数据的核对方法及其装置、计算机设备与流程
【技术领域】
本说明书涉及数据处理技术领域,尤其涉及一种数据的核对方法及其装置、计算机设备。
背景技术:
在互联网领域内,使用数据的双方需要对数据进行同步,并在同步完成后,对双方存储的数据进行核对,以防数据在同步过程中出现问题,而导致双方存储的数据中存在差异数据。
相关技术中,将双方存储的数据按照预设规则进行顺序核对,即便在差异数据很少甚至没有的情况下,也需要对每个数据进行核对,消耗了大量的时间和硬件资源,数据核对的效率很低。
技术实现要素:
本说明书实施例旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本说明书实施例的第一个目的在于提出一种数据的核对方法,以节省数据核对消耗的时间和硬件资源,提升数据核对的效率。
本说明书实施例的第二个目的在于提出一种数据的核对装置。
本说明书实施例的第三个目的在于提出一种计算机设备。
本说明书实施例的第四个目的在于提出一种非临时性计算机可读存储介质。
为达上述目的,本说明书实施例第一方面实施例提出了一种数据的核对方法,包括:获取待核对的第一数据集和第二数据集;其中,所述第一数据集和所述第二数据集中的数据为正整数;对所述第一数据集和所述第二数据集中的数据进行连续异或运算;以及根据连续异或运算的结果,核对所述第一数据集和所述第二数据集中的数据。
和现有技术相比,本说明书实施例在进行数据核对时,通过对两个数据集中的数据进行连续异或运算,来核对两个数据集中的数据是否存在差异,节省了数据核对消耗的时间和硬件资源,提升了数据核对的效率。
另外,本说明书实施例的数据的核对方法,还具有如下附加的技术特征:
可选地,所述对所述第一数据集和所述第二数据集中的数据进行连续异或运算,包括:将所述第一数据集和所述第二数据集中的数据转化为二进制;对转化后的所述第一数据集和所述第二数据集中的数据进行连续异或运算。
可选地,所述根据连续异或运算的结果,核对所述第一数据集和所述第二数据集中的数据,包括:判断所述连续异或运算的结果是否为零;如果是,则确定所述第一数据集和所述第二数据集中的数据完全相同。
可选地,在所述判断所述连续异或运算的结果是否为零之后,还包括:如果不是,则判断所述连续异或运算的结果,是否为所述第一数据集和所述第二数据集的差异数据;如果是,则确定所述第一数据集和所述第二数据集只存在一个所述差异数据。
可选地,在所述判断所述连续异或运算的结果,是否为所述第一数据集和所述第二数据集的差异数据之后,还包括:如果不是,则确定所述连续异或运算的结果中,数值为一的数位;其中,所述数值为一的数位包括第一数位;根据所述第一数位,生成第一分类数;其中,所述第一分类数在所述第一数位上的数值为一,所述第一分类数在所述第一数位以外的其他数位上的数值为零;使用所述第一分类数对所述第一数据集和所述第二数据集中的数据分别进行与运算;根据与运算的结果,对所述第一数据集和所述第二数据集中的数据进行分类,以得到第一数据类和第二数据类;其中,第一数据类中的数据与所述第一分类数的与运算的结果为零,第二数据类中的数据与所述第一分类数的与运算的结果为一;分别对所述第一数据类和所述第二数据类中的数据进行连续异或运算;判断所述第一数据类的连续异或运算的结果,和所述第二数据类的连续异或运算的结果,是否都为所述第一数据集和所述第二数据集的差异数据;如果是,则确定所述第一数据集和所述第二数据集只存在两个所述差异数据。
可选地,在所述判断所述第一数据类的连续异或运算的结果,和所述第二数据类的连续异或运算的结果,是否都为所述第一数据集和所述第二数据集的差异数据之后,还包括:如果不是,则生成第二分类数;其中,所述第二分类数在第二数位上的数值为一,所述第二分类数在所述第二数位以外的其他数位上的数值为零,所述第二数位遍历所述第二分类数的全部数位;使用所述第二分类数对所述第一数据集和所述第二数据集中的数据分别进行与运算;根据与运算的结果,对所述第一数据集和所述第二数据集中的数据进行分类,以得到第三数据类和第四数据类;其中,第三数据类中的数据与所述第二分类数的与运算的结果为零,第四数据类中的数据与所述第二分类数的与运算的结果为一;分别对所述第三数据类和所述第四数据类中的数据进行连续异或运算;判断所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,是否为所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果;如果是,则确定所述第一数据集和所述第二数据集只存在三个所述差异数据。
可选地,在所述判断所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,是否为所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果之后,还包括:如果不是,则对所述第一数据集中的数据进行分组,以生成第一数据组集合;对所述第二数据集中的数据进行分组,以生成第二数据组集合;将所述第一数据组集合中的数据组,分别与所述第二数据组集合中的数据组进行核对,以确定存在所述差异数据的数据组;从每个所述存在差异数据的数据组中,获取所述差异数据,以确定所述第一数据集和第二数据集存在的全部所述差异数据。
可选地,在所述判断所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,是否为所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果之后,还包括:如果不是,则根据预设规则分别对所述第一数据集和所述第二数据集中的数据进行排序;将排序后的所述第一数据集与所述第二数据集中的数据进行依次核对,以确定所述第一数据集和第二数据集存在的全部所述差异数据。
本说明书实施例第二方面实施例提出了一种数据的核对装置,包括:获取模块,用于获取待核对的第一数据集和第二数据集;其中,所述第一数据集和所述第二数据集中的数据为正整数;运算模块,用于对所述第一数据集和所述第二数据集中的数据进行连续异或运算;以及核对模块,用于根据连续异或运算的结果,核对所述第一数据集和所述第二数据集中的数据。
另外,本说明书实施例的数据的核对装置,还具有如下附加的技术特征:
可选地,所述运算模块,包括:转化子模块,用于将所述第一数据集和所述第二数据集中的数据转化为二进制;第一运算子模块,用于对转化后的所述第一数据集和所述第二数据集中的数据进行连续异或运算。
可选地,所述核对模块,包括:第一判断子模块,用于判断所述连续异或运算的结果是否为零;第一确定子模块,用于当所述第一判断子模块确定所述连续异或运算的结果为零时,确定所述第一数据集和所述第二数据集中的数据完全相同。
可选地,所述核对模块,还包括:第二判断子模块,用于当所述第一判断子模块确定所述连续异或运算的结果不为零时,判断所述连续异或运算的结果,是否为所述第一数据集和所述第二数据集的差异数据;第二确定子模块,用于当所述第二判断子模块确定所述连续异或运算的结果,为所述第一数据集和所述第二数据集的差异数据时,确定所述第一数据集和所述第二数据集只存在一个所述差异数据。
可选地,所述核对模块,还包括:第三确定子模块,用于当所述第二判断子模块确定所述连续异或运算的结果,不是所述第一数据集和所述第二数据集的差异数据时,确定所述连续异或运算的结果中,数值为一的数位;其中,所述数值为一的数位包括第一数位;第一生成子模块,用于根据所述第一数位,生成第一分类数;其中,所述第一分类数在所述第一数位上的数值为一,所述第一分类数在所述第一数位以外的其他数位上的数值为零;第二运算子模块,用于使用所述第一分类数对所述第一数据集和所述第二数据集中的数据分别进行与运算;第一分类子模块,用于根据与运算的结果,对所述第一数据集和所述第二数据集中的数据进行分类,以得到第一数据类和第二数据类;其中,第一数据类中的数据与所述第一分类数的与运算的结果为零,第二数据类中的数据与所述第一分类数的与运算的结果为一;第三运算子模块,用于分别对所述第一数据类和所述第二数据类中的数据进行连续异或运算;第三判断子模块,用于判断所述第一数据类的连续异或运算的结果,和所述第二数据类的连续异或运算的结果,是否都为所述第一数据集和所述第二数据集的差异数据;第四确定子模块,用于当所述第三判断子模块确定所述第一数据类的连续异或运算的结果,和所述第二数据类的连续异或运算的结果,都是所述第一数据集和所述第二数据集的差异数据,则确定所述第一数据集和所述第二数据集只存在两个所述差异数据。
可选地,所述核对模块,还包括:第二生成子模块,用于当所述第三判断子模块确定所述第一数据类的连续异或运算的结果,和所述第二数据类的连续异或运算的结果,不是所述第一数据集和所述第二数据集的差异数据时,生成第二分类数;其中,所述第二分类数在第二数位上的数值为一,所述第二分类数在所述第二数位以外的其他数位上的数值为零,所述第二数位遍历所述第二分类数的全部数位;第四运算子模块,用于使用所述第二分类数对所述第一数据集和所述第二数据集中的数据分别进行与运算;第二分类子模块,用于根据与运算的结果,对所述第一数据集和所述第二数据集中的数据进行分类,以得到第三数据类和第四数据类;其中,第三数据类中的数据与所述第二分类数的与运算的结果为零,第四数据类中的数据与所述第二分类数的与运算的结果为一;第五运算子模块,用于分别对所述第三数据类和所述第四数据类中的数据进行连续异或运算;第四判断子模块,用于判断所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,是否为所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果;第五确定子模块,用于当所述第四判断子模块确定所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,就是所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果时,确定所述第一数据集和所述第二数据集只存在三个所述差异数据。
可选地,所述核对模块,还包括:第一分组子模块,用于当所述第四判断子模块确定所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,不是所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果时,对所述第一数据集中的数据进行分组,以生成第一数据组集合;第二分组子模块,用于对所述第二数据集中的数据进行分组,以生成第二数据组集合;第一核对子模块,用于将所述第一数据组集合中的数据组,分别与所述第二数据组集合中的数据组进行核对,以确定存在所述差异数据的数据组;获取子模块,用于从每个所述存在差异数据的数据组中,获取所述差异数据,以确定所述第一数据集和第二数据集存在的全部所述差异数据。
可选地,所述核对模块,还包括:排序子模块,用于当所述第四判断子模块确定所述第三数据类的连续异或运算的结果,和所述第四数据类的连续异或运算的结果,不是所述第一数据集和所述第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果时,根据预设规则分别对所述第一数据集和所述第二数据集中的数据进行排序;第二核对子模块,用于将排序后的所述第一数据集与所述第二数据集中的数据进行依次核对,以确定所述第一数据集和第二数据集存在的全部所述差异数据。
本说明书实施例第三方面实施例提出了一种计算机设备,包括存储器和处理器;所述存储器上存储有可由处理器运行的计算机程序;所述处理器运行所述计算机程序时,执行如前述方法实施例所述的数据的核对方法。
本说明书实施例第四方面实施例提出了一种非临时性计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如前述方法实施例所述的数据的核对方法。
本说明书实施例附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本说明书实施例的实践了解到。
【附图说明】
为了更清楚地说明本说明书实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
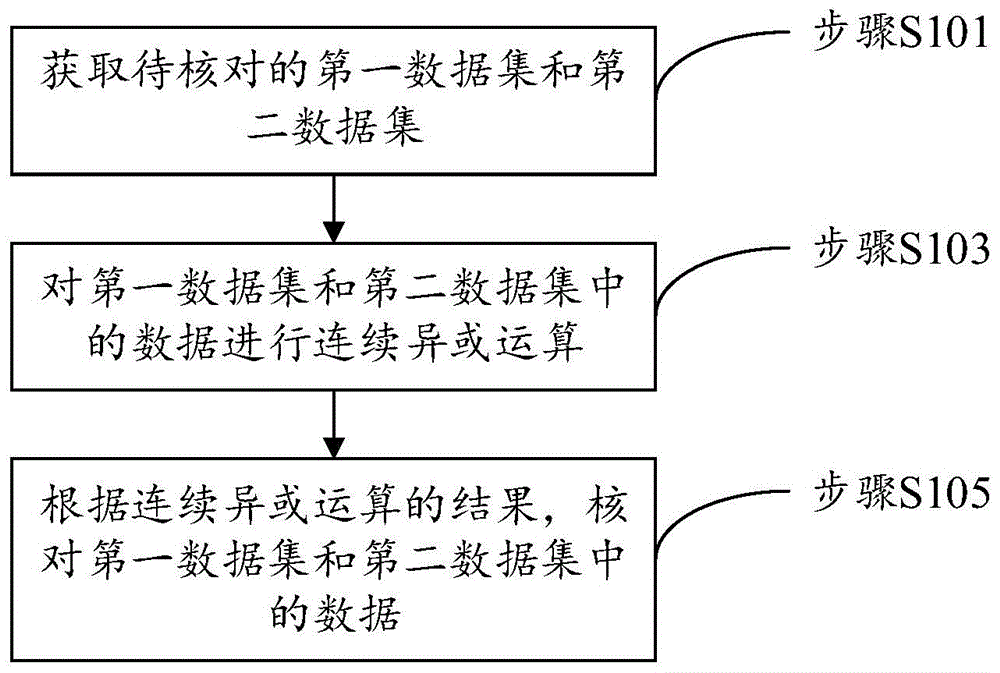
图1为本说明书实施例所提出的一种数据的核对方法的流程示意图;
图2为本说明书实施例所提出的另一种数据的核对方法的流程示意图;
图3为本说明书实施例所提出的又一种数据的核对方法的流程示意图;
图4为本说明书实施例所提出的再一种数据的核对方法的流程示意图;
图5本说明书实施例所提出的数据的核对方法的一个示例的流程图;
图6为本说明书实施例所提出的一种数据的核对装置的结构示意图;
图7为本说明书实施例所提出的另一种数据的核对装置的结构示意图;
图8为本说明书实施例所提出的又一种数据的核对装置的结构示意图;以及
图9为本说明书实施例所提出的再一种数据的核对装置的结构示意图。
【具体实施方式】
下面详细描述本说明书的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本说明书实施例,而不能理解为对本说明书实施例的限制。
下面参考附图描述本说明书实施例的数据的核对方法及其装置、计算机设备。
为了便于说明,将进行同步的一方存储的数据看作一个数据集,将进行同步的双方存储的数据,分别称为第一数据集和第二数据集。
基于前述对背景技术的说明,可以知道,相关技术中,将双方存储的数据按照预设规则进行顺序核对,即便在差异数据很少甚至没有的情况下,也需要对每个数据进行核对,消耗了大量的时间和硬件资源,数据核对的效率很低。
针对这一问题,本说明书实施例提出了一种数据的核对方法,通过对两个数据集中的数据进行连续异或运算,来核对两个数据集中的数据是否存在差异,当差异数据很少甚至没有的情况下,能够快速完成数据核对,节省了数据核对消耗的时间和硬件资源,提升了数据核对的效率。
图1为本说明书实施例所提出的一种数据的核对方法的流程示意图。如图1所示,该方法包括以下步骤:
步骤s101,获取待核对的第一数据集和第二数据集。
其中,第一数据集和第二数据集中的数据为正整数。
需要说明的是,本说明书实施例所提出的数据的核对方法,通过异或运算来实现数据的核对,而异或运算需要在正整数之间实现,因此第一数据集和第二数据集中的数据需要为正整数。
需要特别说明的是,如果进行同步的数据不是正整数,还可以使用正整数作为数据标记,将进行同步的数据(或者数据组)与正整数进行一一对应,并且不同的数据(或者数据组)对应的正整数不同,从而通过核对数据标记来实现对同步的数据(或者数据组)进行核对。那么第一数据集和第二数据集中的数据即为双方存储的数据(或者数据组)对应的数据标记。
步骤s103,对第一数据集和第二数据集中的数据进行连续异或运算。
其中,异或运算是一种逻辑运算,可以视作不带进位的二进制加法,符号为
可以理解,对于二进制数1000和二进制数1000来说,完全相同,对应的异或结果为0000。而对于二进制数1000和二进制数1100来说,从右至左第三位不同,其他位都相同,对应的异或结果0100从右至左第三位为1,其他位都是0。
基于上述分析,可以知道,当两个数据完全相同时,两个数据对应的异或结果为0,当两个数据存在差异时,两个数据对应的异或结果不为0,并且异或结果中为1的数位,就是两个数据存在区别的数位。
在上述的分析中,实现了两个数据之间进行异或运算,来对两个数据进行核对。为了能够对第一数据集和第二数据集中的全部数据进行核对,本说明书实施例需要对第一数据集和第二数据集中的数据进行连续异或运算。
应当理解,为了便于进行异或运算,可以将第一数据集和第二数据集中的数据转化为二进制,对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
步骤s105,根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。
基于上述对异或运算的说明,可以知道,如果连续异或运算的结果为0,说明第一数据集和第二数据集中的数据完全一致。如果连续异或运算的结果不为0,说明第一数据集和第二数据集存在差异数据,需要进一步确定差异数据的数量以及差异数据。
举例来说,第一数据集a包括数据{a1=7,a2=5,a3=6},第二数据集b包括数据{b1=7,b2=5,b3=6},转化为二进制后,a1=111,a2=101,a3=110,b1=111,b2=101,b3=110,
因此,步骤s105,根据连续异或运算的结果,核对第一数据集和第二数据集中的数据,包括:判断连续异或运算的结果是否为零,如果是,则确定第一数据集和第二数据集中的数据完全相同。
综上所述,本说明书实施例所提出的一种数据的核对方法,获取待核对的第一数据集和第二数据集,其中,第一数据集和第二数据集中的数据为正整数。对第一数据集和第二数据集中的数据进行连续异或运算,根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。由此,实现了通过对两个数据集中的数据进行连续异或运算,来核对两个数据集中的数据是否存在差异,节省了数据核对消耗的时间和硬件资源,提升了数据核对的效率。
当第一数据集和第二数据集中只存在一个差异数据时,需要寻找到该差异数据,并确定第一数据集和第二数据集只存在一个差异数据。为此本说明书实施例还提出了另一种数据的核对方法,图2为本说明书实施例所提出的另一种数据的核对方法的流程示意图。如图2所示,该方法包括以下步骤:
步骤s201,获取待核对的第一数据集和第二数据集。
步骤s203,将第一数据集和第二数据集中的数据转化为二进制。
步骤s205,对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
步骤s207,判断连续异或运算的结果是否为零。
步骤s209,如果不是,则判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据。
可以理解,如果连续异或运算的结果不为零,则可以确定第一数据集和第二数据集存在差异数据,为了找到差异数据,本说明书实施例先假设第一数据集和第二数据集只存在一个差异数据,并对该假设进行验证。
步骤s211,如果是,则确定第一数据集和第二数据集只存在一个差异数据。
具体来说,当第一数据集和第二数据集只存在一个差异数据时,第一数据集和第二数据集中的数据包括完全一致的数据和一个差异数据(正整数),完全一致的数据对应的连续异或运算的结果为0,0与差异数据的异或运算结果就是该差异数据。因此,如果连续异或运算的结果就是第一数据集和第二数据集的差异数据,则可以确定第一数据集和第二数据集只存在一个差异数据,并且该差异数据就是连续异或运算的结果。
举例来说,第一数据集a包括数据{a1=7,a2=5,a3=6,a4=1},第二数据集b包括数据{b1=7,b2=5,b3=6},转化为二进制后,a1=111,a2=101,a3=110,a4=001,b1=111,b2=101,b3=110,
需要说明的是,对上述实施例中的步骤s101-步骤s105的解释说明,也适用于本说明书实施例中的步骤s201-步骤s211,此处不再赘述。
从而,实现了当第一数据集和第二数据集中只存在一个差异数据时,能够找到该差异数据,并确定第一数据集和第二数据集只存在一个差异数据。
当第一数据集和第二数据集中只存在两个差异数据时,需要寻找到这两个差异数据,并确定第一数据集和第二数据集只存在两个差异数据。为此本说明书实施例还提出了又一种数据的核对方法,图3为本说明书实施例所提出的又一种数据的核对方法的流程示意图。如图3所示,该方法包括以下步骤:
步骤s301,获取待核对的第一数据集和第二数据集。
步骤s303,将第一数据集和第二数据集中的数据转化为二进制。
步骤s305,对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
步骤s307,判断连续异或运算的结果是否为零。
基于前述说明,可以知道,如果连续异或运算的结果不为零,则可以确定第一数据集和第二数据集存在差异数据。
步骤s309,如果不是,则判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据。
基于前述说明,可以知道,在确定了第一数据集和第二数据集存在差异数据后,本说明书实施例先假设第一数据集和第二数据集只存在一个差异数据,并对该假设进行验证。
步骤s311,如果不是,则确定连续异或运算的结果中,数值为一的数位。
其中,数值为一的数位包括第一数位。
在确定了连续异或运算的结果不是第一数据集和第二数据集的差异数据时,也就确定了第一数据集和第二数据集不只存在一个差异数据,接着本说明书实施例假设第一数据集和第二数据集只存在两个差异数据,并对该假设进行验证。
具体来说,基于前述对异或运算的原理的说明,可以知道,异或运算的结果中,数值为一的数位,对应于两个数据存在区别的数位。因此可以根据连续异或运算的结果中,数值为一的数位,来确定存在区别的两个差异数据。
可以理解,连续异或运算的结果可能只有一个数位上为一,也可能在多个数位上为一。如果连续异或运算的结果只有一个数位上为一,则将该数位作为第一数位,如果连续异或运算的结果在多个数位上为一,则从中选取任一位作为第一数位。
举例来说,如果第一数据集a包括数据{a1=3,a2=5,a3=6},第二数据集b包括数据{b1=7,b2=5,b3=6},转化为二进制后,a1=011,a2=101,a3=110,b1=111,b2=101,b3=110,
如果第一数据集a包括数据{a1=1,a2=5,a3=6},第二数据集b包括数据{b1=7,b2=5,b3=6},转化为二进制后,a1=001,a2=101,a3=110,b1=111,b2=101,b3=110,
步骤s313,根据第一数位,生成第一分类数。
其中,第一分类数在第一数位上的数值为一,第一分类数在第一数位以外的其他数位上的数值为零。
举例来说,在上述例子中,如果将从右至左第2位作为第一数位,则生成的第一分类数为010,如果将从右至左第2位作为第一数位,则生成的第一分类数为100。
步骤s315,使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算。
其中,与运算也是一种逻辑运算,符号为“&”。具体来说,1&1=1,0&1=0,0&0=0,1&0=0。
基于对与运算的说明,可以知道,使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算,由于第一分类数在第一数位以外的其他数位上的数值为零,因此与运算的结果在第一数位以外的其他数位上的数值也为零。如果第一数据集和第二数据集中的数据在第一数位上的数值为一,那么对应的与运算的结果在第一数位上的数值也为一,如果第一数据集和第二数据集中的数据在第一数位上的数值为零,那么对应的与运算的结果在第一数位上的数值也为零。
应当理解,如果两个数据完全一致,那么在这两个数据在第一数位上的数值也应当相同,对应的与运算的结果也应当相同。
如果第一数据集和第二数据集只存在两个差异数据,那么完全一致的数据对应的连续异或运算的结果为0,连续异或运算的结果就是两个差异数据的异或运算的结果,那么异或运算的结果中,数值为一的数位,就是两个差异数据存在区别的数位。从中选取第一数位,在第一数位上,两个差异数据的数值分别为0和1。
使用第一分类数分别与两个差异数据进行与运算,对应的与运算的结果也分别为0和1。
步骤s317,根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第一数据类和第二数据类。
其中,第一数据类中的数据与第一分类数的与运算的结果为零,第二数据类中的数据与第一分类数的与运算的结果为一。
基于上述说明,可以知道,如果第一数据集和第二数据集只存在两个差异数据,那么两个差异数据将被分别分至第一数据类和第二数据类中,且每个数据类应当包括完全一致的数据和一个差异数据。
步骤s319,分别对第一数据类和第二数据类中的数据进行连续异或运算。
如果第一数据集和第二数据集只存在两个差异数据,那么对第一数据类中的数据进行连续异或运算的结果即为第一个差异数据,对第二数据类中的数据进行连续异或运算的结果即为第二个差异数据。
步骤s321,判断第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,是否都为第一数据集和第二数据集的差异数据。
可以理解,通过验证第一数据类的连续异或运算的结果和第二数据类的连续异或运算的结果,即可验证第一数据集和第二数据集是否只存在两个差异数据。
步骤s323,如果是,则确定第一数据集和第二数据集只存在两个差异数据。
应当理解,如果第一数据类的连续异或运算的结果和第二数据类的连续异或运算的结果,都为第一数据集和第二数据集的差异数据,则可以确定第一数据集和第二数据集只存在两个差异数据,并且第一个差异数据是第一数据类的连续异或运算的结果,第二个差异数据是第二数据类的连续异或运算的结果。
需要说明的是,对上述实施例中的步骤s201-步骤s211的解释说明,也适用于本说明书实施例中的步骤s301-步骤s323,此处不再赘述。
从而,实现了当第一数据集和第二数据集中只存在两个差异数据时,能够找到这两个差异数据,并确定第一数据集和第二数据集只存在两个差异数据。
当第一数据集和第二数据集中只存在三个差异数据时,需要寻找到这三个差异数据,并确定第一数据集和第二数据集只存在三个差异数据。为此本说明书实施例还提出了再一种数据的核对方法,图4为本说明书实施例所提出的再一种数据的核对方法的流程示意图。如图4所示,该方法包括以下步骤:
步骤s401,获取待核对的第一数据集和第二数据集。
步骤s403,将第一数据集和第二数据集中的数据转化为二进制。
步骤s405,对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
步骤s407,判断连续异或运算的结果是否为零。
基于前述说明,可以知道,如果连续异或运算的结果不为零,则可以确定第一数据集和第二数据集存在差异数据。
步骤s409,如果不是,则判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据。
基于前述说明,可以知道,在确定了第一数据集和第二数据集存在差异数据后,本说明书实施例先假设第一数据集和第二数据集只存在一个差异数据,并对该假设进行验证。
步骤s411,如果不是,则确定连续异或运算的结果中,数值为一的数位。
在确定了连续异或运算的结果不是第一数据集和第二数据集的差异数据时,也就确定了第一数据集和第二数据集不只存在一个差异数据,接着本说明书实施例假设第一数据集和第二数据集只存在两个差异数据,并对该假设进行验证。
步骤s413,根据第一数位,生成第一分类数。
步骤s415,使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算。
步骤s417,根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第一数据类和第二数据类。
步骤s419,分别对第一数据类和第二数据类中的数据进行连续异或运算。
步骤s421,判断第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,是否都为第一数据集和第二数据集的差异数据。
步骤s423,如果不是,则生成第二分类数。
其中,第二分类数在第二数位上的数值为一,第二分类数在第二数位以外的其他数位上的数值为零,第二数位遍历第二分类数的全部数位。
在确定了第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,不是第一数据集和第二数据集的差异数据时,也就确定了第一数据集和第二数据集不只存在两个差异数据,然后本说明书实施例假设第一数据集和第二数据集只存在三个差异数据,并对该假设进行验证。
需要说明的是,如果第一数据集和第二数据集只存在三个差异数据,则三个差异数据必然存在某一位不完全相同。
下面进行证明,将三个差异数据分别设为k1、k2、k3,
定义函数f(n)为保留数字n的二进制表示中最后一位1,而其他位都变为0,那么
若k1、k2、k3的第m位都为1,则m的第m位也为1,则
若k1、k2、k3的第m位都为0,则m的第m位也为0,则
因此,如果第一数据集和第二数据集只存在三个差异数据,k1、k2、k3在第m位上不可能相同,因此当第二数位为第m位时,必然能够通过三个差异数据在第二数位上的不同,对三个差异数据进行区分。
需要说明的是,上述证明过程只是为了说明三个差异数据必然存在某一位不完全相同,第二数位除了是上述的第m位,还可以是其他数位,同样能够让生成的第二分类数对三个差异数据进行区分。本说明书实施例让第二数位遍历第二分类数的全部数位,依次尝试,直到能够对三个差异数据进行区分。
步骤s425,使用第二分类数对第一数据集和第二数据集中的数据分别进行与运算。
和前述使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算相类似,在第二数位上三个差异数据不完全相同,分别与第二分类数进行与运算,对应的结果在第二数位上也不完全相同,至少一个差异数据在第二数位上为1,至少一个差异数据在第二数位上为0。
步骤s427,根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第三数据类和第四数据类。
其中,第三数据类中的数据与第二分类数的与运算的结果为零,第四数据类中的数据与第二分类数的与运算的结果为一。
基于上述说明,可以知道,至少一个差异数据在第三数据类中,至少一个差异数据在第四数据类中。一种可能的情况是,第三数据类包括一个差异数据和完全一致的数据,第四数据类中包括两个差异数据和完全一致的数据。另一种可能的情况是,第三数据类包括两个差异数据和完全一致的数据,第四数据类中包括一个差异数据和完全一致的数据。
步骤s429,分别对第三数据类和第四数据类中的数据进行连续异或运算。
步骤s431,判断第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,是否为第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果。
应当理解,在第一数据集和第二数据集只存在三个差异数据这一假设下,当一个数据类中包括一个差异数据和完全一致的数据时,该数据类的连续异或运算的结果应当是第一数据集和第二数据集的第一差异数据。当一个数据类中包括两个差异数据和完全一致的数据时,该数据类的连续异或运算的结果应当是第二差异数据与第三差异数据的异或运算的结果。使用前述第一数据集和第二数据集只存在两个差异数据的方法进行处理,根据该数据类的连续异或运算的结果,生成第一分类数,使用第一分类数对该数据类中的数据进行再分类,使得第二差异数据和第三差异数据被分到两个不同的数据小类中,分别对两个不同的数据小类中的数据进行连续异或运算,得到的结果应当是第一数据集和第二数据集的第二差异数据和第三差异数据。
通过验证上述计算得到的三个结果是否为第一数据集和第二数据集的三个差异数据,即可验证第一数据集和第二数据集是否只存在三个差异数据。
步骤s433,如果是,则确定第一数据集和第二数据集只存在三个差异数据。
应当理解,如果第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,就是第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果,则可以确定第一数据集和第二数据集只存在三个差异数据,并且三个差异数据为上述运算得到的结果。
需要说明的是,对上述实施例中的步骤s301-步骤s323的解释说明,也适用于本说明书实施例中的步骤s401-步骤s433,此处不再赘述。
从而,实现了当第一数据集和第二数据集中只存在三个差异数据时,能够找到这三个差异数据,并确定第一数据集和第二数据集只存在三个差异数据。
此外,如果第一数据集和第二数据集存在更多的差异数据,则上述的假设无法成立,也就是说,第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,不是第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果,为了实现对数据进行核对,本说明书实施例还采取了其他的数据核对手段。
第一种可能的实现方式是,包括以下步骤:
步骤s11,对第一数据集中的数据进行分组,以生成第一数据组集合。
步骤s13,对第二数据集中的数据进行分组,以生成第二数据组集合。
步骤s15,将第一数据组集合中的数据组,分别与第二数据组集合中的数据组进行核对,以确定存在差异数据的数据组。
步骤s17,从每个存在差异数据的数据组中,获取差异数据,以确定第一数据集和第二数据集存在的全部差异数据。
上述步骤先对第一数据集合和第二数据集合中的数据按照预设规则进行分组,将分组后的数据进行核对。
第二种可能的实现方式是,包括以下步骤:
步骤s21,根据预设规则分别对第一数据集和第二数据集中的数据进行排序。
步骤s23,将排序后的第一数据集与第二数据集中的数据进行依次核对,以确定第一数据集和第二数据集存在的全部差异数据。
上述步骤先对第一数据集合和第二数据集合中的数据按照预设规则进行排序,将排序后的数据进行核对。
为了更加清楚地说明本说明书实施例所提出的数据的核对方法,下面进行举例说明。
图5本说明书实施例所提出的数据的核对方法的一个示例的流程图,如图5所示,首先获取待核对的第一数据集和第二数据集,对第一数据集和第二数据集进行连续异或运算,判断连续异或运算的结果是否为零,如果为零,则确定第一数据集和第二数据集中的数据完全相同。
如果不为零,则确定第一数据集和第二数据集存在差异数据,首先假设第一数据集和第二数据集只存在一个差异数据,判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据,如果是,则确定第一数据集和第二数据集只存在一个差异数据。
如果不是,则说明第一数据集和第二数据集存在大于一个的差异数据,假设一数据集和第二数据集只存在两个差异数据。确定连续异或运算的结果中,数值为一的数位,从中选取第一数位,并生成第一分类数。使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算,根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第一数据类和第二数据类,分别对第一数据类和第二数据类中的数据进行连续异或运算。判断第一数据类的连续异或运算的结果,是否都为第一数据集和第二数据集的差异数据,如果是,则确定第一数据集和第二数据集只存在两个差异数据。
如果不是,则说明第一数据集和第二数据集存在大于两个的差异数据,假设一数据集和第二数据集只存在三个差异数据。生成第二分类数,使用第二分类数对第一数据集和第二数据集中的数据分别进行与运算,根据与运算的结构,对第一数据集和第二数据集中的数据进行分类,以得到第三数据类和第四数据类。分别对第三数据类和第四数据类中的数据进行连续异或运算,判断第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结构,是否为第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果,如果是,则确定第一数据集和第二数据集只存在三个差异数据。
如果不是,则说明第一数据集和第二数据集存在大于三个的差异数据,则需要对第一数据集和第二数据集中的数据进行分类或者排序,对分类或者排序后的数据进行依次核对。
应当理解,当第一数据集和第二数据集完全相同,或者仅存在一个、两个、三个差异数据时,上述实施例能够快速完成数据核对,而当差异数据数量较多时,仍然需要消耗较多的时间和硬件资源。
此外,在上述对第一数据集和第二数据集中的数据进行分类和连续异或运算时,可以边分类边计算,以减少内存的占用。举例来说,数据包括{1,1,2,2,3,3,4,4,5,6},连续异或结果为3(二进制为11),使用的第一分类数为01,那么在分类时,1&1=1,res1=1;1&1=1,
为了实现上述实施例,本说明书还提出了一种数据的核对装置,图6为本说明书实施例所提出的一种数据的核对装置的结构示意图。如图6所示,该装置包括:获取模块510,运算模块520,核对模块530。
获取模块510,用于获取待核对的第一数据集和第二数据集。
其中,第一数据集和第二数据集中的数据为正整数。
运算模块520,用于对第一数据集和第二数据集中的数据进行连续异或运算。
核对模块530,用于根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。
进一步地,为了便于进行异或运算,一种可能的实现方式是,运算模块520,包括:转化子模块521,用于将第一数据集和第二数据集中的数据转化为二进制。第一运算子模块522,用于对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
进一步地,为了确定第一数据集和第二数据集中的数据完全相同,一种可能的实现方式是,核对模块530,包括:第一判断子模块531,用于判断连续异或运算的结果是否为零。第一确定子模块532,用于当第一判断子模块531确定连续异或运算的结果为零时,确定第一数据集和第二数据集中的数据完全相同。
需要说明的是,前述对数据的核对方法实施例的解释说明也适用于该实施例的数据的核对装置,此处不再赘述。
综上所述,本说明书实施例所提出的一种数据的核对装置,获取待核对的第一数据集和第二数据集,其中,第一数据集和第二数据集中的数据为正整数。对第一数据集和第二数据集中的数据进行连续异或运算,根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。由此,实现了通过对两个数据集中的数据进行连续异或运算,来核对两个数据集中的数据是否存在差异,节省了数据核对消耗的时间和硬件资源,提升了数据核对的效率。
为了实现上述实施例,本说明书还提出了另一种数据的核对装置,图7为本说明书实施例所提出的另一种数据的核对装置的结构示意图。如图7所示,该装置包括:获取模块610,运算模块620,核对模块630。
获取模块610,用于获取待核对的第一数据集和第二数据集。
其中,第一数据集和第二数据集中的数据为正整数。
运算模块620,用于对第一数据集和第二数据集中的数据进行连续异或运算。
核对模块630,用于根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。
其中,运算模块620,包括:转化子模块621,用于将第一数据集和第二数据集中的数据转化为二进制。第一运算子模块622,用于对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
核对模块630,包括:第一判断子模块631,用于判断连续异或运算的结果是否为零。第一确定子模块632,用于当第一判断子模块631确定连续异或运算的结果为零时,确定第一数据集和第二数据集中的数据完全相同。第二判断子模块633,用于当第一判断子模块631确定连续异或运算的结果不为零时,判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据。第二确定子模块634,用于当第二判断子模块633确定连续异或运算的结果,为第一数据集和第二数据集的差异数据时,确定第一数据集和第二数据集只存在一个差异数据。
需要说明的是,前述对数据的核对方法实施例的解释说明也适用于该实施例的数据的核对装置,此处不再赘述。
从而,实现了当第一数据集和第二数据集中只存在一个差异数据时,能够找到该差异数据,并确定第一数据集和第二数据集只存在一个差异数据。
为了实现上述实施例,本说明书还提出了又一种数据的核对装置,图8为本说明书实施例所提出的又一种数据的核对装置的结构示意图。如图8所示,该装置包括:获取模块710,运算模块720,核对模块730。
获取模块710,用于获取待核对的第一数据集和第二数据集。
其中,第一数据集和第二数据集中的数据为正整数。
运算模块720,用于对第一数据集和第二数据集中的数据进行连续异或运算。
核对模块730,用于根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。
其中,运算模块720,包括:转化子模块721,用于将第一数据集和第二数据集中的数据转化为二进制。第一运算子模块722,用于对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
核对模块730,包括:第一判断子模块731,用于判断连续异或运算的结果是否为零。第一确定子模块732,用于当第一判断子模块731确定连续异或运算的结果为零时,确定第一数据集和第二数据集中的数据完全相同。第二判断子模块733,用于当第一判断子模块731确定连续异或运算的结果不为零时,判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据。第二确定子模块734,用于当第二判断子模块733确定连续异或运算的结果,为第一数据集和第二数据集的差异数据时,确定第一数据集和第二数据集只存在一个差异数据。第三确定子模块735,用于当第二判断子模块733确定连续异或运算的结果,不是第一数据集和第二数据集的差异数据时,确定连续异或运算的结果中,数值为一的数位。其中,数值为一的数位包括第一数位。第一生成子模块736,用于根据第一数位,生成第一分类数。其中,第一分类数在第一数位上的数值为一,第一分类数在第一数位以外的其他数位上的数值为零。第二运算子模块737,用于使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算。第一分类子模块738,用于根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第一数据类和第二数据类。其中,第一数据类中的数据与第一分类数的与运算的结果为零,第二数据类中的数据与第一分类数的与运算的结果为一。第三运算子模块739,用于分别对第一数据类和第二数据类中的数据进行连续异或运算。第三判断子模块7310,用于判断第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,是否都为第一数据集和第二数据集的差异数据。第四确定子模块7311,用于当第三判断子模块7310确定第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,都是第一数据集和第二数据集的差异数据,则确定第一数据集和第二数据集只存在两个差异数据。
需要说明的是,前述对数据的核对方法实施例的解释说明也适用于该实施例的数据的核对装置,此处不再赘述。
从而,实现了当第一数据集和第二数据集中只存在两个差异数据时,能够找到这两个差异数据,并确定第一数据集和第二数据集只存在两个差异数据。
为了实现上述实施例,本说明书还提出了再一种数据的核对装置,图9为本说明书实施例所提出的再一种数据的核对装置的结构示意图。如图9所示,该装置包括:获取模块810,运算模块820,核对模块830。
获取模块810,用于获取待核对的第一数据集和第二数据集。
其中,第一数据集和第二数据集中的数据为正整数。
运算模块820,用于对第一数据集和第二数据集中的数据进行连续异或运算。
核对模块830,用于根据连续异或运算的结果,核对第一数据集和第二数据集中的数据。
其中,运算模块820,包括:转化子模块821,用于将第一数据集和第二数据集中的数据转化为二进制。第一运算子模块822,用于对转化后的第一数据集和第二数据集中的数据进行连续异或运算。
核对模块830,包括:第一判断子模块831,用于判断连续异或运算的结果是否为零。第一确定子模块832,用于当第一判断子模块831确定连续异或运算的结果为零时,确定第一数据集和第二数据集中的数据完全相同。第二判断子模块833,用于当第一判断子模块831确定连续异或运算的结果不为零时,判断连续异或运算的结果,是否为第一数据集和第二数据集的差异数据。第二确定子模块834,用于当第二判断子模块833确定连续异或运算的结果,为第一数据集和第二数据集的差异数据时,确定第一数据集和第二数据集只存在一个差异数据。第三确定子模块835,用于当第二判断子模块833确定连续异或运算的结果,不是第一数据集和第二数据集的差异数据时,确定连续异或运算的结果中,数值为一的数位。其中,数值为一的数位包括第一数位。第一生成子模块836,用于根据第一数位,生成第一分类数。其中,第一分类数在第一数位上的数值为一,第一分类数在第一数位以外的其他数位上的数值为零。第二运算子模块837,用于使用第一分类数对第一数据集和第二数据集中的数据分别进行与运算。第一分类子模块838,用于根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第一数据类和第二数据类。其中,第一数据类中的数据与第一分类数的与运算的结果为零,第二数据类中的数据与第一分类数的与运算的结果为一。第三运算子模块839,用于分别对第一数据类和第二数据类中的数据进行连续异或运算。第三判断子模块8310,用于判断第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,是否都为第一数据集和第二数据集的差异数据。第四确定子模块8311,用于当第三判断子模块8310确定第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,都是第一数据集和第二数据集的差异数据,则确定第一数据集和第二数据集只存在两个差异数据。第二生成子模块8312,用于当第三判断子模块确定第一数据类的连续异或运算的结果,和第二数据类的连续异或运算的结果,不是第一数据集和第二数据集的差异数据时,生成第二分类数。其中,第二分类数在第二数位上的数值为一,第二分类数在第二数位以外的其他数位上的数值为零,第二数位遍历第二分类数的全部数位。第四运算子模块8313,用于使用第二分类数对第一数据集和第二数据集中的数据分别进行与运算。第二分类子模块8314,用于根据与运算的结果,对第一数据集和第二数据集中的数据进行分类,以得到第三数据类和第四数据类。其中,第三数据类中的数据与第二分类数的与运算的结果为零,第四数据类中的数据与第二分类数的与运算的结果为一。第五运算子模块8315,用于分别对第三数据类和第四数据类中的数据进行连续异或运算。第四判断子模块8316,用于判断第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,是否为第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果。第五确定子模块8317,用于当第四判断子模块8316确定第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,就是第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果时,确定第一数据集和第二数据集只存在三个差异数据。
进一步地,为了在差异数据较多的情况下能够对数据进行核对,一种可能的实现方式是,核对模块830,还包括:第一分组子模块8318,用于当第四判断子模块8316确定第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,不是第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果时,对第一数据集中的数据进行分组,以生成第一数据组集合。第二分组子模块8319,用于对第二数据集中的数据进行分组,以生成第二数据组集合。第一核对子模块8320,用于将第一数据组集合中的数据组,分别与第二数据组集合中的数据组进行核对,以确定存在差异数据的数据组。获取子模块8321,用于从每个存在差异数据的数据组中,获取差异数据,以确定第一数据集和第二数据集存在的全部差异数据。
另一种可能的实现方式是,核对模块830,还包括:排序子模块8322,用于当第四判断子模块8316确定第三数据类的连续异或运算的结果,和第四数据类的连续异或运算的结果,不是第一数据集和第二数据集的第一差异数据,以及第二差异数据与第三差异数据的异或运算的结果时,根据预设规则分别对第一数据集和第二数据集中的数据进行排序。第二核对子模块8323,用于将排序后的第一数据集与第二数据集中的数据进行依次核对,以确定第一数据集和第二数据集存在的全部差异数据。
需要说明的是,前述对数据的核对方法实施例的解释说明也适用于该实施例的数据的核对装置,此处不再赘述。
从而,实现了当第一数据集和第二数据集中只存在三个差异数据时,能够找到这三个差异数据,并确定第一数据集和第二数据集只存在三个差异数据。
为了实现上述实施例,本说明书实施例还提出一种计算机设备,包括存储器和处理器;存储器上存储有可由处理器运行的计算机程序;当处理器运行计算机程序时,执行如前述方法实施例的数据的核对方法。
为了实现上述实施例,实施例还提出一种非临时性计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如前述方法实施例的数据的核对方法。
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本说明书实施例的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书实施例中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本说明书实施例中的具体含义。
在本说明书实施例中,除非另有明确的规定和限定,第一特征在第二特征“上”或“下”可以是第一和第二特征直接接触,或第一和第二特征通过中间媒介间接接触。而且,第一特征在第二特征“之上”、“上方”和“上面”可是第一特征在第二特征正上方或斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”可以是第一特征在第二特征正下方或斜下方,或仅仅表示第一特征水平高度小于第二特征。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本说明书实施例的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!