一种垃圾文本识别方法与流程
【技术领域】
本发明涉及一种垃圾文本识别方法,尤其涉及计算机数据处理技术领域。
背景技术:
随着互联技术的发展,文字内容越来越丰富,伴之而来的是越来越多的垃圾文本。这些垃圾文本中,除了常见的商业广告,还存在一些反动、诈骗等信息。这些信息的传播,不仅影响人们的日常生活,而且危害社会的安全稳定。因此,需要针对这些垃圾文本进行识别,以便对这些垃圾文本进行过滤或者删除。
技术实现要素:
本发明提出了一种垃圾文本识别方法,能够应用于邮件、短信及其他互联网文本的垃圾文本识别,为采取措施抑制垃圾文本的蔓延提供帮助,满足实际应用需求。
为实现上述目的,本发明提供一种垃圾文本识别方法,包括以下步骤:
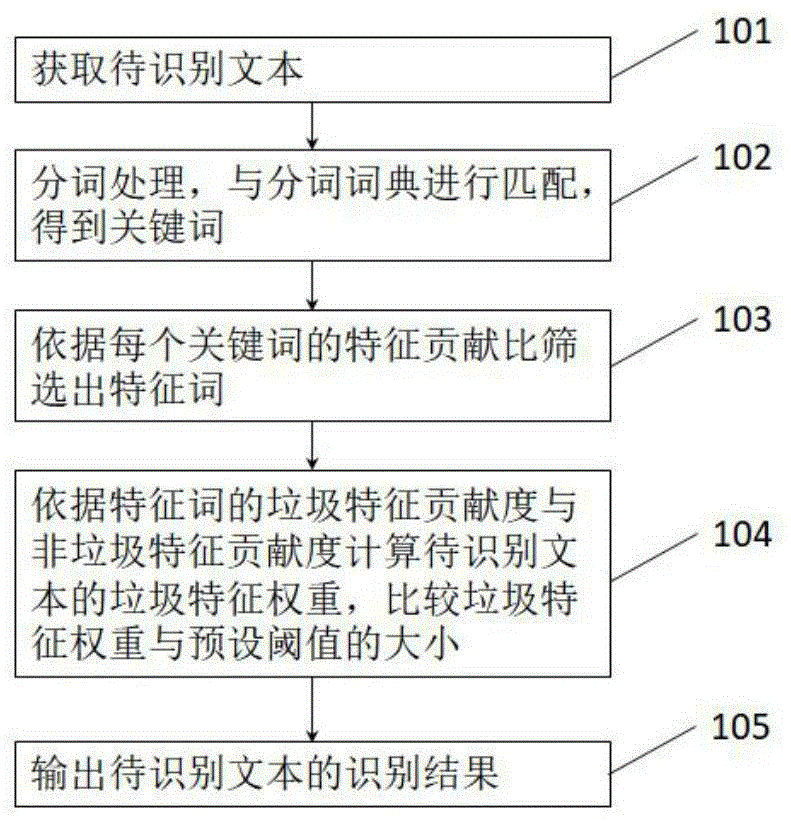
步骤1、将待识别文本进行间隔式滑动窗口分词处理,分词结果与分词词典进行匹配,得到关键词;
步骤2、依据每个关键词的特征贡献比大小,选出待识别文本的特征词;
步骤3、比较待识别文本的特征词特征贡献比与预设阈值的大小;
步骤4、输出待识别文本的识别结果。
作为上述技术方案的改进,步骤2所述特征词的构建方法包括如下步骤:
步骤11、通过两个长度为n的滑动窗口在待识别文本上进行滑动,借助中间的间隔来过滤掉待识别文本中所插入的异常字符;
步骤12、在步骤11基础上,引入一个分词词典。通过与词典进行匹配,获得关键词结果。
作为上述技术方案的改进,上述步骤将样本分为垃圾文本和非垃圾文本;
计算待识别文本的所有关键词的特征贡献比,选取特征贡献比大于预设值的关键词作为用来判别待识别文本是否为垃圾文本的特征词;
计算待识别文本特征词垃圾特征贡献度的权重,当权重大于阈值时判定待识别文本为垃圾文本。
作为上述技术方案的改进,所述垃圾文本样本,存储有敏感词和/或垃圾特征和/或垃圾各式特征。
作为上述技术方案的改进,所述计算待识别文本的每个关键词的特征贡献比具体包括:
对于待识别文本每个关键词,根据公式1计算该特征词的特征贡献比:
式中t为该关键词,r(t)为该关键词的特征贡献比,c(t,cspam)表示关键词t对垃圾样本的贡献度,c(t,cham)表示关键词t对非垃圾样本的贡献度。
作为上述技术方案的改进,所述计算待识别文本的每个关键词的特征贡献度具体包括:
对于待识别文本的每个关键词,根据如下公式2计算该关键词的垃圾特征贡献度:
式中t为该关键词,α(t,cspam)为关键词t词频因子,p(t|cspam)表示含该关键词的文本属于垃圾文本类别的概率,p(t)表示整个样本集中关键词t出现的概率。
根据如下公式3计算该关键词的非垃圾特征贡献度:
式中α(t,cham)为关键词t词频因子,p(t|cham)表示含该关键词的文本属于垃圾文本类别的概率。
作为上述技术方案的改进,所述计算关键词t的词频因子具体包括:
根据如下公式4计算该关键词的词频因子:
式中tf(t,ci)表示类别ci中关键词t出现的次数,n表示类别ci的样本数目,dij表示类别ci中第j个样本,tf(t,dij)表示关键词t在类别ci中的第j个样本出现的次数。
作为上述技术方案的改进,所述计算待识别文本特征词垃圾特征贡献度的权重具体包括:
根据如下公式5计算待识别文本的垃圾特征权重:
式中wgt表示待识别文本的垃圾特征权重,m表示待识别文本中包含的特征词的数目。
本发明的有益效果:
本发明提供了一种垃圾文本识别方法,该方法和系统应用于计算机文本数据,具体为获取待识别文本数据;对待识别文本进行分词处理;对待识别文本的分词与分词词典进行匹配得到关键词;对关键词进行筛选获得待识别文本的特征词;根据特征词的垃圾特征贡献度与非垃圾特征贡献度计算得到待识别文本的垃圾特征权重;将待识别文本的垃圾特征权重与预设阈值进行比较能够确定待识别文本是否为垃圾文本,并为进一步针对判定为垃圾文本的计算机文本数据的处理提供依据,防止垃圾文本对人们日常生活带来负面影响。
本发明的特征及优点将通过实施例结合附图进行详细说明。
【附图说明】
图1为本发明提供的一种垃圾文本识别方法实施例的步骤流程图;
图2为本发明提供的一种垃圾样本文本与非垃圾样本文本的分类流程图;
图3为本发明提供的一种待识别文本的分词流程图;
图4为本发明提供的一种待识别文本的分词模型图;
图5为本发明提供的一种垃圾文本识别方法实施例的结构框图。
【具体实施方式】
参阅图1所示:图1是本发明所述一种垃圾文本识别方法实施例的步骤流程图。虽然本申请提供了如下述实施例或附图所示的方法操作步骤,但基于常规或者无需创造性的劳动在所述方法中可以包括更多或者部分合并后更少的操作步骤,在逻辑性上不存在必要因果关系的步骤中,这些步骤的执行顺序不限于本申请实施例或附图所示的执行顺序。
步骤202,建立垃圾样本文本和非垃圾样本文本,如图2所示;
本步骤中,垃圾样本文本和非垃圾样本文本由编辑人员从样本文本中进行人工筛选,然后手动标注得到。
在构建出垃圾样本文本和非垃圾样本文本后,可在识别阶段根据所构建出的垃圾文本识别方法几系统,对待识别文本进行垃圾识别,具体流程如图3所示,具体步骤包括:
步骤302,对待测样本进行间隔式滑动窗口分词方法,
具体地,不同于传统的滑动窗口,它采用多个滑动窗口联动的方式来采集文本中的信息数据。该滑动窗口模型如图4所示。
从图4中可看到,该模型中存在两个滑动窗口。假定前一个滑动窗口为滑动窗口a,后一个滑动窗口为滑动窗口b,两个滑动窗口的长度都为n,且两个滑动窗口中间存在间隔(在图4中滑动窗口间的间隔为4个字符),在对文本数据进行信息采集时,滑动窗口a与滑动窗口b同时向右移动,将两个滑动窗口中的数据拼接在一起,作为间隔式滑动窗口模型所采集到的特征。
基于间隔式滑动窗口的分词方法,就是通过;两个一定长度的滑动窗口在待识别文本上进行滑动,借助中间的间隔来过滤掉垃圾文本制造者在垃圾文本中所插入的异常字符,从而提高分词的效率。
在对待识别文本进行间隔式滑动窗口分词的过程中,由于待识别文本中可能含有*&%¥#等异常字符,并且异常字符具有不确定性,因此通常需要对一个待识别文本的内容进行反复地滑动来采集文本信息,单次进行信息采集的流程如图3所示。
步骤402,分词结果与分词词典字典匹配获得关键词。
具体地,对于待识别文本进行分词后得到的每个分词结果,可以利用现有技术中的搜索树等数据结构或者字符串匹配算法来对待识别文本的分词结果与分词词典进行匹配,从而匹配出待识别文本中的所有关键词。
步骤403,依据关键词与构建好的垃圾文本样本、非垃圾文本样本,计算出各关键词的关键词特征贡献比,筛选出特征贡献比大于预设阈值的关键词作为特征词,具体步骤包括:
根据如下公式计算该关键词的词频因子:
式中tf(t,ci)表示类别ci中关键词t出现的次数,n表示类别ci的样本数目,dij表示类别ci中第j个样本,tf(t,dij)表示关键词t在类别ci中的第j个样本出现的次数。
对于待识别文本的每个关键词,根据如下公式计算该关键词的垃圾特征贡献度:
式中t为该关键词,α(t,cspam)为关键词t词频因子,p(t|cspam)表示含该关键词的文本属于垃圾文本类别的概率,p(t)表示整个样本集中关键词t出现的概率。
步骤404,根据如下公式计算该关键词的非垃圾特征贡献度:
式中α(t,cham)为关键词t词频因子,p(t|cham)表示含该关键词的文本属于垃圾文本类别的概率。
对于待识别文本每个关键词,根据如下公式计算该特征词的特征贡献比:
式中t为该关键词,r(t)为该关键词的特征贡献比,c(t,cspam)表示关键词t对垃圾样本的贡献度,c(t,cham)表示关键词t对非垃圾样本的贡献度。
步骤405,若关键词t的特征贡献比r(t)大于预设阈值,则将关键词t作为待识别文本的特征词;若关键词t的特征贡献比r(t)小于预设阈值,则将关键词t不作为待识别文本的特征词。
步骤406,依据待识别文本特征词的垃圾贡献度与非垃圾贡献度,计算待识别文本的垃圾特征权重,依据待识别文本的垃圾特征权重与预设阈值的比较结果判断待识别文本是否为垃圾文本,具体如下:
根据如下公式计算待识别文本的垃圾特征权重:
式中wgt表示待识别文本的垃圾特征权重,m表示待识别文本中包含的特征词的数目。
若待识别文本的垃圾特征权重wgt大于预设阈值,则判定待识别文本属于垃圾文本;若待识别文本的垃圾特征权重wgt小于预设阈值,则判定待识别文本属于非垃圾文本。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!