一种融合视觉关系的行人与随身敏感物品跟踪方法与流程
本发明涉及计算机视觉技术领域,特别是一种融合视觉关系的行人与随身敏感物品跟踪方法。
背景技术:
社会治安事件治理是我国公共安全治理的重要组成部分,而社会治安事件主要表现为日常突发的安全事件,且许多事件性质恶劣,影响极其严重。于此同时,由于我国国民数量庞大,相较于人口较少的国家存在更多的安全隐患。
为了一定程度上预防此类安全隐患,视频监控系统逐渐普及,近些年我国各地视频监控市场呈逐步增长态势,当下已逐渐覆盖了各大城市。在城市治安监控中,行人作为社会活动的主体,是治安监控的主要目标,治安监控系统监控着各个公共场所的行人及其行为,并能够直观反映犯罪嫌疑人和犯罪活动的联系。人群在各种公共场所的行为影响着城市的社会治安秩序,而为了处理突发的社会治安事件,必须对公共场所实施视频监控。
视频监控系统的构建与其各种应用,在打击犯罪、维护稳定实践中正担任着愈发重要的角色,其已成为公安机关侦查破案的新方法。在案发后,安全员通常会在第一时间通过查看嫌疑人作案现场附近以及事发前后时间的监控录像,来得到特定目标的活动轨迹和行为,以进一步锁定与追踪目标。在现有的工作模式中,这一过程仍然大多通过人工来进行,但以深圳为例,其常住人口过千万,管理人口数量两千万,拥有超过130万个监控摄像头,这一数量的监控视频绝不可能仅通过人工处理。此外,人工处理存在极大的局限性,一方面,人类作为处理监控视频的主体,存在许多生理上的缺陷,其次,许多情况下,人并非是绝对可靠的观察者,常常无法意识到视频中的安全威胁或是容易出现遗漏,从而导致无法在第一时间发出预警。若需要对监控中的任何异常行为第一时间做出反应,需要相关的安全人员不间断的紧盯监控,如此一来易导致安防人员的疲倦,特别是查看多路监控视频的情况下,人眼难以同时捕获多路信息,难以第一时间对局面做出判断。过往的视频监控系统仅提供监控视频存储和回放等基础的功能,仅能记录已经发生的事情,不能实现智能报警的功能,也无预警的效果。此外,监控视频往往在事后也仅能起到取证的作用,即使通过该方式在案发后获取了嫌疑人的外形外貌信息,也常常会因为嫌疑人快速脱逃无法实现及时抓捕,因此迫切需要智能安防技术来辅助安防人员的工作,构建更完善的安防系统。
随着计算机技术的发展,市面上已经陆续出现新型的智能安防监控系统,其核心是通过计算机视觉技术对人群进行监控,计算机视觉研究是人工智能研究的其中一个主要分支,可以通过数字图像分析来理解视频中的内容。若将监控摄像头当作人眼,则智能监控系统就好比处理信息的大脑。智能监控系统借助计算机远胜过人脑的强大的数据处理功能,对监控视频中大量的数据进行分析与过滤,仅将有用的关键信息提供给监控者。智能视频监控能够进行全天候不限时段的监控,计算机弥补了人类生理上的缺陷,能够在全天对监控视频进行实时的处理,并在任意时间发起警报,另外,优秀的智能监控系统能够有效提升报警精度,降低漏报和误报的几率,其通过优越的图像处理能力,和优秀的智能算法,不但可以辨认监控画面中某个目标的异常行为,而且可以分析多人的群体行为。同时能够对以上行为进行分析判断和发起警报,当出现不停徘徊以及奔跑跳跃等异常行为或人群推搡发生踩踏时,能够及时对安防人员发出报警,又例如存在部分智能安防系统中设定了虚拟的警戒线,在视频中行人逾越警戒线时发起报警等应用方式,极大的提高了视频监控的实用性。并且,不同的智能监控系统能够识别多种异常行为和现象,比如遗留在公共场所的物体,或是在部分特殊区域停滞过久等行为,因而在危险事件发生以前就能够及时提醒安保人员注意到相关监控视频画面,实现一定程度上的防范于未然。这一系列智能安防系统很大程度上加快了事件处理的速度,但却仍有不足之处,如忽略了犯罪嫌疑人可能随身携带危险物品的问题,由于绝大多数的社会治安事件中,犯罪嫌疑人往往随身携带作案工具,如枪、刀等无疑是危险品的物品,除此之外,行人随身携带的包、行李箱等也有藏匿作案工具的嫌疑,因此对于此类敏感物品的检测有助于及时发现险情,当监控中潜在的罪犯持有危险物品时能够及时发现,有利于安防人员及时处理险情,这在一定程度上完善了现有智能安防系统的不足之处。同时,对于可能藏匿作案工具的包、行李箱等随身物品,则需要符合相应的可疑行为才能满足发出警示的条件。因此,考虑监控场景下行人与物品间的关系不仅使得安防人员能够获得监控视频中更丰富的语义信息,更能进一步完善对治安事件的检测效果。综上所述,融合视觉关系的敏感物品检测具有较强的研究意义与应用价值。
技术实现要素:
有鉴于此,本发明的目的是提出一种融合视觉关系的行人与随身敏感物品跟踪方法,本发明能够有效发现监控视频中潜在的威胁,完善现有智能安防体系的不足。
本发明采用以下方案实现:一种融合视觉关系的行人与随身敏感物品跟踪方法,首先根据可变形卷积的retinanet目标检测模型进行敏感物品检测,接着利用融合多特征的视觉关系检测模型进行敏感物视觉关系检测,最后利用deepsort多目标跟踪算法实现对视觉关系的跟踪。
进一步地,具体包括以下步骤:
步骤s1:构建安防敏感物品图像集;
步骤s2:对步骤s1得到的图像集进行数据增强,得到数据增强后的图像集,采用数据增强后的图像集重复步骤s3-步骤s4,对retinanet目标检测模型与视觉关系检测模型进行训练,在实际预测时,利用训练好的两个模型进行步骤s2-步骤s5;
步骤s3:利用结合可变形卷积的retinanet目标检测模型进行敏感物品检测;
步骤s4:使用融合多特征的视觉关系检测模型进行敏感物品的视觉关系检测;
步骤s5:进行基于deepsort的多敏感物品视觉关系跟踪。
进一步地,步骤s1具体包括以下步骤:
步骤s11:分析安防场景下的需重点观察的物品种类,将包括行人、刀具、枪械、行李箱、背包、手提包、水瓶在内的物品列为敏感物品;
步骤s12:通过爬虫分别下载互联网上的相关图片;
步骤s13:筛选出开源数据集coco图像集中包括刀具、枪械、行李箱、背包、手提包、水瓶在内的图片,并将json格式的标注文件转化为xml格式;
步骤s14:使用标注软件labelimg,对步骤s12与步骤s13获取的每一张图手动框选出物体,将矩形框的位置信息与分类信息保存于xml文件中,将标注后的图片集合作为安防敏感物品图像集。
进一步地,步骤s2具体包括以下步骤:
步骤s21:对步骤s1所得数据集中所有图片进行对比度拉伸,对应的xml中的标注信息不变,将进行对比度拉伸的图片加入新的数据集;
步骤s22:对步骤s1所得数据集中所有图片进行多尺度变换,分别将其长、宽变为初始大小的1/2与2倍,对xml中的标注信息同时做相应的坐标变换,并将处理后的图片加入新的数据集;
步骤s23:对步骤s1所得数据集中所有图片进行裁剪,裁剪每张图片1/10的边缘,保留中心,并对xml中的标注信息做相应的坐标变换,并将处理后的图片加入新的数据集;
步骤s24:对步骤s1所得数据集中所有图片加入随机噪声,对应的xml中的标注信息不变,将处理后的图片加入新的数据集;
步骤s25:将新的数据集与步骤s1得到的数据及合并得到数据增强后的图像集。
进一步地,步骤s3中,所述结合可变形卷积的retinanet目标检测模型包括resnet-50残差网络、上采样与add操作模块、可变形卷积模块、特征金字塔以及分类子网络与回归子网络;步骤s3具体包括以下步骤:
步骤s31:将resnet-50残差网络作为retinanet目标检测模型的主干网络,将敏感物品图像输入主干网络以提取图像特征;
步骤s32:将主干网络最后的5个卷积层输出的特征图命名为[c3,c4,c5,c6,c7];
步骤s33:对[c3,c4,c5]进行1×1卷积操作,改变特征图维度,输出特征图维数为256d;
步骤s34:对c5进行上采样,并将上采样的结果c5_up与c4进行add操作,得到c4_added,接着对c4_added进行上采样操作,并将其上采样结果与c3进行add操作,得到c3_added;
步骤s35:将c5、c4_added、c3_added分别进行通过一个卷积核大小为3×3的可变形卷积层以进一步提取特征分别得到[p5,p4,p3],即特征金字塔fpn的底部三层特征;
步骤s36:对c6进行卷积得到p6,接着对p6进行卷积得到p7,至此得到构建完全的特征金字塔[p3、p4、p5、p6、p7];
步骤s37:将特征金字塔的输出分别送入分类子网络以及回归子网络,分类子网络与回归子网络各包含4个256×3×3的卷积层,分别得到输入图片中的敏感物体的类别信息以及敏感物体所对应的检测框坐标位置。
进一步地,步骤s4中所述融合多特征的视觉关系检测模型包括空间位置特模块、词嵌入模块、局部视觉外观特征模块、全局上下文信息模块以及特征融合层;步骤s4具体包括以下步骤:
步骤s41:令p表示所有被标注的人与物体对的集合,每对物体(s,o)∈p中,s表示主语,o表示宾语。p(s,o)表示物体对(s,o)的所有视觉关系集合,即谓语集合,r=(s,p,o)|(s,o)∈p∧p∈p(s,o)表示一张图像中关于敏感物品的全部视觉关系组合,其中p为谓语;
步骤s42:对于步骤s3检测到的所有敏感物品,在空间位置特征模块中计算彼此的相对空间位置特征,其中,空间位置特征的计算方式为:
式中,x、y、w、h分别表示物体对应检测框的左上角横坐标、左上角纵坐标、该对应边界框的宽、高,下标s和o分别表示主语s以及宾语o;
步骤s43:在词嵌入特征模块中利用word2vec词嵌入模型分别将主语s和谓语o的物体类别表示为一个向量,然后将两个向量连接在一起,经过一个全连接层,得到对应的语义嵌入特征,该语义嵌入特征代表主语s与谓语o的语义先验信息;
步骤s44:将敏感物品图像送入可变性卷积的retinanet目标检测模型的resnet-50残差网络提取整张图像对应的特征图即全局特征图,作为全局上下文信息;
步骤s45:在局部视觉外观特征模块中,对于一个关系实例(s,p,o),利用roipooling操作分别截取对应关系实例中三元素所在区域对应的局部视觉特征,其中谓词p的视觉特征即为主语s和宾语o联合区域的特征,提取关系实例的三元素对应区域的视觉特征后直接将之拼接在一起,即得到每个敏感物品的局部视觉外观特征;
步骤s46:将步骤s42得到的空间位置特征、步骤s43得到的语义嵌入特征、步骤s44得到的全局特征图以及步骤s45得到的每个敏感物品的局部视觉外观特征送入视觉关系检测模型的特征融合层中,该融合层由全连接层组成,其中,4个全连接层用于改变空间位置特征、语义嵌入特征、全局特征以及局部视觉外观特征的维度,再将以上4个全连接层的输出进行拼接,送入两个全连接层中输出谓词、以及关系实例的置信度,并剔除置信度低于预设值的关系实例。
进一步地,步骤s46中,所述预设值设为0.3。
进一步地,步骤s5具体包括以下步骤:
步骤s51:当获取视频前一帧敏感物品图像检测输出的敏感物品检测框信息后,利用卡尔曼滤波对敏感物品进行轨迹预测,得到对应的预测框,以获取下一帧图像中相应目标的预测位置和大小;
步骤s52:计算当前检测框与预测框之间的马氏距离m;
步骤s53:计算当前检测框与预测框之间的表现特征的余弦距离cosθ,并使用最小余弦距离表示不同特征向量间的相似度;
步骤s54:计算马氏距离m与余弦距离cosθ的加权融合值z;
步骤s55:利用匈牙利算法实现预测框的匹配,通过匈牙利匹配判断图像与上一帧是否关联,同时对该图片进行卡尔曼滤波预测;当图像与上一帧关联时,判断敏感物品对应的视觉关系是否发生改变,若改变,则发出警报。
进一步地,步骤s54中,加权融合值z的计算为:z=0.5*m+0.5*cosθ。
与现有技术相比,本发明有以下有益效果:本发明提出的敏感物品检测方法能有效改善敏感物品检测中的物体形变问题,在保证了实时性的基础上进一步提升了准确率。同时,本发明提出的融合多特征的敏感物品视觉关系检测方法,相比传统的视觉关系检测方法具备更好的鲁棒性,进一步利用提出的多敏感物品视觉关系跟踪模型应对视觉关系变换时的潜在威胁。综上,本发明能够有效发现监控视频中潜在的威胁,完善现有智能安防体系的不足。
附图说明
图1为本发明实施例的方法原理示意图。
图2为本发明实施例的可变形卷积的retinanet目标检测模型结构示意图。
图3为本发明实施例的视觉关系检测模型结构示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
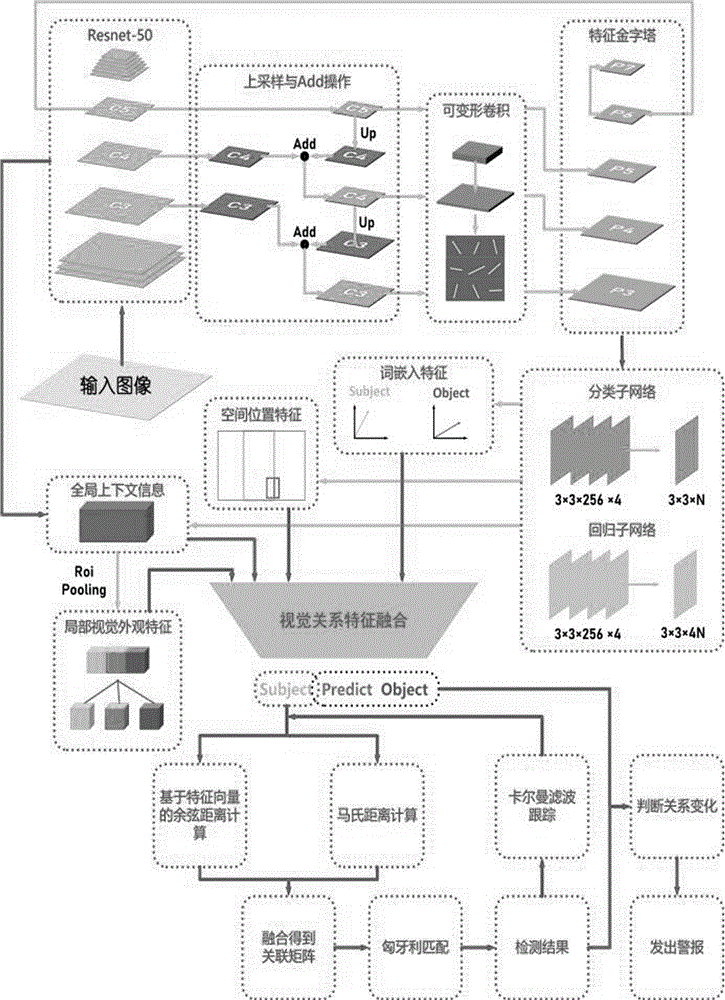
如图1所示,本实施例提供了一种融合视觉关系的行人与随身敏感物品跟踪方法,首先根据可变形卷积的retinanet目标检测模型进行敏感物品检测,接着利用融合多特征的视觉关系检测模型进行敏感物视觉关系检测,最后利用deepsort多目标跟踪算法实现对视觉关系的跟踪。
在本实施例中,具体包括以下步骤:
步骤s1:构建安防敏感物品图像集;
步骤s2:对步骤s1得到的图像集进行数据增强,得到数据增强后的图像集,采用数据增强后的图像集重复步骤s3-步骤s4,对retinanet目标检测模型与视觉关系检测模型进行训练,在实际预测时,利用训练好的两个模型进行步骤s2-步骤s5;
步骤s3:利用结合可变形卷积的retinanet目标检测模型进行敏感物品检测;
步骤s4:使用融合多特征的视觉关系检测模型进行敏感物品的视觉关系检测;
步骤s5:进行基于deepsort的多敏感物品视觉关系跟踪。
在本实施例中,步骤s1具体包括以下步骤:
步骤s11:分析安防场景下的需重点观察的物品种类,将包括行人、刀具、枪械、行李箱、背包、手提包、水瓶在内的物品列为敏感物品;
步骤s12:通过爬虫分别下载互联网上的相关图片;例如从淘宝网以及百度图片网站上下载相关图片;
步骤s13:筛选出开源数据集coco图像集中包括刀具、枪械、行李箱、背包、手提包、水瓶在内的图片,并将json格式的标注文件转化为xml格式;
步骤s14:使用标注软件labelimg,对步骤s12与步骤s13获取的每一张图手动框选出物体,将矩形框的位置信息与分类信息保存于xml文件中,将标注后的图片集合作为安防敏感物品图像集。
在本实施例中,步骤s2具体包括以下步骤:
步骤s21:对步骤s1所得数据集中所有图片进行对比度拉伸,对应的xml中的标注信息不变,将进行对比度拉伸的图片加入新的数据集;
步骤s22:对步骤s1所得数据集中所有图片进行多尺度变换,分别将其长、宽变为初始大小的1/2与2倍,对xml中的标注信息同时做相应的坐标变换,并将处理后的图片加入新的数据集;
步骤s23:对步骤s1所得数据集中所有图片进行裁剪,裁剪每张图片1/10的边缘,保留中心,并对xml中的标注信息做相应的坐标变换,并将处理后的图片加入新的数据集;
步骤s24:对步骤s1所得数据集中所有图片加入随机噪声,对应的xml中的标注信息不变,将处理后的图片加入新的数据集;
步骤s25:将新的数据集与步骤s1得到的数据及合并得到数据增强后的图像集。
在本实施例中,步骤s3中,所述结合可变形卷积的retinanet目标检测模型包括resnet-50残差网络、上采样与add操作模块、可变形卷积模块、特征金字塔以及分类子网络与回归子网络,具体如图2所示;步骤s3具体包括以下步骤:
步骤s31:将resnet-50残差网络作为retinanet目标检测模型的主干网络,将敏感物品图像输入主干网络以提取图像特征;
步骤s32:将主干网络最后的5个卷积层输出的特征图命名为[c3,c4,c5,c6,c7];
步骤s33:对[c3,c4,c5]进行1×1卷积操作,改变特征图维度,输出特征图维数为256d;
步骤s34:对c5进行上采样,并将上采样的结果c5_up与c4进行add操作,得到c4_added,接着对c4_added进行上采样操作,并将其上采样结果与c3进行add操作,得到c3_added;
步骤s35:将c5、c4_added、c3_added分别进行通过一个卷积核大小为3×3的可变形卷积层以进一步提取特征分别得到[p5,p4,p3],即特征金字塔fpn的底部三层特征;
步骤s36:对c6进行卷积得到p6,接着对p6进行卷积得到p7,至此得到构建完全的特征金字塔[p3、p4、p5、p6、p7];
步骤s37:将特征金字塔的输出分别送入分类子网络以及回归子网络,分类子网络与回归子网络各包含4个256×3×3的卷积层,分别得到输入图片中的敏感物体的类别信息以及敏感物体所对应的检测框坐标位置。
在本实施例中,步骤s4中所述融合多特征的视觉关系检测模型包括空间位置特模块、词嵌入模块、局部视觉外观特征模块、全局上下文信息模块以及特征融合层,具体如图3所示;步骤s4具体包括以下步骤:
步骤s41:令p表示所有被标注的人与物体对的集合,每对物体(s,o)∈p中,s表示主语,o表示宾语。p(s,o)表示物体对(s,o)的所有视觉关系集合,即谓语集合,r=(s,p,o)|(s,o)∈p∧p∈p(s,o)表示一张图像中关于敏感物品的全部视觉关系组合,其中p为谓语;
步骤s42:对于步骤s3检测到的所有敏感物品,在空间位置特征模块中计算彼此的相对空间位置特征,其中,空间位置特征的计算方式为:
式中,x、y、w、h分别表示物体对应检测框的左上角横坐标、左上角纵坐标、该对应边界框的宽、高,下标s和o分别表示主语s以及宾语o;
步骤s43:在词嵌入特征模块中利用word2vec词嵌入模型分别将主语s和谓语o的物体类别表示为一个向量,然后将两个向量连接在一起,经过一个全连接层,得到对应的语义嵌入特征,该语义嵌入特征代表主语s与谓语o的语义先验信息;
步骤s44:将敏感物品图像送入可变性卷积的retinanet目标检测模型的resnet-50残差网络提取整张图像对应的特征图即全局特征图,作为全局上下文信息;
步骤s45:在局部视觉外观特征模块中,对于一个关系实例(s,p,o),利用roipooling操作分别截取对应关系实例中三元素所在区域对应的局部视觉特征,其中谓词p的视觉特征即为主语s和宾语o联合区域的特征,提取关系实例的三元素对应区域的视觉特征后直接将之拼接在一起,即得到每个敏感物品的局部视觉外观特征;
步骤s46:将步骤s42得到的空间位置特征、步骤s43得到的语义嵌入特征、步骤s44得到的全局特征图以及步骤s45得到的每个敏感物品的局部视觉外观特征送入视觉关系检测模型的特征融合层中,该特征融合层由全连接层组成,其中,4个全连接层用于改变空间位置特征、语义嵌入特征、全局特征以及局部视觉外观特征的维度,再将以上4个全连接层的输出进行拼接,送入两个全连接层中输出谓词、以及关系实例的置信度,并剔除置信度低于预设值的关系实例。
在本实施例中,步骤s46中,所述预设值设为0.3。
在本实施例中,步骤s5具体包括以下步骤:
步骤s51:当获取视频前一帧敏感物品图像检测输出的敏感物品检测框信息后,利用卡尔曼滤波对敏感物品进行轨迹预测,得到对应的预测框,以获取下一帧图像中相应目标的预测位置和大小;
步骤s52:计算当前检测框与预测框之间的马氏距离m;其中,马氏距离m的计算公式为:
式中,∑为协方差矩阵,μ为所有随机变量e的均值;
步骤s53:计算当前检测框与预测框之间的表现特征的余弦距离cosθ,并使用最小余弦距离表示不同特征向量间的相似度;
其中,设两个向量分别为a[a1,a2,a3…an],b[b1,b2,b3…..bn],则两者之间的余弦距离可以用它们之间夹角的余弦值表示,计算公式为:
接着,使用最小余弦距离表示不同特征向量间的相似度d2(i,j),如式:
d2(i,j)=min{1-rjtri};
式中,d2(i,j)为第j个检测框和第i条轨迹之间的表观匹配程度,rj和ri为深度学习网络提取的以及归一化处理的特征向量,则rjtri表示两个向量的余弦距离,其中,上标t表示向量的转置;
步骤s54:计算马氏距离m与余弦距离cosθ的加权融合值z;
步骤s55:利用匈牙利算法实现预测框的匹配,通过匈牙利匹配判断图像与上一帧是否关联,同时对该图片进行卡尔曼滤波预测;当图像与上一帧关联时,判断敏感物品对应的视觉关系是否发生改变,若改变,则发出警报。
在本实施例中,步骤s54中,加权融合值z的计算为:z=0.5*m+0.5*cosθ。
在本实施例中,步骤s55中,利用匈牙利算法实现预测框的匹配,算法基本流程为:创建的目标匹配矩阵cl×j,并将cl×j的每行元素减去当前行中值最小的元素,进行上述计算后每行得到一个零元素,设计算后的矩阵为c1,接着再对c1的每一列减去当前列值最小的元素,计算后每列都会得到一个零元素,设计算后的矩阵为c2。然后用尽可能少的直线覆盖c2中的零元素,直线的数量设为m,如果m与min{l,j}相等,那么便从所含零元素最少的行与列开始进行分配,直到分配结束便可获得最优匹配方案,若不相等则找出c2中未被直线覆盖的元素,并将元素中的最小值标记为mi,将所有未被覆盖的元素存在的行减掉b值,并在有直线覆盖的元素所在列加上一个mi值,再重新进行对c2零元素的覆盖操作。
综上,本实施例针对市面上的大部分安防系统未关注敏感物品,且忽略人与物品间交互关系的问题,采用了融合视觉关系的行人与随身敏感物品跟踪方法。对于输入的一张图像,利用deform-retinanet进行敏感物品检测,该检测算法采用focalloss作为损失函数,结合resnet-50作为特征提取网络,并引入可变形卷积,并通过两个不同的全卷积神经网络分别得到物体的坐标以及其分类信息。对于检测到的视觉关系主语(行人)及宾语(敏感物品),union为二者的联合区域,代表谓词在视觉关系中的区域,在空间位置特征模块中,计算主语和宾语的相对位置特征,该特征由一个四维的向量构成,其具有尺度不变性。在词嵌入特征模块中,将word2vec作为现成的语言先验模块得到其语义嵌入特征。另一边,将原图送入resnet-50中提取特征,返回的全局特征图作为网络的全局上下文信息,并进一步利用roipooling获取特征图中物体对应位置的特征,即主语、谓语、宾语的局部外观特征,作为局部的视觉外观特征。将空间位置特征、词嵌入特征、局部视觉外观特征、全局上下文信息共同送入网络的融合层中,输出图像中的视觉关系。接着,通过基于特征向量的余弦距离以及马氏距离的加权融合得到跟踪敏感的关联矩阵,通过匈牙利匹配判断图像与上一帧是否关联,同时对该图片进行卡尔曼滤波预测。当图像与上一帧关联时,判断敏感物品对应的视觉关系是否发生改变,若改变,则发出警报。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!