一种基于投诉工单训练文本计算最佳标注集的方法及系统与流程
本发明涉及计算机网络技术领域,更具体地,涉及一种基于投诉工单训练文本计算最佳标注集的方法及系统
背景技术:
电信行业客户服务投诉管理人员会定期针对全量记录的工单文档进行自然语言理解的文本处理、聚类建模等实现客户投诉分析。算法训练过程中需要进行大量语料中文标注工作,尤其在电信行业服务及产品专有名词标注过程中,需要花费大量专有人员标注,且随着业务及服务产品不断升级和各省分公司个性化专业名词不断更新,为投诉工单文本分析语料标注的工作带来巨大挑战和人员成本。现有训练未标注样本全部手工标注,花费大量的时间成本和经济成本。同时如果训练样本的规模过于庞大,训练时间也会花费较长。
现有训练需要专业人员大量标注训练样本,从而导致存在错误/无用标注。同时训练的时间花费较多。
技术实现要素:
本发明采用一种方法针对电信行业客服投诉工单文本语料进行主动学习提出最小核心有用标注集,减少人工标注的样本数量,大量降低人工标注成本,提高投诉工单文本分析系统的效率。
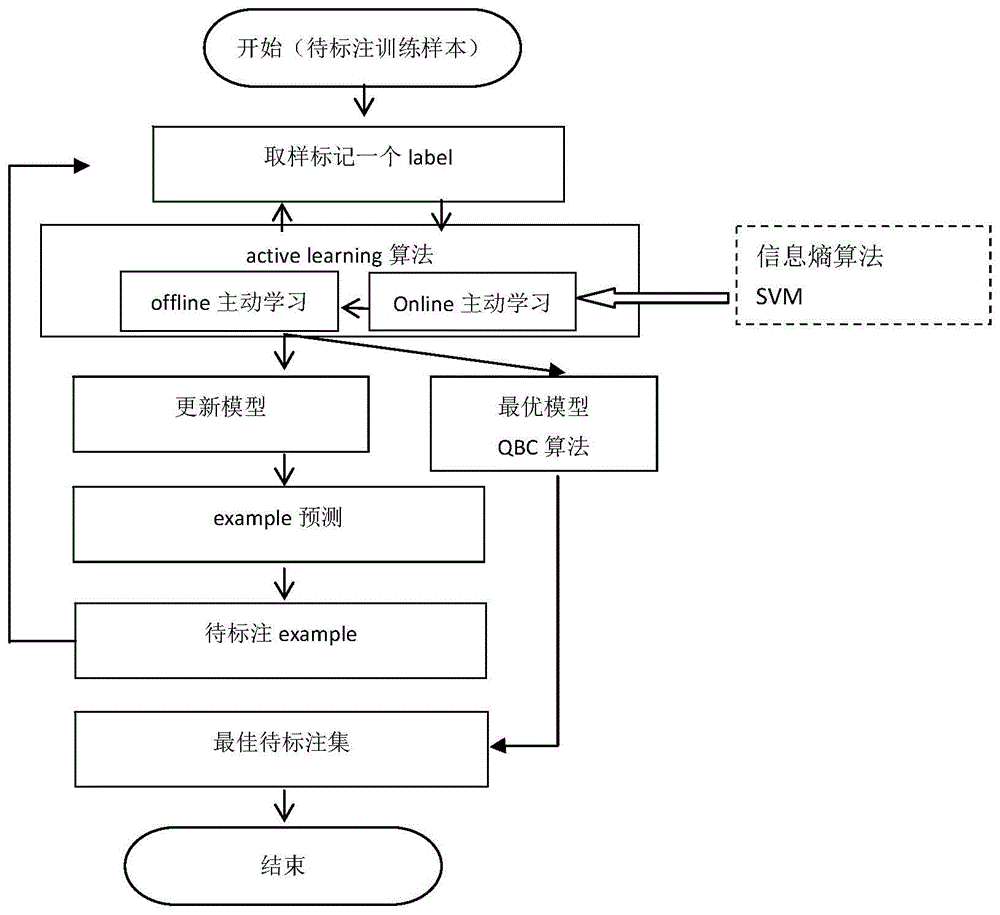
本发明提供一种基于投诉工单训练文本计算最佳标注集的方法,包括:
s1、取样标注一个样本;
s2、主动在线学习实时更新模型;
s3、当标注数据达到一定数据累计阈值时,使用线下深度学习更新模型;
s4、模型更新后对未标注池example做预测;
s5、取确信度最低example作为待标注样例;
s6、重复至步骤s1,对待标注样例进行标注;
s7、重复生成最优模型算法后,计算输出最佳待标注集;
s8、对最佳标注集进行人工标注,从而无需大量标注训练样本。
在本公开的一实施例中,所述步骤s1中,取样标注样本选择涵盖电信行业客服投诉相关专有名词条目,保证电信行业客服投诉工单文本中专有名词的标注。
在本公开的一实施例中,所述步骤s2中,利用信息熵svm算法实时更新模型。
在本公开的一实施例中,所述步骤s3中,所述数据累计阈值为100-200条。
在本公开的一实施例中,所述步骤s3中,使用线下offline的qbc算法深度学习更新模型。
本发明还提供一种基于投诉工单训练文本计算最佳标注集的系统,包括:
取样标注模块,用于取样标注一个样本;
线上主动学习模块,用于主动在线学习实时更新模型;
线下主动学习模块,用于当标注数据达到一定数据累计阈值时,使用线下深度学习更新模型;
example预测模块,用于模型更新后对未标注池example做预测;
待标注样例选取模块,用于取确信度最低example作为待标注样例;
迭代模块,用于对待标注样例进行重复标注;
最优模型算法模块,用于重复生成最优模型算法后,计算输出最佳待标注集;
最佳待标注集模块,用于对最佳标注集进行人工标注,从而无需大量标注训练样本。
在本公开的一实施例中,所述取样标注模块中,取样标注样本选择涵盖电信行业客服投诉相关专有名词条目,保证电信行业客服投诉工单文本中专有名词的标注。
在本公开的一实施例中,所述线上主动学习模块中,利用信息熵svm算法实时更新模型。
在本公开的一实施例中,所述线下主动学习模块中,所述数据累计阈值为100-200条。
在本公开的一实施例中,所述线下主动学习模块中,使用线下offline的qbc算法深度学习更新模型。
本发明提供的基于电信行业客服投诉工单训练文本计算最佳标注集的方法及系统,具有的技术效果为,本发明采用一种方法针对电信行业客服投诉工单文本分类模型训练样本已标注过程中进行主动学习,输出未标注样本池最小待标注样本,从而实现核心有效小样本标注,降低标注时长,减少训练时间及经济成本。
本发明实施例的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明实施例的技术方案做进一步的详细描述。
附图说明
图1是基于电信行业客服投诉工单训练文本计算最佳标注集的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明的实现思路为选取待标注训练样本后,1、取样标注一个样本;2、主动在线学习实时更新模型;3、当标注数据达到一定数据累计阈值时,使用线下深度学习更新模型;4、模型更新后对未标注池example做预测;5、取确信度最低example作为待标注样例;6、重复至步骤1;7、重复生成最优模型算法后,计算输出最佳待标注集;8、对最佳标注集进行人工标注,从而无需大量标注训练样本。
图1为本发明基于电信行业客服投诉工单训练文本计算最佳标注集的方法的实施方式。首先选取待标注电信行业客服投诉工单训练样本,然后进行如下步骤:
s1、取样标注一个样本label,取样标注样本应尽量选择涵盖电信行业客服投诉相关专有名词条目,保证电信行业客服投诉工单文本中专有名词的标注。
s2、对样本进行标注检测,并基于主动学习activelearning模型在线online主动学习,利用信息熵svm算法实时更新模型。
s3、当样本标注数据达到一定数据累计阈值(100-200条)时,使用线下offline的qbc算法深度学习更新模型。
s4、模型更新后对未标注example池做预测。
s5、取确信度最低example作为待标注样例。
s6、重复至步骤s1,对待标注样例进行标注。
s7、利用线下offlineqbc算法,不断迭代,生成最优模型后,计算输出最佳待标注集。
s8、对最佳标注集进行人工标注,从而无需大量标注训练样本。
本发明又一实施例提供一种基于电信行业客服投诉工单训练文本计算最佳标注集的系统,包括:
取样标注模块,用于取样标注一个样本。取样标注样本选择涵盖电信行业客服投诉相关专有名词条目,保证电信行业客服投诉工单文本中专有名词的标注。
线上主动学习模块,用于主动在线学习实时更新模型。利用信息熵svm算法实时更新模型。
线下主动学习模块,用于当标注数据达到一定数据累计阈值时,使用线下offline的qbc算法深度学习更新模型;数据累计阈值为100-200条。
example预测模块,用于模型更新后对未标注池example做预测。
待标注样例选取模块,用于取确信度最低example作为待标注样例。
迭代模块,用于对待标注样例进行重复标注。
最优模型算法模块,用于重复生成最优模型算法后,计算输出最佳待标注集。
最佳待标注集模块,用于对最佳标注集进行人工标注,从而无需大量标注训练样本。
本发明采用一种针对电信行业客服投诉工单文本语料进行主动学习提出最小核心有用标注集的方法,online线上与offline线下模型互相协作,与用户手动标注的过程一起不断循环迭代。在取样标注任务完成之后,offline线下模型可以重新在所有标注数据上重新训练,以达到最好的模型效果,从而减少人工标注的样本数量,大量降低人工标注成本,提高投诉工单文本分析系统的效率。
以上所述仅为本发明的较佳实施例而已,为方便本领域的技术人员更容易理解而设计,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!