一种基于商品评论的主题模型推断方法与流程
本发明属于短文本商品评论信息主题模型技术领域,涉及一种基于商品评论的主题模型推断方法。
背景技术:
电子商务平台的飞速发展,使得越来越多的用户参与其中,已累积了大量的用户评论信息。因此,研究用户商品的评论信息及其蕴含的知识越来越受到学术和企业界的重视,其中评论信息主题模型的研究是基础。迄今为止,主题模型推断方法主要有基于词对的主题模型、基于标签的主题模型等。上述模型虽然都能较好地提取出传统文本中隐含的主题,且对于短文本评论信息也能通过将其聚合成长的伪文档或限制文档主题分布数量达到解决数据稀疏的问题。但短文本的用户商品评论信息由于没有足够的上下文,具有语义稀疏的特点,虽然可通过引入外部知识,利用外部语料库信息进行词嵌入训练,以增加词的语义信息。但在实际应用上仍存在着一些缺陷,比如在外部知识训练的词嵌入模型中,一些词存在语义编码信息与短文本中不一致的现象,使得主题模型在主题一致性上表现较差;此外对词进行语义相似度增强时,没有考虑词相关性的强弱,而笼统的进行统一语义相似度增强,这也导致了主题分类不明确的问题,降低了模型的实际应用效果。
技术实现要素:
本发明的目的是提供一种基于商品评论的主题模型推断方法,解决了现有技术中存在的因语义编码信息与短文本中不一致的现象,使得主题模型在主题一致性上表现较差以及对词进行语义相似度增强时,没有考虑词相关性的强弱,而笼统的进行统一语义相似度增强,导致了主题分类不明确的问题。
本发明所采用的技术方案是,一种基于商品评论的主题模型推断方法,具体按照如下步骤实施:
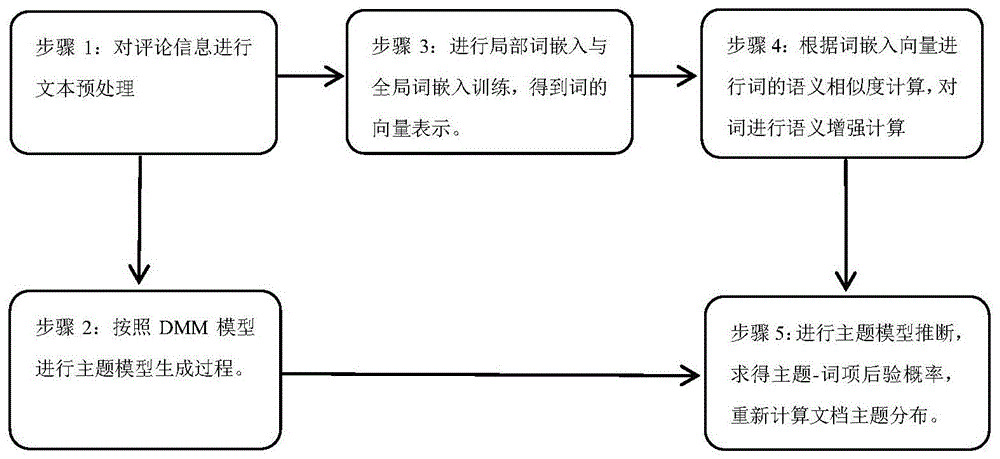
步骤1,对评论信息文献集d进行文本预处理,并将经过预处理的评论信息放入词汇表v中;
步骤2,利用步骤1的文献集d进行建模,生成主题模型并确定要求解的隐藏变量主题-词项的后验概率分布p(w|z=k);
步骤3,利用步骤1的文献集d进行局部词嵌入训练,利用外部语料库即谷歌语料库进行全局词嵌入训练,得到局部词嵌入模型和全局词嵌入模型,利用全局词嵌入模型与局部词嵌入模型分别获得词汇表v中词的向量表示;
步骤4,对步骤3中获得词的全局与局部嵌入向量分别进行余弦相似度计算,然后根据余弦相似度计算进一步得到词与词之间的语义相似性,进而进行语义增强计算;
步骤5,利用步骤4中得到的词的语义增强结果与gibbssampling过程对步骤2主题模型中的隐藏变量主题-词项的后验概率分布p(w|z=k)进行计算,从而完成对主题模型的推断,实现文档的主题概率近似计算。
本发明的特征还在于,
步骤1中对评论信息进行文本预处理的具体操作为:
将文本进行分词、文本中的字母转换成小写、删除文本中出现次数小于4的词、去除停用词、删除文本字数小于4的短文本。
步骤2中的主题模型具体为:给定文献集d,文献集中的文档d,词汇表v和预定义的k个主题,假设每个文档d都只与一个特定的主题k相关,主题概率p(z),表示为θ,其中z为主题变量,服从一个参数为α的先验dirichlet分布dirichlet(α);主题-词项后验概率p(w|z=k),表示为φk,服从一个参数为β的先验dirichlet分布dirichlet(β);文档的主题服从一个参数为θ的多项式分布multionmial(θ),有p(z=k)=θk,并且∑kθk=1,其中,k=1,...,k;文档d中的nd个词
步骤2中利用步骤1的文献集d进行建模具体过程为:
步骤2.1,采样一个主题概率θ~dirichlet(α);
步骤2.2,对于每个主题k∈{1,...,k},采样一个主题-词分布φk~dirichlet(β);
步骤2.3,对于每个文档d∈d,采样一个主题zd~multionmial(θ);
步骤2.4,遍历每个词
步骤3具体为:
用谷歌word2vec的skip-gram开发工具训练全局词嵌入与局部词嵌入模型,完成词到向量的映射过程,其中:
全局词嵌入模型训练:
用谷歌语料库数据集进行词嵌入训练,嵌入空间维度设置为300维,以获取外部知识;
局部词嵌入模型训练:
用步骤1中的文献集d进行词嵌入训练,嵌入空间维度设置为30维,以获得评论信息中词的上下文信息;
从嵌入空间中获得词汇表v中词的局部词嵌入向量与全局词嵌入向量表示。
步骤4对步骤3中获得词的全局与局部嵌入向量分别进行余弦相似度计算,进一步得到词与词之间的语义相似性,进而进行语义增强计算,具体步骤为:
步骤4.1,通过式(1)计算词与词之间的余弦相似度:
其中,v(w)为词w的向量表示,v(wi)为词wi的向量表示;
步骤4.2,利用步骤4.1中的公式计算词w与词wi的全局词嵌入向量的余弦相似度simg(w,wi)与局部词嵌入向量的余弦相似度siml(w,wi),求和再取平均值作为这两个词的语义相似度,用公式(2)表示:
其中,sr(w,wi)表示词w和词wi的语义相似度;
步骤4.3,根据步骤4.2计算的语义相似度,为词w构建语义相关词集mw,mw={wi|wi∈v,sr(w,wi)>ε},参数ε取值为0.6,v为文献集d对应的词汇表;
步骤4.4,根据采样词w,对与采样词相关的语义相关词集mw中的部分词进行语义增强计算,语义增强系数
其中,w为采样词,wi为语义相关词集mw中的词,当w=wi时,语义增强系数:
步骤4.5,根据步骤4.4中的
其中,其中
步骤5具体为:
步骤5.1,在每一次迭代过程中,利用gibbssampling的方法从文献集d采样一篇文档d,并记录其相关的统计量,用mk表示文献集d中属于k主题的文档个数;
步骤5.2,用步骤4中语义增强的方法对相关词集mw中的wi进行削减更新,具体过程为:
步骤5.2.1,更新主题k的文档数量,mk=mk-1;
步骤5.2.2,对于每个词w∈d,更新相关统计量,
步骤5.2.3,对于每个词w的语义相关词集mw中的wi做更新,计算语义增强系数
步骤5.3,为文档d重新采样一个新主题zd,重新采样一个新主题遵从条件概率:
其中下标
并更新相关统计量:
(1)更新主题k的文档数量:mk=mk+1;
(2)对于每个词w∈d,更新相关统计量:
(3)对于每个词w的语义相关词集mw中的wi做更新,计算语义提升系数
步骤5.4,最后利用步骤5.1-5.3更新后的统计量计算步骤2中的主题-词项后验概率分布,计算公式如式(8)所示,
完成主题模型的推断。
步骤5.5,实现文档的主题概率近似计算如式(9)所示:
其中p(z=k|w)表示词w属于主题k的概率,计算公式如式(10)所示:
p(z=k|w)∝p(z=k)p(w|z=k)(10)
本发明的有益效果是:
本发明通过利用狄利克雷混合主题模型进行建模;然后对外部知识语料库进行全局词嵌入训练,获取词的外部知识丰富词的语义信息,对短文本进行局部词嵌入训练获取词的上下文信息,解决与全局词嵌入训练上词语义信息编码不一致的问题,联合全局词嵌入与局部词嵌入进行词的相似度计算,根据词的语义相似度所占的比重进行词的语义增强;最后通过模型推断获得词项-主题的后验概率分布进而计算出短文本所属的主题类别。解决了现有技术存在主题模型在主题一致性上表现较差,对词进行语义相似度增强时,没有考虑词相关性的强弱,而笼统的进行统一语义相似度增强,这也导致了主题分类不明确的问题,降低了模型的实际应用效果的问题,实现评论主题精准分类且主题分类一致的效果,这可广泛应用在电子商务网站用户购物评价的分析中,应用价值高。
附图说明
图1是本发明一种基于商品评论的主题模型推断方法的流程图;
图2是主题模型dmm的生成过程;
图3是文档分类实验结果图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于商品评论的主题模型推断方法,其流程如图1所示,具体按照如下步骤实施:
步骤1,对评论信息文献集d进行文本预处理,并将经过预处理的评论信息放入词汇表v中;对评论信息进行文本预处理的具体操作为:
将文本进行分词、文本中的字母转换成小写、删除文本中出现次数小于4的词、去除停用词、删除文本字数小于4的短文本;
步骤2,利用步骤1的文献集d进行建模,如图2所示:生成主题模型并确定要求解的隐藏变量主题-词项的后验概率分布p(w|z=k);主题模型具体为:给定文献集d,文献集中的文档d,词汇表v和预定义的k个主题,假设每个文档d都只与一个特定的主题k相关,主题概率p(z),表示为θ,其中z表示为主题变量,服从一个参数为α的先验dirichlet分布dirichlet(α);主题-词项概率p(w|z=k),表示为φk,服从一个参数为β的先验dirichlet分布dirichlet(β);文档的主题服从一个参数为θ的多项式分布multionmial(θ),有p(z=k)=θk,并且∑kθk=1,其中,k=1,...,k;文档d中的nd个词
利用步骤1的文献集d进行建模具体过程为:
步骤2.1,采样一个主题概率θ~dirichlet(α);
步骤2.2,对于每个主题k∈{1,...,k},采样一个主题-词分布φk~dirichlet(β);
步骤2.3,对于每个文档d∈d,采样一个主题zd~multionmial(θ);
步骤2.4,遍历每个词
步骤3,利用步骤1的文献集d进行局部词嵌入训练,利用外部语料库,即谷歌语料库进行全局词嵌入训练,得到局部词嵌入模型和全局词嵌入模型,利用局部词嵌入模型与全局词嵌入模型分别获得词汇表v中词的向量表示;具体为:
用谷歌word2vec的skip-gram开发工具训练全局词嵌入与局部词嵌入模型,完成词到向量的映射过程,其中:
全局词嵌入模型训练:
用谷歌语料库数据集进行词嵌入训练,嵌入空间维度设置为300维,以获取外部知识;
局部词嵌入模型训练:
用步骤1中的文献集d进行词嵌入训练,嵌入空间维度设置为30维,以获得评论信息中词的上下文信息;
从嵌入空间中获得词汇表v中词的局部词嵌入向量与全局词嵌入向量表示;
步骤4,对步骤3中获得词的全局与局部嵌入向量分别进行余弦相似度计算,进一步得到词与词之间的语义相似性,进而进行语义增强计算;具体步骤为:
步骤4.1,通过式(1)计算词与词之间的余弦相似度:
其中,v(w)为词w的向量表示,v(wi)为词wi的向量表示;
步骤4.2,利用步骤4.1中的公式计算词w与词wi的全局词嵌入向量的余弦相似度simg(w,wi)与局部词嵌入向量的余弦相似度siml(w,wi),求和再取平均值作为这两个词的语义相似度,用公式(2)表示:
其中,sr(w,wi)表示词w和词wi的语义相似度;
步骤4.3,根据步骤4.2计算的语义相似度,为词w构建语义相关词集mw,mw={wi|wi∈v,sr(w,wi)>ε},参数ε取值为0.6,v为文献集d对应的词汇表;
步骤4.4,根据采样词w,对与采样词相关的语义相关词集mw中的部分词进行语义增强计算,语义增强系数
其中,w为采样词,wi为语义相关词集mw中的词,当w=wi时,语义增强系数:
步骤4.5,根据步骤4.4中的
其中,其中
步骤5,利用步骤4中得到的词的语义增强结果与gibbssampling过程对步骤2主题模型中的隐藏变量主题-词项的后验概率分布p(w|z=k)进行计算,从而完成对主题模型的推断,实现文档的主题概率近似计算,具体为:
步骤5.1,在每一次迭代过程中,利用gibbssampling的方法从文献集d采样一篇文档d,并记录其相关的统计量,用mk表示文献集d中属于k主题的文档个数;
步骤5.2,用步骤4中语义增强的方法对相关词集mw中的wi进行削减更新,具体过程为:
步骤5.2.1,更新主题k的文档数量,mk=mk-1;
步骤5.2.2,对于每个词w∈d,更新相关统计量,
步骤5.2.3,对于每个词w的语义相关词集mw中的wi做更新,计算语义增强系数
步骤5.3,为文档d重新采样一个新主题zd,重新采样一个新主题遵从条件概率:
其中下标
并更新相关统计量:
(1)更新主题k的文档数量:mk=mk+1;
(2)对于每个词w∈d,更新相关统计量:
(3)对于每个词w的语义相关词集mw中的wi做更新,计算语义提升系数
步骤5.4,最后利用步骤5.1-5.3更新后的统计量计算步骤2中的主题-词项后验概率分布,计算公式如式(8)所示,
完成主题模型的推断。
步骤5.5,实现文档的主题概率近似计算如式(9)所示:
其中p(z=k|w)表示词w属于主题k的概率,计算公式如式(10)所示:
p(z=k|w)∝p(z=k)p(w|z=k)(10)
步骤5的过程如表1所示:
实施例
本专利的有效性使用websnippets数据集和amazonreview数据集进行验证。websnippets数据集包括12340个搜索片段,其中每个片段属于8个类别中的一个类别。amazonreview数据集是从1996年5月到2014年7月的亚马逊产品评论信息,其中每个片段属于7个类别中的一个类别,实验从中随机采样20000条数据作为验证的数据集,实验统一设置公共参数值α=50/k、β=0.01、num=10,最大迭代轮次为1500次,预处理之后的数据集信息如表2所示:
表2
实验在主题分类精度与主题一致性上进行模型评估,并与dmm、btm和gpu-dmm模型进行实验对比。
(1)主题分类精度
在短文本分类实验中,用主题模型推断的文档主题概率p(z|d)来表示文档,应用公式(9)进行计算。用支持向量机分类器对文档进行分类,分类的精度越高,主题模型学习到的主题就越合理,主题之间的区分度越高,分类的执行效果就越好。其中分类精度通过5折交叉验证来计算,图3给出了与其他基线模型的实验结果对比,图3(a)为snippets数据集主题分类精度图3(b)为amazon数据集主题分类精度,从图3(a)与图3(b)中可看出,本发明提出的方法在两个数据集上的分类效果比其他模型都要好。
(2)主题一致性
主题一致性实验使用pmi-score值来验证主题一致性。计算pmi-score值时,需利用外部大规模文本数据集(维基百科),基于点态互信息来测量主题相关性。较高的pmi-score值表明主题模型推断的主题更好。
给定主题k和该主题概率排序为前t的词(w1,...,wt),主题k的pmi值的计算公式如下:
其中p(wi,wj)为词对wi和wj在外部数据集(维基百科)中共现的概率,p(wi)为词wi在外部数据集中出现的概率。
实验给出在主题-词项分布排列前10的主题词,主题个数k分别为20,40,60,80上的主题一致性评估结果,如表3所示:
表3
从上表3可以看出,本发明提出的方法在主题一致性上表现出了良好的结果,都优于其他主题模型。
本发明的商品评论信息主题模型推断方法,通过利用狄利克雷混合主题模型进行建模;然后对外部知识语料库进行全局词嵌入训练,获取词的外部知识丰富词的语义信息,对短文本进行局部词嵌入训练获取词的上下文信息,解决与全局词嵌入训练上词语义信息编码不一致的问题,联合全局词嵌入与局部词嵌入进行词的相似度计算,根据词的语义相似度所占的比重进行词的语义增强;最后通过模型推断获得词项-主题的后验概率分布进而计算出短文本所属的主题类别。解决了商品评论信息中词的语义相关度计算及语义增强的问题,实现评论主题精准分类且主题分类一致的效果,这可广泛应用在电子商务网站用户购物评价的分析中,应用价值高。
- 还没有人留言评论。精彩留言会获得点赞!