一种用于机器学习分析的大数据信息处理方法及系统与流程
本发明涉及大数据技术领域,具体是一种用于机器学习分析的大数据信息处理方法及系统。
背景技术:
基于大数据的信息分析技术近年来日益普及到我们生活的各个方面,通过大数据分析能够发现数据之间潜在的关联规律,提高信息分析的准确率和效率,增强预测精度。特别是通过对用户数据(例如用户消费数据、银行交易数据、移动轨迹和位置数据等)的大数据分析,能够发现用户的特点和偏好,提供针对性和个性化的服务。
特别是随着各种机器学习(例如聚类算法、神经网络、贝叶斯、回归分析等)的发展应用,利用机器学习实现大数据信息的分析和挖掘,其分析的数据量级和效率得到了本质上的飞跃,而且能够从大数据中挖掘深度的、潜在的的规律。
机器学习的原理,和人类的学习方式有很大的区别,机器学习并不需要理解大数据中包含信息的真实含义,而是对数据进行多个维度的分布特征的提取,再进行特征的统计归类等,最终获得大数据蕴含的规律性。
但是,用户数据中存在大量的敏感信息,一旦泄露会严重损害用户的安全和利益,降低公众对数据运营方的信赖感。而进行大数据信息分析,往往要通过网络设备传输、存储海量的用户数据,数据安全方面的风险比较高。目前,应对这方面风险的主要手段是进行用户数据的加密,或者施加各种模糊化、匿名化的处理,但是都不能很好的解决该问题,例如加密的用户数据也有可能被破解,或者是模糊化的用户数据有可能造成大数据分析过程中规律提取的障碍。
因此,如何保护用于机器学习分析的用户数据,提高用户数据的安全性是本领域技术人员亟待解决的问题。
技术实现要素:
鉴于上述问题,本发明的目的是为了解决进行大数据信息分析需要通过网络设备传输、存储海量的用户数据,数据安全方面的风险比较高的问题。
本发明实施例提供一种用于机器学习分析的大数据信息处理方法,包括:
获取原始用户数据,将所述原始用户数据与规则树进行匹配,生成用户元数据集合;
将所述用户元数据集合与分布特征一致性模板进行匹配,生成映射特征组;
利用机器学习算法对所述映射特征组进行分析,生成数据分布规律结果;
根据所述数据分布规律结果,实现大数据相关应用。
在一个实施例中,所述获取原始用户数据,将所述原始用户数据与规则树进行匹配,生成用户元数据集合,包括:
基于专家知识,构建规则树;
将所述原始用户数据中的文本内容与所述规则树的字段名、描述关键词进行检索对比,提取所述原始数据中的用户元数据;
利用所述规则树的逻辑关系组织所述用户源数据,生成用户源数据集合。
在一个实施例中,所述将所述用户元数据与分布特征一致性模板进行匹配,生成映射特征组,包括:
获取所述分布特征一致性模板中每个分布特征单元的价值估值;
将所述用户元数据集合与所述分布特征一致性模板进行匹配,生成所述用户元数据集合与所述分布特征一致性模板中每个分布特征单元的匹配度;
根据所述价值估值与所述匹配度,确定所述用户元数据集合的映射特征值;
将所述映射特征值进行集合,生成所述映射特征组。
在一个实施例中,所述获取所述分布特征一致性模板中每个分布特征单元的价值估值,包括:
根据所述分布特征单元中的字段名计算所述价值估值,具体计算公式为:
上式中,k表示所述分布特征一致性模板的第k个分布特征单元,vk表示所述第k个分布特征单元的价值估值,i表示字段名的序号,n表示所述分布特征单元具有n个字段名,l1表示常数系数,si表示第i个字段名的取值区间范围的量化值。
在一个实施例中,所述根据所述价值估值与所述匹配度,确定所述用户元数据集合的映射特征值,包括:
所述映射特征值的计算公式如下:
上式中,tk表示所述用户元数据集合对应于第k个分布特征单元的映射特征值,l2、l3表示经验常数,mk表示第k个分布特征单元与所述用户元数据集合的匹配度。
第二方面,本发明还提供一种用于机器学习分析的大数据信息处理系统,包括:
获取模块,用于获取原始用户数据,将所述原始用户数据与规则树进行匹配,生成用户元数据集合;
匹配模块,用于将所述用户元数据集合与分布特征一致性模板进行匹配,生成映射特征组;
分析模块,用于利用机器学习算法对所述映射特征组进行分析,生成数据分布规律结果;
应用模块,用于根据所述数据分布规律结果,实现大数据相关应用。
在一个实施例中,所述获取模块,包括:
构建子模块,用于基于专家知识,构建规则树;
提取子模块,用于将所述原始用户数据中的文本内容与所述规则树的字段名、描述关键词进行检索对比,提取所述原始数据中的用户元数据;
生成子模块,用于利用所述规则树的逻辑关系组织所述用户源数据,生成用户源数据集合。
在一个实施例中,所述匹配模块,包括:
获取子模块,用于获取所述分布特征一致性模板中每个分布特征单元的价值估值;
匹配子模块,用于将所述用户元数据集合与所述分布特征一致性模板进行匹配,生成所述用户元数据集合与所述分布特征一致性模板中每个分布特征单元的匹配度;
确定子模块,用于根据所述价值估值与所述匹配度,确定所述用户元数据集合的映射特征值;
集合子模块,用于将所述映射特征值进行集合,生成所述映射特征组。
在一个实施例中,所述获取子模块,包括:
根据所述分布特征单元中的字段名计算所述价值估值,具体计算公式为:
上式中,k表示所述分布特征一致性模板的第k个分布特征单元,vk表示所述第k个分布特征单元的价值估值,i表示字段名的序号,n表示所述分布特征单元具有n个字段名,l1表示常数系数,si表示第i个字段名的取值区间范围的量化值。
在一个实施例中,所述确定子模块中所述映射特征值的计算公式如下:
上式中,tk表示所述用户元数据集合对应于第k个分布特征单元的映射特征值,l2、l3表示经验常数,mk表示第k个分布特征单元与所述用户元数据集合的匹配度。
本发明实施例提供的上述技术方案的有益效果至少包括:
本发明实施例提供的一种用于机器学习分析的大数据信息处理方法,本方法利用“机器学习并不需要理解大数据中包含信息的真实含义,而是对数据进行多个维度的分布特征的提取,再进行特征的统计归类等,最终获得大数据蕴含的规律性”的特点,将原始的、携带有真实信息含义的用户数据,映射为不携带任何真实信息含义、但在各个维度上的分布特征与用户数据趋于一致的映射数据,再通过机器学习算法,针对映射数据构成的大数据集合进行特征提取和统计归类等分析,获得数据分布规律结果,进而,根据机器学习分析的数据分布规律结果,实现大数据相关应用。在网络中传输、存储的都是不携带真实信息含义的映射数据,即便被截获、泄露,也不可能从中获得任何的有价值的用户数据,从而降低了大数据分析的信息安全风险。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步地详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例提供的用于机器学习分析的大数据信息处理方法的流程图;
图2为本发明实施例提供的步骤s101流程图;
图3为本发明实施例提供的步骤s102流程图;
图4为本发明实施例提供的用于机器学习分析的大数据信息处理系统的框图;
图5为本发明实施例提供的获取模块41的框图;
图6为本发明实施例提供的匹配模块42的框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
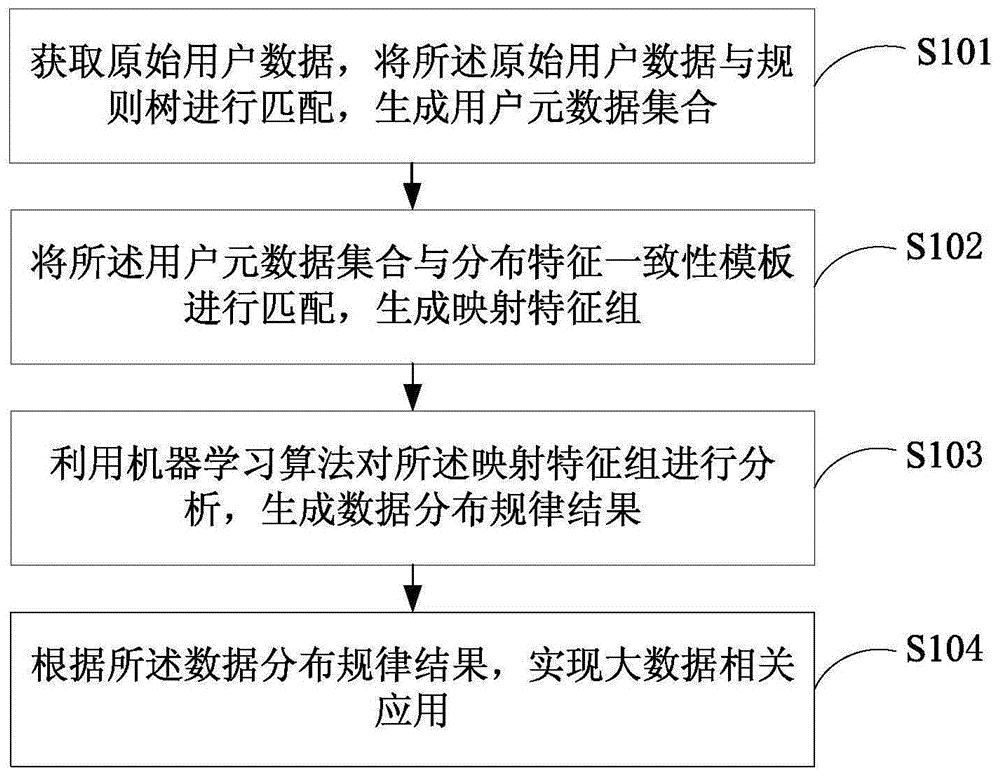
参照图1所示,本发明实施例提供的一种用于机器学习分析的大数据信息处理方法,该方法包括:步骤s101~s104;
s101、获取原始用户数据,将所述原始用户数据与规则树进行匹配,生成用户元数据集合;
具体的,将上述原始用户数据与上述规则树进行关键词匹配,生成具有哦字段描述结构、关联结构的用户元数据集合。
s102、将所述用户元数据集合与分布特征一致性模板进行匹配,生成映射特征组;
具体的,将所述用户元数据集合与分布特征一致性模板进行匹配后,生成的映射特征组的特征分布规律与用户元数据集合自身具有的特征分布规律保持一致;其中,上述分布特征一致性模板带有价值估值。
进一步地,上述分布特征一致性模板包含若干个分布特征单元,每个分布特征单元具有与用户元数据集合相同的字段名,每字段名具有预定的字段属性值的取值区间,分布特征单元所包含的字段名与用户元数据集合中的字段名对应。
s103、利用机器学习算法(例如聚类算法、神经网络、贝叶斯、回归分析等)对所述映射特征组进行分析,生成数据分布规律结果(例如聚类或者分类结果等);
s104、根据所述数据分布规律结果,实现大数据相关应用。
例如,通过聚类算法将映射特征组归为某个类群,则对应的用户也就归为该类群,可以根据该类群,向用户提供相应的个性化服务或者推送。
本实施例中,在将大数据分析运用于用户数据的过程中,在原始用户数据的数据源一端,将原始用户数据映射为不携带真实信息含义的映射数据,同时保持映射数据在各个维度上的分布特征与用户数据趋于一致,避免了用户数据在存储、分析、应用等环节的过度集中,减少了大量用户数据的直接网络传输,进而保护了用户数据,提高了用户数据的安全性。
在一个实施例中,参照图2所示,上述步骤s101中获取原始用户数据,将所述原始用户数据与规则树进行匹配,生成用户元数据集合,包括:
s1011、基于专家知识,构建规则树;
其中,上述规则树由专家知识彼此按照逻辑关系进行关联的字段名、描述关键词组成。
s1012、将所述原始用户数据(文本或表单格式的原始用户数据)中的文本内容与所述规则树的字段名、描述关键词进行检索对比,提取所述原始数据中的用户元数据;
具体的,上述用户元数据根据检索对比结果,从原始用户数据中自动提取字段名和字段属性值的用户元数据。
s1013、利用所述规则树的逻辑关系组织所述用户源数据,生成用户源数据集合。
在一个实施例中,参照图3所示,上述步骤s102中所述将所述用户元数据与分布特征一致性模板进行匹配,生成映射特征组,包括:
s1021、获取所述分布特征一致性模板中每个分布特征单元的价值估值;
具体的,根据所述分布特征单元中的字段名计算所述价值估值,具体计算公式为:
上式中,k表示所述分布特征一致性模板的第k个分布特征单元,vk表示所述第k个分布特征单元的价值估值,i表示字段名的序号,n表示所述分布特征单元具有n个字段名,l1表示常数系数,si表示第i个字段名的取值区间范围的量化值。
进一步地,分布特征单元的字段属性值的取值区间覆盖范围越大,则该分布特征单元的该字段名对应的价值估值越低,全部字段名的价值估值累加作为分布特征单元的价值估值。
s1022、将所述用户元数据集合与所述分布特征一致性模板进行匹配,生成所述用户元数据集合与所述分布特征一致性模板中每个分布特征单元的匹配度;
具体的,用户元数据集合中字段名的字段属性值落入第k个分布特征单元的同字段名取值区间的次数mk作为该分布特征单元与用户元数据集合的匹配度。
s1023、根据所述价值估值与所述匹配度,确定所述用户元数据集合的映射特征值;
具体的,所述映射特征值的计算公式如下:
上式中,tk表示所述用户元数据集合对应于第k个分布特征单元的映射特征值,l2、l3表示经验常数,mk表示第k个分布特征单元与所述用户元数据集合的匹配度。
s1024、将所述映射特征值进行集合,生成所述映射特征组。
具体的,用户元数据集合对应于分布特征一致性模板的各个分布特征单元的特征值的集合<t1,t2…tk…>,作为用户元数据集合的映射特征组。
本实施例中,在原始用户数据的数据源获得映射特征组与用户元数据集合自身具有的特征分布规律一致的特征分布规律,将原始的、携带有真实信息含义的用户数据,映射为不携带任何真实信息含义、但在各个维度上的分布特征与用户数据趋于一致的映射数据,并将映射数据用于机器学习分析,在网络中传输、存储的都是不携带真实信息含义的映射数据,降低了大数据分析的信息安全风险。
基于同一发明构思,本发明实施例还提供了一种用于机器学习分析的大数据信息处理系统,由于该系统所解决问题的原理与前述一种用于机器学习分析的大数据信息处理方法相似,因此该装置的实施可以参见前述方法的实施,重复之处不再赘述。
本发明实施例提供的一种用于机器学习分析的大数据信息处理系统,参照图4所示,包括:
获取模块41,用于获取原始用户数据,将所述原始用户数据与规则树进行匹配,生成用户元数据集合;
具体的,将上述原始用户数据与上述规则树进行关键词匹配,生成具有哦字段描述结构、关联结构的用户元数据集合。
匹配模块42,用于将所述用户元数据集合与分布特征一致性模板进行匹配,生成映射特征组;
具体的,将所述用户元数据集合与分布特征一致性模板进行匹配后,生成的映射特征组的特征分布规律与用户元数据集合自身具有的特征分布规律保持一致;其中,上述分布特征一致性模板带有价值估值。
分析模块43,用于利用机器学习算法例如聚类算法、神经网络、贝叶斯、回归分析等)对所述映射特征组进行分析,生成数据分布规律结果例如聚类或者分类结果等);
应用模块44,用于根据所述数据分布规律结果,实现大数据相关应用。
其中,获取模块41与匹配模块42都设置于原始用户数据的数据源一端。
在一个实施例中,所述获取模块41,包括:
构建子模块411,用于基于专家知识,构建规则树;
其中,上述规则树由彼此按照逻辑关系进行关联的字段名、描述关键词组成。
提取子模块412,用于将所述原始用户数据(文本或表单格式的原始用户数据)中的文本内容与所述规则树的字段名、描述关键词进行检索对比,提取所述原始数据中的用户元数据;
具体的,上述用户元数据根据检索对比结果,从原始用户数据中自动提取字段名和字段属性值的用户元数据。
生成子模块413,用于利用所述规则树的逻辑关系组织所述用户源数据,生成用户源数据集合。
在一个实施例中,所述匹配模块42,包括:
获取子模块421,用于获取所述分布特征一致性模板中每个分布特征单元的价值估值;
进一步地,分布特征单元的字段属性值的取值区间覆盖范围越大,则该分布特征单元的该字段名对应的价值估值越低,全部字段名的价值估值累加作为分布特征单元的价值估值。
匹配子模块422,用于将所述用户元数据集合与所述分布特征一致性模板进行匹配,生成所述用户元数据集合与所述分布特征一致性模板中每个分布特征单元的匹配度;
确定子模块423,用于根据所述价值估值与所述匹配度,确定所述用户元数据集合的映射特征值;
集合子模块424,用于将所述映射特征值进行集合,生成所述映射特征组。
在一个实施例中,所述获取子模块421,包括:
根据所述分布特征单元中的字段名计算所述价值估值,具体计算公式为:
上式中,k表示所述分布特征一致性模板的第k个分布特征单元,vk表示所述第k个分布特征单元的价值估值,i表示字段名的序号,n表示所述分布特征单元具有n个字段名,l1表示常数系数,si表示第i个字段名的取值区间范围的量化值。
在一个实施例中,所述确定子模块423中所述映射特征值的计算公式如下:
上式中,tk表示所述用户元数据集合对应于第k个分布特征单元的映射特征值,l2、l3表示经验常数,mk表示第k个分布特征单元与所述用户元数据集合的匹配度。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!