采用训练好的语义补全神经网络对待处理的视频和自然语言描述进行处理,直接将待处理的一个视频和一段自然语言描述输入到网络中,输出自然语言描述相关的特定视频片段对应的起始帧下标和结束帧下标。
实施例
本发明使用了activitycaptions数据集和charades-sta数据集进行训练和验证。具体实施步骤同上,不再赘述。
activitycaptions数据集一开始是为了人类行为理解而建立起来的,这个数据集包含了20000个内容丰富且未经修剪过的视频。在已发布的activitycaptions数据集中,有17031个视频片段和对应的自然语言描述。这里本发明使用这个数据集的val_1作为验证集、val_2作为测试集。这个数据集的平均视频长度是117.74秒,平均自然语言描述长度是13.16个单词。
charades-sta数据集是专门的视频时序定位的数据集,这个数据集包含了12408个视频片段和对应的自然语言描述。这个数据集的平均视频长度是29.8秒,平均自然语言描述长度是8.6个单词。
为了客观地评价本发明的算法的性能,将本发明的算法与其他视频时序定位的算法进行比较。这些其他算法包括vsa-rnn,vsa-stv,ctrl,qspn,ws-dec。本发明使用了intersectionoverunion(iou)指标,这个指标衡量视频片段与自然语言描述之间的相似度,若iou越大,则说明两者相关性越大。然后再定义
在activitycaptions数据集的验证效果如下述表格所示:
在charades-sta数据集的验证效果如下述表格所示:
- 还没有人留言评论。精彩留言会获得点赞!