一种基于多视融合多示例学习的国画图像分类方法与流程
本发明涉及图像分类技术领域,特别涉及一种基于多视融合多示例学习的国画图像分类方法。
背景技术:
许多传统书画现存数量很少且十分珍贵,且大部分作品分布于世界各地的博物馆中。但随着计算机网络的发展与普及,通过数字化形式浏览和查阅中国古书画,人们不但能欣赏到优秀的、大师级的国画作品,而且国画鉴定人员还可以获得更多的信息,提高真伪鉴定的准确性。另外,由于国画的种类繁多,自古到今有大量的名人名作出现,随着数字化技术的发展,国画数字图像的数量也将会以惊人的速度增长,数字博物馆或数字图书馆为了便于大家查找或浏览各自感兴趣的国画图像,就得建立高效的存储与管理系统。因此,对国画图像的特征提取与自动分类技术进行研究,具有重要应用价值。
随着互联网技术和国画事业的蓬勃发展,如何对海量的艺术作品实现高效的管理和检索成为迫切需要解决的问题。国画作为中国文化艺术的瑰宝,受到人们越来越多的关注,早期的国画图像分类技术局限在人工标注,工作量庞大,且标注精度不高。因此,通过计算机自动分析国画图像内容以实现对国画的数字化管理技术应运而生,其中,国画图像分类技术是数字化管理系统的重要组成部分,具有重要应用价值。
国画是使用毛笔和墨在绢、宣纸、帛上作的画,属于中国传统绘画形式之一,它用其特有的笔墨绘画技巧为人们展示对象的神色、形态、风韵。国画的分类方式多样,按照内容,可分为花鸟画、古树画、江南水乡、人物画、水墨画等。国画注重意境,讲究借景抒情或托物言志,因此,对于不同的绘画内容,国画的表现手法也大不相同文献[1]徐茜.浅析国画艺术的意境表现手法[j].大众文艺,2012(22):25-26。
目前对国画图像分类的相关算法可分为两种:基于浅层特征和基于深度学习的分类方法.文献[2]lee,sg,cha,etal.styleclassificationandvisualizationofartpainting'sgenreusingself-organizingmaps[j].humancentriccomputingandinformationsciences,2016,6(7):1-11.基于颜色的统计计算提取图像全局特征,并通过分隔绘画对象提取图像结构特征,实现分类.文献[3]m.j.sun,d.zang,z.wang,etal.montecarloconvexhullmodelforclassificationoftraditionalchinesepaintings[j].neurocomputig,2016,171(1):788-797.采用蒙特卡洛凸壳特征选择模型来整合基础特征描述子,再使用支持向量机对不同艺术家的作品实现分类。文献[4]高峰,聂婕,黄磊,段凌宇等.基于表现手法的国画分类方法研究[j].计算机学报.2017,40(12):2871-2882.提出融合sift特征检测子和边缘检测得到国画关键区域,对关键区域视觉特征及内部领域差异性进行描述得到图像特征,采用融合不同维度特征,级联分类策略实现分类。文献[5]陈俊杰,杜雅娟,李海芳,中国画的特征提取及分类[j].计算机工程与应用,2008,44(15):166-169.分析国画图像的多维低阶特征与高阶语义之间的相关性,采用支持向量机实现语义分类。文献[6]j.li,j.z.wang.studingdigitalimageryofancientpaintingsbymixturesofstachasticodels[j].ieeetransactionsonimageprocessing,2004,13(3):340-35.设计了对中国画分类的通用框架,用混合二维多分辨率马尔科夫模型(mhmm)来表示不同艺术家的笔画属性实现分类。文献[7]盛家川,基于小波变换的国画特征提取
及分类[j],计算机科学,2014,41(2):317-319.提出在小波域内利用不同分辨率及频带的图像结构所展现的艺术风格的不同表现形式来获得国画艺术深度信息的方法,再利用3种不同的分类器进行分类.文献[8]j.c.sheng,j.m.jiang,recognitionofchineseartistsviawindowedandentropybalancedfusioninclassificationoftheirauthoredinkandwashpaintings(iwps)[j].patternrecognition,2014,47(2):612-622提出提取基于直方图的局部特征来表示国画图像风格,并设计了一种窗口和熵平衡的融合方案优化分类结果。这类方法通常是利用人工经验或特征转换来抽取特征,对算法性能带来了限制,基于深度学习的方法克服了此问题,文献[9]kevinalfiantojangtjik,trang-thiho,mei-chenyeh,etal.acnn-lstmframeworkforauthorshipclassificationofpaintings[c].2017ieeeinternationalconferenceonimageprocessing,beijing:china,2017:2866-2870.提出构造国画图像的多尺度金字塔,再学习sh-cnn模型返回多个标签,采用自适应融合方法实现分类。文献[10]m.j.sun,d.zhang,j.c.ren,etal.brushstrokebasedsparsehybridconvolutionalneuralnetworksforauthorclassificationofchineseink-washpaintings[c].2015ieeeinternatio-nalconferenceonimageprocessing(icip),quebec,canada.2015:626-630.提出基于稀疏编码混合深度学习神经网络的方法从中国水墨画的笔划中提取不同画家作画风格特征从而实现分类。文献[11]盛家川,李玉芝.国画的艺术目标分割及深度学习与分类[j].中国图象图形学报,2018,23(8):1193-1206.将国画对象通过最大相似度区域合并分割成艺术目标,利用深度卷积神经网络(o-cnn)描述其语义特征,最后引入支持向量机对艺术目标进行分类.国画中基于深度学习使上述算法在分类精度和速度都有所提高,但是对国画图像局部表现手法的分析研究较少。
随着数字化技术的发展,中国画数字图像的数量越来越多,且还在以惊人的速度增长,特别是随着中国画图像数字博物馆或数字图书馆的建立,则利用计算机对中国画数字图像进行自动分类,在国画管理与真伪鉴定应用中具有重要意义。为了帮助中国画鉴定人员提高真伪鉴定的效率与准确性。本发明研究了一种基于多示例学习(mil)的国画图像分类方法,实现对国画图像风格类型及细节信息的自动捕获,建立国画风格分类模型,实现国画图像自动分类功能。项目的研究成果也可用于刑侦、打击文物走私等领域,在保护我国的珍贵文化遗产中具有重要意义。
随着互联网技术和国画事业的蓬勃发展,如何对海量数字化的艺术作品实现高效的分类与管理,已成为数字图书馆与数字博物馆迫切需要解决的问题。国画作为中国文化艺术的瑰宝,受到人们越来越多的关注,早期的国画图像分类技术局限在人工标注,工作量庞大且标注精度不高。因此,通过计算机自动分析国画图像的手笔手法与绘画风格,以实现对国画的数字化管理应运而生,其中,图画国像自动分类作为管理系统的重要组成部分,具有重要意义。
近年来,随着多媒体、计算机、通信、internet技术的迅速发展,已有国画图像分类方法主要是基于内容的方法,即根据国画图像所包含的色彩、纹理、形状等信息,直观地比较国画图像特征之间的相似度,从而实现分类。这些方法并不试图分析国画图像所表达的语义知识,很难满足国画图像分类的应用需求。所以,基于内容的国画图像分类存在着很多问题有待解决。实际上,传统的低层视觉特征并不能很好的表达国画图像的内在语义,人们判断国画图像的相似性并非仅仅建立在图像视觉特征的相似性上,而主要根据国画图像的局部表现手法及整体风格,而不是简单的颜色、形状、纹理等全局特征。
要实现国画图像自动分类,要解决的技术问题有:
(1)国画图像的特征提取问题。由于“语义鸿沟”的存在,在国画图像分类时,单纯利用国画图像的全局视觉特征,很难全方位地反映国画图像的局部表现手法而实现风格分类。
(2)没有考虑不同特征存在性质差异的问题。在国画图像特征提取,通常是把不同性质的底层视觉特征串联起来作为一个整体来使用,没有将不同性质的特征分开处理,因为不同性质的特征其提取原理不同,在数值上会存在很大的差异,则导致不同特征因数值上的较大差异而发生特征淹没的问题,即数值小的特征被数值大的特征淹没掉,在分类过程中发挥不出应有的作用。
(3)国画图像的语义学习问题。与传统的自然场景图像不同,国画图像的特点是“以形写神”,其语义信息更加抽象和丰富。因此,为了在国画图像的底层特征与高层语义之间对立可靠的联系,就得设计鲁棒的机器学习方法。
总之,要对国画图像实现自动分类与管理,已经成为中国画数字博物馆与数字图书馆领域一个极具挑战性且亟待解决的关键问题,具有重要应用价值。
技术实现要素:
本发明提供一种基于多视融合多示例学习的国画图像分类方法,更能表达图像所包含的各种高层语义及相互关系,能让不同的特征在国画图像分类中发挥相同的作用,降低用户使用本技术方案的难度。
本发明提供了一种基于多视融合多示例学习的国画图像分类方法,包括以下步骤:
s1、分类器训练
s11、输入训练图像集t={(imgi,yi):i=1,2,...,n},其中imgi表示第i幅图像,yi∈{1,2,...,c}表示第i个图像标记,c表示图像类别数,n表示训练图像的数量;
s12、对训练图像集t中的每一幅图像imgi,进行分块,并提取每个分块的三种不同性质的局部视觉特征,将图像集构造成三个不同的多示例包,即颜色包bci、纹理包bti与形状包bsi,得到三种多示例学习mil训练数据集tc、tt与ts;
s13、多视特征提取
分别基于三种多示例学习mil训练数据集tc、tt与ts,计算每个多示例包的单视特征,单视特征即颜色特征
s14、softmax分类器训练
基于所有训练图像的多视特征bi与标记yi,组织成训练数据集
由训练数据集
得到最终的多视融合多示例学习分类器θ;
s2、分类阶段
设img表示任意一幅待分类的国画图像,首先获得它的多视特征,然后,用多视融合多示例学习分类器θ来预测任意一幅待分类的国画图像属于每个图像类别的后验概率,对它进行分类识别。
上述步骤s12中构造三个不同的多示例包的具体方法为:
s121、采用金字塔有重叠网格分块的方法对图像进行自动分块;
输入图像img、分块的高度h、宽度w、步长stp和图像缩小比率α;
根据分块的高度h、宽度w和步长stp对输入图像img进行分块;
将分块后的图像img按比率α进行缩小,当图像img缩小到设定像素时,停止分块;
s122、提取每个分块的颜色、纹理和形状三种不同性质的底层视觉特征,构造成三个不同的多示例包。
上述步骤s122中的颜色、纹理和形状三种不同性质的底层视觉特征提取的具体方法为:
s1221、hsv非均匀量化颜色直方图特征提取;
采用更符合人眼色彩视觉特征的hsv颜色模型,首先将图像的r,g,b值转换为h,s,v值,h∈[0,360],v∈[0,1],s∈[0,1],根据hsv模型的特性作如下的非均匀量化:
(1)黑色:对于亮度v<0.1的颜色认为是黑色;
(2)白色:对于饱和度s<0.1且亮度v>0.9的颜色认为是白色;
(3)彩色:把位于黑色与白色区域之外的颜色,依色度hue的不同,以20,40,75,155,190,270,295,316为分界点,划分为8个区间,再结合饱合度s以0.6为分界点,每个区间分成2种颜色,则形成16种不同的彩色信息;
s1222、gabor纹理特征提取;
根据尺度和方向建立gabor滤波器组,gabor滤波器组包括多个gabor滤波器;
gabor滤波器组与每个分块图像在空域卷积,每个分块图像得到多个gabor滤波器输出;
利用每个分块图像输出系数的均值与方差,得到多维的特征向量作为该分块图像块的纹理特征;
s1223、sift描述子形状特征提取;
对于每个图像分块,为了使sift描述子对图像旋转具有不变性,计算每个图像分块每个像素的梯度模值与方向角;
使用每个图像分块所有像素的梯度模值及方向角,统计每个图像分块所有像素的梯度方向直方图;梯度方向直方图的峰值则代表了每个图像分块梯度的主方向;将坐标轴旋转为该图像分块的主方向,再使用多个种子点,且在每个种子多个邻域计算多个方向的梯度方向直方图,则对于任一个分块,产生多个数据,即多维的sift描述子,用于表示图像块的局部结构形状特征。
上述步骤s13中多视特征提取的具体步骤为:
第一步:基于自适应非线性投影的单视特征提取
设由颜色特征组成的多示例训练包为:
tc={(bci,yi):i=1,2,...,n}(1)
式(1)中,bci={cxij|j=1,...,ni}表示第i幅图像imgi对应的颜色多示例包,ni表示第i幅图像imgi被划分的块数,n表示图像总数;则采用如下所述自适应非线性投影方法提取tc中每个多示例包的单视特征;
构造视觉投影空间;
将tc中所有多示例包的所有示例排在一起,称为示例集,记作
intset={xt|t=1,2,...,p.}(2)
其中
自适应非线性投影单视特征提取;
为了获得每幅国画图像颜色多示例包所对应的单视特征,设计一个自适应非线性投影函数,用于提取多示例包的单视特征,由此将多示例包转化成单个代表向量,然后用监督学习方法求解多示例学习mil问题,具体技术方案如下:
设ω={w1,w2,...,wk}表示从多示例训练包tc构建的视觉投影空间,其中wk表示第k个视觉单词,k表示视觉单词的总数,首先,定义wk与多示例包bci={cxi,j|j=1,2,...,ni}之间的最大与最小欧氏距离为:
然后,多示例包bci的单视特征计算方法定义为:
其中,s(wk,bci)由二个值组成,即exp(-dmin(wk,bci)/δ)与exp(-dmax(wk,bci)/δ),它们反映的是当前多示例包bci包含有视觉单词wk的似然概率,因为在图像分类问题中,最大似然与最小似然具有相同的重要性,所以在单视特征提取过程中同时使用二者,以提高图像分类的精度,值得注意的是:在式(4)中,δ是一个必须预先设定的尺度因子,它的功能就是用于调节s(wk,bci)在取值区间[0,1]内分布的合理性,以提高国画图像分类精度;
为了增加算法的自适应能力,本发明设计了如下自适应计算方案,即“尺度因子自适应方案”,具体技术方案步骤如下:
将tc中所有多示例包的所有示例排在一起,称为示例集,记作
intset={xct|t=1,2,...,p.}(5)
其中
对于intset中每一个示例xct,在视觉投影空间ω={w1,w2,...,wk}中计算与示例xct最近邻视觉单词之间的欧氏距离,记为dist(xct),则尺度因子δ为:
第二步:多视特征计算即单视特征融合
训练图像集除了生成式(1)所示的“颜色包”之外,还有纹理示例包与形状示例包,记为:
同理,采用上述相同方法,也可求得任意纹理包bti与形状包bsi的单视特征,记为:
然后,将
总之,通过上述多视特征提取方法,将图像的3种多示例包转化成一个特征向量,从而得到图像imgi的最终特征表示bi,若颜色、纹理与形状训练集tc、tt、ts所对应的视觉单词个数均为k时,则融合之后的多视特征
上述步骤s14中softmax分类器训练方法具体为:
设t={(imgi,yi):i=1,2,...,n}为训练图像集,其中imgi表示第i幅图像,yi∈{1,2,...,c}表示其标号,c表示图像类别数,n表示训练图像的数量,通过多包建模及多视特征提取,则转化成训练数据集
其中θ=[θ1,θ2,…,θc]t∈rc×d表示模型参数,d表示特征维度,p(c|b;θ)表示多视特征b属于第c类的后验概率c=1,2,...,c,
与现有技术相比,本发明的有益效果在于:
(1)mil与传统的有监督单示例学习框架不同,它的训练样本称为包(bag),每个包中含有数量不等的示例(instance),所以,包中的多个示例比起单个示例来说,更能表达图像所包含的各种高层语义及相互关系,特别适合处理训练样本标注信息不完整、图像语义模糊与训练样本存在歧义等情况的模糊学习问题。
(2)本发明设计的底层特征分开的多包多示例建模技术方案,不同特征将被分开处理,可以避免不同性质的特征在数值上存在较大差异而导致特征淹没,能让不同的特征在国画图像分类中发挥相同的作用。应用实验也证明了本发明设计的多包多示例建模方案在mil中是有效的,性能优于传统的单包多示例建模方案。
(3)设计自适应多视特征提取技术方案,不但可以利于图像的不同视觉属性从不同的角度对国画图像进行鉴别区分及语义表征,而且还让整个算法具有较强的自适应能力,降低用户使用本技术方案的难度。应用实验证明:将3种单视特征串联融合起来,得到最终的多视特征用于对国画图像进行表征,较之基于单视特征的国画图像分类,性能也更好。
附图说明
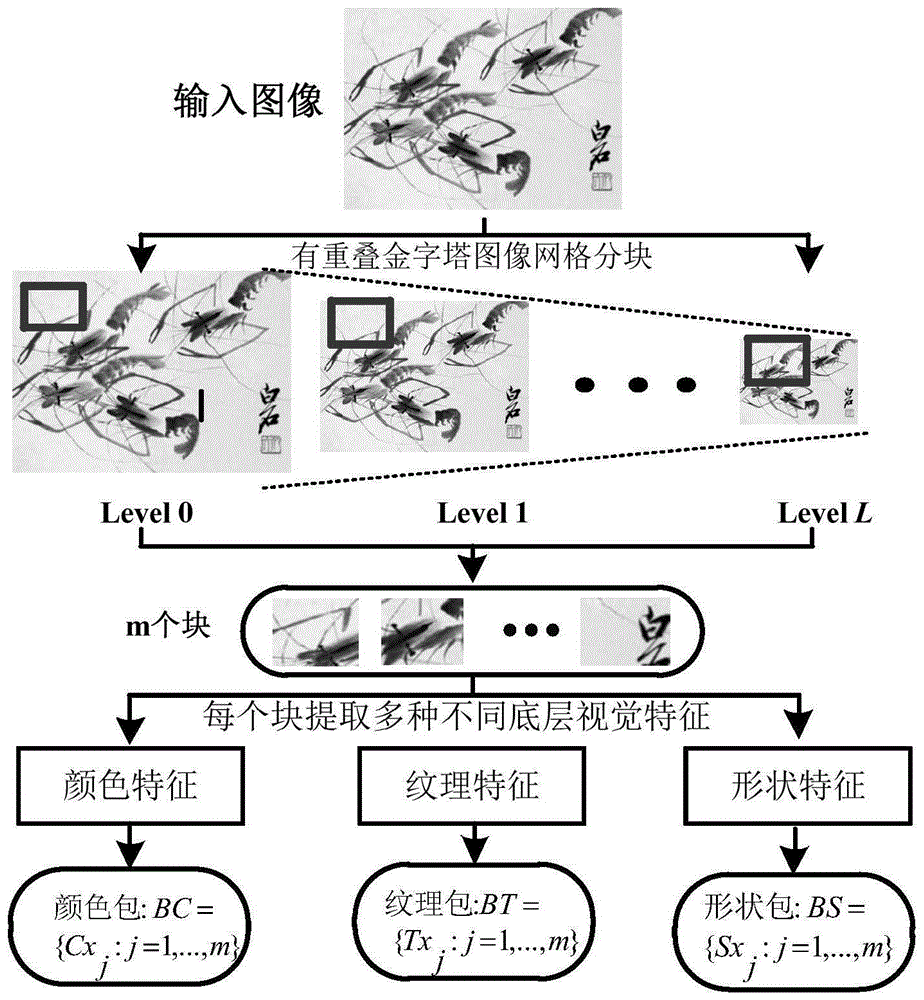
图1为本发明提供的一种基于多视融合多示例学习的国画图像分类方法中金字塔分块多包多示例建模流程示意图。
图2为本发明提供的一种基于多视融合多示例学习的国画图像分类方法中多视特提取流程示意图。
具体实施方式
下面结合附图1-2,对本发明的一个具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
本发明提供的一种基于多视融合多示例学习的国画图像分类方法,包括以下步骤:
1)训练阶段
输入:训练图像集t={(imgi,yi):i=1,2,...,n},k-means聚类数量k;
输出:基于softmax多示例分类器θ;
step1:金字塔分块多包多示例建模:
对t中任意图像imgi,用图1所示方法,将其转化成三种不同的多示例包,即颜色包bci、纹理包bti与形状包bsi,则得到三种mil训练集,记为式(2.1)形式;
step2:多视特征提取
首先,采用单视特征提取所述技术方案,分别基于三种mil训练数据tc、tt与ts,计算每个多示例包的单视特征
step3:softmax分类器训练
首先,基于所有训练图像的多视特征bi与标签yi,组织成训练数据集
2)分类阶段
设img表示任意一幅待分类的国画图像.首先,采用上述相同方法计算它的多视特征,然后,用分类器θ来预测它属于每类的后验概率,以实现对它进行分类识别。
1、输入模块:训练图像集t={(imgi,yi):i=1,2,...,n},聚类个数k;
2、金字塔分块多包多示例建模模块
对训练图像集t中的每一幅图像imgi,采用金字塔方式进行分块,并提取每个分块3种不同性质的局部视觉特征,将图像构造成3个不同的多示例包;
3、自适应多视特征提取模块
首先,采用聚类方法构造视觉投影空间,然后,新设计了一个自适应“投影特征”计算方法,用提取多示例包的多视特征,用来作为多示例包的表征向量。
4、基于softmax多示例学习模块
基于softmax算法,设计了一种多视融合多示例学习算法,用于训练国画图像分类器θ;
5、输出模块:分类器θ。
一、金字塔多包多示例建模模块具体方法
为了能将国画图像不同性质的底层视觉特征分开对待,本发明设计了一种多包多示例建模方案。首先,采用“金字塔有重叠网格分块”的方法对图像进行自动分块;然后,再提取每个分块的颜色、纹理、形状等不同性质的底层视觉特征,分别建立成3个多示例包,从而将国画图像分类问题转化成mil问题。具体是:
算法:金字塔分块多包多示例建模技术方案
输入:图像img,分块的高度h与宽度w,步长stp,图像缩小比率α;
输出:多个多示例包
step1:当图像i的高度大于50,且宽度大于50
forr=1:stp:图像i的高度-h
forc=1:stp:图像i的高度-w
①局部块r=img(r:r+h,c:c+w);
②提取r的3种底层视觉特征,作为示例添加到相应的多示例包中;
endr
endc
step2:将图像i按比率α进行缩小,返回step1;
step3:建模结束,输出图像i对应的3个由不同视觉特征构成的多示例包。
如图1所示,是多包多示例建模示意图,应用实验中,块大小h与w均设置为16像素,块从左往右、从上往下移动步长stp设置为6像素,图像缩小比率α设置为0.5,当图像缩小到50像素或以下时,则分块停止。
设img为任意一幅国画图像,其被划分成为m个子块{rj:j=1,2,...,m},则将img图像分别由颜色、纹理与形状等三种不同的底层视觉特征组织成3个多示例包,记为:
其中cxj表示rj的hsv颜色直方图特征;txj表示rj的gabor纹理特征;sxj表示rj的128维sift描述子特征。该基于金字塔分块的多包多示例建模技术方案,较之传统基于“图像分割”的单包多示例建模方案,优点有:
(1)简单高效,且普适性与鲁棒性更强,能够从不同的分辨率获取图像的局部信息;
(2)底层特征分开的多包mil建模,不同特征将被分开处理,一则可避免特征在数值上的较大差异而导致特征淹没,二则可利于后续的多视结构化特征提取与融合。
在上述多包多示例建模过程中,将图像划分不同的小块之后,要提取每个小块3种不同的底层视觉特征,这3种特征的具体提取方法分别是:
1、hsv非均匀量化颜色直方图特征提取方法
rgb颜色空间与人眼的感知差别很大,本发明采用更符合人眼色彩视觉特征的hsv颜色模型,首先将图像的r,g,b值转换为h,s,v值(h∈[0,360],v∈[0,1],s∈[0,1]),根据hsv模型的特性作如下改进的非均匀量化:
(1)黑色:对于亮度v<0.1的颜色认为是黑色;
(2)白色:对于饱和度s<0.1且亮度v>0.9的颜色认为是白色;
(3)彩色:把位于黑色与白色区域之外的颜色依色度(hue)的不同,以20,40,75,155,190,270,295,316为分界点,划分为8个区间,再结合饱合度s以0.6为分界点,分成2种,则形成16种不同的彩色信息。.
通过上述方法将hsv颜色空间量化成18种代表色,有效地压缩了颜色特征,且能更好地符合人眼对颜色的感知特性。然后,统计每个分块区域这18种颜色出现的频率,从而得到18维的hsv颜色直方图,用于描述图像区域的颜色特征,即对图像第j个分块rj可得到它的18维hsv颜色直方图特征,记为:记为:
cxj={ci:i=1,2,..,18}(12)
2、gabor纹理特征提取方法:
gabor纹理提取方法的主要思想是:不同纹理一般具有不同的中心频率及带宽,根据这些频率和带宽可以设计一组gabor滤波器对纹理图像进行滤波,每个gabor滤波器只允许与其频率相对应的纹理顺利通过,而使其他纹理的能量受到抑制,从各滤波器的输出结果中分析和提取纹理特征,用于之后的分类或分割任务。gabor滤波器提取纹理特征主要包括两个过程:①设计滤波器(例如函数、数目、方向和间隔);②从滤波器的输出结果中提取有效纹理特征集。gabor滤波器是带通滤波器,它的单位冲激响应函数(gabor函数)是高斯函数与复指数函的乘积。它是达到时频测不准关系下界的函数,具有最好地兼顾信号在时频域的分辨能力。
利用gabor滤波器组,实现纹理特征提取的步骤如下:
(1)建立gabor滤波器组:选择4个尺度,6个方向,这样组成了24个gabor滤波器;
(2)gabor滤波器组与每个图像块在空域卷积,每个图像块可以得到24个滤波器输出;
(3)每个图像块经过gabor滤波器组的24个输出,利用这些输出系数的“均值”与“方差”,共48维的特征向量作为该图像块的纹理特征。
通过上述方法,对图像第j个分块rj可得到它的48维gabor纹理特征,记为:
txj={(ut,σt)|t=1,2,...,24}(13)
其中,ut,σt分别表示第t个滤波器输出系数的均值与方差。
3、sift描述子形状特征提取方法
对于每个16×16的图像小块r(x,y),为了使sift描述子对图像旋转具有不变性。可以计算每个像素的梯度模值与方向角,如下:
然后,使用该小块所有像素的梯度及方向分布的特性,统计小块r(x,y)所有像素的梯度方向角直方图。梯度直方图的范围是0~360度,其中每10度一个方向,总共36个方向。直方图的峰值则代表了该小块r(x,y)梯度的主方向;最后,为了给每个小块r(x,y)建立一个描述符,且使其不随光照、视角变化而变化。将坐标轴旋转为该小块r(x,y)的主方向,再使用4×4共16个种子点,且在每个种子4×4的邻域计算8个方向的梯度方向直方图,则对于第j个分块rj,可以产生128个数据,即128维的sift描述子,用于表示图像块rj的局部结构形状特征。记为:
sxj={ht|t=1,2,...,128}(15)。
二、自适应多视特征提取模块具体方法
设t={(imgi,yi):i=1,2,...,n}表示国画图像分类训练图像集,其中n表示训练图像的数量,yi∈{1,2,...,c}表示第i幅图像imgi的类别标号,c表示图像类别数。由上述“多包多示例建模模块”所述技术方案,每幅训练图像将生成3个不同性质的“多示例包”,则可以获得3种不同的训练数据集,记为:
其中bci、bti与bsi分别表示第i幅图像imgi对应的颜色、纹理与形状特征对应的“多示例包”,ni表示其被划分的块数。
不防将不同性质底层特征组成的“多示例包”当作观察国画图像的一个视角(view),本发明设计了一种多视特征提取方法,以从多个视角描述国画图像的性质而提高分类精度。
本发明提出的多视特征提取技术方案,其主要包括如下2个步骤,即:
第一步:基于自适应非线性投影的单视特征提取
这里不妨设由颜色特征组成的多示例训练包为:
tc={(bci,yi):i=1,2,...,n}(1)
其中bci={cxij|j=1,...,ni}表示第i幅图像imgi对应的颜色多示例包,ni表示其被划分的块数,
构造视觉投影空间
将tc中所有多示例包的所有示例排在一起,称为示例集,记作
intset={xt|t=1,2,...,p.}(2)
其中
自应用非线性投影单视特征提取
为了获得每幅国画图像颜色“多示例包”所对应的单视特征,本发明设计一个自适应非线性投影函数,用于提取多示例的单视特征,由此将多示例包转化成单个“代表向量”,然后用后续有监督学习方法求解mil问题。具体技术方案如下:
设ω={w1,w2,...,wk}表示从多示例训练包tc构建的“视觉投影空间”,其中wk表示第k个视觉单词”,k表示视觉单词”的总数。首先,定义wi与多示例包bci={cxi,j|j=1,2,...,ni}之间的最大与最小欧氏距离为:
然后,多示例包bci的单视特征计算方法定义为(本发明要保护的技术点1):
其中,s(wt,bci)由二个值组成,即exp(-dmin(wt,bci)/δ)与exp(-dmax(wt,bci)/δ),它们反映的是当前多示例包bci包含有视觉单词”wk的似然概率,因为在图像分类问题中,最大似然与最小似然具有相同的重要性,所以在本发明的单视特征提取过程中同时使用二者,以提高图像分类的精度。值得注意的是:在式(2.5)中,δ是一个必须预先设定的尺度因子,它的功能就是用于调节s(wt,bci)在取值区间[0,1]分布的合理性,以提高国画图像分类精度。
但是,如果该尺度因子δ设置不合理,则会影响算法的分类精度;同时,要让非专业的普通用户去设置一个合理的δ,也非常困难。所以,本发明为了增加算法的自适应能力,设计了如下自适应计算方案,即“尺度因子自适应方案”,具体技术方案步骤如下:
将tc中所有多示例包的所有示例排在一起,称为示例集,记作
intset={xct|t=1,2,...,p.}(5)
其中
对于intset中每一个示例xct,在ω={w1,w2,...,wk}中计算与它最近邻视觉单词”之间的欧氏距离,记为dist(xct),则尺度因子δ为:
通过上述方法,本发明的算法能自动根据示例分布的疏密程度,自动调节尺度因子δ,使多示例包对应的单视特征分布更加合理,从而增加算法的自适应能力,应用实验中验证了使用该方案自适应尺度因子δ,一则可降低用户使用整个算法的难度,二则该方案也极大地增强了整个算法的自适应能力与鲁棒性。
第二步:多视特征(即单视特征融合)
由图1所示多包多示例建模技术方案,训练图像集除了可以生成式(3)所示的“颜色包”之外,还有“纹理”与“形状”等多示例包,记为:
同理,采用上述相同方法,也可求得任意纹理包bti与形状包bsi的单视特征,记为:
然后,将
总之,通过上述多视特征提取方法,可以将图像的3个多示例包被转化成一个特征向量,从而得到图像imgi的最终特征表示bi。若颜色、纹理与形状训练集tc、tt、ts所对应的”视觉单词”个数均为k时,则融合之后的多视特征
①将多个多示例包转化成单个的特征向量,由此将多包mil转化成有监督学习问题,从而能用标准的有监督学习方法对多包mil问题进行求解;
视特征在构造过程中利用了多个包中所有视觉特征及其相互关系,相当于“视觉语义融合特征”,能更加有效地表征国画图像所蕴含的语义信息,在图像分类问题中更具语义区分能力。
上述多视特征提取流程如图2所示。
三、基于softmax的多示例学习模块
设t={(imgi,yi):i=1,2,...,n}为训练图像集,其中imgi表示第i幅图像,yi∈{1,2,...,c}表示其标号,c表示图像类别数,n表示训练图像的数量。通过图1所示多包建模及图2所示多视特征提取,则转化成训练数据集
其中θ=[θ1,θ2,…,θc]t∈rc×d表示模型参数,d表示特征维度,p(c|b;θ)表示多视特征b属于第c(c=1,2,...,c)类的后验概率,
本发明在深入分析和研究传统中国画在数字化后所形成的数字图像的基础上,包括艺术风格、绘画技巧,用笔手法以及数字表示等领域,对国画图像特征提取技术进行了深入研究。其重点是设计多尺度多视角特征提取技术,用于对国画的图像的内在语义进行表示,然后,设计一种决策融合的国画图像分类算法,用于在国画图像底层视觉特征与高层语义之间建立联系。涉及的主要技术如下:①多尺度国画图像局部特征提取方法;②多角度多视特征提取方法;③基于softmax的决策融合机器学习方法。
(1)mil与传统的有监督单示例学习框架不同,它的训练样本称为包(bag),每个包中含有数量不等的示例(instance),所以,包中的多个示例比起单个示例来说,更能表达图像所包含的各种高层语义及相互关系,特别适合处理训练样本标注信息不完整、图像语义模糊与训练样本存在歧义等情况的模糊学习问题。
(2)本发明设计的底层特征分开的多包多示例建模技术方案,不同特征将被分开处理,可以避免不同性质的特征在数值上存在较大差异而导致特征淹没,能让不同的特征在国画图像分类中发挥相同的作用。应用实验也证明了本发明设计的多包多示例建模方案在mil中是有效的,性能优于传统的单包多示例建模方案。
(3)设计自适应多视特征提取技术方案,不但可以利于图像的不同视觉属性从不同的角度对国画图像进行鉴别区分及语义表征,而且还让整个算法具有较强的自适应能力,降低用户使用本技术方案的难度。应用实验证明:将3种单视特征串联融合起来,得到最终的多视特征用于对国画图像进行表征,较之基于单视特征的国画图像分类,性能也更好。
以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!