一种基于改进结构推理网络的高铁接触网零部件定位方法与流程
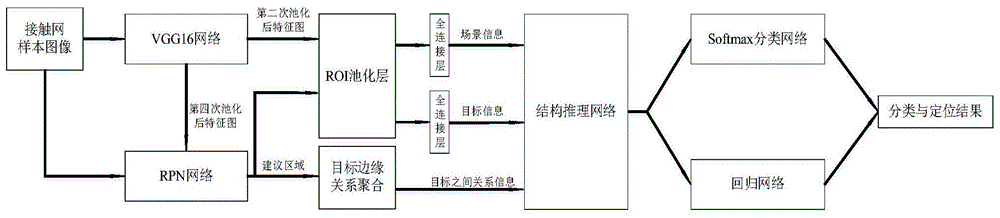
本发明涉及高速铁路图像智能检测技术领域,具体为一种基于改进结构推理网络的高铁接触网零部件定位方法。
背景技术:
高速铁路接触网的设备状态对于列车的安全运行十分重要,而目前铁路上运行的4c检测设备仍主要采用传统的图像处理算法,对于全国情况各异的线路不具有普适性,而且并未实现自动化,检测精度也亟待提高。
随着技术发展,图像检测技术在接触网零部件上的应用愈加广泛。在现有的图像检测技术当中,在检测各零部件的状态之前需要先对其进行定位分类,而传统的图像检测方法不仅精度低、耗时长,并且对于不同铁路线路并不具有通用性。几种经典深度学习网络如fastrcnn、ssd、yolo虽然在精度与检测速度上有所提高,但并未达到理想状态。韩烨采用sift特征和边缘曲线弯曲度检测旋转双耳耳片状态;张桂南提出了一种通过快速模糊匹配实现绝缘子故障判断的方法;钟俊平利用sift算法和改进ransac实现双耳套筒的定位;陈隽文提出了基于adaboost算法对斜撑套筒进行定位,并利用hough变换分析螺钉的状态;张桂南介绍了一种实现绝缘子的抗旋转匹配和故障检测的方法;段汝娇通过hough变换方法检测定位器的倾斜度;刘志刚依据接触网图像结构特点,通过先分类后定位的方法构建级联网络,提高大尺度零部件定位精度。
由于现场采集的接触网支撑及悬挂装置图像普遍较复杂,且尺寸与形状变化大,因此急需一种简单迅速的图像检测算法对接触网各零部件进行快速定位与检测。考虑到接触网支撑悬挂装置各零部件位置相对固定,且检测图像中出现的场景有限,可将其作为训练过程添加的辅助信息。
技术实现要素:
针对上述问题,本发明的目的在于提供一种基于改进结构推理网络(sin,structureinferencenet)的高铁接触网零部件定位方法,能够实现接触网零部件精确快速定位,而且考虑了接触网零部件大小差异,使用第二次池化后特征层输入roi池化层,能够精确定位顶紧螺栓等细小零部件。技术方案如下:
一种基于改进结构推理网络的高铁接触网零部件定位方法,包括以下步骤:
步骤a:对高速铁路接触网支撑及悬挂装置进行图像采集;
步骤b:根据采集到的图像建立接触网支撑及悬挂装置的样本数据集;
步骤c:将数据集划分为训练集和测试集,训练好结构推理网络后,利用结构推理网络对接触网零部件进行精确快速定位:
步骤c1:向网络输入接触网的样本图像,由vgg16网络对其进行卷积与池化操作,将第二次池化操作后的特征图送入roi池化层,第四次池化操作后的特征图送入rpn网络用于生成建议区域;
步骤c2:rpn网络接收来自vgg16网络的特征图,并采用多种不同大小与长宽比的区域框架对特征图滑动采集零部件特征,得到一定数量的特征区域,然后根据原图groundtruth与特征区域的重叠率大小,筛选出重叠率值大于设定阈值的特征区域作为建议区域,并向roi池化层输入图像的建议区域;
步骤c3:roi池化层将每个建议区域映射到特征图上,并在池化操作后将其合并为一个固定大小特征图;经过全连接层后,提取各目标的特征作为视觉特征向量
步骤c4:结构推理网络接收各目标节点视觉特征向量
步骤c5:根据得到目标节点状态,softmax分类网络与回归网络对各目标节点分类并得到定位矩形框坐标。
进一步的,在所述vgg16网络中,针对小目标特征图分辨率的问题,将pool2池化操作后的特征图代替原来pool5池化操作后的特征图送入roipooling层,用于对建议区域的目标进行分类;并加上一个1×1的卷积将pool2池化层的通道数维持在512;且取消原有的pool5池化层以及conv5-1、conv5-2、conv5-3卷积层,改用将pool4池化操作后的特征图送入rpn网络,用于生成建议区域。
更进一步的,所述结构推理网络使用gru将不同信息编码为目标状态,gru将从来自目标之间的关系信息和场景信息中选择相关信息更新当前目标的隐状态,当目标的状态更新时,目标之间的关系也会随着变化;场景gru的初始状态为视觉特征fv,输入为场景信息ms;边缘gru的初始状态也为视觉特征fv,输入为目标位置信息me,其中me集成了各个目标对于当前目标vi节点的位置关系;使用maxpooling提取出目标信息,
计算目标节点vj对于目标节点vi的位置关系ej→i的计算下式所示:
式中,wp和wv均为可学习的权重矩阵,视觉关系向量由
其中,(xi,yi)表示目标的中心点坐标,wi和wj,分别表示目标节点vi和vj的宽度,hj和hj分别表示目标节点vi和vj的高度,si和sj分别表示目标节点vi和vj的面积;目标节点vi通过接收来自场景以及其它节点的信息,得到场景gru的输出
本发明的有益效果是:本发明能够高效快速定位接触网各零部件,网络模型当中的结构推理网络融合了目标自身信息和目标之间的位置关系信息以及场景信息,并以此进行信息的迭代传播;考虑了接触网零部件大小差异太大,使用第二次池化后特征层输入roi池化层,能够精确定位顶紧螺栓等细小零部件。
附图说明
图1为本发明方法处理过程框图。
图2为本发明现场采集的高铁接触网悬挂装置图像。
图3为本发明网络模型定位后的高铁接触网悬挂装置零部件图像。
图4为改进后的vgg16网络结构。
图5为图像各类信息建模原理图。
图6为gru网络输入输出图。
图7为gru内部原理图。
图8为结构推理网络结构图。
图9为结构推理原理图。
图10为定位结果图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细说明。图1为本发明方法处理过程框图。图2为现场采集的高铁接触网悬挂装置图像,图3使用本发明网络模型定位后的高铁接触网悬挂装置零部件图像,图10为定位结果图。本发明基于结构推理网络的高铁接触网零部件定位方法,包括以下步骤:
步骤a:采用专用综合列检车对高速铁路接触网支撑及悬挂装置进行成像;如图2所示。
步骤b:建立接触网支撑及悬挂装置的样本数据集;接触网支撑悬挂装置零部件如图3所示。
步骤c:将步骤b的数据集划分为训练集和测试集,训练好结构推理网络后,利用结构推理网络对接触网零部件进行精确快速定位。
根据上述方案,所述步骤c的具体过程如下:
步骤c1:将所述数据集划分为训练集和测试集,向网络输入接触网的样本图像,由改进vgg16网络对其进行卷积与池化操作,将第二次池化操作后的特征图送入roi池化层,第四次池化操作后的特征图送入rpn网络用于生成建议区域;改进后的vgg16网络结构如图4所示。
步骤c2:rpn网络接收来自vgg16网络的特征图,并采用多种不同大小与长宽比的区域框架对特征图滑动采集零部件特征,得到一定数量的特征区域,然后根据原图groundtruth与特征区域的重叠率(iou)大小,筛选出iou值大于设定阈值0.7的特征区域作为建议区域,并向roi池化层输入该图像建议区域。
步骤c3:roi池化层将每个建议区域映射到特征图上,并在池化操作后将其合并为一个固定大小特征图。经过全连接层后,提取各目标的特征作为视觉特征向量
其中,构建的网络主要由vgg16网络、rpn网络、roi池化层、结构推理网络与分类回归网络组成。
1)vgg16网络。为了适应尺度变化较大的零部件,在原有anchor尺寸[8,16,32]基础上增加了三个尺寸,变为[2,4,8,16,32,64],长宽比依然为[2:1,1:1,1:2]。增加两个小尺寸anchor目的是为了更好适应斜撑套筒顶紧螺栓等小目标的尺寸。
针对小目标特征图分辨率的问题,因斜撑套筒螺钉等小目标的特征图featuremaps经过pool5池化操作后分辨率过低,故将pool2池化操作后的特征图代替原来pool5池化操作后的特征图送入roipooling层,用于对建议区域的目标进行分类,由于pool2池化层后的通道数为256,因此我们加上了一个1×1的卷积将通道数维持在512;除此之外,我们取消了原有的pool5池化层以及之前的conv5-1、conv5-2、conv5-3卷积层,改用将pool4池化操作后的特征图送入rpn网络,用于生成建议区域,该操作也是为了提高特征图的分辨率。改进后的vgg16网络如图4所示。
2)rpn网络。区域提案网络(rpn,regionproposalnetwork)提取感兴趣区域(roi,regionofinterest)
3)roi池化层。将2)中提取的感兴趣区域(roi)调整到固定大小,将roi映射到featuremap的对应位置。
4)构推理网络。构建结构推理网络,由于铁路接触网个零部件具有空间和位置相互关联的关系,这种关系可以作为零部件定位时的辅助信息,图像中的各类信息可建模如图5所示。
图5中vi表示建议区域,视作为一个目标节点,由roi池化层的fc层提取的视觉特征向量
步骤c4:结构推理网络接收各目标节点视觉特征向量
结构推理网络由一组级联的场景gru和边缘gru网络组成,其将场景信息和目标之间位置关系信息传至目标节点,并根据图像变化对节点进行更新。
a)、gru网络原理。图像中每个目标节点都需要接收大量来自场景和其它目标节点的信息,并将这些信息进行整合以得到一个完整信息,这个功能由gru(gaterecurrentunit)网络来完成。gru(gaterecurrentunit)是循环神经网络(recurrentneuralnetwork,rnn)的一种。
gru网络的输入为当前状态xt和上一个节点传递的隐状态
r=σ(wr[x,ht])
r=σ(wz[x,ht]
随后
最后,
gru网络输入输出图如图6所示,gru内部原理图如图7所示。
b)结构推理网络。结构推理网络使用gru将不同信息编码为目标状态,gru将从来自目标之间的关系信息和场景信息中选择相关信息更新当前目标的隐状态,当目标的状态更新时,目标之间的关系也会随着变化,并且随着时间步长的增加,得到的模型越稳定。
场景gru的初始状态为视觉特征fv,输入为场景信息ms;边缘gru的初始状态也为视觉特征fv,输入为目标位置信息me,其中me集成了各个目标对于当前目标vi的位置关系,不同目标对于当前目标的关系权重ej→i不同,这是由相对位置和视觉关系决定的。
使用maxpooling提取出最重要的信息,避免无关区域的干扰。
计算目标vj对于目标vi的位置关系ej→i的计算下式所示。
式中wp和wv均为可学习的权重矩阵,视觉关系向量由
其中(xi,yi)表示目标的中心点坐标,wi和
步骤c5:根据得到目标节点状态,softmax分类网络与回归网络对各目标节点分类并得到定位矩形框坐标。定位得到的图像如图10所示。
- 还没有人留言评论。精彩留言会获得点赞!