一种基于Docker的大数据学习平台搭建方法与流程
本发明涉及大数据平台搭建技术,尤其涉及一种基于docker的大数据学习平台搭建方法。
背景技术:
docker是一个开源的、轻量级的容器引擎,主要运行于linux和windows,用于创建、管理和编排容器,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器,容器是完全使用沙箱机制,相互之间不会有任何接口,几乎没有性能开销,可以很容易地在机器和数据中心中运行。
大数据软件开发过程中,设计的组件、服务种类多,版本迭代频繁,网络服务,存储服务,虚拟化服务等应用服务创建需要学习人员具有专门的操作系统知识,这种现状造成了初学者学习成本的上升,docker镜像技术有效的解决了这个问题。docker开发人员根据dockerfile来构建个性化的版本镜像,打包应用以及依赖包到一个可移植的容器中,组件依赖环境已经预先设置,组件的各类启动命令已经脚本化,各类服务已经提前部署,基于docker镜像的容器启动即服务。docker使用容器承载应用程序,而不使用操作系统,所以它的开销很少,性能很高。docker容器的启动时间是秒级的,大量地节约初学者学习的时间,提高初学者的学习体验。
技术实现要素:
发明目的:为降低大数据初学者的学习成本,构建独立的大数据学习平台,本发明提供一种基于docker的大数据学习平台快速搭建方法。
技术方案:一种基于docker的大数据学习平台搭建方法,包括如下步骤:
(1)初始化主机网络环境,创建虚拟网卡并桥接到物理网卡上;
(2)客户端调用脚本创建容器,所述容器具有ubuntu系统最小系统的基础组件,容器设定ssh服务,实现与服务器相同的访问;
(3)创建容器镜像,设置后台守护进程作为容器运行时的依赖进程,所述容器镜像在容器内部进程异常退出后实现自动拉起;
(4)配置容器环境变量实现,包括调用内部脚本读取环境变量实现可配置功能。
进一步的,所述基础组件包括kafka、zookeeper、hadoop、spark、scala、hbase数据库组件,根据学习目的选择启动方式,并构建大数据学习平台。
更进一步的,步骤(1)所述初始化主机网络环境通过docker的bridge桥接模式,将模拟虚拟网卡桥接到物理网卡上,配置与物理网卡同一网段的网络信息,将docker服务的指定网卡指向新创建的虚拟网卡,新创建的容器设置为客户端直接访问对象。
步骤(2)基于ubuntu基础镜像,包括通过dockerfile文件编译镜像时增加sshd服务,生成安装sshd服务的镜像。
所述大数据学习平台安装有sshd服务的ubuntu镜像,通过dockerfile文件编译并增加java、scala、mysql基础组件包,zookeeper、hadoop、spark、scala和hbase数据库组件,增加组件的安装目录默认用户的.bashrc文件中,增加java、scala和zookeeper等组件的二进制文件路径到path环境变量中,形成大数据搭建的基础环境。
步骤(3)包括在容器入口默认启动守护进程,守护进程定义需要监控的进程信息,通过守护进程所具有的进程看门狗,实现进程异常退出自动拉起。
步骤(4)具体包括在容器启动脚本执行时,传入环境变量,所述环境变量在容器启动后成为容器的全局变量,容器内部初始化时,根据变量值批量修改hadoop的配置文件,包括core-site.xml、hdfs-site.xml、yarn-site.xml文件,批量修改hbase的配置文件为hbase-site.xml文件,批量修改hive的配置文件为hive-site.xml,所述配置文件在编译镜像时将关键的配置项进行关键词标记,根据容器的名字替换关键词标记进行批量修改并实现可配置的功能。
更进一步的,所述大数据学习平台的组件的一键启动功能包括docker的一键启动以及docker容器中hadoop、hive、hbase大数据组件的一键启动;
所述的docker的一键启动根据用户的用户id创建出id-master、id-slave1、id-slave2和id-mysql四个容器,id-slave1、id-slave2两个容器根据虚拟网卡的网段自动分配两个ip地址,id-master、id-slave1、id-slave2通过link方式连接到id-mysql容器上;
所述大数据组件的一键启动运行在id-master容器中,容器启动时默认执行入口脚本,所述入口脚本中包含了初始化环境变量,批量替换配置文件关键词、按照顺序依次启动zookeeper、hadoop、hive和hbase大数据组件的进程,容器启动后大数据环境自动搭建。
有益效果:与现有技术相比,本发明所提供的一种基于docker的大数据学习平台快速搭建方法,基于docker实现依赖环境、大数据组件的容器化,方便移植,构建独立的大数据学习平台,降低大数据初学者的学习成本。
附图说明
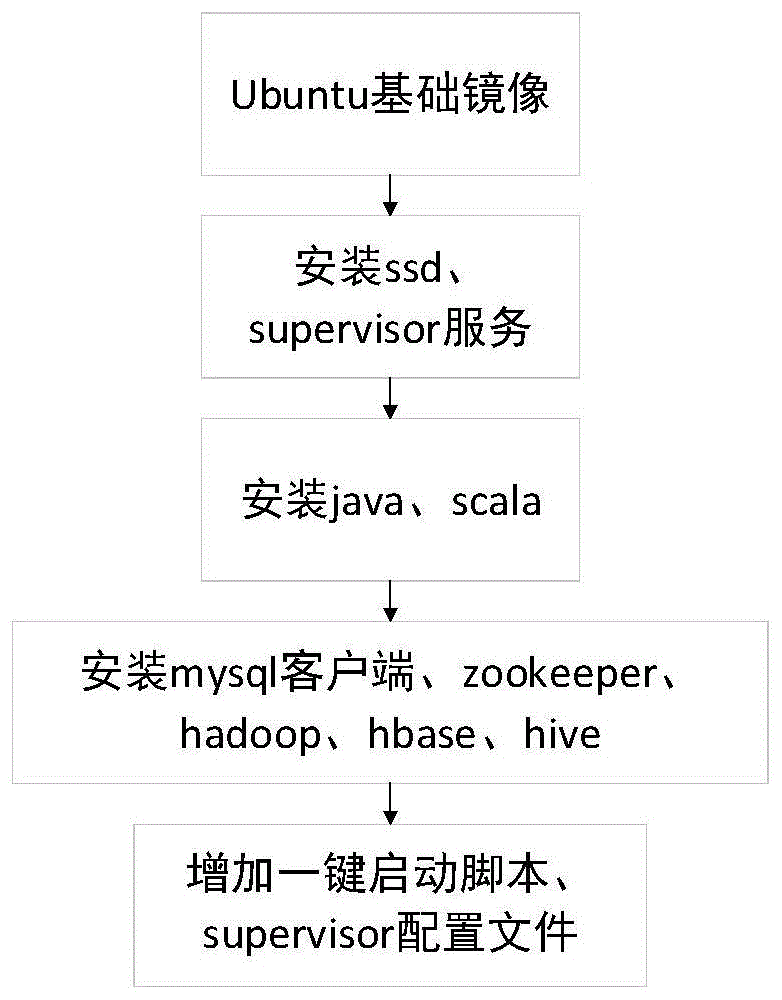
图1为本发明中bigdata镜像对应dockerfile的编写逻辑图;
图2为本发明中mysql镜像对应dockerfile的编写逻辑图;
图3为本发明所述大数据学习平台容器分布图;
图4为本发明所述大数据学习环境一键创建的流程。
具体实施方式
为了详细的说明本发明所公开的技术方案,下面结合说明书附图和具体实施例做进一步的阐述。
本发明提供的是一种基于docker的大数据学习平台搭建方法,该方法主要的实施步骤如下:
步骤1:编写大数据基础镜像bigdata和数据库基础镜像mysql的dockerfile并编译生成镜像。
bigdata镜像基于开源的ubuntu基础镜像,利用dockerfile的语法规则创建大数据学习平台的运行环境,图1所示的是bigdata镜像对应dockerfile的编写逻辑图。集成zookeeper、hadoop、hbase、hive和kafka等大数据组件,编译构成bigdata大数据基础镜像。大数据学习平台的master、slave1和slave2容器都是基于该镜像创建而成。
mysql基础镜像基于开源的ubuntu基础镜像,图2所示的是mysql镜像对应dockerfile的编写逻辑图。使用rpm包方式安装mysql,编译构成mysql基础镜像。mysql容器启动后会根据环境变量自动初始化mysql容器,创建mysql用户,给mysql用户赋权,容器启动即服务。
步骤2:根据bigdata镜像和mysql镜像一键启动容器.
如图3所示,bigdata镜像生成master容器、slave1容器和slave2容器三个大数据容器用户构建大数据环境。大数据环境中zookeeper启动standalone模式,只启动在master容器上;hadoop启动单master模式,master容器上启动namenode、resourcemanager进程,slave1容器和slave2容器启动datanode、nodemanager进程,形成hdfs集群和yarn集群;hbase集群启动一个hmaster和两个regionserver进程,hmaster运行在master容器上,regionserver进程分别运行在slave1和slave2容器上;hive只运行在master进程上。mysql镜像生成mysql容器用于存储hive元数据
步骤3:根据大数据组件一键启动脚本快速构建大数据学习环境
图4所示的是大数据学习环境一键创建的流程。一键创建会创建hadoop的元数据目录、数据目录,启动mysql容器、master容器、slave1容器和slave2容器。mysql容器是大数据学习平台的数据库容器,master容器、slave1容器和slave2容器组成了大数据学习平台的多节点环境,在容器内启动hadoop环境会一键拉起3个容器内的所有相关进程,实现环境的一键搭建,也可以根据要求自动修改配置文件,实现大数据环境搭建的实践学习。
本发明所述方法还包括大数据学习平台快速搭建的配置文本化、安装一键化、启动脚本化等优秀特性,针对学习平台搭建过程进行个性化设计,提升平台用户体验。
大数据学习平台包括构建大数据学习平台相关docker镜像。基于开源的ubuntu系统,自定义大数据学习平台的基础镜像,保留图形界面、远程访问等基础功能,发挥ubuntu系统可视化优势。自定义dockerfile编译文件,自动构建大数据平台依赖的环境变量,编译打包大数据组件至镜像中,构建定制化、可视化、可操作的大数据学习平台。
大数据学习平台通过配置文件定义docker的安装目录、容器的数据目录和容器初始环境变量的等信息,通过对配置文件的预先配置,可以实现容器环境变量的自定义。
大数据学习平台提供大数据环境的一键启动功能。一键启动脚本批量修改配置文件,按照顺序启动zookeeper、hadoop、hbase和hive等大数据组件,实现大数据环境的自动启动。
- 还没有人留言评论。精彩留言会获得点赞!