一种基于自回归移动平均和支持向量机的农产品需求量预测方法与流程
本发明属于时间序列预测分析方法领域,尤其涉及一种基于自回归移动平均和支持向量机的农产品需求量预测方法。
背景技术:
近年来,我国农产品需求量受种植面积、生产成本、市场流通、自然气候以及突发事件等因素的影响,短期波动十分频繁,导致农产品需求量呈现出波动大﹑非平稳﹑非线性等特征。因此,关注和研究国内农产品需求量走势,对其波动状况进行分析和预测,有利于农产品市场流通信息的监测,对于稳定国内农产品需求的超常波动都具有重要的现实意义。
自回归移动平均模型(autoregressiveintegratedmovingaveragemodel,简称arima)是时间序列中最典型最常用的一种模型,短期预测精准度较高。早期常被应用于农产品价格预测等,但自回归移动平均模型只适用于解决符合线性的时间序列问题,当需要处理的问题不是线性关系时,偏差较大。在农产品需求量预测中,由于受时间和空间多因素影响,导致数据集会呈现出非平稳性、非线性噪声等复杂的非线性特征时使用单一预测方法可能会出现较大误差。而支持向量机(简称svm)是一种寻求最大分类间隔的机器学习方法,根据结构风险最小原则,在解决非线性、高纬度和局部极小点等实际问题上具有很好的效果。
(1)arima算法
arima算法拟合的是差分平稳序列,实际上就是差分运算和arma模型相结合,对于具有非季节性的时间序列,首先需要做差分,采用arima(p,d,q)模型,其中ar为自回归,p为自回归阶数;ma为移动平均,q为移动平均项数;d为差分阶数。它通过适当的d阶差分运算使序列平稳。
自回归模型ar,是指当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。自回归模型需要先确定阶数p,表示用几期的历史值来预测当前值。p阶自回归模型可以表示为:
其中,yt是当前值,μ是常数项,p是阶数,r是自相关系数,∈是误差。
移动平均模型ma,关注的自回归模型中的误差项的累加,q阶自回归过程的公式定义如下:
而自回归移动平均模型arma(p,q)是由自回归模型ar和移动平均模型ma模型相结合得到的,计算公式如下:
(2)svm算法
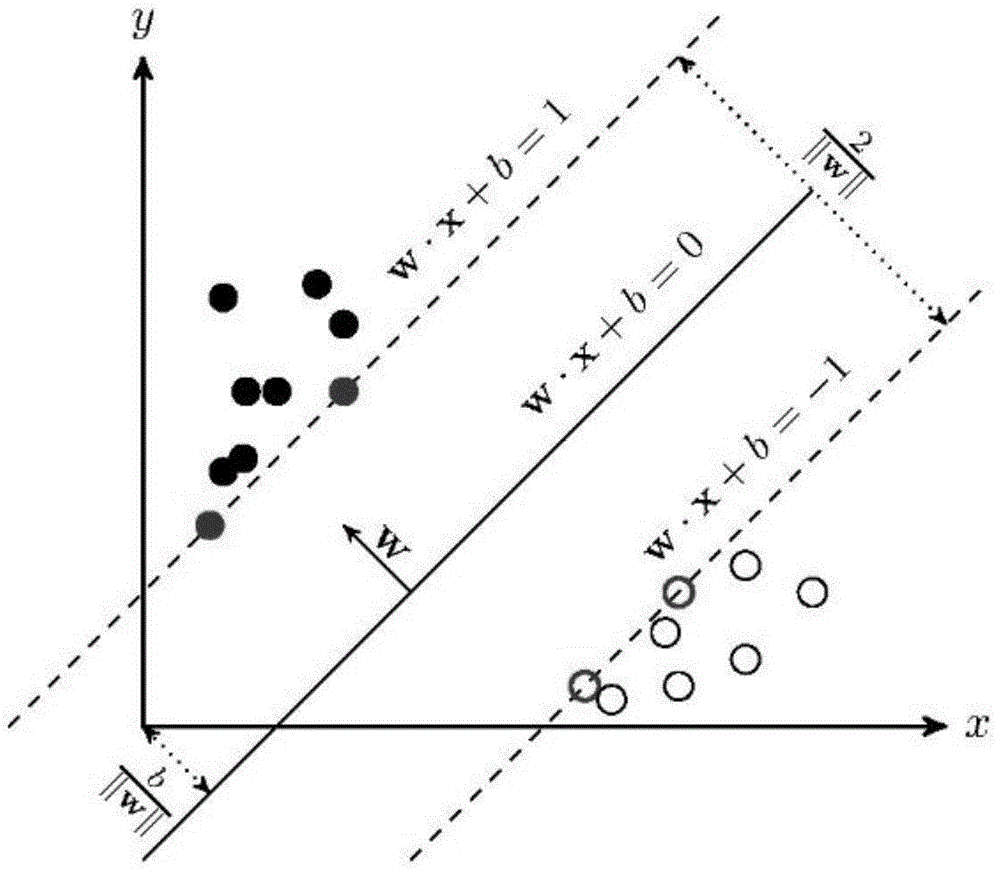
svm算法基本思想是基于训练集d在样本空间能够正确划分训练集并找到一个几何间隔最大的分离超平面,假设训练集d={(x1,y1),(x2,y2),...(xm,ym)},yi∈{-1,+1},超平面wtx+b=0,其中w为法向量,b为位移项。定义超平面关于样本点(xi,yi)的几何间隔为
距离超平面最近的几个训练样本,被称为“支持向量”,它们到超平面的距离之和为
根据以上定义,svm模型的求解最大分割超平面问题可以表示为以下:
s.t.yi(wtxi+b)≥1,i=1,2,...,m
这是一个含有不等式约束的凸二次规划问题,可以对其使用拉格朗日乘子法得到其对偶问题,如下:
αi≥0,i=1,2,...m·
其中αi是拉格朗日乘子。
上述原理是在样本集呈线性关系的情况下的解决方案,对于非线性分类问题,可通过非线性变换将它转化为某个维的特征空间中的线性分类问题。在线性支持向量机学习的对偶问题里,都只涉及xi和xj之间的内积,这里就提出了核函数,使用核函数替换对偶问题里的内积。核函数,指通过一个非线性转换后的两个实例间的内积。具体地,
k(xi,xj)=<φ(xi),φ(xj)>=φ(xi)tφ(xj)
则上述对偶问题可重写为:
αi≥0,i=1,2,...m·
技术实现要素:
本发明是一种基于自回归移动平均和支持向量机的农产品需求量预测方法。数据集采用了某市农产品市场的月度需求量样本数据,通过构建自回归移动平均模型和支持向量机模型,将二者的预测结果进行整合作为最终的预测结果。
为实现上述目的,本发明将采用以下技术方案:由于自回归移动平均模型要求序列是线性的,也就是平稳序列。因此,首先是要检验农产品需求量序列的平稳性,若序列非平稳化,需要将序列转化为平稳序列。
步骤1农产品需求量序列平稳化
1)农产品需求量序列是否平稳,观察农产品需求量序列是否有明显波动趋势,通过自相关图和偏自相关图是否收敛来检验序列的平稳性。2)若自相关图和偏自相关图不收敛,表明农产品需求量序列是非平稳的,需要对序列做自然对数差分,若序列波动趋势基本消除,但部分样本仍有较大差别,表明序列存在季节性,需要对序列做季节差分,直至序列均值与0无显著差异,说明序列已平稳化。
步骤2自回归移动平均建模
由于农产品需求量序列经过对数差分及季节差分,通过观察序列的偏自相关图,从低阶到高阶逐步识别模型的类型和阶数,确定arima模型的参数arima(p,d,q),其中p为自回归阶数;q为移动平均项数;d为差分阶数。
步骤3支持向量机建模
使用原农产品需求量序列减去步骤2的预测序列得到残差序列,对残差序列使用支持向量机模型进行预测,即用svm模型来逼近非线性函数,其中核函数和参数采用交叉验证方法进行优化,使得最优参数下训练得到的模型对残差序列进行预测。
步骤4整合预测结果
将步骤2的预测结果和步骤3的预测结果整合相加,得到自回归移动平均和支持向量机的预测结果。
在本发明对农产品需求量进行预测时,由于农产品在市场的需求量上具有明显的波动性和季节性差异,以arima模型预测农产品需求量变动的线性趋势,svm模型预测农产品需求量变动的非线性规律,有效的弥补了自回归移动平均算法对非线性序列的局限性,同时又发挥了自回归移动平均算法特有的差分运算和支持向量机模拟非线性、自适应自学习的优点。与使用单独的自回归移动平均和支持向量机相比较,基于自回归移动平均和支持向量机的农产品需求量预测方法可以提高预测的精确度,准确把握农产品需求量变动趋势,比单个模型的预测结果更合理、更可靠,可以作为农产品需求量时间序列预测的有效工具。
附图说明
图1是本发明支持向量与间隔结构图。
图2是本发明自回归移动平均和支持向量机预测的整体流程图。
图3是本发明序列平稳化的流程图。
具体实施方式
结合说明书附图和算法公式,基于自回归移动平均和支持向量机的农产品需求量预测方法主要分为以下步骤:
1.农产品需求量序列平稳性检验
首先对农产品需求量序列中需求量指标进行指数化,可以看到序列随时间的变化出现了较大偏差,通过其自相关图和偏自相关图发现序列是非平稳的,其中自相关图通过计算自相关函数(acf)来获得,而偏自相关图通过计算偏自相关函数(pacf)来获得。
2.序列平稳化
为了消除趋势同时减小序列的波动,对序列做一阶自然对数逐期差分处理,通过观察其自相关-偏自相关分析图,序列波动趋势基本消除,但部分样本的自相关系数和偏自相关系数不为0,这表明序列存在季节性,需要对序列做季节差分,对序列进行0均值检验,直至检验结果显示序列均值与0无显著差异,可进行步骤3。
3.自回归移动平均模型建模
由于农产品需求量序列经过自然对数逐期差分及季节差分,通过观察序列的偏自相关图,从低阶到高阶逐步试探法去识别模型的类型和阶数,确定了arima模型的参数,通过上述arima算法公式计算得到了arima预测结果。
4.支持向量机建模
使用原农产品需求量序列减去步骤3的预测序列得到残差序列,对残差序列使用支持向量机模型进行预测,即用svm模型的非线性解决方案来逼近非线性函数,其中的核函数选择高斯核函数,将核函数和参数采用交叉验证的方法进行优化,使得最优参数下训练得到的模型对残差序列进行预测。
5.整合预测结果
最后将步骤3的预测结果和步骤4的预测结果整合相加,得到的就是基于自回归移动平均和支持向量机的农产品需求量预测结果。
- 还没有人留言评论。精彩留言会获得点赞!