自动生成视觉内容的制作方法
背景技术:
可以基于文本内容来创作对应的视觉内容,以增强直观性、可读性、趣味性等。视觉内容是对文本内容的视觉化呈现,其可以采用图像、动画等形式。例如,分镜(storyboard)是一种常见的视觉内容。通常,可以将视觉内容与相关联的音频进行组合,以便生成多媒体内容。例如,动态绘本是一种示例性的多媒体内容,其通过图像、动画、声音等形式来呈现故事,其也可以被称为动画绘本、视觉故事书、动态有声书、可动绘本等。动态绘本可以包括一系列分镜,这些分镜是对文本故事中的多个语句的视觉化呈现,动态绘本还可以包括基于文本故事中的语句所生成的一系列音频,这些音频随对应的分镜一起播放。与文本故事相比,动态绘本可以通过视觉辅助来简化对文本故事的理解并且更生动地表达故事内容。
技术实现要素:
提供本发明内容以便介绍一组概念,这组概念将在以下的具体实施方式中做进一步描述。本发明内容并非旨在标识所保护主题的关键特征或必要特征,也不旨在用于限制所保护主题的范围。
本公开的实施例提出了用于自动生成视觉内容的方法和装置。可以获得文本语句。可以生成与所述文本语句对应的结构化数据。可以基于所述结构化数据,从模板库中选择模板。可以至少利用所述结构化数据来生成所述模板的配置信息。可以基于所述配置信息,从素材库中选择素材。可以通过利用所选择的素材填充所述模板来生成视觉内容。
应当注意,以上一个或多个方面包括以下详细描述以及权利要求中具体指出的特征。下面的说明书及附图详细提出了所述一个或多个方面的某些说明性特征。这些特征仅仅指示可以实施各个方面的原理的多种方式,并且本公开旨在包括所有这些方面和其等同变换。
附图说明
以下将结合附图描述所公开的多个方面,这些附图被提供用以说明而非限制所公开的多个方面。
图1示出了根据实施例的用于自动生成多媒体内容的示例性过程。
图2示出了根据实施例的基于文本内容所自动生成的视觉内容的实例。
图3示出了根据实施例的用于自动生成视觉内容的示例性过程。
图4示出了根据实施例的示例性模板网格。
图5示出了根据实施例的示例性实体尺寸。
图6示出了根据实施例的示例性实体位置。
图7示出了根据实施例的示例性景深。
图8示出了根据实施例的示例性景深。
图9示出了根据实施例的示例性定制化模板的可视化呈现。
图10示出了根据实施例的示例性实体图像库。
图11示出了根据实施例的示例性实体组件图像库。
图12示出了根据实施例的示例性背景图像库。
图13示出了根据实施例的用于自动生成视觉内容的示例性方法的流程图。
图14示出了根据实施例的用于自动生成视觉内容的示例性装置。
图15示出了根据实施例的用于自动生成视觉内容的示例性装置。
具体实施方式
现在将参考多种示例性实施方式来讨论本公开。应当理解,这些实施方式的讨论仅仅用于使得本领域技术人员能够更好地理解并从而实施本公开的实施例,而并非教导对本公开的范围的任何限制。
视觉内容通常是被人为地创作的。例如,对于给定的文本内容,可以首先人为地、逐个帧地进行构图。每一帧画面的构图可以包括人为设计的例如实体尺寸、实体位置、景深等。然后,可以根据构图,向画面中人为地添加素材,包括例如实体图像、背景图像、动画等,以便形成最终的视觉内容。上述的视觉内容创作过程中的各个环节都是人为地完成的,因此,这将是耗时且低效的。
本公开的实施例提出了利用预先准备的模板库和素材库来自动地基于文本内容生成视觉内容,并进而生成多媒体内容。在本文中,视觉内容可以包括各种类型的视觉化呈现,例如,分镜序列、图像序列、动态图像序列、动画序列等。模板库包括多个预先准备的候选模板。在本文中,模板可以指将要在视觉内容的画面中采用的一组呈现规则。素材库包括多个预先准备的素材。在本文中,素材可以指在视觉内容的画面中包含的可视化元素。在自动生成视觉内容的过程中,可以基于文本内容从模板库中选择出匹配的模板,并且根据所选择的模板从素材库中选择素材并填充到模板中以形成视觉内容。通过本公开的实施例,可以以自动的方式来快速高效地创建视觉内容。即便对于缺乏绘画或动画技能的用户,也可以容易地创作出视觉内容。所创作的视觉内容可以进一步与对应于文本内容的音频进行组合,以形成多媒体内容。
本公开的实施例可以被应用于各种基于文本内容生成多媒体内容的场景,例如,基于文本故事自动生成动态绘本、基于文本教学资料自动生成多媒体教育课件、基于文本新闻自动生成多媒体新闻、基于文本广告词自动生成动画广告等等。以下讨论主要以基于本文故事自动生成动态绘本为例来说明根据本公开实施例的自动生成视觉内容和多媒体内容的示例性过程。但是,应当理解,也可以通过类似的过程和方式来将本公开的实施例应用于任何其它场景。
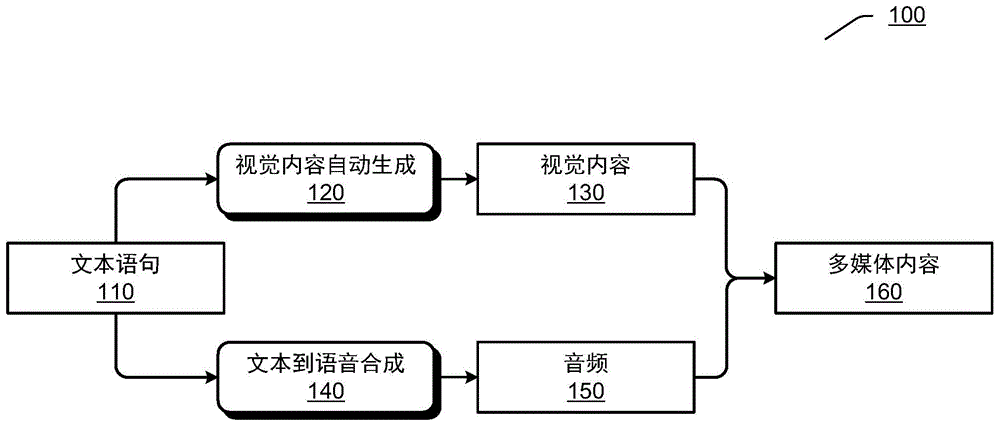
图1示出了根据实施例的用于自动生成多媒体内容的示例性过程100。过程100可以被执行用于针对文本内容中的一个文本语句生成对应的多媒体内容。文本内容可以是多个文本语句的集合,例如文本故事。每个文本语句可以是从文本内容中识别或提取的一段语意完整的表述,该段表述适于通过画面来呈现。文本语句可以包括用于描述例如时间、地点、人物、动物、物体、动作等中的至少一个的语言元素。应当理解,在本文中,文本语句可以具有与语法语句相同或不同的划分方式。语法语句通常是在语法上以例如句号等句末标点划分的,而本文中的一个文本语句则可能是一个语法语句、一个语法语句的一部分、一个以上语法语句的组合等等。
假设过程100被执行用于针对文本内容中的文本语句110生成多媒体内容。
在120处,可以基于文本语句110来执行根据本公开实施例的视觉内容自动生成过程,以便生成与文本语句110对应的视觉内容130。视觉内容130可以包括与文本语句110对应的画面,该画面可以包括图像、动画等。
在140处,可以对文本语句110执行文本到语音合成,以便生成与文本语句110对应的音频150。可以在140处采用用于从文本生成语音的任何语音合成技术。
可以通过将视觉内容130和音频150进行组合来生成与文本语句110对应的多媒体内容160。在生成多媒体内容160的过程中,可以对视觉内容130和音频150执行时序对准。例如,可以对与文本语句110对应的视觉内容130和与文本语句110对应的音频150设置相同或对应的时间戳t。从而,在生成多媒体内容160时,可以基于时间戳t来将视觉内容130和音频150对准。相应地,可以实现在呈现视觉内容130期间播放对应的音频150。应当理解,视觉内容与音频之间的时序对准可以具有广泛的含义,例如,视觉内容的持续时间落在音频的持续时间之内,音频的持续时间落在视觉内容的持续时间之内,视觉内容的起始时间比音频的起始时间早预定时间量,音频的起始时间比视觉内容的起始时间早预定时间量,等等。
应当理解,过程100可以是针对文本内容中的每个文本语句而执行的。通过对于文本内容中的所有文本语句都分别执行过程100,可以获得与整个文本内容对应的一系列多媒体内容。从而,当文本内容是例如文本故事时,可以获得与该文本故事对应的动态绘本。
图2示出了根据实施例的基于文本内容所自动生成的视觉内容的实例。
假设文本内容是一个文本故事,并且包括文本语句212“桌子上有一半西瓜”、文本语句214“汤姆说:我们把它吃了吧”、文本语句216“玛丽说:没有刀我们怎么吃呢?”等。根据本公开实施例所提出的视觉内容自动生成过程,可以自动生成分别与文本语句212、214和216对应的视觉内容222、224和226。每个视觉内容也可以被称为一个分镜。
视觉内容222包括:关于桌子的图像,其对应于文本语句212中的“桌子”;以及关于一半西瓜的图像,其对应于文本语句212中的“一半西瓜”。
视觉内容224包括:男孩图像,其对应于文本语句214中的“汤姆”;对话框图像,其中显示了文本语句214中的角色汤姆的话语;以及背景图像。
视觉内容226包括:女孩图像,其对应于文本语句216中的“玛丽”;对话框图像,其中显示了文本语句216中的角色玛丽的话语;以及背景图像。
视觉内容222、224和226以可视化的方式呈现了文本内容中的文本语句212、214和216。
应当理解,尽管未在图2中示出,也可以生成分别与文本语句212、214和216对应的音频。与文本语句212对应的音频可以与视觉内容222组合以形成第一多媒体内容,与文本语句214对应的音频可以与视觉内容224组合以形成第二多媒体内容,与文本语句216对应的音频可以与视觉内容226组合以形成第三多媒体内容。第一多媒体内容、第二多媒体内容以及第三多媒体内容可以一起组成动态绘本。
图3示出了根据实施例的用于自动生成视觉内容的示例性过程300。
根据过程300,可以获得文本语句310。例如,可以从文本内容中提取文本语句310。
根据过程300,可以通过对文本语句310进行分析,来生成与文本语句310对应的结构化数据320。结构化数据320可以包括从文本语句310中识别和提取的各种语言信息,例如场景、天气、时间、实体数量、每个实体的实体信息等中的一个或多个。场景可以指文本语句310中所描述的地点等,例如,草原、街道、公园等。天气可以包括,例如,下雨、晴朗、刮风等。时间可以包括,例如,白天、晚上等。文本语句310还可能描述了实体,例如,人、拟人化动物、原始动物、物体等。实体数量可以指文本语句310中包括的实体的数量。实体信息可以指文本语句310中对实体的描述。一个实体的实体信息可以包括以下至少之一:实体类型、实体名称、实体性别、实体年龄、实体情感、实体颜色、实体动作等。实体类型可以指实体所属于的类型,例如,人、拟人化动物、原始动物、物体等。实体名称可以指文本语句310中对该实体的称呼,例如,汤姆、玛丽、爷爷、老师、警察等。实体性别可以包括,例如,男、女等。应当理解,实体性别也可以是通过实体名称来推断出的。例如,如果一个实体的实体名称为“汤姆”,则由于该名称通常为男性的名字,可以推断出该实体的性别为男。实体年龄可以包括成年人、小孩等。应当理解,实体年龄也可以是通过实体名称来推断出的。例如,如果一个实体的实体名称为“爷爷”,则可以推断出该实体的年龄为成年人。实体情感可以是对实体的情感的描述,例如,开心、悲伤等。实体颜色可以指与实体相关联地描述的颜色,例如,从语句“玛丽穿着红裙子”中可以检测出实体“玛丽”的实体颜色为“红色”。实体动作可以指该实体所执行的动作,例如,走、跳、跑、说话等。应当理解,以上所列的结构化数据320中所包括的信息仅仅是示例性的,根据具体的应用场景和需求,可以在结构化数据320中包括更多或更少的信息。在一种实施方式中,可以通过任何预先训练的自然语言处理模型来从文本语句310中提取结构化数据320。该自然语言处理模型可以以文本语句作为输入,并且输出与该文本语句对应的结构化数据。
以文本语句“草原上下着雨,爷爷看着玛丽,玛丽开心地笑了”为例,所提取的结构化数据可以被表示为:{<场景=“草原”>,<天气=“下雨”>,<时间=“默认”>,<实体数量=2>,实体1<类型=“人”,名称=“爷爷”,性别=“男”,年龄=“成年人”,情感=“默认”,颜色=“默认”,动作=“默认”>,实体2<类型=“人”,名称=“玛丽”,性别=“女”,年龄=“小孩”,情感=“开心”,颜色=“默认”,动作=“笑”>}。应当理解,上述的结构化数据中的“默认”可以指示没有从文本语句中提取出与该条目明确对应的信息,从而可以采用任何预先规定的默认信息。
根据过程300,可以基于结构化数据320来从模板库330中选择模板340。模板库330可以包括多个预先准备的候选模板。每个候选模板可以包括将要在视觉内容的画面中采用的一组呈现规则。所述一组呈现规则可以包括该候选模板所定义的构图配置。构图配置可以规定例如实体的呈现和排布规则。例如,构图配置可以包括以下至少之一:实体位置、实体尺寸、实体朝向、实体顺序、景深(depthoffield)类型、取景位置等。模板库330中的多个候选模板可以分别对应于不同的构图配置,以便可以适用于不同的画面呈现需求。可以将一个模板所定义的呈现规则用作标签或关键词以对该模板进行标记。
在一种实施方式中,对模板340的选择可以包括首先从结构化数据320中提取构图参考信息。构图参考信息可以指能够在确定模板的构图配置过程中所参考的信息或者与构图配置相关联的信息。例如,构图参考信息可以包括以下至少之一:实体数量、实体类型、实体年龄、实体动作等。特定的构图参考信息或其组合可以对应于特定模板的构图配置。然后,可以利用构图参考信息,从模板库330中选择模板340,该模板340可以具有与从结构化数据320中提取的构图参考信息匹配的构图配置。例如,可以通过将构图参考信息与候选模板的标签或关键词进行比较或匹配,来从模板库330中检索出匹配的模板340。
为了便于理解,在图3中示出了模板340的一种示例性可视化呈现,该可视化呈现以可视化方式显示了模板340中定义的一部分呈现规则,例如,一部分构图配置。块342代表模板340所定义的构图区域,块344和346代表模板340中涉及的两个实体。块344和346的尺寸对应于两个实体各自的尺寸。如图所示,块344的尺寸大于块346的尺寸,这可能表明块344对应的实体为成年人,而块345对应的实体为小孩。块344和346在块342中的位置对应于两个实体在构图区域中各自的位置。此外,模板340还可能定义了其它不适于可视化的呈现规则,例如,块344对应的实体与块346对应的实体将在画面中出现的朝向、顺序等。此外,尽管未示出,模块340还可以定义关于景深类型、取景位置等的呈现规则。
在一种实施方式中,可选地,模板库330还可以包括定制化候选模板。定制化候选摸板可以是例如与特定实体动作对应的模板。以实体动作“说话”为例,可以预先准备对应的定制化模板,该定制化模板定义了适应于呈现实体说话画面的构图配置,例如,实体位于画面左侧三分之一处、在画面右侧三分之一的上部设置话语框等。在这种情况下,对模板340的选择可以包括首先从结构化数据320中提取实体动作,然后从模板库330中选择与该实体动作对应的定制化模板。
根据过程300,在选择了模板340后,可以生成该模板340的配置信息350。模板的配置信息可以广泛地包括该模板针对特定的文本语句所定义的呈现方案。配置信息350可以是至少利用结构化数据320来生成的。例如,配置信息350可以包括关于结构化数据320的信息,以便引导后续素材的选择和填充。利用结构化数据320来生成配置信息350的过程也可以被视为是利用文本语句310中的信息对模板340进行初始化的过程。可选地,配置信息350还可以包括用于描述模板340的构图配置的构图配置信息。应当理解,由于构图配置是预先为模板定义的且并非是特定于某个文本语句的,因此,也可以不在配置信息350中包括构图配置信息,从而使得构图配置信息350专门包含与文本语句有关的信息。
根据过程300,可以基于配置信息350来从素材库360中选择素材370。
素材库360可以包括多个预先准备的候选素材。素材可以是例如能够在视觉内容的画面中呈现的图像、动画等。素材库360中的候选素材可以是静态素材或动态素材。静态素材可以是例如图像等,而动态素材可以是例如动画等。可选地,素材库360可以包括前景图像库。前景图像库可以包括与实体相关联的静态图像。例如,前景图像库可以包括实体图像库和/或实体组件图像库。实体图像库是与各种实体对应的图像的集合。实体组件图像库是与各种类型实体的不同组件对应的图像的集合。一个或多个实体组件图像可以被用于形成一个实体图像。也就是说,一个实体的图像可以是由该实体的多个组件的图像组合成的。例如,一个人的图像可以是利用脸部图像、头型图像、身体图像、衣服图像、鞋图像等组合成的。可选地,素材库360可以包括背景图像库。背景图像库可以包括与场景、天气、时间等相关联的静态图像,例如,关于草原的图像、关于街道的图像、关于下雨的图像、关于夜晚的图像等。可选地,素材库360可以包括动画库。动画库可以包括作为动态素材的多个预先定义的动画。动画可以包括例如缩放、晃动、闪动、左淡入、右淡出等等。每个动画是由动画参数来定义的。动画参数可以包括以下至少之一:位置、时间、方向、频率等。
如前所述,配置信息350可以包括结构化数据信息,因此,可以至少基于结构化数据信息中的条目来从素材库360中选择对应的素材370。例如,对于结构化数据信息中的场景“草原”,可以从素材库360中的背景图像库中选择关于草原的图像。例如,对于结构化数据信息中的实体<类型=“人”,名称=“玛丽”,性别=“女”,年龄=“小孩”,情感=“开心”,颜色=“默认”,动作=“笑”>,可以从素材库360中的前景图像库中选择关于小女孩的图像,并且从素材库360中的动画库中选择针对实体动作“笑”的动画。
根据过程300,可以通过利用所选择的素材370填充模板340来生成视觉内容380。在一种实施方式中,可以依据模板340的构图配置来将素材370填充到模板340中。以构图配置中的实体位置为例,假设构图配置中为实体1和实体2分别规定了实体位置1和实体位置2,则可以将与实体1对应的素材填充到实体位置1处,并将与实体2对应的素材填充到实体位置2处。此外,应当理解,多个素材可以通过以例如不同图层的方式而在模板中进行堆叠,以形成最终的视觉内容画面。
为了便于理解,图3中示出了视觉内容380的示例性呈现画面,其中,块382限定了该画面的呈现区域。假设文本语句为“草原上下着雨,爷爷看着玛丽,玛丽开心地笑了”,该画面包括了背景图像“草原”与背景图像“下雨”的堆叠、人物实体384“爷爷”、人物实体386“玛丽”、表达了人物实体386的情感“开心”和动作“笑”的笑脸、等等。尽管未示出,该画面也可以包括用于呈现实体动作“笑”的动画,例如晃动等。从图3中可以看出,视觉内容380中的素材的添加遵循了模板340的构图配置。例如,人物实体384具有块344所规定的尺寸并被填充到块344所规定的位置、人物实体386具有块346所规定的尺寸并被填充到块346所规定的位置、等等。
应当理解,图3中的过程300仅仅是示例性的,根据具体的应用场景和需求,可以对过程300进行任意方式的改变。
下面将对根据本公开实施例的模板的构图配置的多个方面进行进一步的讨论。
如前所述,模板的构图配置可以规定例如实体位置、实体尺寸、取景位置等。为了便于对这些涉及位置或尺寸的参数进行规定,可以在模板中定义各种类型的网格。网格是利用网格线对模板的构图区域进行划分来实现的,并且网格和/或网格线可以以类似于坐标的方式来对位置或尺寸等进行定义。图4示出了根据实施例的示例性模板网格。图4在模板的可视化呈现中给出了多种不同类型的网格划分。在一个方面,可以通过水平网格线来将模板的构图区域划分成多个水平网格。例如,在视图412中,构图区域被8根水平网格线均匀地划分成了9个网格。在视图414中,构图区域被2根水平网格线均匀地划分成了3个网格。应当理解,本公开实施例也可以采用任何其它数量的水平网格线来将构图区域划分成任何其它数量的水平网格。在一个方面,可以通过垂直网格线来将模板的构图区域划分成多个垂直网格。例如,在视图422中,构图区域被1根垂直网格线均匀地划分成了2个网格。在视图424中,构图区域被2根垂直网格线均匀地划分成了3个网格。在视图426中,构图区域被3根垂直网格线均匀地划分成了4个网格。在视图428中,构图区域被4根垂直网格线均匀地划分成了5个网格。应当理解,本公开实施例也可以采用任何其它数量的垂直网格线来将构图区域划分成任何其它数量的垂直网格。在一个方面,可以通过交叉网格线来将模板的构图区域划分成多个交叉网格。例如,在视图432中,构图区域被2根交叉网格线均匀地划分成了4个网格。在视图434中,构图区域被4根交叉网格线均匀地划分成了9个网格。应当理解,本公开实施例也可以采用任何其它数量的交叉网格线来将构图区域划分成任何其它数量的交叉网格。此外,应当理解,一个模板的构图区域也可以是通过上述不同方式的组合来被划分成网格的。例如,可以将视图412与视图424的方式组合起来,以便在水平方向上将一个模板的构图区域划分成9个网格,同时,在垂直方向上将该模板的构图区域划分成3个网格。
模板的构图配置可以规定实体尺寸。实体尺寸可以关联于例如实体类型、实体名称、实体年龄等中的一个或多个。对于同一种实体类型的实体,可以基于实体名称、实体年龄等来定义不同的相对尺寸。例如,如果一个实体的类型为“人”且名称为“爷爷”,则该实体可以具有“成年人”尺寸。如果一个实体的类型为“人”且年龄为“小孩”,则该实体可以具有“小孩”尺寸,其小于“成年人”尺寸。例如,如果一个实体的类型为“原始动物”且名称为“老虎”,另一个实体的类型为“原始动物”且名称为“猪”,则该原始动物“老虎”的尺寸可以大于该原始动物“猪”的尺寸。此外,在不同实体类型的实体之间,也可以定义不同的相对尺寸。例如,如果实体类型为“拟人化动物”、实体名称为“猫”且实体年龄为“成年”,则该拟人化动物“猫”的尺寸可以参照“人”的尺寸来定义,例如,该拟人化动物“猫”的尺寸可以对应于实体类型“人”中的“小孩”的尺寸。例如,如果实体类型为“原始动物”且实体名称为“猫”,则该原始动物“猫”的尺寸可以参照拟人化动物“猫”的尺寸来定义,例如,该原始动物“猫”的尺寸可以是拟人化动物“猫”的尺寸的一半。
图5示出了根据实施例的示例性实体尺寸。在图5中以模板的呈现区域被划分成9个水平网格为例示出了对不同实体所定义的尺寸。应当理解,也可以以任何其它网格划分方式来定义实体尺寸。实体502是成年人,其尺寸可以被定义为8个水平网格高度。实体504是小孩,其尺寸可以被定义为7个水平网格高度,小于成年人的尺寸。实体506是拟人化成年动物,其尺寸可以被定义为7个水平网格高度,等于小孩的尺寸。实体508是拟人化幼年动物,其尺寸可以被定义为6个水平网格高度,小于拟人化成年动物。实体510、512、514、516分别是原始动物“大象”、“老虎”、“猪”、“兔子”,可以根据这些原始动物的相对大小而对这些实体分别定义不同的水平网格高度。实体518是物体“桌子”,其尺寸可以被定义为4个水平网格高度,小于小孩的尺寸。实体520是物体“足球”,其尺寸可以被定义为2个水平网格高度。应当理解,尽管图5中以水平网格的数量来定义实体的高度并进而定义实体尺寸,但是也可以通过垂直网格的数量来定义实体的宽度并进而定义实体尺寸。此外,图5中的所有实体尺寸都是示例性的,也可以在模板中以任何其它方式来为不同的实体定义尺寸。
模板的构图配置可以规定实体位置。实体位置可以关联于例如实体数量、实体年龄等中的一个或多个。例如,不同的实体数量可以决定这些实体在构图区域中的不同水平位置、不同的实体年龄可以决定这些实体在构图区域中的不同垂直位置、等等。在一种实施方式中,可以利用水平网格线和/或垂直网格线来定义实体位置。
图6示出了根据实施例的示例性实体位置。假设在构图区域610中包括两个实体612和614,其中,实体612可以是成年人,实体614可以是小孩。在将构图区域划分为示例性的9个水平网格的情况下,实体612的上边缘可以位于第1根水平网格线处且下边缘位于第8根水平网格线处,即,实体612的水平位置是在构图区域的上端1/9部分与构图区域的下端1/9部分之间。实体614的上边缘可以位于第2根水平网格线处且下边缘位于第8根水平网格线处,即,实体612的水平位置是在构图区域的上端2/9部分与构图区域的下端1/9部分之间。此外,在将构图区域划分为示例性的3个垂直网格的情况下,实体612的中线可以位于左侧第1根垂直网格线上,即,实体612的垂直位置是在构图区域的左侧1/3处。实体614的中线可以位于右侧第1根垂直网格线上,即,实体614的垂直位置是在构图区域的右侧1/3处。
模板的构图配置可以规定实体朝向。在本文中,实体朝向可以指实体的脸部的方向,例如,向左半侧脸、向左侧脸、向右半侧脸、向右侧脸、正脸等。实体朝向可以关联于例如实体数量。例如,当只有一个实体时,可以规定该实体具有预定的实体朝向,例如向左半侧脸。当有两个实体时,可以规定左侧实体的实体朝向为例如向左半侧脸,而右侧实体的实体朝向为例如向右半侧脸。当有三个实体时,可以规定左侧的两个实体的实体朝向为例如向左半侧脸,而右侧实体的实体朝向为例如向右半侧脸。应当理解,以上的实体朝向都是示例性的,可以在模板中为不同数量的实体定义任何其它类型的实体朝向。
模板的构图配置可以规定实体顺序。在本文中,实体顺序可以指两个或更多实体在画面中呈现的时间次序。实体顺序可以关联于例如不同实体在文本语句中出现的先后次序。例如,假设文本语句为“爷爷站在河边,玛丽走了过来”,在该文本语句中首先描述了实体“爷爷”,然后描述了实体“玛丽”,因此,在构图配置中可以规定首先呈现实体“爷爷”,然后呈现实体“玛丽”。
模板的构图配置可以规定景深类型和取景位置。景深类型可以包括不同的取景方式,例如全身、半身、特写、远景等。可以通过在模板的构图区域中定义不同位置或尺寸的取景框来实现不同类型的景深。景深类型可以关联于例如实体数量、实体动作等中的至少一个。例如,如果实体数量为1,则可以采用景深类型“半身”。如果实体数量为2,则可以采用景深类型“全身”。如果实体数量为1且实体动作为“走路”,则可以采用景深类型“全身”。如果实体数量为3且实体动作为“踢球”,则可以采用景深类型“远景”等。不同的景深类型决定了不同的取景位置。取景位置可以广泛地指取景框的位置或尺寸,其可以关联于例如景深类型、实体尺寸等中的至少一个。例如,如果景深类型为“半身”,则取景框的位置可以在实体的上半身的区域,且取景框的尺寸可以适合于包围实体的上半身。例如,如果景深类型为“全身”,则取景框的位置可以在实体的全身的区域,且取景框的尺寸可以适合于包围整个实体。
图7示出了根据实施例的示例性景深。图7旨在说明对于实体类型为人、拟人化动物等的示例性取景方式。作为示例,在一个模板的构图区域710中定义了一个实体712,该实体712可以是例如成年人。可以确定在该模板中采用景深类型“半身”,并且在构图区域710中定义了取景框714。示例性的画面716是基于该模板所生成的,其中,以半身景深示出了实体。作为示例,在一个模板的构图区域720中定义了一个实体722,该实体722可以是例如小孩,其尺寸小于实体712的尺寸。可以确定在该模板中采用景深类型“半身”,并且在构图区域720中定义了取景框724。可以看出,取景框724的位置略低于取景框714的位置,以便适应于实体722的尺寸。示例性的画面726是基于该模板所生成的,其中,以半身景深示出了实体。作为示例,在一个模板的构图区域730中定义了两个实体732和734,实体732和734可以是例如成年人。可以确定在该模板中采用景深类型“全身”,并且在构图区域730中定义了取景框736。可以看出,取景框730的尺寸基本等于构图区域730的尺寸,以便能够完整地包围实体732和724两者。示例性的画面738是基于该模板所生成的,其中,以全身景深示出了两个实体。
图8示出了根据实施例的示例性景深。图8旨在说明对于实体类型为物体、原始动物等的示例性取景方式。作为示例,在一个模板的构图区域810中定义了一个实体812,该实体812可以是例如某种物体。可以确定在该模板中采用景深类型“特写”,并且在构图区域810中定义了取景框814。该取景框814的位置在构图区域810的中下部,并且该取景框的尺寸可以包围实体812。在一种实施方式中,在取景框814与实体812之间可以保留预定的空白区域。示例性的画面816是基于该模板所生成的,其中,以特写景深示出了实体。可以看出,在画面816中,与在取景框814与实体812之间保留的预定空白区域相对应地,在实体与画面816的呈现区域的边框之间也保留了预定的空白区域,以便实现更好的视觉效果。应当理解,实体可能具有各种形状和尺寸。在这种情况下,取景框可以优先在实体的具有较大尺寸的维度方向上保留足够的预定的空白区域。作为示例,在一个模板的构图区域820中定义了一个实体822,该实体822的纵轴尺寸大于横轴尺寸。在构图区域820中定义了取景框824。该取景框824可以参考实体822的纵轴尺寸来保留预定的空白区域。示例性的画面826是基于该模板所生成的,其中,与在取景框824与实体822之间保留的预定空白区域相对应地,在实体与画面826的呈现区域的边框之间也保留了预定的空白区域。作为示例,在一个模板的构图区域830中定义了一个实体832,该实体832的横轴尺寸大于纵轴尺寸。在构图区域830中定义了取景框834。该取景框834可以参考实体832的横轴尺寸来保留预定的空白区域。示例性的画面836是基于该模板所生成的,其中,与在取景框834与实体832之间保留的预定空白区域相对应地,在实体与画面836的呈现区域的边框之间也保留了预定的空白区域。
应当理解,在模板中针对实体所规定的景深类型和取景位置也同时被施加于背景图像。例如,假设背景图像平铺于模板的构图区域,则只有落在取景框所包围的区域中的背景图像部分会呈现在最终的视觉内容的画面中。
如前所述,模板库可以包括定制化候选模板。定制化候选摸板可以是例如与特定实体动作对应的模板。图9示出了根据实施例的示例性定制化模板的可视化呈现。图9以与实体动作“说话”对应的定制化模板为例。应当理解,本公开的实施例还可以包括针对任何其它实体动作的定制化模板。作为示例,假设文本语句中涉及一个实体在讲话,则可以在构图区域910中定义实体912、话语框914等,其中,在话语框914中可以呈现实体912所说的话语。实体912可以示例性地位于模板的垂直中线上,并且实体朝向为向左半侧脸。话语框914可以示例性地位于实体912的右上方。此外,在构图区域910中还定义了取景类型“半身”以及取景框916。作为示例,假设文本语句中涉及两个实体之间的对话。可以在针对首先说话的实体的模板的构图区域920中定义实体922、话语框924等。实体922可以示例性地位于模板的左侧1/3处,并且实体朝向为向左半侧脸。话语框924可以示例性地位于实体922的右上方。此外,在构图区域920中还定义了取景类型“半身”以及取景框926。可以在针对随后说话的实体的模板的构图区域930中定义实体932、话语框934等。实体932可以示例性地位于模板的右侧1/3处,并且实体朝向为向右半侧脸。话语框934可以示例性地位于实体932的左上方。此外,在构图区域930中还定义了取景类型“半身”以及取景框936。
下面将对根据本公开实施例的素材库的多个方面进行进一步的讨论。
素材库可以包括多个预先准备的候选素材。这些候选素材可以是基于各种可能的模板配置信息来准备的。模板配置信息可能包括例如场景、天气、时间、实体数量、实体类型、实体名称、实体性别、实体年龄、实体情感、实体颜色、实体动作、实体位置、实体尺寸、实体朝向、实体顺序、景深类型、取景位置等各种信息,从而可以分别针对每种模板配置信息或者一种或多种模板配置信息的组合来准备素材。候选素材可以是预先人为创作的,或者从任何类型的图像源提取的。
素材库可以包括与实体相关联的前景图像库。前景图像库可以包括例如实体图像库、实体组件图像库等。图10示出了根据实施例的示例性实体图像库。实体图像库可以是各种实体的图像的集合。例如,实体图像库可以包括关于人的一组图像1010、关于拟人化动物的一组图像1020、关于原始动物的一组图像1030、关于物体的一组图像1040等。实体图像库中的每个实体图像可以附有描述信息,包括例如名称、性别、年龄、情感、尺寸等。对实体图像的描述信息可以被用于与模板配置信息进行比较和匹配,以便可以基于模板配置信息来选择对应的实体图像。图11示出了根据实施例的示例性实体组件图像库。实体组件图像库是与各种类型实体的不同组件对应的图像的集合。一个或多个实体组件图像可以被用于形成一个实体图像。在图11中以关于实体类型“人”为例示出了涉及人的组件的多个实体组件图像。例如,实体组件图像库可以包括关于脸部的一组图像1110、关于头型的一组图像1120、关于衣服的一组图像1130、关于鞋的一组图像1140、关于身体的一组图像1150等。实体组件图像库中的每个实体组件图像可以附有描述信息,包括例如名称、颜色、尺寸、性别等。对实体组件图像的描述信息可以被用于与模板配置信息进行比较和匹配,以便可以基于模板配置信息来选择对应的实体组件图像并组合成实体图像。例如,假设模板配置信息中描述了关于实体“玛丽”的多种信息,如“小孩”、“女”、“红裙子”、“短发”、“红鞋”等,则可以从所述一组图像1110中选择关于女孩的脸部图像1112、从所述一组图像1120中选择关于短发的头型图像1122、从所述一组图像1130中选择关于红裙子的衣服图像1132、从所述一组图像1140中选择关于红鞋的鞋图像1142、并且从所述一组图像1150中选择关于小女孩的身体图像1152。通过对所选择的脸部图像1112、头型图像1122、衣服图像1132、鞋图像1142、以及身体图像1152进行组合,可以形成对应于实体“玛丽”的实体图像1160。应当理解,本公开的实施例并不局限于图10和图11所示的实体图像和实体组件图像,还可以包括任何其它实体图像和实体组件图像。
素材库可以包括背景图像库。背景图像库可以包括与例如场景、天气、时间等相关联的图像。图12示出了根据实施例的示例性背景图像库。例如,背景图像1202是关于场景“家”的,背景图像1204是关于场景“教室”的,背景图像1206是关于场景“家”和时间“夜晚”的,背景图像1208是关于时间“夜晚”的,背景图像1210和1212是关于场景“森林”的,背景图像1214是关于场景“街道”的,背景图像1210是关于场景“公园的,等等。背景图像库中的每个背景图像可以附有描述信息,包括例如场景、天气、时间等。对背景图像的描述信息可以被用于与模板配置信息进行比较和匹配,以便可以基于模板配置信息来选择对应的背景图像。应当理解,本公开的实施例并不局限于图12所示的背景图像,还可以包括任何其它背景图像。
素材库可以包括动画库。动画库可以包括多个预先定义的动画。每个动画可以是由例如位置、时间、方向、频率等动画参数来定义的。位置参数可以指示该动画是否导致位移。如果导致位移,则位置参数进一步包括该位移的起始位置和终止位置。例如,对于动画“左淡入”,位置参数可以定义,例如,起始位置为构图区域的左侧边缘、终止位置为构图区域的中心线等。时间参数可以指示该动画的起始时间和终止时间。例如,起始时间可以是呈现画面的时刻、播放音频的时刻、在播放音频时刻之后的预定时刻、在播放音频时刻之前的预定时刻、等等。终止时间可以是例如完成音频播放的时刻、在完成音频播放的时刻之前或之后的预定时刻、等等。方向参数可以指示该动画所导致的位移的方向,例如,向左、向右、向右下、等等。频率参数可以指呈现该动画的频率。例如,对于动画“闪动”,频率参数可以规定例如每秒闪动的次数等。在一种实施方式中,当描述实体动作的词语为例如实义动词时,可以随机地选择动作位移较大的动画,而当描述实体动作的词语为例如系动词时,可以随机地选择动作位移较小的动画。
应当理解,动画库中还可以包括一些与预定实体动作对应的定制化动画。这些预定实体动作可以是一些高频动作,例如,说话、走、跳、跑、笑、等等。例如,对于实体动作“跳”,定制化动画可以为“闪动”,其动画参数可以指示位移的起始位置和终止位置、方向为向上和向下、频率为每秒2次等。当模板配置信息中包括一种预定实体动作时,可以从动画库中直接选择与该预定实体动作对应的定制化动画。
图13示出了根据实施例的用于自动生成视觉内容的示例性方法1300的流程图。
在1310处,可以获得文本语句。
在1320处,可以生成与所述文本语句对应的结构化数据。
在1330处,可以基于所述结构化数据,从模板库中选择模板。
在1340处,可以至少利用所述结构化数据来生成所述模板的配置信息。
在1350处,可以基于所述配置信息,从素材库中选择素材。
在1360处,可以通过利用所选择的素材填充所述模板来生成视觉内容。
在一种实施方式中,所述结构化数据可以包括以下至少之一:场景、天气、时间、实体数量、以及每个实体的实体信息。所述实体信息可以包括以下至少之一:实体类型、实体名称、实体性别、实体年龄、实体情感、实体颜色、以及实体动作。所述实体可以包括以下至少之一:人、拟人化动物、原始动物、以及物体。
在一种实施方式中,所述选择模板可以包括:从所述结构化数据中提取构图参考信息;以及利用所述构图参考信息,从所述模板库中选择所述模板,其中,所述模板具有与所述构图参考信息匹配的构图配置。所述构图参考信息可以包括以下至少之一:实体数量、实体类型、实体年龄、以及实体动作。所述构图配置可以包括以下至少之一:实体位置、实体尺寸、实体朝向、实体顺序、景深类型、以及取景位置。所述模板的配置信息还可以包括关于所述构图配置的构图配置信息。
在一种实施方式中,所述选择模板可以包括:从所述结构化数据中提取实体动作;以及从所述模板库中选择与所述实体动作对应的定制化模板。
在一种实施方式中,所述素材库可以包括前景图像库和背景图像库。所述前景图像库可以包括以下至少之一:实体图像库;以及实体组件图像库,其中,一个或多个实体组件图像被用于形成实体图像。
在一种实施方式中,所述素材库可以包括动画库,所述动画库包括多个预先定义的动画,并且每个动画的动画参数包括以下至少之一:位置、时间、方向、以及频率。所述多个预先定义的动画可以包括:与预定实体动作对应的定制化动画。
在一种实施方式中,所述视觉内容可以是分镜。
在一种实施方式中,方法1300还可以包括:生成与所述文本语句对应的音频;以及通过组合所述视觉内容和所述音频来生成多媒体内容。
应当理解,方法1300还可以包括根据上述本公开实施例的用于自动生成视觉内容的任何步骤/过程。
图14示出了根据实施例的用于自动生成视觉内容的示例性装置1400。
装置1400可以包括:文本语句获得模块1410,用于获得文本语句;结构化数据生成模块1420,用于生成与所述文本语句对应的结构化数据;模板选择模块1430,用于基于所述结构化数据,从模板库中选择模板;配置信息生成模块1440,用于至少利用所述结构化数据来生成所述模板的配置信息;素材选择模块1450,用于基于所述配置信息,从素材库中选择素材;以及视觉内容生成模块1460,用于通过利用所选择的素材填充所述模板来生成视觉内容。
在一种实施方式中,所述结构化数据可以包括以下至少之一:场景、天气、时间、实体数量、以及每个实体的实体信息。所述实体信息可以包括以下至少之一:实体类型、实体名称、实体性别、实体年龄、实体情感、实体颜色、以及实体动作。
在一种实施方式中,所述模板选择模块1430可以用于:从所述结构化数据中提取构图参考信息;以及利用所述构图参考信息,从所述模板库中选择所述模板,其中,所述模板具有与所述构图参考信息匹配的构图配置。所述构图参考信息可以包括以下至少之一:实体数量、实体类型、实体年龄、以及实体动作。所述构图配置可以包括以下至少之一:实体位置、实体尺寸、实体朝向、实体顺序、景深类型、以及取景位置。
在一种实施方式中,所述模板选择模块1430可以用于:从所述结构化数据中提取实体动作;以及从所述模板库中选择与所述实体动作对应的定制化模板。
在一种实施方式中,所述素材库可以包括前景图像库、背景图像库以及动画库。所述前景图像库可以包括以下至少之一:实体图像库;以及实体组件图像库,其中,一个或多个实体组件图像被用于形成实体图像。所述动画库可以包括多个预先定义的动画,并且每个动画的动画参数包括以下至少之一:位置、时间、方向、以及频率。所述多个预先定义的动画可以包括:与预定实体动作对应的定制化动画。
此外,装置1400还可以包括被配置用于根据上述本公开实施例的自动生成视觉内容的任何其它模块。
图15示出了根据实施例的用于自动生成视觉内容的示例性装置1500。
装置1500可以包括至少一个处理器1510和存储计算机可执行指令的存储器1520。当执行计算机可执行指令时,至少一个处理器1510可以:获得文本语句;生成与所述文本语句对应的结构化数据;基于所述结构化数据,从模板库中选择模板;至少利用所述结构化数据来生成所述模板的配置信息;基于所述配置信息,从素材库中选择素材;以及通过利用所选择的素材填充所述模板来生成视觉内容。至少一个处理器1510还可以被配置用于执行根据上述本公开实施例的用于自动生成视觉内容的方法的任何操作。
本公开的实施例可以实施在非暂时性计算机可读介质中。非暂时性计算机可读介质可以包括指令,当指令被执行时,使得一个或多个处理器执行根据上述本公开实施例的用于自动生成视觉内容的方法的任何操作。
应当理解,以上描述的方法中的所有操作都仅仅是示例性的,本公开并不限制于方法中的任何操作或这些操作的顺序,而是应当涵盖在相同或相似构思下的所有其它等同变换。
还应当理解,以上描述的装置中的所有模块都可以通过各种方式来实施。这些模块可以被实施为硬件、软件、或其组合。此外,这些模块中的任何模块可以在功能上被进一步划分成子模块或组合在一起。
已经结合各种装置和方法描述了处理器。这些处理器可以使用电子硬件、计算机软件或其任意组合来实施。这些处理器是实施为硬件还是软件将取决于具体的应用以及施加在系统上的总体设计约束。作为示例,本公开中给出的处理器、处理器的任意部分、或者处理器的任意组合可以实施为微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑器件(pld)、状态机、门逻辑、分立硬件电路、以及配置用于执行在本公开中描述的各种功能的其它适合的处理部件。本公开给出的处理器、处理器的任意部分、或者处理器的任意组合的功能可以实施为由微处理器、微控制器、dsp或其它适合的平台所执行的软件。
软件应当被广泛地视为表示指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、运行线程、过程、函数等。软件可以驻留在计算机可读介质中。计算机可读介质可以包括例如存储器,存储器可以例如为磁性存储设备(如,硬盘、软盘、磁条)、光盘、智能卡、闪存设备、随机存取存储器(ram)、只读存储器(rom)、可编程rom(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、寄存器或者可移动盘。尽管在本公开给出的多个方面中将存储器示出为是与处理器分离的,但是存储器也可以位于处理器内部,如,缓存或寄存器。
以上描述被提供用于使得本领域任何技术人员可以实施本文所描述的各个方面。这些方面的各种修改对于本领域技术人员是显而易见的,本文限定的一般性原理可以应用于其它方面。因此,权利要求并非旨在被局限于本文示出的方面。关于本领域技术人员已知或即将获知的、对本公开所描述各个方面的元素的所有结构和功能上的等同变换,都将由权利要求所覆盖。
- 还没有人留言评论。精彩留言会获得点赞!