一种基于spark的大数据处理方法与流程
本发明属于计算机技术领域,尤其涉及一种基于spark的大数据处理方法。
背景技术:
hadoop是一个由apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。hdfs有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。hdfs放宽了(relax)posix的要求,可以以流的形式访问(streamingaccess)文件系统中的数据。hadoop的框架最核心的设计就是:hdfs和mapreduce。hdfs为海量的数据提供了存储,而mapreduce则为海量的数据提供了计算。
但现有技术中,基于hadoop中mapreduce的多线程数据处理方法,不能应用在企业对账中,因为每个线程在执行完成时的时间不统一,导致各个线程的执行结果是分步提交的,这就产生了时差。举例来说,在企业对账中,现金日记账期末余额应与总分类账的库存现金期末余额核对相符,但若一个线程对现金日记账期末余额计算的执行结果提交时间和另一个线程对总分类账的库存现金期末余额计算的执行结果,两者提交时间不同,就导致此次执行结果无法进行比对,进而不能输出对账结果。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于spark的大数据处理方法,其利用将数据处理结果需要进行比对的两方数据同时缓存至中间库,将第一方数据的处理结果和第二方数据的处理结果同时输出,以解决在企业对账中,因对账的两方数据不能同时处理完成,导致的不能输出对账结果的问题。
为解决上述技术问题,本发明采用的技术方案是:一种基于spark的大数据处理方法,包括:
将数据处理结果需要进行比对的两方数据同时缓存至中间库,所述两方数据包括第一方数据和第二方数据;
根据第一方数据的数量分配多个处理第一方数据的第一副线程,根据第二方数据的数量分配多个处理第二方数据的第二副线程;
多个第一副线程均完成数据处理时,触发:第一主线程对所有副线程的数据处理结果进行收集,并生成第一方数据的处理结果;
多个第二副线程均完成数据处理时,触发:第二主线程对所有副线程的数据处理结果进行收集,并生成第二方数据的处理结果;
将第一方数据的处理结果和第二方数据的处理结果同时输出。
上述一种基于spark的大数据处理方法,根据第一方数据的数量分配处理第一方数据的副线程时,包括:
获取第一方数据的数量λ1;
计算所需副线程数量n1,
为第一方数据的处理分配n1条副线程。
上述一种基于spark的大数据处理方法,还包括:第一主线程对所有第一副线程的数据处理结果进行收集完成时,对占用的资源进行释放。
上述一种基于spark的大数据处理方法,还包括:根据预设比对规则,对第一方数据的处理结果和第二方数据的处理结果进行比对,生成比对结果。
上述一种基于spark的大数据处理方法,所述中间库为redis或者mysql。
本发明与现有技术相比具有以下优点:
1、本发明通过将数据处理结果需要进行比对的两方数据同时缓存至中间库,在方便数据处理的同时,保证提取的两方数据的时间节点相同。
2、本发明通过将数据处理以多个副线程执行,多个副线程的数据处理结果以一个主线程进行收集,合并出总的数据处理结果,在提升数据处理速度的同时,也保证了总的数据处理结果的有效完成。
3、本发明其利用将数据处理结果需要进行比对的两方数据同时缓存至中间库,将第一方数据的处理结果和第二方数据的处理结果同时输出,以解决在企业对账中,因对账的两方数据不能同时处理完成,导致的不能输出对账结果的问题。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
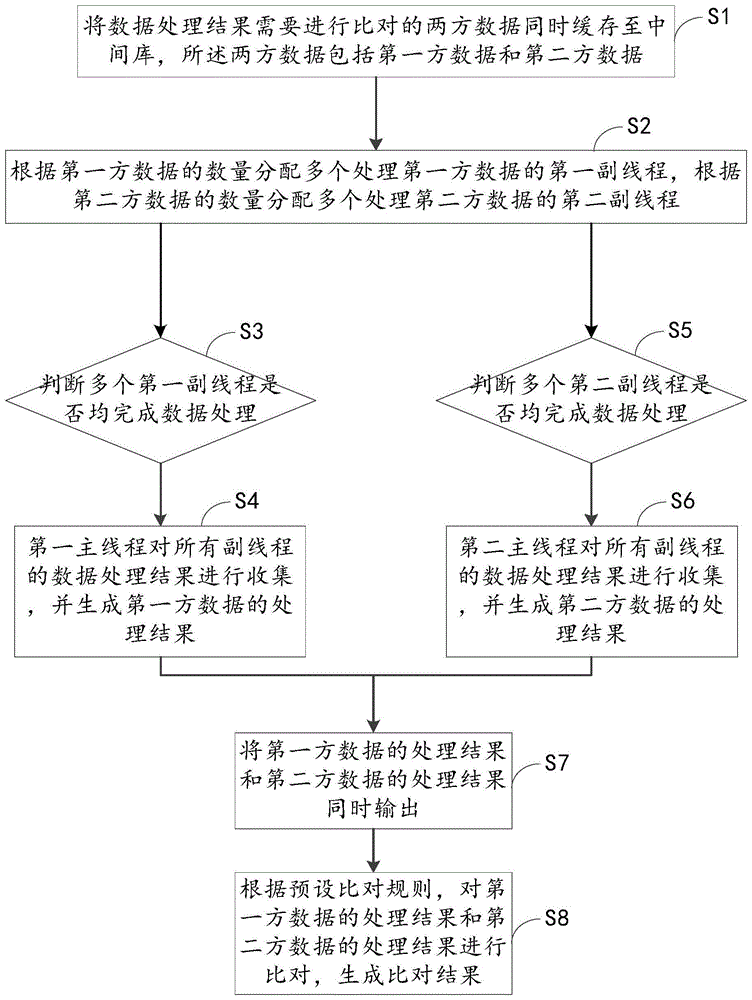
图1为本发明的方法步骤流程图。
具体实施方式
如图1所示,一种基于spark的大数据处理方法,包括:
s1、将数据处理结果需要进行比对的两方数据同时缓存至中间库,所述两方数据包括第一方数据和第二方数据;
将两方数据同时缓存至中间库,目的在于方便数据处理的同时,能够保证提取的两方数据的时间节点相同。
s2、根据第一方数据的数量分配多个处理第一方数据的第一副线程,根据第二方数据的数量分配多个处理第二方数据的第二副线程;
对于第一方数据的处理任务进行切分,切分出多个子任务,每个子任务由一个第一副线程进行执行,多个第一副线程对整个第一方数据的处理任务进行处理。
对于第二方数据的处理任务进行切分,切分出多个子任务,每个子任务由一个第二副线程进行执行,多个第二副线程对整个第二方数据的处理任务进行处理。
s3、判断多个第一副线程是否均完成数据处理,若是,进入步骤s4;
s4、第一主线程对所有副线程的数据处理结果进行收集,并生成第一方数据的处理结果;
s5、判断多个第二副线程是否均完成数据处理,若是,进入步骤s6;
s6、第二主线程对所有副线程的数据处理结果进行收集,并生成第二方数据的处理结果;
现有技术中的多线程处理没有数据处理结果的合并,本发明中,通过第一主线程对多个第一副线程的数据处理结果进行收集,合并出第一方数据的处理结果。通过第二主线程对多个第二副线程的数据处理结果进行收集,合并出第二方数据的处理结果。在提升数据处理速度的同时,也保证了总的数据处理结果的有效完成。
s7、将第一方数据的处理结果和第二方数据的处理结果同时输出。
本发明其利用将数据处理结果需要进行比对的两方数据同时缓存至中间库,将第一方数据的处理结果和第二方数据的处理结果同时输出,以解决在企业对账中,因对账的两方数据不能同时处理完成,导致的不能输出对账结果的问题。
本实施例中,根据第一方数据的数量分配处理第一方数据的副线程时,包括:
获取第一方数据的数量λ1;
计算所需副线程数量n1,
为第一方数据的处理分配n1条副线程。
本实施例中,根据第二方数据的数量分配处理第二方数据的副线程时,包括:
获取第二方数据的数量λ2;
计算所需副线程数量n2,
为第二方数据的处理分配n2条副线程。
本实施例中,s4还包括:第一主线程对所有第一副线程的数据处理结果进行收集完成时,对占用的资源进行释放。
本实施例中,s6还包括:第二主线程对所有第二副线程的数据处理结果进行收集完成时,对占用的资源进行释放。
本实施例中,还包括:s8、根据预设比对规则,对第一方数据的处理结果和第二方数据的处理结果进行比对,生成比对结果。
本实施例中,所述中间库为redis或者mysql。
以上所述,仅是本发明的较佳实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!