一种基于词组的概念化主题建模方法与流程
本发明涉及一种基于词组的概念化主题建模方法,属于自然语言处理中的文本挖掘领域。
背景技术:
主题模型是一种可以在海量文本语料中挖掘出文本隐含主题的一类机器学习方法。
随着信息技术的发展,互联网上每天都会产生海量的文本,有效地分析这些文本的信息,如文本的语义关系、词之间的语义联系等,有助于我们对文本进行整理分类、对信息进行筛选过滤等。主题模型是一种通过机器学习的方法自动地分析海量文本语料的语义结构的有效方法,近年来广泛地被应用于学术界和商业界。
主题模型通常运用词袋模型的方法,将需要处理的文本语料中的每篇文档视为一个词袋,在词袋中,文本被看成一些词的集合,即词和词之间的位置关系被忽略,只考虑不同的词出现的频数。主题模型中,每篇文档是由若干个主题按照一定的概率分布构成的(文档-主题分布),每个主题是由词表中的词按照一定概率分布构成的(主题-词分布)。求解主题模型的两个参数文档-主题分布及主题-词分布的方法主要有三种:em方法、吉布斯采样方法和神经网络方法。通过训练,得到的文档-主题分布可以用于文本分类、推荐系统、信息检索等领域,主题-词分布可以用于文本主题的分析,词义的聚类或分类等场景。
由于基于词袋的主题模型将文档视为词的集合,忽略了词序对文本语义的作用,近年来很多研究工作着眼于在主题模型中以词对或词组的形式挖掘主题,如yan等人、elkishky等人和tang等人的工作,这些工作在文本语义分析方面取得了良好的效果。本发明属于基于词组袋的主题模型,与基于词袋模型的主题模型相比,基于词组袋的主题模型可以在一定程度上保留文本的词序信息,有助于模型对文本语义的分析与理解,增强了主题模型学习到的主题的语义完整性和可解释性。
传统的主题模型大多是基于统计机器学习的,这类主题建模方法挖掘出的文本语料的主题信息是通过统计词的词频和词的共现来实现的,然而,这类主题模型无法做到像人一样“理解”自然语言文本的含义。当我们看到“盘子里有一个苹果。”这句话时,我们会知道盘子里有一个水果,这个水果是苹果,而且我们不会理解成盘子里的是一台苹果牌电脑。这是因为我们是基于自己的经验知识(先验知识)来理解自然语言的,我们的先验知识中包含苹果是一种水果或者一个品牌的名称,盘子可以装水果且一般不用来装电脑,因此我们得出盘子里有一种叫做苹果的水果的结论。然而,计算机没有先验知识,无法将苹果(实体)理解成水果(概念)或者品牌(概念)。概念知识库是一类人工构建的包含实体和概念间关系的数据库,如freebase、wordnet、probase等。本发明提出的一种基于词组的概念化主题建模方法,将概念知识库融入主题建模,可以从概念层面上理解文本语料,从而更好地对文本语料的主题进行建模。
技术实现要素:
本发明的目的在于提高现有主题模型对文本的理解能力和挖掘可解释性强主题的能力,提出了一种基于词组的概念化主题建模方法,使计算机能够利用概念知识库中丰富的概念与实体的关系深入理解自然语言文本,以词组为单位,挖掘出可解释性强的主题。
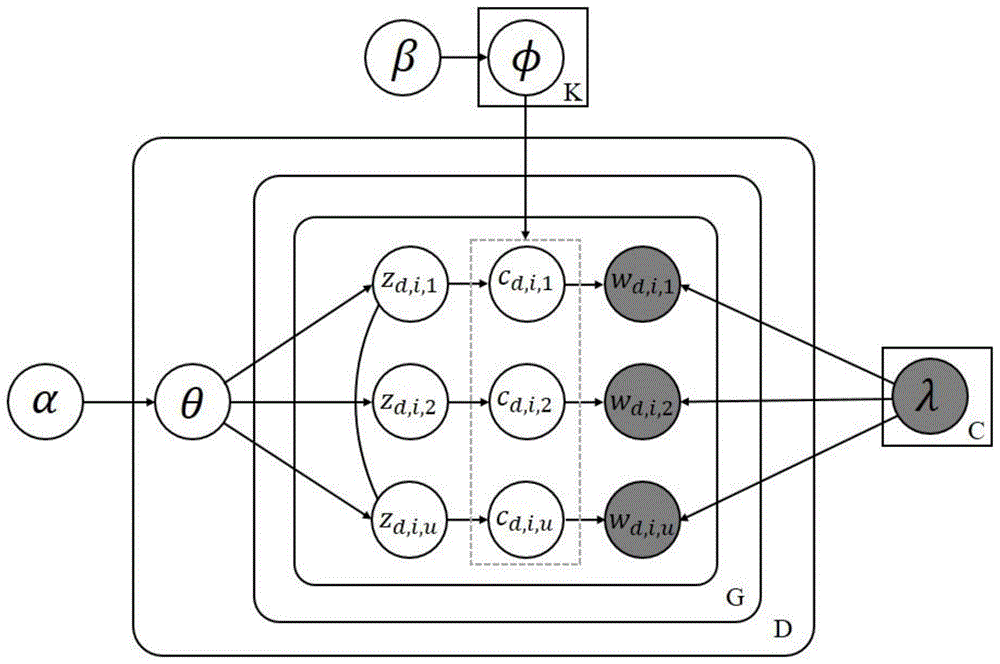
所述基于词组的概念化主题建模方法,借助于概念知识库中概念和实体见的关系,从输入的文本语料中计算出文档-主题参数θ和主题-概念参数φ,具体包括以下步骤:
步骤1:挖掘文本语料中包含的词组,具体为:根据数据集中相邻词的共现,采用词组挖掘方法共现频率大的相邻词作为词组;
其中,优选的,词组挖掘方法为topmine方法;
步骤2:从概念知识库获取概念、实体以及概念和实体间的关系值;
其中,实体包括词和词组,概念和实体间的关系值为每个概念中不同实体的概率;
步骤3:根据数据集的特点和文本挖掘的需求,设置语料库的主题数k、文档-主题的dirichlet分布的先验参数α的值、主题-概念的dirichlet分布的先验参数β的值以及最大迭代次数n,并初始化迭代次数nn为1;
步骤4:对于数据集中每篇文档的每个词组,随机地为该词组中的每个词分配概念;
其中,根据词组在概念知识库中的存在情况,词组中每个词的概念分配包括三种情况:
情况4.1:若概念知识库的实体中包含该词组,随机地为该词组中的每个词分配同一个与该词组相关的概念;
情况4.2:若概念知识库的实体中不包含该词组,对于该词组中的所有属于概念知识库中实体的词,分别为这些词随机地分配与之相关的概念;
情况4.3:若概念知识库的实体中不包含该词组,对于该词组中所有不属于概念知识库中实体的词,将这些词作为原子概念,即等同于概念功能的词;
步骤5:对于数据集中每篇文档的每个词组所分配的概念,随机地分配相同的主题;
步骤6:通过gibbs采样方法迭代地更新数据集中所有文档的所有词组的概念和主题分配,具体包括如下子步骤:
步骤6.1对于数据集中的每篇文档d,统计每个主题z被分配到文档d的次数
步骤6.2对于每个主题z,统计z被分配到数据集中的每个概念c的次数
步骤6.3对于每篇文档d中的每个词组g,重新采样其主题和概念分配,采样的后验概率计算如公式(1);
其中,u为词组gd,i中的词数,词组gd,i的第一个词是其所在文章的第a+1个词;公式(1)是为文档d的第i个词组gd,i分配主题zd,i=k,并且为词组gd,i中的u个词分别分配概念cd,a+1=j1,cd,a+2=j2,…,cd,a+u=ju的后验概率;α为文档-主题的dirichlet先验分布的参数,β为主题-概念的dirichlet先验分布的参数;w,g,c,z分别表示一个词、一个词组、一个概念和一个主题,加黑的w,c,z分别表示数据集中的所有词、概念和主题序列;c-(d,i)表示c中不包含词组gd,i的概念序列,z-(d,i)表示z中不包含词组gd,i的主题序列;∝为正比符号,∏为连乘符号,∑为连加符号;c为数据集的概念总数,k为数据集的主题总数;
情况6.3.1对于情况4.1),p(wd,y|cd,y)为从概念知识库中获取到的词组gd,i在概念cd,y中的概率;
情况6.3.2对于情况4.2),p(wd,y|cd,y)为从概念知识库中获取到的词wd,y在概念cd,y中的概率;
情况6.3.3对于情况4.3),词wd,y为一个原子概念,p(wd,y|cd,y)=1;
步骤6.4,更新数据集中为词组中每个词分配的概念和主题,判断nn是否等于n,若不等nn加1,跳至步骤6.1,若相等,跳至步骤6.5;
步骤6.5,输出为数据集中每篇文档的每个概念分配的主题,以及词组中每个词的概念分配;
步骤7,计算本方法的文档-主题分布参数θ和主题-概念分布参数φ的估计值,如公式(2)和公式(3)所示:
其中,
步骤8根据文档-主题分布参数θ的估计值得出每篇文档中不同主题占的比重;
步骤9根据主题-概念分布参数φ的估计值得出每个主题中不同概念的占比,并结合概念知识库对从文本语料挖掘出的主题进行解释。
有益效果
本发明一种基于词组的概念化主题建模方法,与现有主题建模方法相比,具有如下有益效果:
1.所述建模方法设计了基于词组的概念化主题建模,该方法可以将概念知识库中丰富的实体与概念之间的关系融入主题建模方法中,使主题模型在挖掘文本语料主题的过程中,深入理解文本的含义,同时,本发明以词组而非词为单位对文本语料进行自动的理解与分析,增强了主题挖掘的语义完整性;
2.所述方法为一个文档-主题-概念-词组的四层结构的主题建模方法,不仅可以挖掘出可解释性强的主题,还可以挖掘到主题和概念之间的关系,从而用概念知识库中丰富的概念解释挖掘到的主题。
附图说明
图1是本发明一种基于词组的概念化主题建模方法的模型图。
具体实施方式
下面结合具体实施例以及附图对本发明一种基于词组的概念化主题建模方法进行细致阐述。
实施例1
本实施例叙述了本发明所述方法的流程及其具体实施例。
图1为本发明一种基于词组的概念化主题建模方法的模型图。
假设数据集共包含两篇文档分别为:
文档1:w1,w2,w3,w4,w1,w3,w2;
文档2:w1,w2,w5,w1,w4;
其中,词表为v={w1,w2,w3,w4,w5};
我们将数据集记作:
其中,wi表示词表中的第i个词,wi,j表示第i篇文档的第j个词;
步骤1:挖掘文本语料中包含的词组;
与现有的基于词袋模型的主题建模方法不同,本方法是一种基于词组的主题建模方法,本方法首先根据数据集中相邻词的共现,挖掘共现频率大的相邻词作为词组,这些词组是表达较完整语义的语块,本方法以词组为单位进行主题建模,可以将词的语义相关性融入主题和概念的分配中,增强了挖掘出的主题的语义完整性;
假设共挖掘出5个词组,分别为:
g1=w1,w2,g2=w3,w4,w1,g3=w3,w2,g4=w5,w1,g5=w4;
则:
d={d1={g1,g2,g3},d2={g1,g4,g5}},
记作:{d1={g1,1,g1,2,g1,3},d2={g2,1,g2,2,g2,3}}
其中,gi表示所有词组中的第i个词组,gi,j表示第i篇文档的第j个词组;
步骤2:从概念知识库获取概念、实体以及概念和实体间的关系值;
假设概念知识库中包含3个概念,且每个概念下词组或词的概率如表1:
表1概念知识库中概念-词分布
步骤3:根据数据集的特点和文本挖掘的需求,设置语料库的主题数k=2,dirichlet分布的参数α和β的值均为0.01,迭代次数n=5,并初始化迭代次数nn为1;
步骤4:对于数据集中每篇文档的每个词组,随机地为该词组中的每个词分配概念;
其中,根据词组在概念知识库中的存在情况,词组中的每个词的概念分配包括三种情况:
情况4.1:若概念知识库的实体中包含该词组,随机地为该词组中的每个词分配同一个与该词组相关的概念;
情况4.2:若概念知识库的实体中不包含该词组,对于该词组中的所有属于概念知识库中实体的词,分别为这些词随机地分配与之相关的概念;
情况4.3:若概念知识库的实体中不包含该词组,对于该词组中所有不属于概念知识库中实体的词,将这些词看做原子概念;
对于数据集中的文档d1的词组g1,1,根据表1,g1在概念知识库中,符合情况1),随机为其分配一个相关的概念,假设分配概念c3,则g1,1中的每个词都被分配概念c3,即[c3,c3],其中[]内表示在同一个词组中;
对于数据集中的文档d1中的第二个词组g1,2,根据表1,g2不在概念知识库中,但g2中的词w3、w4和w1在概念知识库中,符合情况2),词w3与概念c2和概念c3相关,随机为其分配一个相关的概念,假设分配概念c2;类似地,为词w4和词w1随机分配概念;假设g1,2被分配的概念序列为[c2,c2,c1];
对于数据集中的文档d2中的第二个词组g2,2,根据表1,g4不在概念知识库中,但g4中的词w1在概念知识库中,符合情况2);词w5不在概念知识库中,符合情况3),将其视为一个原子概念,记作c4;假设g2,2被分配的概念序列为[c4,c3];
相似地,我们为数据集中的所有文档中的词组随机分配概念,结果为:
其中,ci表示概念知识库中的第i个概念,ci,j表示第i篇文档的第j个词分配的概念;
步骤5:对于数据集中每篇文档的每个词组所分配的概念,随机地分配相同的主题;
假设分配结果为:
其中,zi表示第i个主题,zi,j表示第i篇文档的第j个词组的所有概念分配的主题;
步骤6:通过gibbs采样方法迭代地更新数据集中所有文档的所有词组的概念和主题分配;
步骤6.1对于数据集中的每篇文档d,统计每个主题z被分配到文档d的次数
步骤6.2对于每个主题z,统计z被分配到数据集中的每个概念c的次数
步骤6.3对于每篇文档d中的每个词组g,重新采样其主题和概念分配;
g1,1分配主题z1,g1,1中的2个词分别分配概念c1,1=c1,2=c1的后验概率为:
类似地,计算出g1,1分配主题zi,(i∈{1,2})且g1,1中的2个词分别分配概念c1,1=c1,2=ci,(i∈{1,2,3})的后验概率的值,分别记作p1,p2,p3,p4,p5,p6;
从p1,p2,p3,p4,p5,p6中采样出一个对象,假设采样出的对象属于p4,则为词组g1,1主题z2,g1,1中的2个词分别分配概念c1,1=c1,2=c1;
类似地,为数据集中的每个词组重新分配主题和概念;
步骤6.4,更新数据集中为词组中每个词分配的概念和主题,判断nn是否等于5,若不等nn加1,跳至步骤6.1,若相等,跳至步骤6.5;
步骤6.5,输出为数据集中每篇文档的每个概念分配的主题,以及词组中每个词的概念分配;
步骤7,计算本方法的文档-主题分布参数θ和主题-概念分布参数φ的估计值:
步骤8根据文档-主题分布参数θ的估计值得出每篇文档中不同主题占的比重;
步骤9根据主题-概念分布参数φ的估计值得出每个主题中不同概念的占比,并结合概念知识库对从文本语料挖掘出的主题进行解释;
假设本方法建模出的主题1的概念分布为{0.5体育,0.3活动,0.2球类},其中不同概念之间用逗号“,”分隔,数字表示概念在主题中的占比,“体育”、“活动”、“球类”表示概念;假设在概念知识库中,概念“体育”的词分布为{0.4竞技体育,0.3体育课,0.3跑步},概念“活动”的词分布为{0.5公益活动,0.4社团活动,0.1体育活动},概念“球类”的词分布为{0.5篮球,0.3足球,0.2排球};我们可以根据主题1的概念分布并结合概念知识库中概念与实体间的关系,将主题1解释成“运动”;而现有基于词袋且没有融入概念化建模思想的主题模型学习到的主题“运动”的词分布假设是{0.4体育,0.3活动,0.2球,0.1竞技},由于在主题建模过程中缺少词组的较完整语义信息和概念知识库中丰富的概念和实体之间的关系作为指导,将学习到的主题可解释性比本方法差。
实施例2
本实施例叙述了本发明所述方法(pclda)与未使用基于词组的主题建模方法(clda)和未使用概念化的主题建模方法(phraselda)相比的技术优势;评价指标为困惑度,记为ppl,困惑度是主题模型的常用评价指标,困惑度值越小,表示似然性越大,模型越效果越好;
本实例采用从四个学术会议下载的论文全文作为数据集对本发明所述方法进行有效性验证,在数据集相同的情况下,采用相同的参数设置进行对比实验,结果如表2所示;结果表明,本发明与不使用基于词组的主题建模方法和不使用概念化的主题建模方法相比,ppl测评指标明显减少,本方法的主题建模方法优于基准系统;
表2使用基于词组的概念化主题建模方法前后的ppl值对比
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!