信息获取方法、装置、电子设备及计算机可读存储介质与流程
本申请涉及自然语言处理技术领域,特别是涉及一种信息获取方法、装置、电子设备及计算机可读存储介质。
背景技术:
问答系统是当前自然语言处理的研究热点之一,问答系统中一个重要步骤是问句实体链指,链指的结果直接影响问答系统的性能。
传统的问句实体连接方法主要通过两个步骤完成,即命名实体识别和实体连接。实体识别当前主要是基于crf(conditionalrandomfield,条件随机域)、或者blstmcrf(bidirectionallongshort-termmemorycrf,双向长短期记忆神经网络条件随机域)等方式,实体链指主要采用分类方法和相似度计算等方法。分类方法需要先选择候选实体,使用经典机器学习方法或神经网络方法进行分类,经典分类方法需要大量特征工程工作。
在相似度计算方面,有概率主题模型、基于图的方法和排序法等方法。这些方法利用上下文语义信息,但在问句中上下文信息很少。
在通常技术方案中,采用基于词向量(wordembedding)的方法进行实体链接,词向量可以反映词的语义信息,但通常需要引入额外的语料以训练词向量,另外一些文献采用构建模版的方法进行问题理解,但是这种方法需要大量的人工模板、费时费力、缺乏灵活性、拓展性不强。
技术实现要素:
本申请提供一种信息获取方法、装置、电子设备及计算机可读存储介质,以解决现有技术中需要大量的人工模板、费时费力、缺乏灵活性,拓展性不强的问题。
为了解决上述问题,本申请公开了一种信息获取方法,包括:
识别出待解答问题中的至少一个实体检索词;
根据所述至少一个实体检索词进行信息检索,得到所述至少一个实体检索词对应的子图形式的检索文本;
对所述子图形式的检索文本与所述待解答问题进行匹配,确定出目标子图形式的检索文本;
根据所述目标子图形式的检索文本,确定所述待解答问题对应的至少一个候选答案;
获取所述至少一个候选答案与所述待解答问题对应的相似度;
根据所述相似度,从所述至少一个候选答案中确定所述待解答问题的目标答案。
可选地,所述识别出待解答问题中的至少一个实体检索词,包括:
获取所述待解答问题;
将所述待解答问题输入至第一网络模型进行文本识别;
根据文本识别结果,确定出所述待解答问题中的起止位置;
根据所述起止位置,确定所述至少一个实体检索词。
可选地,所述根据所述至少一个实体检索词进行信息检索,得到所述至少一个实体检索词对应的子图形式的检索文本,包括:
采用所述至少一个实体检索词在预置知识库中进行检索,得到与所述至少一个实体检索词关联的多个初始检索文本;
将所述至少一个实体检索词与所述多个初始检索文本以子图形式进行关联,得到所述子图形式的检索文本。
可选地,所述对所述子图形式的检索文本与所述待解答问题进行匹配,确定出目标子图形式的检索文本,包括:
将所述子图形式的检索文本与所述待解答问题组成句子对文本;
将所述句子对文本输入至所述第二网络模型;
通过所述第二网络模型对所述句子对文本进行实体消歧处理,确定所述目标子图形式的检索文本。
可选地,所述根据所述目标子图形式的检索文本,确定所述待解答问题对应的至少一个候选答案,包括:
对所述目标子图形式的检索文本进行拆解,得到所述至少一个候选答案。
可选地,所述获取所述至少一个候选答案与所述待解答问题对应的相似度,包括:
将所述至少一个候选答案分别与所述待解答问题输入至第三网络模型;
通过所述第三网络模型对所述至少一个候选答案和所述待解答问题进行相似度匹配,确定所述至少一个候选答案与所述待解答问题的相似度。
为了解决上述问题,本申请公开了一种信息获取装置,包括:
实体检索词识别模块,用于识别出待解答问题中的至少一个实体检索词;
子图检索文本获取模块,用于根据所述至少一个实体检索词进行信息检索,得到所述至少一个实体检索词对应的子图形式的检索文本;
目标子图文本确定模块,用于对所述子图形式的检索文本与所述待解答问题进行匹配,确定出目标子图形式的检索文本;
候选答案确定模块,用于根据所述目标子图形式的检索文本,确定所述待解答问题对应的至少一个候选答案;
相似度获取模块,用于获取所述至少一个候选答案与所述待解答问题对应的相似度;
目标答案确定模块,用于根据所述相似度,从所述至少一个候选答案中确定所述待解答问题的目标答案。
可选地,所述实体检索词识别模块包括:
待解答问题获取单元,用于获取所述待解答问题;
文本识别单元,用于将所述待解答问题输入至第一网络模型进行文本识别;
起止位置确定单元,用于根据文本识别结果,确定出所述待解答问题中的起止位置;
实体检索词确定单元,用于根据所述起止位置,确定所述至少一个实体检索词。
可选地,所述子图检索文本获取模块包括:
初始检索文本获取单元,用于采用所述至少一个实体检索词在预置知识库中进行检索,得到与所述至少一个实体检索词关联的多个初始检索文本;
子图检索文本获取单元,用于将所述至少一个实体检索词与所述多个初始检索文本以子图形式进行关联,得到所述子图形式的检索文本。
可选地,所述目标子图文本确定模块包括:
句子对文本组成单元,用于将所述子图形式的检索文本与所述待解答问题组成句子对文本;
句子对文本输入单元,用于将所述句子对文本输入至所述第二网络模型;
目标子图文本确定单元,用于通过所述第二网络模型对所述句子对文本进行实体消歧处理,确定所述目标子图形式的检索文本。
可选地,所述候选答案确定模块包括:
候选答案获取单元,用于对所述目标子图形式的检索文本进行拆解,得到所述至少一个候选答案。
可选地,所述相似度获取模块包括:
候选答案输入单元,用于将所述至少一个候选答案分别与所述待解答问题输入至第三网络模型;
相似度确定单元,用于通过所述第三网络模型对所述至少一个候选答案和所述待解答问题进行相似度匹配,确定所述至少一个候选答案与所述待解答问题的相似度。
为了解决上述问题,本申请公开了一种电子设备,包括:
处理器、存储器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一项所述的信息获取方法。
为了解决上述问题,本申请公开了一种计算机可读存储介质,当所述存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行上述任一项所述的信息获取方法。
与现有技术相比,本申请包括以下优点:
本申请实施例提供的信息获取方案,通过识别出待解答问题中的至少一个实体检索词,根据至少一个实体检索词进行信息检索,得到至少一个实体检索词对应的子图形式的检索文本,对子图形式的检索文本与待解答问题进行匹配,确定出目标子图形式的检索文本,根据目标子图形式的检索文本,确定待解答问题对应的至少一个候选答案,获取至少一个候选答案与待解答问题对应的相似度,根据相似度,从至少一个候选答案中确定待解答问题的目标答案。本申请实施例通过采用子图匹配的方式进行实体消歧,同时实现实体识别、实体消歧义以及文本匹配三个关键任务,该方法不需要引入外部语料也无需构建模板,提高问答系统的灵活性和效率。
附图说明
图1示出了本申请实施例提供的一种信息获取方法的步骤流程图;
图2示出了本申请实施例提供的另一种信息获取方法的步骤流程图;
图2a示出了本申请实施例提供的一种问答系统的示意图;
图2b示出了本申请实施例提供的一种实体标注样例的示意图;
图2c示出了本申请实施例提供的一种实体识别模型的示意图;
图2d示出了本申请实施例提供的一种实体子图信息的示意图;
图2e示出了本申请实施例提供的一种基于bert的子图匹配算法的示意图;
图2f示出了本申请实施例提供的一种子图拆解的示意图;
图2g示出了本申请实施例提供的一种文本相似度匹配的示意图;
图2h示出了本申请实施例提供的一种联合学习模型的示意图;
图3示出了本申请实施例提供的一种信息获取装置的结构示意图;
图4示出了本申请实施例提供的另一种信息获取装置的结构示意图。
具体实施方式
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本申请作进一步详细的说明。
参照图1,示出了本申请实施例提供的一种信息获取方法的步骤流程图,该信息获取方法具体可以包括如下步骤:
步骤101:识别出待解答问题中的至少一个实体检索词。
本申请实施例可以应用于问答系统中,以获取待解答问题对应的答案的场景中。
对于问答系统可以结合图2a进行如下描述。
参照图2a,示出了本申请实施例提供的一种问答系统的示意图,如图2a所示,对于待解答问题“q:徐悲鸿的八骏图创作于哪一年”,首先,可以对待解答问题进行实体识别,得到识别的实体检索词:“徐悲鸿”、“八骏图”,然后根据实体检索词进行信息检索,可以得到两个子图形式的检索结果:八骏图(郎世宁)和八骏图(徐悲鸿)(可以理解地,在知识图谱中信息都是以子图的形式存在的),然后,再通过子图匹配的方式进行实体消歧,去除非检索的信息,得到八骏图(徐悲鸿)对应的子图信息,并通过实体信息与待解答问题的文本相似度匹配,从而得到最终的答案。
接下来,结合具体地步骤,对本申请实施例的方案为进行详细描述。
待解答问题是指用于从知识图谱中获取到相应答案的问题。
在某些示例中,待解答问题可以是由用户输入的问题,例如,在用户a需要获取某个问题的答案时,可以在知识图谱中输入相应的问题,从而可以得到对应的待解答问题。
在某些示例中,待解答问题还可以是从互联网上获取的问题,例如,可以获取用户针对哪些问题感兴趣,将用户比较感兴趣的问题作为待解答问题等。
可以理解地,上述示例仅是为了更好地理解本申请实施例的技术方案而列举的示例,在具体实现中,还可以采用其它方式获取待解答问题,本申请实施例对获取待解答问题的方式不加以限制。
实体检索词是指待解答问题中用于进行信息检索的实体词,在本申请中,可以采用指针标注的方式获取待解答问题中的实体检索词,而对于实体检索词的具体获取方式将在下述实施例中进行详细描述,本申请实施例在此不再加以赘述。
在获取待解答问题之后,可以对待解答问题进行识别,从而得到待解答问题中包含的至少一个实体检索词。例如,待解答问题为:徐悲鸿的八骏图创作于哪一年,其中包含的实体为:徐悲鸿、八骏图。
可以理解地,上述示例仅是为了更好地理解本申请实施例的技术方案而列举的示例,不作为对本申请实施例的唯一限制。
在识别出待解答问题中的至少一个实体检索词之后,执行步骤102。
步骤102:根据所述至少一个实体检索词进行信息检索,得到所述至少一个实体检索词对应的子图形式的检索文本。
子图形式的检索文本是指采用至少一个实体检索词在知识图谱进行信息检索,得到的检索结果文本。
可以理解地,在知识图谱中,各类信息通常是以子图形式的,子图形式可以结合图2d进行描述,参照图2d,示出了本申请实施例提供的一种实体子图信息的示意图,如图2d所示,与八骏图相关的信息可以采用“—”连接,从而可以形成相应的子图形式的关联信息。
在识别出待解答问题中的至少一个实体检索词之后,可以采用实体检索词在知识图谱中进行信息检索,进而,可以得到与每一个实体检索词对应的子图形式的检索文本。
在根据至少一个实体检索词进行信息检索,得到至少一个实体检索词对应的子图形式的检索文本之后,执行步骤103。
步骤103:对所述子图形式的检索文本与所述待解答问题进行匹配,确定出目标子图形式的检索文本。
目标子图形式的检索文本是指从至少一个实体检索词中选取的与待解答问题匹配的子图形式的检索文本。即本步骤中实现实体消歧,去除与待解答问题不匹配的子图形式的检索文本,从而可以得到最终的与待解答问题匹配的检索文本,即为目标子图形式的检索文本。
在得到至少一个实体检索词对应的子图形式的检索文本之后,则可以将子图形式的检索文本与待解答问题进行匹配,根据匹配结果可以从至少一个实体检索词中确定出与待解答问题匹配的目标子图形式的检索文本。对于匹配确定目标子图形式的检索文本的过程将在下述实施例中进行详细描述,本申请实施例在此不再加以赘述。
在对子图形式的检索文本与待解答问题进行匹配,确定出目标子图形式的检索文本之后,执行步骤104。
步骤104:根据所述目标子图形式的检索文本,确定所述待解答问题对应的至少一个候选答案。
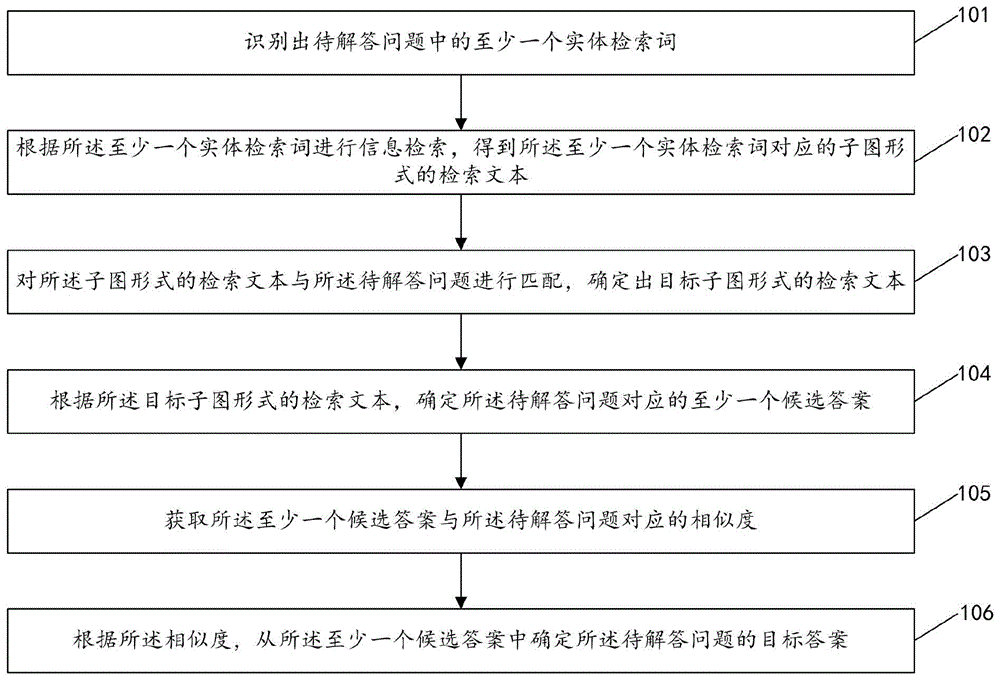
候选答案是指从目标子图形式的检索文本中选取作为待解答问题的答案的候选项。
在获取到与待解答问题匹配的目标子图形式的检索文本之后,则可以根据目标子图形式的检索文本确定待解答问题的至少一个候选答案,具体地,可以对目标子图形式的检索文本进行拆解,可以得到至少一个候选答案,例如,参照图2f,示出了本申请实施例提供的一种子图拆解的示意图,如图2f所示,在将图2f左半图拆解后,可以如图2f右半图所示的多个候选项:八骏图作者徐悲鸿,八骏图创作时间近代,八骏图收藏地不详,八骏图流派浪漫主义,八骏图创作类别水墨画等。
可以理解地,上述示例仅是为了更好地理解本申请实施例的技术方案而列举的示例,不作为对本申请实施例的唯一限制。
在根据目标子图形式的检索文本,确定出待解答问题对应的至少一个候选答案之后,执行步骤105。
步骤105:获取所述至少一个候选答案与所述待解答问题对应的相似度。
相似度是指至少一个候选答案与待解答问题之间的相似程度,相似度可以反应出哪些候选答案与待解答问题比较接近,能够作为待解答问题的标准答案。
在根据目标子图形式的检索文本,确定出待解答问题对应的至少一个候选答案之后,可以获取至少一个候选答案与待解答问题之间的相似度,具体地,可以将至少一个候选答案分别与待解答问题输入至预置网络模型,通过预置网络模型识别出至少一个候选答案与待解答问题之间的相似度,具体地,将在下述实施例中进行详细描述,本申请实施例在此不再加以赘述。
在获取各候选答案与待解答问题之间的相似度之后,执行步骤106。
步骤106:根据所述相似度,从所述至少一个候选答案中确定所述待解答问题的目标答案。
目标答案是指从至少一个候选答案中选择出的待解答问题的标准答案,即将最终选择的目标答案作为待解答问题的准确答案。
在获取至少一个候选答案与待解答问题之间的相似度之后,可以结合至少一个候选答案的相似度从至少一个候选答案中选择出待解答问题的目标答案,具体地,可以从至少一个候选答案中选择相似度最大的候选答案作为待解答问题的目标答案,或者,从至少一个候选答案中选择相似度大于设定相似度阈值的至少一个候选答案作为待解答问题的目标答案。具体地,可以根据业务需求而定,本申请实施例对此不加以限制。
本申请实施例通过采用子图匹配的方式进行实体消歧,无需构建模板,提高了问答系统的信息检索效率。
本申请实施例提供的信息获取方法,通过识别出待解答问题中的至少一个实体检索词,根据至少一个实体检索词进行信息检索,得到至少一个实体检索词对应的子图形式的检索文本,对子图形式的检索文本与待解答问题进行匹配,确定出目标子图形式的检索文本,根据目标子图形式的检索文本,确定待解答问题对应的至少一个候选答案,获取至少一个候选答案与待解答问题对应的相似度,根据相似度,从至少一个候选答案中确定待解答问题的目标答案。本申请实施例通过采用子图匹配的方式进行实体消歧,同时实现实体识别、实体消歧义以及文本匹配三个关键任务,该方法不需要引入外部语料也无需构建模板,提高问答系统的灵活性和效率。
参照图2,示出了本申请实施例提供的另一种信息获取方法的步骤流程图,该信息获取方法具体可以包括如下步骤:
步骤201:获取所述待解答问题。
本申请实施例可以应用于问答系统中,以获取待解答问题对应的答案的场景中。
对于问答系统可以结合图2a进行如下描述。
参照图2a,示出了本申请实施例提供的一种问答系统的示意图,如图2a所示,对于待解答问题“q:徐悲鸿的八骏图创作于哪一年”,首先,可以对待解答问题进行实体识别,得到识别的实体检索词:“徐悲鸿”、“八骏图”,然后根据实体检索词进行信息检索,可以得到两个子图形式的检索结果:八骏图(郎世宁)和八骏图(徐悲鸿)(可以理解地,在知识图谱中信息都是以子图的形式存在的),然后,再通过子图匹配的方式进行实体消歧,去除非检索的信息,得到八骏图(徐悲鸿)对应的子图信息,并通过实体信息与待解答问题的文本相似度匹配,从而得到最终的答案。
接下来,结合具体地步骤,对本申请实施例的方案为进行详细描述。
待解答问题是指用于从知识图谱中获取到相应答案的问题。
在某些示例中,待解答问题可以是由用户输入的问题,例如,在用户a需要获取某个问题的答案时,可以在知识图谱中输入相应的问题,从而可以得到对应的待解答问题。
在某些示例中,待解答问题还可以是从互联网上获取的问题,例如,可以获取用户针对哪些问题感兴趣,将用户比较感兴趣的问题作为待解答问题等。
可以理解地,上述示例仅是为了更好地理解本申请实施例的技术方案而列举的示例,在具体实现中,还可以采用其它方式获取待解答问题,本申请实施例对获取待解答问题的方式不加以限制。
在获取到待解答问题之后,执行步骤202。
步骤202:将所述待解答问题输入至第一网络模型进行文本识别。
第一网络模型是指用于对待解答问题进行文本识别的模型,在本申请中,第一网络模型可以为bert模型等。
在获取到待解答问题之后,可以将待解答问题输入至第一网络模型,由第一网络模型对待解答问题进行文本识别。
在本申请中可以采用指针标注的方式实现文本识别,例如,参照图2b,示出了本申请实施例提供的一种实体标注样例的示意图,如图2b所示,可以采用两个序列标注分别标注实体的在数据中的起止位置,如图2b所示,问句徐悲鸿的八骏图创作于哪一年?中“徐悲鸿”和“八骏图”的标注方式。
具体地,可以将待解答问题以单输入的方式输入至第一网络模型,如图2c所示,将待解答问题输入至bert模型之后,进而,可以将句子编码为[cls]徐悲鸿的八骏图创作于哪一年?[sep],将bert输出的编码通过一个全连接层,采用sigmod激活函数,loss函数采用二进制交叉熵损失函数,最终输出序列每个位置上的值即为实体起止位置的置信度,这里取置信度大于0.5的位置为实体的起止位置,截取原始输入文本的相应位置便可以得到实体。
在将待解答问题输入至第一网络模型进行文本识别之后,执行步骤203。
步骤203:根据文本识别结果,确定出待解答问题中的起止位置。
起止位置是指在待解答问题中进行标注的起始和结束位置,通过标注的起止位置可以确定标注的实体词。
至将待解答问题输入至第一网络模型进行文本识别之后,在可以根据文本识别结果得到在待解答问题的文本中的标注起止位置,如图2b所示,可以采用指针标注的方式进行实体识别,具体方法为:用两个序列标注分别标注实体的在数据中的起止位置,图2b便是问句“徐悲鸿的八骏图创作于哪一年?”中“徐悲鸿”和“八骏图”的标注方式。
在根据文本识别结果确定出待解答问题中的起止位置之后,执行步骤204。
步骤204:根据所述起止位置,确定所述至少一个实体检索词。
实体检索词是指待解答问题中用于进行信息检索的实体词。
在确定出待解答问题中的起止位置之后,可以根据起止位置识别出待解答问题中的实体词,如图2b所示,根据标注结果,可以得到其中的实体词为:“徐悲鸿”和“八骏图”。
在根据文本识别结果得到至少一个实体检索词之后,执行步骤205。
步骤205:采用所述至少一个实体检索词在预置知识库中进行检索,得到与所述至少一个实体检索词关联的多个初始检索文本。
在本申请中,预置知识库是指预先生成的对应于知识图谱的数据库,在预置知识库中,可以将知识图谱的信息全部以关联形式存储于数据库中,以得到预置知识库,具体地,可以采用数据库列表的形式,以某个实体词作为索引,将其关联的信息依次排布,从而可以形成具有众多关联关系的子图形式的关联信息。
初始检索文本是指采用实体检索词在预置知识库中检索得到的检索文本。
在获取至少一个实体检索词之后,则可以采用至少一个实体检索词在预置知识库中进行检索,从而,可以得到与每个实体检索词关联的多个初始检索文本。
在采用至少一个实体检索词在预置知识库中进行检索,得到与至少一个实体检索词关联的多个初始检索文本之后,执行步骤206。
步骤206:将所述至少一个实体检索词与所述多个初始检索文本以子图形式进行关联,得到所述子图形式的检索文本。
将识别的实体作为检索词进行知识图谱检索,例如,当检索八骏图时,知识库中存在两个八骏图,可以从知识图谱中获取该实体的属性和关系,它们是以子图的形式存在知识图谱中,如图2d所示。为了区别问句中的八骏图是图2d中的哪一个,将实体的属性与关系用“—”拼接起来,作为该实体的描述信息。如图2d所示,可以将八骏图(徐悲鸿)和八骏图(郎世宁)分别对应的信息相关联,能够得到这两个实体分别对应的子图形式的检索文本,如,两个八骏图的实体描述分别为:作者徐悲鸿__创作时间近代__创作类别水墨画__流派浪漫主义__收藏地不详;作者郎世宁__创作时间清代__创作类别绢本设色__流派宫廷绘画__收藏地故宫博物院。
在将至少一个实体检索词与多个初始检索文本以子图形式进行关联,得到子图形式的检索文本之后,执行步骤207。
步骤207:将所述子图形式的检索文本与所述待解答问题组成句子对文本。
句子对是指两个文本组成的一对句子文本,例如,两个文本分别为“徐悲鸿”、“张大千”,这两个文本组成句子对即为“徐悲鸿—张大千”;再例如,两个文本为“山水画”、“风景画”,这两个文本组成的句子对即为“山水画—风景画”。
句子对文本是指子图形式的检索文本与待解答问题所组成的句子对,也即在得到每个实体检索词对应的子图形式的检索文本之后,则将每个子图形式的检索文本与待解答问题组成一个句子对,从而可以得到句子对文本。
在将各子图形式的检索文本与待解答问题组成句子对文本之后,执行步骤208。
步骤208:将所述句子对文本输入至所述第二网络模型。
第二网络模型是指预先设置的用于对子图形式的检索文本进行实体消歧的网络模型,第二网络模型可以为bert模型等,具体地,可以根据业务需求而定,本申请实施例对此不加以限制。
在将各子图形式的检索文本与待解答问题组成句子对文本之后,可以将各句子对文本输入至第二网络模型,例如,承接步骤207中的示例,输入bert的句子对编码为:[cls]徐悲鸿的八骏图创作于哪一年?[sep]作者徐悲鸿__创作时间近代__创作类别水墨画__流派浪漫主义__收藏地不详[sep],则可以采用“[cls]徐悲鸿的八骏图创作于哪一年?[sep]”输入至bert模型,采用dense层和sigmod层对输入的问题进行处理。
可以理解地,上述示例仅是为了更好地理解本申请实施例的技术方案而列举的示例,不作为对本申请实施例的唯一限制。
在将句子对文本输入至第二网络模型之后,执行步骤209。
步骤209:通过所述第二网络模型对所述句子对文本进行实体消歧处理,确定所述目标子图形式的检索文本。
目标子图形式的检索文本是指从至少一个实体检索词中选取的与待解答问题匹配的子图形式的检索文本。即本步骤中实现实体消歧,去除与待解答问题不匹配的子图形式的检索文本,从而可以得到最终的与待解答问题匹配的检索文本,即为目标子图形式的检索文本。
在将句子对文本输入至第二网络模型之后,可以通过第二网络模型对句子对文本进行实体消歧处理,具体地,可以将子图形式的检索文本与待解答问题进行语义分析识别,从而识别出与待解答问题匹配的目标子图形式的检索文本。例如,参照图2e,示出了本申请实施例提供的一种基于bert的子图匹配算法的示意图,如图2e所示,在组成每个子图形式的检索文本与待解答问题之间的句子对文本之后,则可以输入至第二网络模型,由第二网络模型根据待解答问题和实体描述,确定出与待解答问题匹配的目标子图形式的检索文本。
在通过第二网络模型对句子对文本进行实体消歧处理,确定目标子图形式的检索文本之后,执行步骤210。
步骤210:对所述目标子图形式的检索文本进行拆解,得到所述至少一个候选答案。
候选答案是指从目标子图形式的检索文本中选取作为待解答问题的答案的候选项。
在确定了问句中核心实体的子图(即目标子图形式的检索文本),为进一步确定答案,需要将核心实体的子图按照关系和属性进行拆解,从而可以得到至少一个候选答案,例如,参照图2f,示出了本申请实施例提供的一种子图拆解的示意图,如图2f所示,在将图2f左半图拆解后,可以如图2f右半图所示的多个候选项:八骏图作者徐悲鸿,八骏图创作时间近代,八骏图收藏地不详,八骏图流派浪漫主义,八骏图创作类别水墨画等。
可以理解地,上述示例仅是为了更好地理解本申请实施例的技术方案而列举的示例,不作为对本申请实施例的唯一限制。
在对目标子图形式的检索文本进行拆解,得到至少一个候选答案之后,执行步骤211。
步骤211:将所述至少一个候选答案分别与所述待解答问题输入至第三网络模型。
第三网络模型是指用于计算候选答案与待解答问题之间的相似度的模型。第三网络模型可以为bert模型等,具体地,可以根据业务需求而定,本申请实施例对此不加以限制。
在获取至少一个候选答案之后,则可以将至少一个候选答案分别与待解答问题输入至第三网络模型。
在将至少一个候选答案分别与待解答问题输入至第三网络模型之后,执行步骤212。
步骤212:通过所述第三网络模型对所述至少一个候选答案和所述待解答问题进行相似度匹配,确定所述至少一个候选答案与所述待解答问题的相似度。
相似度是指至少一个候选答案与待解答问题之间的相似程度,相似度可以反应出哪些候选答案与待解答问题比较接近,能够作为待解答问题的标准答案。
在将至少一个候选答案分别与待解答问题输入至第三网络模型之后,可以通过第三网络模型对至少一个候选答案进行相似度计算,例如,参照图2g,示出了本申请实施例提供的一种文本相似度匹配的示意图,如图2g所示,可以将问句(即待解答问题)与关系/属性描述(即候选答案)输入至bert,通过bert模型上对至少一个候选答案和待解答问题进行相似度匹配,从而获取到至少一个候选答案与待解答问题之间的相似度。
当然,在具体实现中,也可以采用计算余弦相似度的方式计算各候选答案与待解答问题之间的相似度,本申请实施例对于计算相似度的方式不做具体限定。
本申请实施例上述步骤提及的三种模型可以是采用联合学习的方式得到的,即述三个任务均采用google的预训练bert模型作为特征提取器,因此我们考虑采用联合学习的方案实现三个任务。这里称实体识别任务为taska,子图匹配任务为taskb,文本相似度匹配任务为taskc。为统一loss函数,可将taskc中的余弦相似度目标函数改成二分类交叉熵损失函数。联合学习的目标函数是最小化loss=loss_taska+loss_taskb+loss_taskc。本申请通过同时利用联合学习的方法实现实体识别、实体消歧义以及文本匹配三个关键任务,该方法不需要引入外部语料也无需构建模板,提高问答系统的灵活性和效率。
在通过第三网络模型对至少一个候选答案和待解答问题进行相似度匹配,确定各候选答案与待解答问题的相似度之后,执行步骤212。
步骤212:根据所述相似度,从所述至少一个候选答案中确定所述待解答问题的目标答案。
目标答案是指从至少一个候选答案中选择出的待解答问题的标准答案,即将最终选择的目标答案作为待解答问题的准确答案。
具体地,可以由业务人员预先设置一个与至少一个候选答案的相似度进行比较的相似度阈值,对于相似度阈值的具体数值可以根据业务需求而定,本申请实施例对此不加以限制。在计算得到至少一个候选答案与待解答问题的相似度之后,可以结合至少一个候选答案的相似度从至少一个候选答案中选择出待解答问题的目标答案,即从至少一个候选答案中获取相似度大于相似度阈值的候选答案,并将相似度大于相似度阈值的候选答案作为目标答案。
本申请实施例通过采用子图匹配的方式进行实体消歧,无需构建模板,提高了问答系统的信息检索效率。
本申请实施例提供的信息获取方法,通过识别出待解答问题中的至少一个实体检索词,根据至少一个实体检索词进行信息检索,得到至少一个实体检索词对应的子图形式的检索文本,对子图形式的检索文本与待解答问题进行匹配,确定出目标子图形式的检索文本,根据目标子图形式的检索文本,确定待解答问题对应的至少一个候选答案,获取至少一个候选答案与待解答问题对应的相似度,根据相似度,从至少一个候选答案中确定待解答问题的目标答案。本申请实施例通过采用子图匹配的方式进行实体消歧,同时实现实体识别、实体消歧义以及文本匹配三个关键任务,该方法不需要引入外部语料也无需构建模板,提高问答系统的灵活性和效率。
参照图3,示出了本申请实施例提供的一种信息获取装置的结构示意图,该信息获取装置具体可以包括如下模块:
实体检索词识别模块310,用于识别出待解答问题中的至少一个实体检索词;
子图检索文本获取模块320,用于根据所述至少一个实体检索词进行信息检索,得到所述至少一个实体检索词对应的子图形式的检索文本;
目标子图文本确定模块330,用于对所述子图形式的检索文本与所述待解答问题进行匹配,确定出目标子图形式的检索文本;
候选答案确定模块340,用于根据所述目标子图形式的检索文本,确定所述待解答问题对应的至少一个候选答案;
相似度获取模块350,用于获取所述至少一个候选答案与所述待解答问题对应的相似度;
目标答案确定模块360,用于根据所述相似度,从所述至少一个候选答案中确定所述待解答问题的目标答案。
本申请实施例提供的信息获取装置,通过识别出待解答问题中的至少一个实体检索词,根据至少一个实体检索词进行信息检索,得到至少一个实体检索词对应的子图形式的检索文本,对子图形式的检索文本与待解答问题进行匹配,确定出目标子图形式的检索文本,根据目标子图形式的检索文本,确定待解答问题对应的至少一个候选答案,获取至少一个候选答案与待解答问题对应的相似度,根据相似度,从至少一个候选答案中确定待解答问题的目标答案。本申请实施例通过采用子图匹配的方式进行实体消歧,同时实现实体识别、实体消歧义以及文本匹配三个关键任务,该方法不需要引入外部语料也无需构建模板,提高问答系统的灵活性和效率。
参照图4,示出了本申请实施例提供的一种信息获取装置的结构示意图,该信息获取装置具体可以包括如下模块:
实体检索词识别模块410,用于识别出待解答问题中的至少一个实体检索词;
子图检索文本获取模块420,用于根据所述至少一个实体检索词进行信息检索,得到所述至少一个实体检索词对应的子图形式的检索文本;
目标子图文本确定模块430,用于对所述子图形式的检索文本与所述待解答问题进行匹配,确定出目标子图形式的检索文本;
候选答案确定模块440,用于根据所述目标子图形式的检索文本,确定所述待解答问题对应的至少一个候选答案;
相似度获取模块450,用于获取所述至少一个候选答案与所述待解答问题对应的相似度;
目标答案确定模块460,用于根据所述相似度,从所述至少一个候选答案中确定所述待解答问题的目标答案。
可选地,所述实体检索词识别模块410包括:
待解答问题获取单元411,用于获取所述待解答问题;
文本识别单元412,用于将所述待解答问题输入至第一网络模型进行文本识别;
起止位置确定单元413,用于根据文本识别结果,确定出所述待解答问题中的起止位置;
实体检索词确定单元414,用于根据所述起止位置,确定所述至少一个实体检索词。
可选地,所述子图检索文本获取模块420包括:
初始检索文本获取单元421,用于采用所述至少一个实体检索词在预置知识库中进行检索,得到与所述至少一个实体检索词关联的多个初始检索文本;
子图检索文本获取单元422,用于将所述至少一个实体检索词与所述多个初始检索文本以子图形式进行关联,得到所述子图形式的检索文本。
可选地,所述目标子图文本确定模块430包括:
句子对文本组成单元431,用于将所述子图形式的检索文本与所述待解答问题组成句子对文本;
句子对文本输入单元432,用于将所述句子对文本输入至所述第二网络模型;
目标子图文本确定单元433,用于通过所述第二网络模型对所述句子对文本进行实体消歧处理,确定所述目标子图形式的检索文本。
可选地于,所述候选答案确定模块440包括:
候选答案获取单元441,用于对所述目标子图形式的检索文本进行拆解,得到所述至少一个候选答案。
可选地,所述相似度获取模块450包括:
候选答案输入单元451,用于将所述至少一个候选答案分别与所述待解答问题输入至第三网络模型;
相似度确定单元452,用于通过所述第三网络模型对所述至少一个候选答案和所述待解答问题进行相似度匹配,确定所述至少一个候选答案与所述待解答问题的相似度。
本申请实施例提供的信息获取装置,通过识别出待解答问题中的至少一个实体检索词,根据至少一个实体检索词进行信息检索,得到至少一个实体检索词对应的子图形式的检索文本,对子图形式的检索文本与待解答问题进行匹配,确定出目标子图形式的检索文本,根据目标子图形式的检索文本,确定待解答问题对应的至少一个候选答案,获取至少一个候选答案与待解答问题对应的相似度,根据相似度,从至少一个候选答案中确定待解答问题的目标答案。本申请实施例通过采用子图匹配的方式进行实体消歧,同时实现实体识别、实体消歧义以及文本匹配三个关键任务,该方法不需要引入外部语料也无需构建模板,提高问答系统的灵活性和效率。
对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本申请并不受所描述的动作顺序的限制,因为依据本申请,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本申请所必须的。
另外地,本申请实施例还提供了一种电子设备,包括:处理器、存储器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一项所述的信息获取方法。
本申请实施例还提供了一种计算机可读存储介质,当所述存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行上述任一项所述的信息获取方法。
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上对本申请所提供的一种信息获取方法、一种信息获取装置、一种电子设备和一种计算机可读存储介质,进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 还没有人留言评论。精彩留言会获得点赞!