一种基于孪生网络的针对模糊目标的跟踪方法与流程
本发明涉及深度学习和计算机视觉技术,具体涉及一种基于孪生网络的针对模糊目标的跟踪方法。
背景技术:
视觉跟踪在计算机视觉中起着至关重要的作用。它是智能视频监视,现代军事,智能交通和视觉导航领域中许多高级应用程序的重要组成部分。尽管跟踪问题已经研究了很长时间,但是由于跟踪问题的复杂性以及诸如变形、照明变化、比例变化、遮挡、背景杂乱和运动模糊等外部挑战,使得跟踪仍然是一项非常困难的任务。过去,人们一直在努力建立鲁棒的外观模型以进行跟踪,以解决变形、比例尺变化和遮挡的问题。但是,大多数现有的跟踪算法并未明确考虑视频序列中包含的运动模糊。实际上,运动模糊是一个常见的问题,尤其是在诸如无人机或吊舱之类的应用中,运动模糊很可能与其他挑战一起出现,这会降低这些应用场景中跟踪算法的性能。
近年来,由于去模糊算法和跟踪技术在深度学习方向上的发展,将去模糊方法应用到跟踪领域变成可能。首先,对抗生成网络已经运用到去模糊算法上并取得良好的效果。而孪生网络由于其稳定性、准确性和速度快的优势,在跟踪领域应用很广泛。由于对抗生成网络和孪生网络的优势,我们将生成网络应用到跟踪系统中用以提高对模糊目标跟踪的性能。
技术实现要素:
本发明所要解决的技术问题是,提高跟踪器对模糊目标跟踪的性能,提出了一种基于孪生网络的目标跟踪方法,通过将对抗生成网络和孪生网络有效结合,提高跟踪器对模糊目标跟踪时的精读及鲁棒性,从而有效解决上述问题。
为了实现上述目的,本发明提供了一种基于孪生网络的针对模糊目标的跟踪方法,包括以下步骤:
步骤1:根据清晰图像集生成模糊图像集,分别对清晰图像集、模糊图像集进行预处理,得到预处理后清晰图像集和预处理后模糊图像集;
步骤2:构建去模糊对抗生成网络,通过对抗损失、内容损失构建去模糊对抗生成网络的总损失函数,结合预处理后清晰图像集以及预处理后模糊图像来训练去模糊对抗生成网络,得到训练后去模糊对抗生成网络;
步骤3:通过多个图像序列构建训练样本,通过人工标记法对图像序列中图像标记目标矩形框;
步骤4:训练样本中每幅图像根据目标区域的图像尺寸进行截取得到目标区域样本,训练样本中每幅图像根据搜索区域的图像尺寸进行截取得到搜索区域样本,将搜索区域样本中每幅图像的像素点标记出是否为目标位置;
步骤5:通过目标区域分支以及搜索区域分支构建孪生网络,根据相似度分数矩阵构建孪生网络的损失函数,通过目标区域样本以及搜索区域样本进行训练得到训练后孪生网络;
步骤6:将待跟踪图像序列通过训练后去模糊对抗生成网络以及训练后跟踪孪生网络进行图像跟踪,得到待跟踪图像序列的目标坐标位置。
作为优选,步骤1所述根据清晰图像集生成模糊图像集为:
清晰图像集选择高帧率图像数据集,通过运动模糊退化模型,将清晰图像集中连续m′帧的清晰图像合成为一幅模糊图像,并选取m′帧清晰图像的中间一帧作为相对应的清晰图像。光学感应器的成像信息用如下积分函数表示:
其中,t表示曝光总时间,s(t)表示曝光时刻t记录的影像信息,i表示成像信息,在成像后还需要经过成像设备响应函数将图像信息映射到合适的像素值;
伽马函数近似于成像设备响应函数,光学系统获得的图像像素值可以表示为:
l=g(i)
其中g(·)表示伽马函数,也表示成像设备响应函数,l表示图像亮度值。
通过混合相邻m′帧的成像信息,可模拟模糊图像的成像信息,模糊图像的成像信息可用如下公式表示:
最后,再对模糊图像的成像信息iblurry经过成像设备响应函数,则可得到模糊图像。定义为:
伽马变换定义为:
g(x)=x1/γ
每m′帧清晰图像s(·)通过上述变换后即可得到一帧模糊图像,模糊图像放入模糊图像集中,从m′帧清晰图像中选取一帧放入清晰图像集中;
所述裁减处理为:
将所述清晰图像集中每幅清晰图像通过裁减处理,使得每幅清晰图像的长和宽均为k,得到步骤1所述预处理后清晰图像集,即psharp(s);
将所述模糊图像集中每幅模糊图像通过裁减处理,使得每幅模糊图像的长和宽均为k,得到步骤1所述预处理后模糊图像集,即pblurry(b);
作为优选,步骤2所述去模糊对抗生成网络由生成器、判别器构成;
所述生成器包含:卷积层、归一化层、激活函数层;
所述生成器的输入为预处理后模糊图像集即pblurry(b),若b属于模糊图像集中的图像,即b∈pblurry(b),b经过生成器得到的图像记为g(b);
所述判别器包含:卷积层、归一化层、激活函数层;
所述判别器的输入为生成器生成的图像g(b),或者清晰的图像s,其中s∈psharp(s),最后得到长宽尺寸为m的矩阵;
步骤2所述对抗损失通过wasserstein距离来定义,具体如下;
其中,s属于清晰图像集中的图像,s~psharp(s)表示s穷举清晰图像集所有图像。b属于模糊图像集中的图像,b~pblurry(b)表示b穷举模糊图像集所有图像。d(s)表示判别器对图像s的输出,d(g(b))表示判别器对所生成图像g(b)的输出,e表示期望值;
步骤2所述内容损失使用l2距离进行定义,即均方误差来定义,具体如下:
lmse=||s-g(b)||2
步骤2所述去模糊对抗生成网络的总损失定义为:
l=ladv+100lmse
通过最小化损失函数l来对模型进行训练,根据梯度下降法得到去模糊对抗生成网络的weight;,即可完成步骤2所述训练后去模糊对抗生成网络的构建;
作为优选,步骤3所述图像序列的数量为m;
步骤3所述图像序列均包含n幅图像;
步骤3所述训练样本中图像的数量为:m×n幅;
步骤3所述对图像序列中图像标记目标矩形框为:
对第i个图像序列中第j幅图像人工标记其目标矩形框为:
(xi,j,yi,j,wi,j,hi,j)
其中,(xi,j,yi,j)表示第i个图像序列中第j幅图像的目标矩形框左上角的坐标,(wi,j,hi,j)表示第i个图像序列中第j幅图像的目标矩形框的尺寸,
作为优选,步骤4所述目标区域得图像尺寸为图像的长、宽,且均为p1;
步骤4所述根据目标区域的图像尺寸进行截取为:
以训练样本中每幅图像的目标矩形框为中心,截取长、宽均为p1的图像作为目标区域样本的图像;
所述截取长、宽均为p1的图像的具体方法为:
训练样本中每幅图像即第i个图像序列中第j幅图像,截取出来的图像矩形框的中心坐标为:
步骤4所述目标区域样本:
m个图像序列,每个图像序列有n幅长、宽均为p1的图像;
所述目标区域样本定义为φ,所述目标区域样本中第i个序列中第j幅图像为φi,j;
步骤4所述搜索区域的图像尺寸为图像的长、宽,且均为p2,p2>p1;
步骤4所述根据搜索区域的图像尺寸进行截取为:
以训练样本中每幅图像的目标矩形框为中心,截取长、宽均为p2的图像作为搜索区域样本的图像;
所述截取长、宽均为p2的图像的具体方法为:
训练样本中每幅图像即第i个图像序列中第j幅图像,截取出来的图像矩形框的中心坐标为:
若有以下情况之一:
步骤4所述搜索区域样本:
m个图像序列,每个图像序列有n幅长、宽均为p2的图像;
所述目标区域样本定义为
对于搜索区域样本中每幅图像均有p22个像素点,将每个像素点标记出是否为目标位置,其计算公式为:
其中c表示搜索区域图像中目标的中心点,u表示每个要标记的位置。r表示以c为圆心画圆的半径。u与c的距离超过r,则标记为-1,u表示负样本,不是目标位置,否则标记为+1,u表示正样本,是目标位置。
作为优选,所述目标区域分支由卷积层、最大池化层组成,所述目标区域分支的输出为目标区域图像的特征向量;
所述搜索区域分支由卷积层、最大池化层组成,所述搜索区域分支的输出为搜索区域图像的特征向量;
搜索区域分支在网络结构上完全复制目标区域分支百度网络结构。在训练过程中,搜索区域分支网络每一层的weight值保持和目标区域分支网络相同层的weight值一样;
所述目标区域样本中第i图像序列为:{φi,1,φi,2,φi,3...φi,n};
所述搜索区域样本中第i图像序列为:
训练第i图像序列时,依次将φi,1、φi,2φi,3、...、φi,n作为目标区域分支的输入;
把φi,1作为目标区域分支的输入,得到尺寸为s1,通道数为c1的卷积核
再依次将
将两个卷积核进行互相关操作,得到尺寸为l1的相似度分数矩阵
即将每个
接着依次将{φi,2,φi,3...φi,n}作为目标区域分支的输入,每次更换目标区域分支输入时,重复上一步骤操作。即对于每个图像序列,可以得到n2个相似度分数矩阵。跟踪孪生网络用m个图像序列进行训练,可以得到m×n2个相似度分数矩阵
进一步通过相似度矩阵得到目标在原图像的坐标:
若有一个相似度分数矩阵matrix1,找到矩阵中值最大的点,将matrix1经过插值操作扩展到尺寸为l2的矩阵matrix2,这个点在matrix2中对应的坐标即为目标的位置。
训练过程中,损失函数使用log损失;
相似度分数矩阵上每个点单独的损失函数为:
l(v1,v2)=log(1+exp(-v1·v2))
其中,v2是matrixi,x,y单个点的得分,如果计算出的这个点的v2越大,则说明这个点越可能是目标,而v1是该点位置对应的标签,且v1∈{+1,-1},如果是正样本,v1=+1,否则v1=-1;
一个点如果标记为v1=+1,则这个点为目标,若该点训练时的得分v2比较大,损失函数的值l(v1,v2)也会变大,从而反向传播调整网络的weight值;
求出矩阵单个点的损失函数后,则相似度分数矩阵matrix1的整体损失函数用全部点损失的均值表示:
其中,d表示整个矩阵,u表示矩阵上的每个点;
由于公共会生成m×n2个相似度分数矩阵matrix1,则会得到m×n2个l(y,v),经加和后得到最终的损失函数lall,通过梯度下降法最小化损失函数lall来进行训练,最终得到跟踪孪生网络的weight;
作为优选,步骤6中所述将待跟踪图像序列通过训练后去模糊对抗生成网络以及训练后跟踪孪生网络进行图像跟踪为:
所述将待跟踪图像序列为:{η1,η2,η3...ηp};
待跟踪图像序列中第1帧图像为η1,经过训练后去模糊对抗生成网络处理后,输入至训练后跟踪孪生网络中目标区域分支的输入图像;
待跟踪图像序列中剩余图像用ηi′表示,其中i′∈[2,p];
ηi′经过去模糊对抗生成网络处理后,进一步输入至训练后跟踪孪生网络中搜索区域分支的输入图像,ηi′通过训练后跟踪孪生网络得到ηi′的相似度分数矩阵,并搜索出ηi′的相似度分数矩阵中最大值,通过步骤5中的插值操作,得到待跟踪图像序列中目标坐标位置。
本发明的有益效果是:本发明提供了一种针对模糊场景和模糊目标的目标跟踪方法,通过结合生成网络和孪生网络,提高了在模糊场景下的跟踪精度,并在实际的模糊场景中表现出良好的鲁棒性。
附图说明
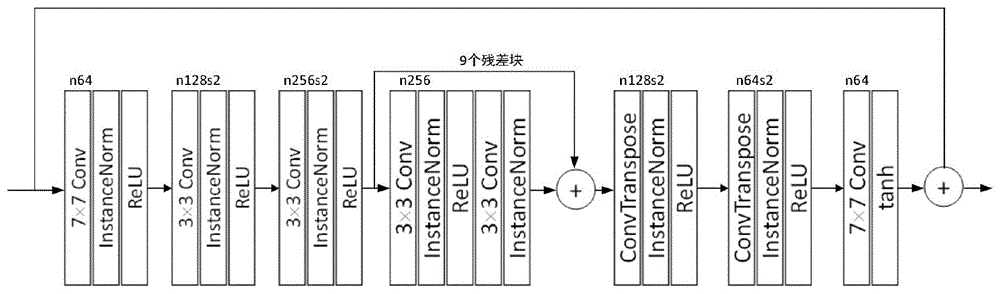
图1:为本发明实施例提供的生成器模型
图2:为本发明实施例提供的判别器模型
图3:为本发明实施例提供的生成对抗网路流程
图4:为本发明实施例提供的孪生网络结构
图5:为本发明实施例提供的孪生网络的跟踪流程
图6:为本发明实施例提供的系统流程图
图7:为本发明实施例提供的方法流程图
图8:为所提出方法针对模糊目标的跟踪结果示意图。
具体实施方式
下面将结合附图,对本发明实施例中的实现步骤进行清楚、完整的描述。此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互结合
下面结合附图1至附图8对本发明的实施方式进行详细描述。
本发明的具体实施方式为一种基于孪生网络的针对模糊目标的跟踪方法,包括以下步骤:
步骤1:根据清晰图像集生成模糊图像集,分别对清晰图像集、模糊图像集进行预处理,得到预处理后清晰图像集和预处理后模糊图像集;
所述根据清晰图像集生成模糊图像集为:
清晰图像集选择高帧率图像数据集,通过运动模糊退化模型,将清晰图像集中连续m′=5帧的清晰图像合成为一幅模糊图像,并选取m′=5帧清晰图像的中间一帧作为相对应的清晰图像。光学感应器的成像信息用如下积分函数表示:
其中,t表示曝光总时间,s(t)表示曝光时刻t记录的影像信息,i表示成像信息,在成像后还需要经过成像设备响应函数将图像信息映射到合适的像素值;
伽马函数近似于成像设备响应函数,光学系统获得的图像像素值可以表示为:
l=g(i)
其中g(·)表示伽马函数,也表示成像设备响应函数,l表示图像亮度值。
通过混合相邻m′帧的成像信息,可模拟模糊图像的成像信息,模糊图像的成像信息可用如下公式表示:
最后,再对模糊图像的成像信息iblurry经过成像设备响应函数,则可得到模糊图像。定义为:
伽马变换定义为:
g(x)=x1/γ
每m′=5帧清晰图像s(·)通过上述变换后即可得到一帧模糊图像,模糊图像放入模糊图像集中,从m′=5帧清晰图像中选取一帧放入清晰图像集中;
所述裁减处理为:
将所述清晰图像集中每幅清晰图像通过裁减处理,使得每幅清晰图像的长和宽均为k=255,得到步骤1所述预处理后清晰图像集,即psharp(s);
将所述模糊图像集中每幅模糊图像通过裁减处理,使得每幅模糊图像的长和宽均为k=255,得到步骤1所述预处理后模糊图像集,即pblurry(b);
步骤2:构建去模糊对抗生成网络,通过对抗损失、内容损失构建去模糊对抗生成网络的总损失函数,结合预处理后清晰图像集以及预处理后模糊图像来训练去模糊对抗生成网络,得到训练后去模糊对抗生成网络;
步骤2所述去模糊对抗生成网络由生成器、判别器构成;
所述生成器包含:卷积层、归一化层、激活函数层;其模型结构如图1所示,它共由七块组成,每一块里面都包含了卷积层、instance归一化层和relu激活函数层。第一块卷积核大小77,步幅为1,通道数为64。第二块与第三块的卷积核大小为33,步长为2,通道数分别为128和256。后面接入9个卷积核大小为33,步幅为1的残差块,通道数为256。接着的两块是两个卷积核为33,步长为2的反卷积块,通道数分别为128和64。接着的一块是卷积核大小77,步幅为1,通道数为64,后接一层tanh激活函数层。最后接一层全局残差层,生成三通道的生成图像。
所述生成器的输入为预处理后模糊图像集即pblurry(b),若b属于模糊图像集中的图像,即b∈pblurry(b),b经过生成器得到的图像记为g(b);
所述判别器包含:卷积层、归一化层、激活函数层;其模型结构如图2所示,它包含六块,除了最后一块之外,每一块后面都有斜率为0.2的leakyrelu激活函数层。第一块的卷积核大小为4×4,步幅为2,通道数为64。第二三四块的卷积核大小都为4×4,步幅为2,通道数分别为128,256和512,后面接上bn(batchnormalization)层。第五块的卷积核大小为4×4,步幅为1,通道数为512,后面接上bn层。最后一块的卷积核大小为4×4,步幅为1,通道数为1,最后得到长宽尺寸为m=16的矩阵。
所述判别器的输入为生成器生成的图像g(b),或者清晰的图像s,其中s∈psharp(s),最后得到长宽尺寸为m=16的矩阵;
去模糊对抗生成网路流程图如图3所示。
步骤2所述对抗损失通过wasserstein距离来定义,具体如下;
其中,s属于清晰图像集中的图像,s~psharp(s)表示s穷举清晰图像集所有图像。b属于模糊图像集中的图像,b~pblurry(b)表示b穷举模糊图像集所有图像。d(s)表示判别器对图像s的输出,d(g(b))表示判别器对所生成图像g(b)的输出,e表示期望值;
步骤2所述内容损失使用l2距离进行定义,即均方误差来定义,具体如下:
lmse=||s-g(b)||2
步骤2所述去模糊对抗生成网络的总损失定义为:
l=ladv+100lmse
通过最小化损失函数l来对模型进行训练,根据梯度下降法得到去模糊对抗生成网络的weight;,即可完成步骤2所述训练后去模糊对抗生成网络的构建;
步骤3:通过多个图像序列构建训练样本,通过人工标记法对图像序列中图像标记目标矩形框;
步骤3所述图像序列的数量为m;
步骤3所述图像序列均包含n幅图像;
步骤3所述训练样本中图像的数量为:m×n幅;
步骤3所述对图像序列中图像标记目标矩形框为:
对第i个图像序列中第j幅图像人工标记其目标矩形框为:
(xi,j,yi,j,wi,j,hi,j)
其中,(xi,j,yi,j)表示第i个图像序列中第j幅图像的目标矩形框左上角的坐标,(wi,j,hi,j)表示第i个图像序列中第j幅图像的目标矩形框的尺寸,
步骤4:训练样本中每幅图像根据目标区域的图像尺寸进行截取得到目标区域样本,训练样本中每幅图像根据搜索区域的图像尺寸进行截取得到搜索区域样本,将搜索区域样本中每幅图像的像素点标记出是否为目标位置
步骤4所述目标区域得图像尺寸为图像的长、宽,且均为p1=127;
步骤4所述根据目标区域的图像尺寸进行截取为:
以训练样本中每幅图像的目标矩形框为中心,截取长、宽均为p1=127的图像作为目标区域样本的图像;
所述截取长、宽均为p1=127的图像的具体方法为:
训练样本中每幅图像即第i个图像序列中第j幅图像,截取出来的图像矩形框的中心坐标为:
步骤4所述目标区域样本:
m个图像序列,每个图像序列有n幅长、宽均为p1=127的图像;
所述目标区域样本定义为φ,所述目标区域样本中第i个序列中第j幅图像为φi,j;
步骤4所述搜索区域的图像尺寸为图像的长、宽,且均为p2=255,p2>p1;
步骤4所述根据搜索区域的图像尺寸进行截取为:
以训练样本中每幅图像的目标矩形框为中心,截取长、宽均为p2=255的图像作为搜索区域样本的图像;
所述截取长、宽均为p2=255的图像的具体方法为:
训练样本中每幅图像即第i个图像序列中第j幅图像,截取出来的图像矩形框的中心坐标为:
若有以下情况之一:
步骤4所述搜索区域样本:
m个图像序列,每个图像序列有n幅长、宽均为p2=255的图像;
所述目标区域样本定义为
对于搜索区域样本中每幅图像均有2552个像素点,将每个像素点标记出是否为目标位置,其计算公式为:
其中c表示搜索区域图像中目标的中心点,u表示每个要标记的位置。r表示以c为圆心画圆的半径。u与c的距离超过r,则标记为-1,u表示负样本,不是目标位置,否则标记为+1,u表示正样本,是目标位置。
步骤5:通过目标区域分支以及搜索区域分支构建孪生网络,根据相似度分数矩阵构建孪生网络的损失函数,通过目标区域样本以及搜索区域样本进行训练得到训练后孪生网络;
步骤5所述目标区域分支由卷积层、最大池化层组成,所述目标区域分支的输出为目标区域图像的特征向量;
所述搜索区域分支由卷积层、最大池化层组成,所述搜索区域分支的输出为搜索区域图像的特征向量;
搜索区域分支在网络结构上完全复制目标区域分支的网络结构。如图4所示是其中一个分支的网络结构示意图,它包含5个卷积层和2个池化层,第一个卷积层卷积核大小为11×11,步幅为2,通道数为96;第一层池化层为最大池化,卷积核大小为3×3,步幅为2。第二个卷积层卷积核大小为5×5,步幅为,通道数为256;第二层池化层为最大池化,卷积核大小为3×3,步幅为2。第三个卷积层卷积核大小为3×3,步幅为1,通道数为192;第四个卷积层卷积核大小为3×3,步幅为1,通道数为192;第五个卷积层卷积核大小为3×3,步幅为1,通道数为128;
在训练过程中,搜索区域分支网络每一层的weight值保持和目标区域分支网络相同层的weight值一样;
所述目标区域样本中第i图像序列为:{φi,1,φi,2,φi,3...φi,n};
所述搜索区域样本中第i图像序列为:
跟踪孪生网络整个流程图如图5所示,
训练第i图像序列时,依次将φi,1、φi,2φi,3、...、φi,n作为目标区域分支的输入;
把φi,1作为目标区域分支的输入,得到尺寸为s1=6,通道数为c1=128的特征向量
再依次将
将两个特征向量进行互相关操作,得到尺寸为l1=17的相似度分数矩阵
即将每个
接着依次将{φi,2,φi,3...φi,n}作为目标区域分支的输入,每次更换目标区域分支输入时,重复上一步骤操作。即对于每个图像序列,可以得到n2个相似度分数矩阵。跟踪孪生网络用m个图像序列进行训练,可以得到m×n2个相似度分数矩阵
进一步通过相似度矩阵得到目标在原图像的坐标:
若有一个相似度分数矩阵matrix1,找到矩阵中值最大的点,将matrix1经过插值操作扩展到尺寸为l2=255的矩阵matrix2,这个点在matrix2中对应的坐标即为目标的位置。
训练过程中,损失函数使用log损失;
相似度分数矩阵上每个点单独的损失函数为:
l(v1,v2)=log(1+exp(-v1·v2))
其中,v2是matrixi,x,y单个点的得分,如果计算出的这个点的v2越大,则说明这个点越可能是目标,而v1是该点位置对应的标签,且v1∈{+1,-1},如果是正样本,v1=+1,否则v1=-1;
一个点如果标记为v1=+1,则这个点为目标,若该点训练时的得分v2比较大,损失函数的值l(v1,v2)也会变大,从而反向传播调整网络的weight值;
求出矩阵单个点的损失函数后,则相似度分数矩阵matrix1的整体损失函数用全部点损失的均值表示:
其中,d表示整个矩阵,u表示矩阵上的每个点;
由于公共会生成m×n2个相似度分数矩阵matrix1,则会得到m×n2个l(y,v),经加和后得到最终的损失函数lall,通过梯度下降法最小化损失函数lall来进行训练,最终得到跟踪孪生网络的weight;
步骤6:将待跟踪图像序列通过训练后去模糊对抗生成网络以及训练后跟踪孪生网络进行图像跟踪,得到待跟踪图像序列的目标坐标位置。
步骤6中所述将待跟踪图像序列通过训练后去模糊对抗生成网络以及训练后跟踪孪生网络进行图像跟踪,流程如图6所示。
所述将待跟踪图像序列为:{η1,η2,η3...ηp};
组合网络的方法流程图如图7所示,待跟踪图像序列中第1帧图像为η1,经过训练后去模糊对抗生成网络处理后,输入至训练后跟踪孪生网络中目标区域分支的输入图像;
待跟踪图像序列中剩余图像用ηi′表示,其中i′∈[2,p];
ηi′经过去模糊对抗生成网络处理后,进一步输入至训练后跟踪孪生网络中搜索区域分支的输入图像,ηi′通过训练后跟踪孪生网络得到ηi′的相似度分数矩阵,并搜索出ηi′的相似度分数矩阵中最大值,通过步骤5中的插值操作,得到待跟踪图像序列中目标坐标位置。
图8为本发明提出的跟踪方法在部分模糊目标或模糊场景下的跟踪效果。红色边框表示的是本发明的方法跟踪到的目标区域,可以看出本发明在实例中取得了不错的效果。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!