一种基于尺度融合的腹部CT多器官的分割方法与流程
技术领域:
本发明属于医学图像处理和其应用,涉及一种基于尺度融合的腹部ct多器官的分割方法。
背景技术:
:
随着现今社会的发展,越来越多的跨领域学科正在相结合以便更有效的解决面临的问题。其中利用深度学习方法的医学影像技术在医学诊断中有着不可或缺的作用,它能够利用已有的图像进行医学影像分析,帮助医生更好理解病情以进一步的进行诊断和给出治疗方案。而医学分割作为医学影像处理的第一阶段,对后续的影像分析都有重要意义!对腹部器官的分割能够精确定位到各个脏器,从而对手术的引导和医学影像的配准有着重要意义。
人体内部器官分布复杂,没有清晰的边界来区分各个器官。但是利用电子计算机断层扫描(computedtomography),它通过单一轴面的x射线旋转照射人体,由于不同的组织对x射线的吸收能力不同,于是就有不同组织的灰度图,这就得到了高分辨率的解剖图像。但是由于超声图像的一些局限,有时可能会产生阴影、斑点噪声和重叠的影响,再加上同一器官在不同切面的差异比较大、腹部ct图像的器官边界模糊,这也对一个临床经验不足的医生产生分割的困难。
目前传统的分割方法是影像科医生人工读片,手工标记器官和病灶的位置,这样的分割不仅受到医生主观的经验和情绪影响,而且耗时耗力。于是本发明提出了一种基于尺度融合的腹部ct图像多器官的分割方法,利用改进的u-net神经网络模型和注意力机制相融合对腹部器官进行分割。实现了无医生参与的器官分割,避免了由医生主观经验产生的分割错误,同时减少了专业人士的投入,从而实现了真正意义上的智能诊断。
技术实现要素:
:
本发明的目的在于提供一种基于尺度融合的腹部ct图像多器官分割方法,以此克服现有的传统分割方法的时效性和通用型差以及解决受医生主观意向对分割所产生的影响。
本发明的技术方案如下:
一种基于尺度融合的腹部ct多器官的分割方法,步骤如下:
第一步:将已有数据集进行数据预处理,然后分为训练集、验证集和测试集进行训练和评估模型性能。在医生标好的图像对应的标签,给标签像素标记为0-6来代表ct图像背景、肝脏、脾脏、肾脏、肝、胃和胰腺。
第二步:在原有的u-net上加入了深度监督来避免由于器官大小在不同切片的多变造成的影响,同时引入了空间(spatialattention)和通道注意力(channelattention)机制让网络模型在通道和空间上都有关注的重点,从而更加准确的分割器官。
第三步:将已经预处理好的数据输入到第二步中搭建的模型中训练,此过程加入了batchnormalization算法来增加网络的对称性同时加快网络收敛速度。在这个改进的u-net用训练集进行训练,得到分割模型。
第四步:选择第三步中训练的最好模型用于验证集的ct图像分割进行模型验证。
第五步:利用训练好的分割模型对测试集分割。
所述第一步中的预处理如下:
1.1本发明使用的原始图像集包含若干组nii格式的腹部ct影像文件。这些图像为三维图像,而且不同病人间的切片厚度不一样,所以先将轴向面(axialplane)统一为3mm使得网络更好训练。
1.2由于所采集的ct图像都是512*512*z大小的图像,直接输进网络的话显卡没有足够的显存对其进行计算,因此我们对原图像进行cubicinterpolation使得冠状面和矢状面大小减少一半变成256*256*z来减少显存的消耗同时加快训练速度。
1.3然后进行有效区域的截取。在原始图像中存在了很大一块区域的无效区域。为了简化后面的训练模型,加快训练速度,对与标签值为0的区域截除后在进行模型的训练。
1.4处理完上述步骤后就对处理后的ct图像进行数据增强。这是由于原始图像集中的图像数量有限,故而采取数据增强的方式增加数据的丰富性,从而提高训练模型的精确度。
数据增强主要包括旋转、镜像、弹性扭曲、膨胀。这种方法可以使图像集中包括同一张图像在不同角度、不同尺度的各种数据,增加了图像集中图像的个数。通过扩充图像集,可以防止图像样本过少导致的过拟合问题。
1.5对数据进行归一化处理。由于我们得到的ct图像的hu值的分布范围跨度大,不利于模型的训练。在分析数据的hu值分布后,我们首先对数据进行阈值截取,将灰度值在阈值外的截断掉,本发明采取的阈值为[-300,300],即hu>300的话我们设为300;反之,若hu<-300,那阈值设为-300。然后对阈值截取后的数据z-score标准化进行规范化处理。
所述第二步的模型搭建具体步骤如下:
2.1为了精确高效地分割腹部ct图像,必须合理的利用人工智能算法对大量数据进行训练,和fcn相比,由于医学数据的缺乏,u-net网络适合用于医学图像的分割。为了更好的实现三维分割,本发明的网络模型选择基于u-net网络和卷积神经网络cnn来进行搭建。
2.2在进行了一系列的实验后发现加入了通道注意力和空间注意力相结合取得了最好的模型。主要包含了se_block、sp_block两个注意力模块,同时还有conv_block、up_conv进行特征提取和上采样。其中conv_block是网络模型的特征提取模块,它包含了3个卷积层(3个都为三维卷积,卷积核大小都为3,填充(padding)为1),然后接着归一化层和采用2×2的卷积层,步长为2的池化层,每个卷积层后都带有prelu激活函数。up_conv是对已经经过下采样的图像上采样回上一步大小来恢复分辨率,它包括了一个三维转置矩阵(convtranspose3d)和prelu激活函数。
2.3其中se_block模块是用于通道注意力,就是在原有的u-net基础上对已有卷积通道数上加入注意力,它通过给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高,也就是我们越需要去注意的通道了。结构如图1所示,它包括了卷积层、全局平均池化层(globalaveragepooling)、relu激活函数以及sigmoid激活函数。而sp_block模块是用于空间注意力的,它使网络模型的关注点聚焦在权重大的区域而避免不必要的干扰。如图2所示,它通过在decoder部分使用attentiongate得到一个权重图后与原图相乘得到重点关注的区域。它包括了卷积,归一化层),relu激活函数以及sigmoid激活函数。
2.4同时考虑到ct图像在不同帧间的大小变化,我们还加入了深度监督(deepsupervision),在进行了一次下采样得到的结果再上采样回原来大小计算loss,然后再把每次的loss分配相应权重加起来。这样有一点程度的避免了由于再ct图像帧间的大小差异变化。
所述第三步的模型训练过程如下:
3.1本发明用的是主流的训练方法,先将数据输入构建的网络中。
3.2通过前向传播对网络进行训练,最后通过softmax分类器,输出预测的概率图。
3.3得到了代价函数值后采用cross-entropy作为损失函数,该损失函数对应于多分类问题,与softmax相对应,cross-entropy公式如下:
其中p为预测,t为目标,i表示数据点,j表示类别。
3.4基于步骤3.3中得到的计算误差,利用adam算法进行反向传播,更新网络中参数的值。一直重复上述过程直到损失函数值收敛到一个范围。
3.5完成上述步骤后得到多器官分割模型
所述第四步的模型验证流程如下:
为对第三步中得到的分割模型进行效果测试,定量评估模型的性能,我们采用了发明选用相似性系数(dicesimilaritycoefficient),dsc作为评估标准。
所述第五步对测试集分割如下:
采用已经得到的网路模型对将测试集进行分割,得到最后的分割结果。
与现有分割技术相比,本发明的优点在于:
1.针对传统手工或半自动方法工作量大、标注质量不高或差异较大等问题,本发明可以实现对于腹部区域ct图像的自动分割,且与现有的主流方法对比能取得较高的精度。
2.本发明提出的网络模型,采用了通道注意力(se_block模块)和空间注意力(sp_block模块)相结合进行特征的融合,对原始ct图像有了通道间关键信息的联系和空间位置上的关注点的重点学习,使得网络分割的更加精确。同时加入了深度监督(deepsupervision)来加强网络对器官在ct图像不同帧间的大小变化的理解能力,从而减少了失误的分割。卷积块上也加入了三维空洞卷积(3ddilatedconvolution),这可以在不改变参数个数的情况下,扩大了卷积层的感受野,获取了多尺度信息,能够更好的捕捉ct图像的浅层特征,从而提高了分割精度。
3.本发明能够很好的将腹部ct图像区域的器官分割出来,与现有大多是针对单器官分割的方法来说更加有效率,同时网络模型也有一定的泛化能力分割其他组织器官。
附图说明
图1是本发明的具体流程图;
图2是sp_block模块的具体结构图;
图3是se_block模块的具体结构图;
图4是整体的网络结构图。
具体实施方法:
本发明实现的是一种基于深度学习方法的特征融合进行的腹部ct图像多器官分割,主要包括数据预处理、搭建模型、训练模型、模型验证四个部分。
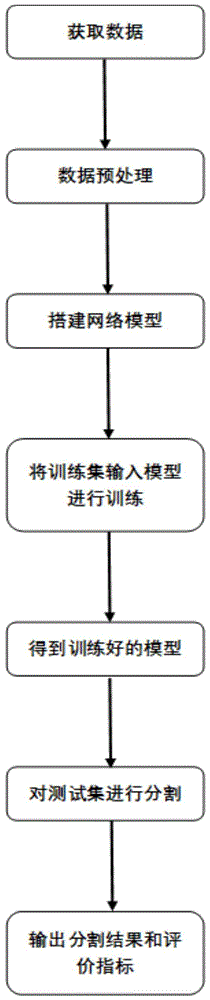
为更好理解实验的进行,下面结合附图及实施例对本发明做进一步的详细说明。图1是本发明的工作流程框架示意图。主要包括
步骤1数据集进行数据预处理
1.1首先对收集到的ct图像分为训练集、验证集和测试集。
1.2然后对它们进行预处理后再送进网络,先对ct图像的轴向面(axialplane)统一为3mm,是的网络更好学习。
1.3由于所采集的ct图像都是512*512*z大小的图像,直接输进网络的话显卡没有足够的显存对其进行计算,因此我们对原图像进行cubicinterpolation使得冠状面和矢状面大小减少一半变成256*256*z来减少显存的消耗同时加快训练速度。
1.4然后进行有效区域的截取。由于ct原始图像存在了很多混杂的背景信息,为了简化后面的训练模型,加快训练速度,根据训练集的标签值对标签值为0的区域截除后保存为处理后的图像进行模型的训练。
1.5处理完上述步骤后就对处理后的ct图像进行数据增强。数据增强主要包括旋转、镜像、弹性扭曲、膨胀。这种方法可以使图像集中包括同一张图像在不同角度、不同尺度的各种数据,增加了图像集中图像的个数。通过扩充图像集,可以防止图像样本过少导致的过拟合问题。
1.6对数据进行归一化处理。在分析数据的hu值分布后,我们首先对数据进行阈值截取,将灰度值在阈值外的截断掉,本发明采取的阈值为[-300,300],即hu>300的话我们设为300;反之,若hu<-300,那阈值设为-300。然后对阈值截取后的数据z-score标准化进行规范化处理。z-score标准化公式如下:
其中x*为经过归一化的值,x表示个体的观测值,μ表示总体数据的均值,δ表示总体数据的标准差。
所述步骤(2)中模型的搭建如下:
2.1以u-net为原始网络框架,本发明加入了深度监督(deepsupervision)和se_block、sp_block进行特征融合来加强网络的学习能力。其中conv_block、up_conv进行特征提取和上采样。其中conv_block是网络模型的特征提取模块,每个包含conv_block模块包含了3个卷积层(3个都为三维卷积,卷积核大小都为3,填充(padding)为1),然后接着归一化层,为了获取更多的图像信息,采用2×2的卷积层,步长为2的池化层代替最大池化层,每个卷积层后都带有prelu激活函数。up_conv是对已经经过下采样的图像上采样回上一步大小来恢复分辨率,它包括了一个三维转置矩阵(convtranspose3d)和prelu激活函数。
2.2其中se_block模块是用于通道注意力,就是在原有的u-net基础上对已有卷积通道数上加入注意力,它通过给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高,也就是我们越需要去注意的通道了。结构如图1所示,它包括了卷积层、全局平均池化层(globalaveragepooling)、relu激活函数以及sigmoid激活函数。而sp_block模块是用于空间注意力的,它使网络模型的关注点聚焦在权重大的区域而避免不必要的干扰。如图2所示,它通过在decoder部分使用attentiongate得到一个权重图后与原图相乘得到重点关注的区域。它包括了卷积,归一化层),relu激活函数以及sigmoid激活函数。
2.3考虑到了ct图像在不同帧之间器官的差异,本发明加入了深度监督来增强网络对器官不同帧之间尺度变化的泛化能力。
所述步骤(3)的模型训练过程如下:
3.1将训练集输入到搭建好的网络中。
3.2通过前向传播对网络进行训练,最后通过softmax分类器,输出预测的概率图。
3.3得到了代价函数值后采用cross-entropy作为损失函数,该损失函数对应于多分类问题,与softmax相对应,cross-entropy公式如下:
其中p为预测,t为目标,i表示数据点,j表示类别。
3.4基于步骤3中得到的计算误差,利用adam算法进行反向传播,更新网络中参数的值。一直重复上述过程直到损失函数值收敛到一个范围。
3.5完成上述步骤后得到多器官分割模型
所述步骤(4)的模型验证流程如下:
对训练模型的效果进行评估。在本发明中的评估尺度采用的是dicemetric指标,使用dice指标来评估所提出的分割算法准确率。
通用的dicemetric指标如下:
其中a为分割图,b为ground-truth真实分割,|a|和|b|分别为a和b分割图的体素(三维像素)数量,|a∩b|为两图重合部分的体素数量。
所述步骤(5)对测试集分割如下:
采用已经得到的网路模型对将测试集进行分割,得到最后的分割结果。
- 还没有人留言评论。精彩留言会获得点赞!