一种基于视觉显著性的实例人体解析方法与流程
本发明涉及人体解析领域,更具体地说,涉及一种基于视觉显著性的实例人体解析方法。
背景技术:
人体解析是一种细粒度的语义分割任务,旨在将人体的各个部位以及衣物配饰等语义标签分配给图像中人体的每一个像素,以提供对图片的详细理解。目前,对于单人人体解析的研究已经取得了很大的进步,产生了众多优秀的算法。但是在人类面对的真实情景中,很多时候并非是单个人的画面,实例人体解析因此成为了必要的研究任务。实例人体解析是指在识别出人体各个部位类别的同时,进一步识别这些类别分别属于哪一个实例。实例人体解析目前已经广泛应用于人体行为分析,视频监控,虚拟现实等领域。
现有的实例级人体解析算法从算法流程出发大体可以分为两类,基于检测的方法和基于分割的方法。基于检测的方法大多是先利用检测算法定位到每一个人体实例,然后对选中的实例进行人体部分语义分割。例如liu等人(lius,suny,zhud,etal.cross-domainhumanparsingviaadversarialfeatureandlabeladaptation[c]//thirty-secondaaaiconferenceonartificialintelligence.2018)首先利用目标检测的方法,通过训练检测网络得到人体实例目标框,再与人体解析得到的全局分类合并。ruant等(ruant,liut,huangz,etal.devilinthedetails:towardsaccuratesingleandmultiplehumanparsing[c]//proceedingsoftheaaaiconferenceonartificialintelligence.2019,33:4814-4821)首先提出了人体解析模型ce2p,然后对于单人图片,先通过mask-rcnn(hek,gkioxarig,dollárp,etal.maskr-cnn[c]//proceedingsoftheieeeinternationalconferenceoncomputervision.2017:2961-2969)将图片中的每一个人检测出来并处理成满足ce2p输入尺寸的单独的图片,再分别利用ce2p模型对每一个实例进行分割,最后将所有的分割结果融合以得到最后的解析结果。然而,分别独立训练用于粗略定位的检测网络和用于细致分割的分割网络可能会导致检测结果和分割结果不一致,这种网络模式不仅训练耗时,而且预测结果也会过于依赖检测网络的准确性。
基于分割的方法,例如holistic网络(liq,arnaba,torrphs.holistic,instance-levelhumanparsing[j].arxivpreprintarxiv:1709.03612,2017)同时训练检测网络和分割网络,检测网络定位到每一个人体实例,分割网络则将图像中人体的每一个像素赋予相应的语义标签,然后通过马尔科夫随机场的方法将两个子网络的结果融合并得到最后的实例解析结果。文献[5]首先通过pgn(gongk,liangx,liy,etal.instance-levelhumanparsingviapartgroupingnetwork[c]//proceedingsoftheeuropeanconferenceoncomputervision(eccv).2018:770-785)生成实例边缘图和整体分割图,然后通过线性解码的方式将这两个任务融合得到最后的实例解析结果。虽然这一类方法都是端到端的训练方式,但是它们应用在拥挤的场景中时的分割结果容易缺少实例,且对于眼镜、手表等小目标容易分割失败。
目前的技术方案多是针对单人图片进行人体解析,而实际应用中多是多人的场景,因此迫切需要有效的针对多人的实例人体解析算法。目前存在的实例人体解析算法主要还存在以下问题:基于检测的算法模型需要分别训练检测模型和分割模型,训练需耗费大量的计算资源和时间,且由于不是端到端的网络,需要先通过检测网络定位到每一个人体实例,这导致算法的整体性能过于依赖检测网络的准确性;基于分割的方法尽管解决了基于检测方法存在的问题,但是算法的精度依然不能应用于实际生活中,主要是因为在现实场景中,人物之间会存在拥挤、遮挡、交叠等情况,而现有算法在拥挤场景下的分割结果会存在实例缺失的情况。
技术实现要素:
本发明要解决的技术问题在于,针对实例人体解析的现有技术中存在的:(1)跟语义分割一样,实例人体解析也存在物体边缘容易与背景或其他实例物体混淆的问题;(2)对于人物数量多的拥挤场景,现有的实例人体解析方法分割出的结果容易缺少实例,从而大大降低分割精度和算法性能的技术缺陷,提供了一种基于视觉显著性的实例人体解析方法,用于解决上述两个技术问题。
本发明为解决其技术问题,提供了一种基于视觉显著性的实例人体解析方法,包含如下步骤:
s1、利用显著性检测算法将输入图片中的显著性区域检测出来,从而获取显著性图;
s2、将显著性图和输入图片相加得到人体被高亮的视觉增强图;
s3、接下来将视觉增强图作为网络输入,经过公共特征提取网络获取同时适用于语义分割和边缘检测的公用特征,在公共特征提取网络的第3、4、5层卷积层后分别引入侧输出层,将融合后的侧输出特征图送入人体语义分割单元中,得到人体语义分割结果图;
s4、在公共特征提取网络的第3、4、5层卷积层后分别引入侧输出层,将融合后的侧输出特征图分别送入人体边缘检测单元,得到人体边缘检测结果图;
s5、通过融合单元将人体语义分割结果图和人体边缘检测进行融合,从而得到最后的人体解析结果。
实施本发明的基于视觉显著性的实例人体解析方法,具有下述技术效果:(1)本发明中利用了视觉显著性这一先验特征,通过适当增大显著性区域像素值的方法使得图像中的人体实例更容易被分割网络定位,而不需要依赖额外的检测网络;(2)用显著性检测算法对输入图片进行显著性检测,使得图像中的每个人体实例都被高亮,从而解决了其它算法在拥挤场景下缺失实例的问题;(3)利用边缘检辅助任务使得实例的边缘部分更加清晰平滑。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明的基于视觉显著性的实例人体解析框架图;
图2是本发明的bms算法模型流程图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
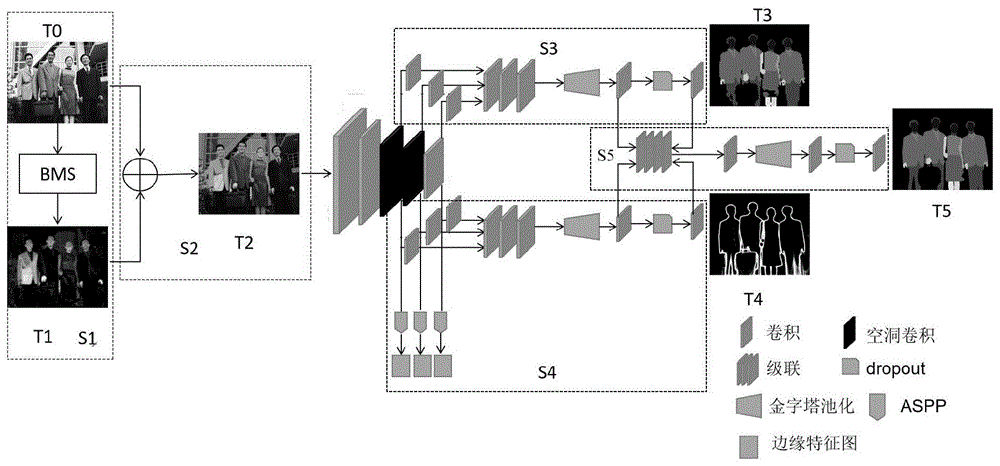
参考图1,图1是本发明的基于视觉显著性的实例人体解析框架图一种基于视觉显著性的实例人体解析方法,包含如下步骤:
s1、利用显著性检测算法将输入图片中的显著性区域检测出来,从而获取显著性图;
s2、将显著性图和输入图片相加得到人体被高亮的视觉增强图;
s3、接下来将视觉增强图作为网络输入,经过公共特征提取网络获取同时适用于语义分割和边缘检测的公用特征,在公共特征提取网络的第3、4、5层卷积层后分别引入侧输出层,将融合后的侧输出特征图送入人体语义分割单元中,得到人体语义分割结果图;
s4、在公共特征提取网络的第3、4、5层卷积层后分别引入侧输出层,将融合后的侧输出特征图分别送入人体边缘检测单元,得到人体边缘检测结果图;
s5、通过融合单元将人体语义分割结果图和人体边缘检测进行融合,从而得到最后的人体解析结果。
接下来,对每一步操作进行解释。
s1、t0到t1环节:利用bms算法获取显著性图。接下来详细介绍bms算法:bms是基于布尔图理论的显著性目标检测算法模型,其流程图如图2所示,图中c(i)为颜色特征图,bcolor为颜色布尔图,acolor为颜色注意力图,si为显著性图。
(1)从输入到c(i)
图像的颜色通道能反映图像的全局信息,而lab颜色空间能更好地以颜色之间的差异体现人眼感觉到的色差大小,视觉上具有良好的连续性,有利于形成良好的颜色通道特征图。因此首先将输入图片根据以下公式转换为lab空间的颜色特征图c(i)。
rgb颜色空间不能直接转换为lab颜色空间,需要借助xyz颜色空间,把rgb颜色空间转换到xyz颜色空间,之后再把xyz颜色空间转换到lab颜色空间。
rgb与xyz颜色空间有如下关系:
假设r,g,b(r,g,b)为像素三个通道,取值范围均为[0,255],转换公式如下:
其中,
xyz转lab:
l*=116f(y/yn)-16
a*=500[f(x/xn)-f(y/yn)]
b*=200[f(y/yn)-f(z/zn)]
其中,
上述公式中l*,a*,b*是最终的lab彩色空间三个通道的值,x,y,z是rgb转xyz后计算出来的值,xn,yn,zn一般默认是95.047,100.0,108.883。
(2)从c(i)到bcolor
对(1)得到的颜色特征图进行如下操作得到对应的布尔图。首先将颜色特征图根据以下三个公式进行白化操作以去除冗余并将特征值都归一化到[0,255]范围内。
其中n为像素数,pij为像素值,最后得到的xij即是白化操作后得到的对应像素值,μ表示均值,σ2表示方差。
然后根据布尔图理论的先验分布理论取一组范围在[0,255]范围内的符合均匀分布的阈值
上式中,
(3)从bcolor到acolor
根据格式塔心理学提出的图像-背景分离原则:显著性目标很大程度上具有完整的闭合轮廓,而背景往往是无序的。由上一步得到的颜色布尔图中被包围的区域是值为0或1的连通区域,具有完整的闭合轮廓,而不被包围的区域则是杂乱无序的背景区域,因此对于布尔图bcolor,本发明利用floodfill算法以图像的四个边界的像素作为种子点快速掩膜掉不被包围的像素,保留具有闭合轮廓的像素,通过这一处理后,被包围的区域取1,不被包围的区域取0,最终得到了一系列的颜色视觉注意图acolor,将其相加得到最终的颜色注意力图。如以下公式所示:
acolor=f(bcolor)
其中
(4)从acolor到si
将颜色注意图acolor进行归一化处理以保留小的视觉注意区域,本发明在其l2范数范围内进行归一化处理,与l1范数相比,l2范数对极小的显著性区域并不敏感。为了使得具有小的、分散的显著性区域的视觉注意图不被抑制,在归一化之前还进行了内核宽为ωd1的膨胀操作,归一化后将视觉注意图分别求平均即得到最终的显著性图si。
其中归一化的公式如下:
s*=average(s)
其中a*为膨胀操作之后的注意力图,||a*||2表示l2范数,s即为归一化后的初步显著性图,s*表示显著性图。
s2、t1到t2环节:对显著性图和输入图片进行融合操作。将上一步得到的显著性图和原图按照以下公式相加,得到视觉增强图se:
se=ξsi+ηs*,
其中,se是指视觉增强图,s*表示显著性图,si表示输入图片,ξ和η表示权重,ξ>0,η>0,ξ+η=1。根据多次实验结果,最终取ξ=0.5,η=0.5。
s3、t2到t3环节:利用公共特征提取网络获取公用特征并利用人体语义分割单元获取人体语义分割结果图。将视觉增强图se作为输入送入公共特征提取网络,然后将经过公共特征网络单元得到的特征图送入人体语义分割单元以得到人体语义分割结果图。
(1)公共特征提取网络
本发明所用的公共特征提取网络是基于resnet-101网络的改进,将resnet-101网络的第三阶段和第四阶段的普通卷积全部更改为空洞卷积,以达到在不增加参数量的前提下增大感受野。公共特征提取网络主要目的是提取图像中同时适用于语义分割和边缘检测的特征,因为语义分割和边缘检测都是利用来自附近像素的低级上下文信息和高级语义特征来理解像素级的语义特征的,所以本发明没有单独训练两个网络来处理这两个相关的任务,而是共用了一个允许权重共享的骨干网络。
(2)人体语义分割单元
传统的语义分割算法都是在几个不同的尺度上利用共享的网络权重预测图像,然后将预测与学习到的权重结合在一起。为了增强网络的泛化性,本发明应用了另外一种上下文聚合模式,在公共特征提取网络的第3、4、5层卷积层后分别引出侧输出层,接着分别通过一个卷积层得到特征图,共三个特征图,然后将三个特征图级联,通过这样的方式,将浅层的空间信息和深层的语义信息充分结合。为了获得全局信息,本发明还采用了金字塔池化处理级联后的特征图。接下来再经过一个卷积层使得通道数等于物体的总类别数,再连接一个dropout层,最后增加一个卷积层进一步融合特征,得到人体语义分割结果图t3。
s4、t2到t4环节:利用人体边缘检测单元获取人体边缘检测结果图
本发明首先将视觉增强图se作为输入送入公共特征提取网络,在公共特征提取网络的第3、4、5层卷积层后分别引出侧输出层,,在第3、4、5层卷积层后引出的侧输出层后分别增加了带空洞卷积的金字塔池化模块aspp(atrousspatialpyramidpooling),利用aspp能在不耗费巨大的计算量的前提下得到多尺度信息,以此产生了前三个边缘特征图;同时在三个侧输出层后分别通过一个1×1的卷积层来得到后三个边缘特征图,再将后三个边缘特征图级联,在级联融合后的特征图后面继续添加金字塔池化模块(无特殊说明,本发明中金字塔池化模块是指一般的金字塔池化模块,而非aspp),再经过一个卷积层改变通道数,使得通道数等于物体的总类别数,再连接一个dropout层,最后增加一个卷积层进一步融合特征,从而得到人体边缘检测结果图t4。其中,所述带空洞卷积的金字塔池化模块aspp包括依次连接的一个1×1卷积和四个3×3空洞卷积,其扩张率分别为2、4、8和16。
人体边缘检测任务是相关任务,其主要目的是辅助人体解析这一主任务,作为相关任务,它主要有以下两个功能:第一通过边缘信息可以准确的定位到每一个人体实例,以防存在实例缺失的情况;第二边缘信息也可以使实例的边缘部分分割更加清晰平滑,解决了实例人体解析边缘部分容易与背景或其它物体混淆的问题。
s5、t3、t4到t5环节:将人体语义分割结果图和人体边缘结果图融合。
将人体语义分割单元所得到的人体语义分割结果图t3、人体语义分割单元中dropout前的特征图、人体边缘检测单元所得到的人体边缘检测结果图t4以及人体边缘检测单元中dropout前的特征图级联,然后通过一个1×1卷积将级联后的特征图映射为更大数量通道的特征图,将映射后的特征图再次送入金字塔池化模块中,以相互促进分割和边缘检测的结果,再连接一个dropout层,最后增加一个卷积层进一步融合特征,最后即得到实例人体解析结果图t5,进行融合所采用的公式如下:
式中,α和β分别为分割和边缘检测所占的权重,ls和l's分别是人体语义分割单元得到的人体语义分割结果图和dropout前的特征图经过softmax以及交叉熵损失函数所得到的损失值,le和l'e则是人体边缘检测单元得到的人体边缘检测结果图和dropout前的特征图经过softmax以及交叉熵损失函数所得到的损失值,lside是前三个边缘特征图经过sigmoid激活函数以及二进制交叉熵损失函数得到的损失值,其中n=3。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!