一种基于高考大数据的院校录取成绩预测方法与流程
本发明涉及数据挖掘领域,更具体的,涉及基于高考大数据的院校录取成绩预测模型。
背景技术:
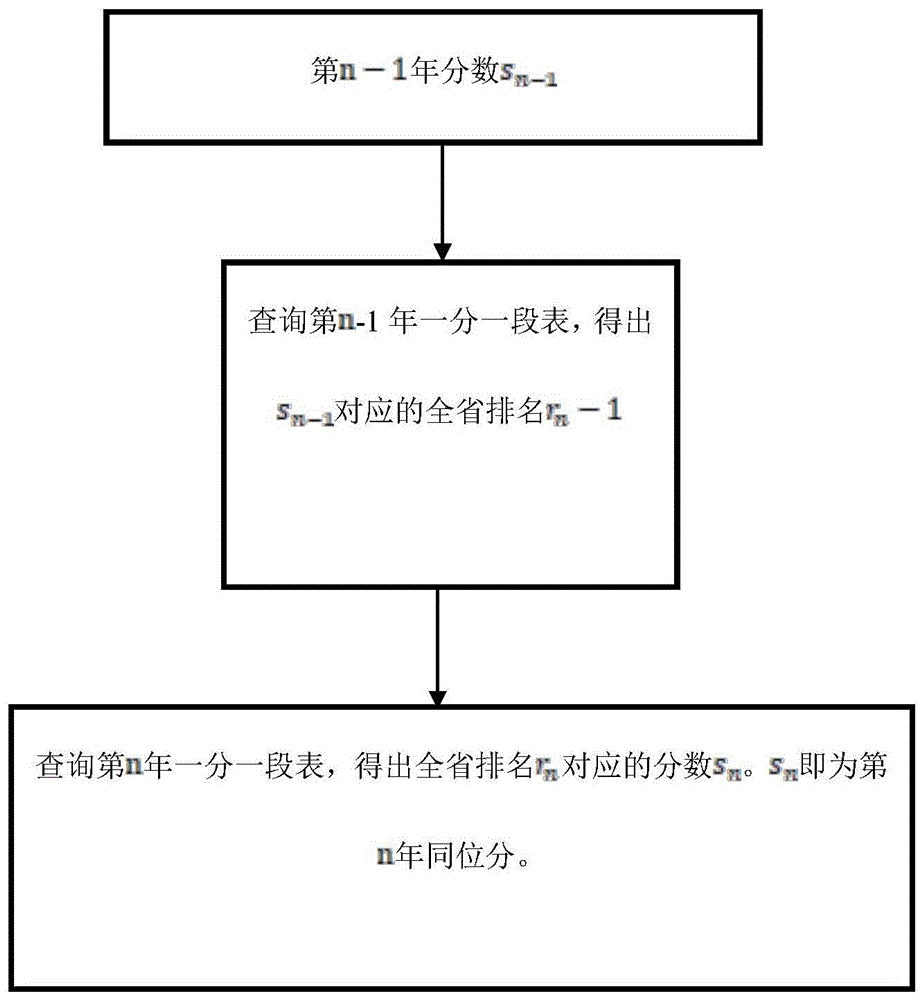
:高考是普通高等学校招生全国统一考试的简称,是中国学子想要实现大学梦唯一的公平途径,而志愿填报是其中极为关键的环节之一。如果志愿填报不合理,往往会出现分数高于院校录取线,导致分数浪费;或是分数低于院校录取线,导致落榜。较为传统的录取线预测方式有同位分法,线差法,线性回归法。同位分法是将往年的录取线通过一分一段表(每个分数对应的位次)转换为录取位次,再利用当年的一分一段表,将往年录取位次映射到当年的录取分数,得到预测值;线差法是求往年录取分与批次线的差值,再求该差值与当年批次线之和,得到录取线。两种方法均简单易行,通过手动计算便可得出。虽然部分预测结果较为准确,但是其将所有高校作为一个整体静态的模型,默认所有高校录取线相对稳定,忽略了每年因为各种原因发生浮动的现象,导致总体预测精度不高;线性回归法是确定年份与录取线的依赖关系,建立线性模型,而这种方法过于依赖大量的历史数据,且容易受到外部因素干扰,因此性能不佳。技术实现要素:本发明提供了一种基于高考大数据的院校录取成绩预测模型。通过使用各类统计机器学习模型进行组合,得出性能较好的预测模型,通过历史高考数据对模型进行训练,使模型能够精准地预测当年各高校的录取成绩。本发明提取了高考数据中影响录取成绩的重要特征:专业数、计划数以及录取级差。计划数是指当年各院校文理各科总招生人数;录取级差是指院校录取考生中最高分与最低分的差值。除此以外,基于高考志愿填报的特点,本发明还考虑到各高校之间会有竞争关系的存在,即某一高校的招生人数变化,影响到其他高校的录取情况。本发明提供的模型先使用同位分法进行预测,得到粗略预测值;再利用上述重要特征,使用集成学习模型(如非线性回归模型gbdt),拟合出录取成绩变化率,与粗略预测值结合,得到初步预测值;最后利用无监督聚类模型(如谱聚类)对高校进行划分,拟合高校间的竞争关系,调整初步预测值,得到最终预测结果。本发明提出的一种基于高考大数据的院校录取成绩预测方法,包含以下步骤:步骤1:回归模型训练;根据已有的数据,以作为输入,作为输出,对回归模型进行训练,得到训练好的回归模型;其中:jn表示第n年高校的招生人数,zn表示第n年z高校的专业数,gn-1表示第n-1年的录取最高分与录取最低分的差值;rn表示第n年高校的录取分位次;步骤2:生成稳定高校集合与非稳定高校集合;根据高校历年录取成绩,判断其波动幅度是否小于阈值,若是,则认为该高校是稳定的,将其加入集合s中;否则认为该高校是不稳定的,将其加入集合ns中;步骤3:对步骤2集合s中高校的录取分的初步预测;采用高校第n年的同位分作为第n+1年的录取分的初步预测值,转步骤5;其中同位分的计算方法为:设已知第n-1年的高校录取成绩sn-1,利用第n-1年的一分一段表得到sn-1在第n-1年对应的全省排名rn-1;再利用第n年的一分一段表,找到排名rn-1对应的分数sn;此时,称sn为高校在第n年的同位分;步骤4:对步骤2集合ns中高校录取分的初步预测;步骤4.1:采用高校第n年的录取位次作为粗略预测值;步骤4.2:提取高校的特征x,采用步骤1训练好的回归模型,计算输出值,根据粗略预测值,结合输出值计算得到的第n+1年的名次预测值,在第n+1年的一分一段表中找到该名次预测值对应的分数,作为第n+1年的录取分的初步预测值,转步骤5,所述一分一段表是学生成绩与省内排名的映射关系;步骤5:对于所有高校,根据高校间的竞争关系采用聚类模型将高校进行划分;高校在所属聚类簇内依照步骤3和步骤4得到的初步预测值进行排序,再按照聚类簇内的高校往年相同排序位次的录取分数对初步预测值进行修正,得到最终的录取成绩预测结果。进一步的,所述步骤5中采用聚类簇内的高校往年相同排序位次的录取分数与初步预测值的平均值作为最终预测结果。本发明和现有的高考录取成绩预测模型相比,创新点在于:1、预测目标的转换。回归模型用来预测录取成绩变化率,从而间接预测录取成绩,而不是直接对录取成绩进行预测。这样做的好处是能够更真实地还原录取成绩变化的过程——高校特征是在往年录取位次的基础上影响录取成绩的:高校特征的数值变化,会基于往年录取位次导致当年位次升高或降低,使用回归模型拟合这种“升高”或“降低”的幅度与高校特征的非线性关系,由此抓住了预测问题的本质;2、考虑到院校间的竞争关系,引入聚类模型,拟合竞争因素。一般的预测模型并不考虑高校之间的相互作用关系,而由于高考志愿填报本身的特点,考生有多个志愿指标进行填报,志愿中靠前的院校具有较高优先级,因此当高优先级院校招生人数扩招,会导致低优先级院校失去相对高分的学生,使得录取线下降。所以拟合高校间的竞争关系,是提高预测精度的重要手段;3、同位分法、回归模型和聚类模型的结合使用,逐步缩小预测误差。对于录取成绩稳定的院校,同位分法预测精度极高,而对于不稳定院校,同位分法只能得到一个误差较大的预测值,所以需要回归模型和聚类模型对同位分法预测值进行修正。回归模型用于修正院校本身特征的变化造成的误差;聚类模型用于修正具有竞争关系院校的影响造成的误差。两者结合使用,极大程度缩小了预测误差。附图说明图1为同位分法基本原理。图2为判断院校录取成绩是否稳定的流程图。图3为院校录取成绩预测模型流程图。具体实施方式为使本发明的目的更清晰,结合附图进行详细介绍:表1是本发明所用到的一分一段表的基本结构,其中记录了高考中从最高分到最低分,每一分对应的全省排名。若已知分数,可以通过将分数映射到一分一段表得出全省排名,反之亦然。图1是本发明中用到的同位分法的基本原理。设已知第n-1年的高校录取成绩sn-1,可利用第n-1年的一分一段表得到sn-1在第n-1年对应的全省排名rn-1;再利用第n年的一分一段表,找到排名rn-1对应的分数sn;此时,称sn为高校在第n年的同位分;定义同位分转换函数:s=ts(x,y,z)即基于y年的录取成绩x,结合第z年的一分一段表得出的同位分。图2是本发明中判断院校录取成绩是否稳定的具体流程。将历年的录取成绩通过一分一段表映射为历年录取位次,再将历年录取位次通过预测年份的一分一段表转化为同位分,相邻两年同位分求取差值,若所有差值的绝对值均不大于3分,则认为该院校是稳定的,否则认为该院校是非稳定的。图3是本发明所提出的基于高考大数据的院校录取成绩预测模型的具体流程。首先,对数据中的每个高校提取重要特征其中,jn表示第n年高校的招生人数,zn表示第n年高校的专业数,gn-1表示第n-1年的录取极差(录取最高分与录取最低分的差值);提取并计算高校的标签其中,rn表示第n年高校的录取位次(录取最低分在一分一段表中所对应的全省排名)。使用集成学习模型如gbdt进行非线性回归拟合,得到高校特征与标签之间的非线性关系。然后,使用图2中所提到的算法,判断该高校的录取分数是否稳定,若是,则使用该高校的同位分sn+1=ts(sn,n,n+1)作为第n+1年录取成绩的初步预测值,其中sn为第n年的录取成绩;否则,将rn作为粗略预测值,需要使用回归模型进一步缩小误差:提取出回归模型所需的高校特征,使用训练过的学习模型进行预测,得出高校的录取位次变化率预测值,计算录取位次预测值,再查询第n+1年的一分一段表,得到录取位次对应的分数,作为第n+1年录取成绩的初步预测值。最后,使用无监督聚类模型如谱聚类,根据高校的录取数据和高校信息,进行聚类,划分出具有竞争关系的簇。簇内第n年的录取成绩转换为第n+1年的同位分s′n+1=ts(sn,n,n+1),其中sn为第n年的录取成绩。先在簇内按照同位分s′n+1的值进行排序,记录每个排序位次对应的同位分。按照上一步得到的高校初步预测值,在簇内对高校进行排序,得到高校的当年竞争位序,并求每个高校的初步预测值与竞争位序对应的同位分的平均值,得到最终预测结果。表1一分一段表基本结构分数排名s1r1s2r2……表2竞争模型原理示例注:表中当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1