一种医疗单据识别方法与流程
本发明涉及计算机视觉、网络科学、深度神经网络,特别是涉及一种医疗单据识别方法。
背景技术:
自东汉起至现代,人们都是通过纸张来记录信息,比如银行票据、商业合同、财务报表、公民个人档案等等都会被记录在纸质文档上。而在医药卫生领域,患者在就医过程中也会产生大量的纸质单据。这些纸质单据都将作为重要凭证日后具有多种用途。
由于数据积累的需要和监管要求,医院或审核机关对于原始单据的信息采集往往要求非常旺盛,但是受限于成本压力,目前大部分仅仅通过bpo(businesspro-cessoutsourcing,商务流程外包)采集了发票信息,其他票据信息往往转变为沉默数据。而纯粹依靠手工处理这些单据存在很多的问题:耗时耗力、效率极低、不便于日后统计与检索等等。在这种情况下,迫切需要一种能够将医疗单据进行快速识别的方法。
而自动识别医疗单据存在着诸多限制:单据中普遍存在印章,这些印章的存在将会给文字识别带来困扰,因此需要将印章去除;单据的扫描图像普遍存在小角度的倾斜,这将严重影响文字块的分割,因此需要将存在倾斜的图像进行校正。
综上,传统的医疗单据识别中存在的很多亟待解决的问题,包括医疗单据本身由于打印精度限制等因素,单据本身往往容易出现错位、错行、表面污渍等限制,尚无有效的解决办法。
技术实现要素:
有鉴于此,本发明提出一种医疗单据识别方法,采用了以卷积神经网络和循环神经网络为代表的深度学习算法,主要针对医疗单据,利用医疗文字的相关性从医疗单据的文本等原始信息中提取出高层抽象属性。
本发明解决其技术问题所采用的技术方案如下:
一种医疗单据识别方法,包括以下步骤:
步骤1:收集电子版医疗单据,构建数据集,收集医疗专业词汇,构建词库;
步骤2:对数据集中单据图像进行预处理;
步骤3:构建对医疗单据进行增强去噪的图像增强模型;
步骤4:构建基于语义分割的表格区域检测模型;
步骤5:构建基于匹配校正的文字识别模型;
步骤6:将识别结果进行结构化处理。
进一步,所述步骤1中,收集电子版医疗单据,所述行为数据不包括质量有明显问题部分,所述质量有明显问题部分包括缺失百分之四十以上内容或严重过曝。
再进一步,所述步骤2中,对数据集中单据进行预处理,包括以下步骤:
2.1)对于单据中含有印章部分,通过常用手段去除印章;
2.2)对经上一步处理后的医疗单据图像利用图片所在的空间和霍夫空间之间的变换,将图片所在的直角坐标系中具有形状的曲线或直线映射到霍夫空间的一个点上形成峰值,寻找峰值对应的的角度进行图像倾斜矫正。
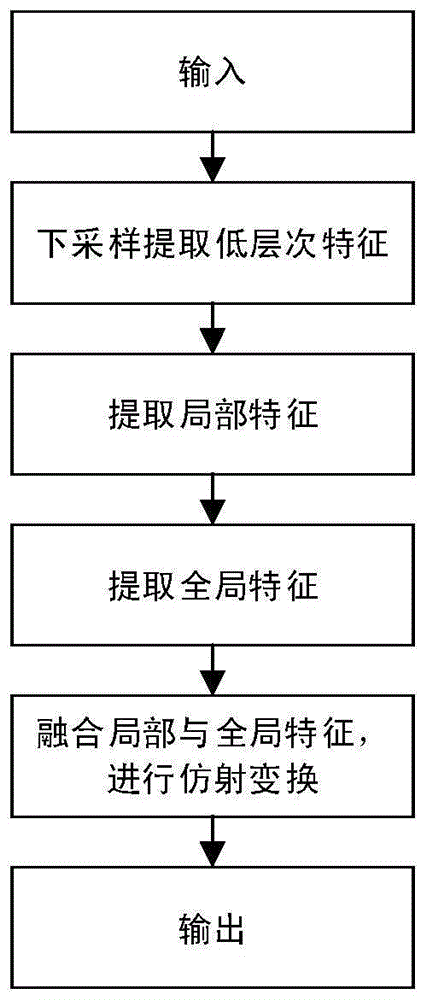
所述步骤3中,构建对医疗单据进行增强去噪的图像增强模型,包括以下步骤:
3.1)把输入的图片经过一系列卷积层进行下采样,提取较低层次的特征,提取特征的公式如下:
其中i=1,2……n为每个卷积层的索引,c,c′为卷积层channels通道索引,ωi为卷积核权重矩阵,bi为偏差,σ为激活函数;
3.2)将上一步的提取的特征输入两层的卷积层进一步处理,提取局部特征。
3.3)将由步骤3.1)所提取的特征输入由步长为2的两层卷积层加3个全连接层组成的网络中,提取全局特征;
3.4)通过逐点仿射变换融合局部特征及全局特征。将融合特征进行上采样,进行仿射变换获得最终输出。
所述步骤4中,构建基于语义分割的表格区域检测模型,包括以下步骤:
4.1)首先将图片通过初始生成模型生成表格区域检测图,初始生成模型的损失函数公式如下:
其中h为图像的高,w为图像的宽,k为每个像素点的分类数,yijl为在高为i宽为j的像素点上,第l维是否是正确的分类,若是正确的分类则yijl=1,反之为0,ρijl为在高为i宽为j的像素点上,第l维是否是正确的分类,若是正确的分类则ρijl=1,反之为0;
4.2)然后将该检测结果图送入判别模型d中,作为负类,另外,将正确的表格区域图送入判别模型d中作为正类,判别模型损失函数公式如下:
ld=logd(x)+log(1-d(g(z)))(3)
其中x为真实语义分割后的图片,z为原始图片经基于语义分割的表格区域检测模型g后生成的图片;
4.3)固定判别模型d的的参数,将判别模型的损失函数加入到训练生成模型的损失函数中,公式为:
lg=l+θld(4)
其中θ为预先设定的超参数,在训练生成模型g时,最小化lg;
4.4)重复4.2)和4.3),直至判别模型d和生成模型g的损失函数值都趋于稳定;
4.5)将经过增强后的图像送入模型g,得到模型预测的表格区域。
所述步骤5中,采用构建基于匹配校正的文字识别模型,包括以下步骤:
5.1)提取特征,大小为w*h*c(width*height*channels),用滑动窗口在前一步得到的特征上进一步提取特征,利用这些特征来对多个目标待选区域进行预测,将得到的特征输入到双向的lstm中,输出结果,再将这个结果输入到全连接层,得到密集的目标文本,抑制掉多余的噪声干扰,使用文本线构造方法将上述得到的一个一个的文本段合并成文本行;
5.2)对生成的文本进行应用场景匹配判断单据类型(如出院小结、费用明细单等),对不同种类的单据分别使用进一步的匹配校正;
5.3)将经上一步校正后的文字识别不清晰(有异议)的进行专业词库匹配识别文字,匹配识别公式如下:
其中t∈rn*n,tuv≥0表示生成文本d中的词u转移到所收集专业词库中词v所占的权重,du表示词u本身在d中所拥有的权重,c(u,v)表示词u与词v的距离,求得距离最小值前5个词送入下一步;
5.4)将经上一步所得结果进行上下文匹配识别文字,向量表示计算公式如下:
v(wi)=argmaxjsim(vcontext(wi),w(i,j))(6)
其中wi为输入的单词,vcontext(wi)为上下文向量,w(i,j)为多原型向量表示内容,得到v(wi)后,计算全局相似度,取相似度高的单词为最终匹配结果。
所述步骤6中,将识别结果进行结构化处理包括以下过程:
6.1)将所识别的医疗单据文本进行汇总,统一编码格式,以word格式输出;
6.2)读取word内容,将其按照设定规则处理后以结构化形式存入csv中。
本发明的有益效果为:采用了以卷积神经网络和循环神经网络为代表的深度学习算法,主要针对医疗单据,利用医疗文字的相关性从医疗单据的文本等原始信息中提取出高层抽象属性。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的构建对医疗单据进行增强去噪的图像增强模型流程图;
图2为本发明实施例提供的构建基于语义分割的表格区域检测模型流程图;
图3为本发明实施例提供的构建基于匹配校正的文字识别模型流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为便于对本实施例进行理解,首先对本发明实施例所公开的一种医疗单据识别方法进行详细介绍。
参照图1~图3,一种医疗单据识别方法,具体分为以下六个步骤:
步骤1:收集电子版医疗单据,构建数据集,收集医疗专业词汇,构建词库;
步骤2:对数据集中单据图像进行预处理;
步骤3:构建对医疗单据进行增强去噪的图像增强模型;
步骤4:构建基于语义分割的表格区域检测模型;
步骤5:构建基于匹配校正的文字识别模型;
步骤6:将识别结果进行结构化处理。
进一步,所述步骤1中,收集电子版医疗单据,所述行为数据不包括质量有明显问题部分,如缺失百分之四十以上内容或严重过曝等。
再进一步,所述步骤2中,对数据集中单据进行预处理,包括以下步骤:
2.1)对于单据中含有印章部分,通过常用手段去除印章;
2.2)对经上一步处理后的医疗单据图像利用图片所在的空间和霍夫空间之间的变换,将图片所在的直角坐标系中具有形状的曲线或直线映射到霍夫空间的一个点上形成峰值,寻找峰值对应的的角度进行图像倾斜矫正。
所述步骤3中,构建对医疗单据进行增强去噪的图像增强模型,包括以下步骤:
3.1)把输入的图片经过一系列卷积层进行下采样,提取较低层次的特征,提取特征的公式如下:
其中i=1,2……n为每个卷积层的索引,c,c′为卷积层channels通道索引,ωi为卷积核权重矩阵,bi为偏差,σ为激活函数;
3.2)将上一步的提取的特征输入两层的卷积层进一步处理,提取局部特征;
3.3)将由步骤3.1)所提取的特征输入由步长为2的两层卷积层加3个全连接层组成的网络中,提取全局特征;
3.4)通过逐点仿射变换融合局部特征及全局特征。将融合特征进行上采样,进行仿射变换获得最终输出。
所述步骤4中,构建基于语义分割的表格区域检测模型,包括以下步骤:
4.1)首先将图片通过初始生成模型生成表格区域检测图,初始生成模型的损失函数公式如下:
其中h为图像的高,w为图像的宽,k为每个像素点的分类数,yijl为在高为i宽为j的像素点上,第l维是否是正确的分类,若是正确的分类则yijl=1,反之为0,ρijl为在高为i宽为j的像素点上,第l维是否是正确的分类,若是正确的分类则ρijl=1,反之为0;
4.2)然后将该检测结果图送入判别模型d中,作为负类,另外,将正确的表格区域图送入判别模型d中作为正类,判别模型损失函数公式如下:
ld=logd(x)+log(1-d(g(z)))(3)
其中x为真实语义分割后的图片,z为原始图片经基于语义分割的表格区域检测模型g后生成的图片;
4.3)固定判别模型d的的参数,将判别模型的损失函数加入到训练生成模型的损失函数中,公式为:
lg=l+θld(4)
其中θ为预先设定的超参数,在训练生成模型g时,最小化lg;
4.4)重复4.2)和4.3),直至判别模型d和生成模型g的损失函数值都趋于稳定;
4.5)将经过增强后的图像送入模型g,得到模型预测的表格区域。
所述步骤5中,采用构建基于匹配校正的文字识别模型,包括以下步骤:
5.1)提取特征,大小为w*h*c(width*height*channels),用滑动窗口在前一步得到的特征上进一步提取特征,利用这些特征来对多个目标待选区域进行预测,将得到的特征输入到双向的lstm中,输出结果,再将这个结果输入到全连接层,得到密集的目标文本,抑制掉多余的噪声干扰,使用文本线构造方法将上述得到的一个一个的文本段合并成文本行;
5.2)对生成的文本进行应用场景匹配判断单据类型(如出院小结、费用明细单等),对不同种类的单据分别使用进一步的匹配校正;
5.3)将经上一步校正后的文字识别不清晰(有异议)的进行专业词库匹配识别文字,匹配识别公式如下:
其中t∈rn*n,tuv≥0表示生成文本d中的词u转移到所收集专业词库中词v所占的权重,du表示词u本身在d中所拥有的权重,c(u,v)表示词u与词v的距离。求得距离最小值前5个词送入下一步。
5.4)将经上一步所得结果进行上下文匹配识别文字,向量表示计算公式如下:
v(wi)=argmaxjsim(vcontext(wi),w(i,j))(6)
其中wi为输入的单词,vcontext(wi)为上下文向量,w(i,j)为多原型向量表示内容,得到v(wi)后,计算全局相似度,取相似度高的单词为最终匹配结果。
所述步骤6中,将识别结果进行结构化处理,包括以下过程:
6.1)将所识别的医疗单据文本进行汇总,统一编码格式,以word格式输出;。
6.2)读取word内容,将其按照设定规则处理后以结构化形式存入csv中。
本发明实施例所提供的一种医疗单据识别方法,所述程序代码包括的指令可用于执行前面方法实施例中所述的方法,具体实现可参见方法实施例,在此不再赘述。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!