一种实时数据存储方法、设备、存储介质与流程
本发明涉及信息处理技术领域,尤其涉及一种实时数据存储方法、设备、存储介质。
背景技术:
随着大数据技术的发展,计算引擎不断优化和更新已经基本解决引擎的瓶颈。但随着数据量的增加,数据如何高效存储也是一个重要话题,数据实时和高效存储也显得非常重要。数据抽取工具也有很多,例如:sqoop、datax等;可供选择的文件结构的有parquet、orc、txt、csv等,其中parquet是业界比较公认大数据文件结构,压缩比高,存储快。如果采用流式(实时)计算存储数据时,把数据可以存储为parquet文件,能很快的存储到数据仓库,但是同时会形成非常多小文件,基本是一条记录生成一条小文件,导致数据文件占用空间大、计算引擎的计算速度大幅度减慢,降低了数据存储的效率。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种实时数据存储方法、设备及其存储介质,实现高效实时文件存储,降低数据文件占用的空间,提高计算引擎的计算速度。
本发明的目的之一采用如下技术方案实现:
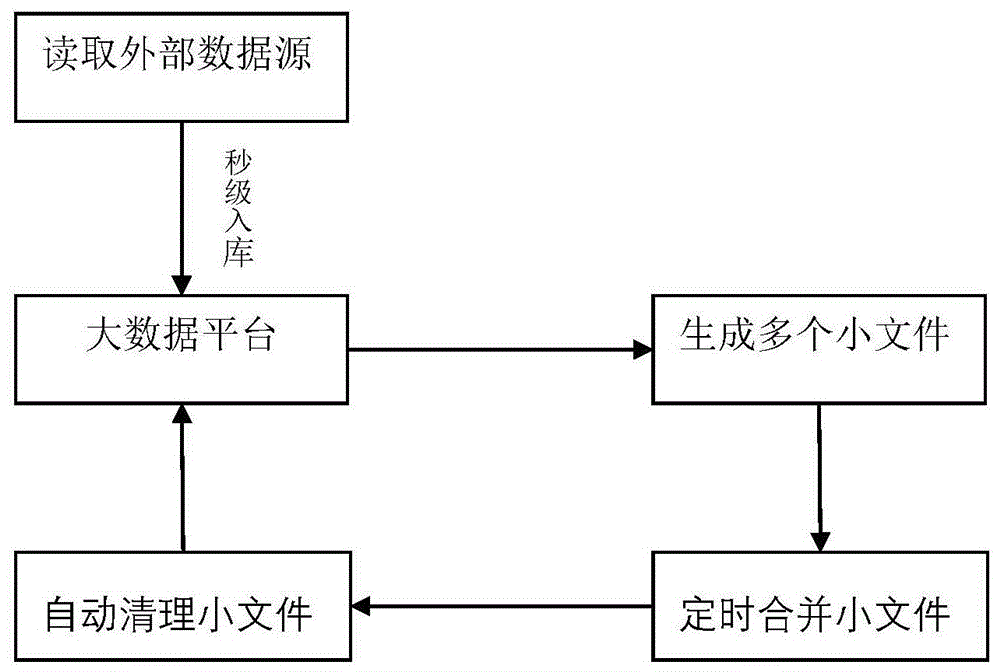
一种实时数据存储的方法,包括以下步骤:
s1、实时读取外部流式数据源数据,并保存至大数据平台,生成多个小文件;
s2、定时启动合并程序,合并所述小文件;
s3、通过多线程读取所述小文件,将所述小文件多线程合并成预设大小的数据文件;
s4、自动删除大数据平台中的小文件。
进一步地,所述外部流式数据源为kafka集群。
进一步地,所述小文件为parquet文件结构。
进一步地,s3中,将所述小文件分批合并至64m。
进一步地,s2中每个小时启动合并程序。
进一步地,s1中通过sparkstreaming流式并发实时读取数据源数据。
进一步地,所述数据源为外部流式数据源。
进一步地,所述大数据平台每秒读取外部流式数据源数据。
本发明的目的之二采用如下技术方案实现:
一种设备,其包括处理器、存储器及存储于所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述的一种实时数据存储的方法。
本发明的目的之三采用如下技术方案实现:
一种存储介质,其上存储有计算机程序,所述计算机程序被执行时实现权利要求如上所述的一种实时数据存储的方法。
相比现有技术,本发明的有益效果在于:
本发明提供了一种实时数据存储的方法、设备、存储介质,在大数据分析处理过程中,实时读取外部数据源的数据,将外部数据源生成多个小文件,将小文件合并且定时清除,提高计算速率,为数据分析提供了较好的数据环境,缩短数据处理周期,降低数据文件占用的空间。
附图说明
图1为本发明所提供实施例一的流程示意图;
图2为本发明所提供实施例一的示意图;
图3为本发明所提供实施例二的结构示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
如图1所示,本发明提供了一种实时数据存储的方法,包括以下步骤:s1、实时读取外部流式数据源,并保存至大数据平台,生成多个小文件;
s2、定期启动合并程序,合并所述小文件;
s3、通过多线程读取所述小文件,将所述小文件定时合并成预设大小的数据文件;
s4、自动删除大数据平台中的小文件。
本申请提供实时数据存储的方法,在大数据分析处理过程中,实时读取外部数据源的数据,将外部数据源生成多个小文件,将小文件合并且定时清除,提高计算速率,为数据分析提供了较好的数据环境,缩短数据处理周期,降低数据文件占用的空间。
具体的,该方法是基于kafka平台,kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据,统一线上和离线的消息处理,通过集群提供实时消息。在kafka平台集群上通过sparkstreaming读取外部流式数据源数据,并保存至大数据平台中。sparkstreaming是spark生态系统当中一个重要的框架,它建立在sparkcore之上,sparkstreaming是sparkcore的扩展应用,它具有可扩展,高吞吐量,对于流数据的可容错性等特点。可以监控来自kafka平台等数据,通过复杂的算法以及一系列的计算分析数据,并且可以将分析结果存入到hdfs文件系统,数据库以及前端页面中,。在本申请中,使用其流式读取数据源,低延迟,可以在秒级别上对数据进行处理,达到秒级读取。完成数据读取后,保存至大数据平台,生成多个小文件。在本实施例中,所述小文件为parquet文件结构。
如图2所示,为本申请实施例应用的示意图。企业服务端,即为消息的生产者推送数据至kafka平台的代理,即kafka-broker进行数据的缓存。zookeeper对kafka-broker进行管理,当kafka平台中新增了代理或某个代理失效时,zookeeper服务将通知消息生产者和消息消费者。消息生产者与消息消费者据此开始与其他代理协调工作。消息消费者程序从kafka-broker拉取企业服务端产生的数据至大数据平台,由大数据平台读取、保存,在上述过程中会累积大量小文件,占用数据的存储空间,因此需要定时启动合并程序,合并小文件,将小文件分批合并成预设大小的数据文件。若是没有定时合并,则会累积多个的小文件,后期需要占用大量资源进行合并。每个小时多线程合读取所述小文件,分批合并至64m大小的数据文件,保持数据文件内的内容与小文件的内容不变,但合并后的文件所需存储空间远小于合并前小文件所需的存储空间,不影响整个大数据的分析和计算。合并后的数据文件比这样可整个大数据处理提速,缩短数据处理的周期,避免后期占用过多资源。合并完成后,自动删除大数据平台中的小文件,仅保存合并后的数据文件,降低所需的存储空间。
另外,本发明还提供一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现前述一种实时数据存储的方法的步骤。
其中,计算机程序包括计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读介质可以包括:能够携带计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、计算机存储器(磁盘)、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)以及分布式文件系统hdfs等。需要说明的是,计算机可议介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
本发明可用于众多通用或专用的计算系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、机顶盒、可编程的消费电子设备、网络pc、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等,如实施例二。
实施例二
一种设备,如图3所示,包括存储器、处理器以及存储在存储器中的程序,所述程序被配置成由处理器执行,处理器执行所述程序时实现上述一种实时数据存储的方法步骤。
处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,处理器是智能门锁的控制中心,利用各种接口和线路连接述一种智能锁的设置方法的各个部分。
存储器可用于存储计算机程序和/或模块,处理器通过运行或执行存储在存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现一种实时数据存储的方法。存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所倡的应用程序(比如声音播放功能、图像播放功能等)等;存储据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flash-card)至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
本发明可用于众多通用或专用的云计算环境和大数据环境中。例如:大数据平台、服务器集群环境、大数据分析计算,用户高并发、集群计算等场景中得到应用。
- 还没有人留言评论。精彩留言会获得点赞!