一种基于双目图像视觉的物资形状识别方法与流程
本发明涉及图像识别领域,具体涉及一种基于双目图像视觉的物资形状识别方法。
背景技术:
目前,通常采用以下几种识别技术来进行物资形状的识别:
(1)射频设别:利用扫描条形码的技术来识别物资的种类。
(2)材质识别:利用传感器来识别物资的材质。
(3)超声波测距+称重识别:利用超声波测距技术大致计算物资的长度和直径,并利用称重技术来识别物资的重量。
(4)常规图像识别:利用背景差分法来识别物资。
然而实践表明,上述物资识别技术由于自身原理所限,普遍存在如下问题:一、射频设别技术要求物资必须带有条形码,一旦物资的条形码脱落,其便无法进行物资的识别,由此导致其适用范围受限。二、材质识别技术存在实现成本高、技术难度大、识别效率低的问题。三、超声波测距+称重识别技术存在识别精确度低的问题。四、常规图像识别技术要求图像的背景是均匀且不变的,导致其存在技术难度大、识别效率低的问题。基于此,有必要发明一种全新的物资识别技术,以解决现有物资识别技术存在的上述问题。
技术实现要素:
为解决上述问题,本发明提供了一种基于双目图像视觉的物资形状识别方法,可以实现物资形状的快速精确识别,适用范围广。
为实现上述目的,本发明采取的技术方案为:
一种基于双目图像视觉的物资形状识别方法,包括如下步骤:
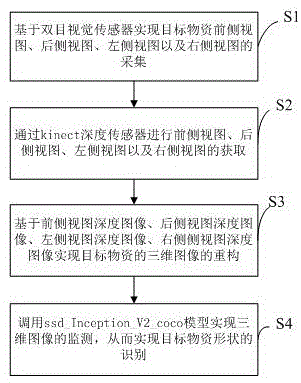
s1、基于双目视觉传感器实现目标物资前侧视图、后侧视图、左侧视图以及右侧视图的采集;
s2、通过kinect深度传感器进行前侧视图、后侧视图、左侧视图以及右侧视图的获取;
s3、将所获得的前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像进行三角化,然后在尺度空间中融合所有三角化的深度图像构建分层有向距离场,对距离场中所有的体素应用整体三角剖分算法产生一个涵盖所有体素的凸包,并利用marchingtetrahedra算法构造等值面,将获得的前侧视图等值面、后侧视图等值面、左侧视图等值面、右侧视图等值面进行拼接,拼接时,使得前侧视图等值面、后侧视图等值面、左侧视图、右侧视图等值面的顶面完全重合,从而得到目标物资的三维图像;
s4、调用ssd_inception_v2_coco模型实现三维图像的监测,从而实现目标物资形状的识别。
进一步地,所述前侧视图、后侧视图、左侧视图以及右侧视图均需全覆盖顶面及对应的侧面。
进一步地,还包括根据目标物资形状识别的结果调用对应的测量标尺进行目标物资尺寸测量的步骤。
进一步地,还包括进行三维图像各个面上测量点坐标标定的步骤,测量标尺以上述坐标为节点进行测量。
进一步地,还包括驱动三维图像旋转的步骤,从而实现各个面的测量。
进一步地,所述ssd_inception_v2_coco模型采用ssd目标检测算法,用coco数据集预训练inception_v2深度神经网络,然后用先前准备好的物资三维图像数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测物资形状的目标检测模型。
进一步地,还包括基于tiramisu_coco模型实现前侧视图、后侧视图、左侧视图以及右侧视图背景的清除的步骤。
本发明可以实现物资形状的快速精确识别,适用范围广。
附图说明
图1为本发明实施例1的流程图。
图2为本发明实施例2的流程图。
图3为本发明实施例3的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
实施例1
如图1所示,一种基于双目图像视觉的物资形状识别方法,包括如下步骤:
s1、基于双目视觉传感器实现目标物资前侧视图、后侧视图、左侧视图以及右侧视图的采集;所述前侧视图、后侧视图、左侧视图以及右侧视图均需全覆盖顶面及对应的侧面,便于后续的拼接操作;
s2、通过kinect深度传感器进行前侧视图、后侧视图、左侧视图以及右侧视图的获取;
s3、基于前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像实现目标物资的三维图像的重构,具体的,将所获得的前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像进行三角化,然后在尺度空间中融合所有三角化的深度图像构建分层有向距离场,对距离场中所有的体素应用整体三角剖分算法产生一个涵盖所有体素的凸包,并利用marchingtetrahedra算法构造等值面,将获得的前侧视图等值面、后侧视图等值面、左侧视图等值面、右侧视图等值面进行拼接,拼接时,使得前侧视图等值面、后侧视图等值面、左侧视图、右侧视图等值面的顶面完全重合,从而得到目标物资的三维图像;
s4、调用ssd_inception_v2_coco模型实现三维图像的监测,从而实现目标物资形状的识别。
本实施例中,所述ssd_inception_v2_coco模型采用ssd目标检测算法,用coco数据集预训练inception_v2深度神经网络,然后用先前准备好的物资三维图像数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测物资形状的目标检测模型。
实施例2
s1、基于双目视觉传感器实现目标物资前侧视图、后侧视图、左侧视图以及右侧视图的采集;所述前侧视图、后侧视图、左侧视图以及右侧视图均需全覆盖顶面及对应的侧面,便于后续的拼接操作;
s2、通过kinect深度传感器进行前侧视图、后侧视图、左侧视图以及右侧视图的获取;
s3、基于前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像实现目标物资的三维图像的重构,具体的,将所获得的前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像进行三角化,然后在尺度空间中融合所有三角化的深度图像构建分层有向距离场,对距离场中所有的体素应用整体三角剖分算法产生一个涵盖所有体素的凸包,并利用marchingtetrahedra算法构造等值面,将获得的前侧视图等值面、后侧视图等值面、左侧视图等值面、右侧视图等值面进行拼接,拼接时,使得前侧视图等值面、后侧视图等值面、左侧视图、右侧视图等值面的顶面完全重合,从而得到目标物资的三维图像;
s4、调用ssd_inception_v2_coco模型实现三维图像的监测,从而实现目标物资形状的识别;
s5、根据目标物资形状识别的结果调用对应的测量标尺进行目标物资尺寸测量,测量时首先进行三维图像各个面上测量点坐标标定,测量标尺以上述坐标为节点进行测量,然后根据需要测量的面驱动三维图像旋转,从而实现各个面的测量。
本实施例中,所述ssd_inception_v2_coco模型采用ssd目标检测算法,用coco数据集预训练inception_v2深度神经网络,然后用先前准备好的物资三维图像数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测物资形状的目标检测模型。
实施例3
s1、基于双目视觉传感器实现目标物资前侧视图、后侧视图、左侧视图以及右侧视图的采集;所述前侧视图、后侧视图、左侧视图以及右侧视图均需全覆盖顶面及对应的侧面,便于后续的拼接操作;
s2、基于tiramisu_coco模型实现前侧视图、后侧视图、左侧视图以及右侧视图背景的清除;
s3、通过kinect深度传感器进行前侧视图、后侧视图、左侧视图以及右侧视图的获取;
s4、基于前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像实现目标物资的三维图像的重构,具体的,将所获得的前侧视图深度图像、后侧视图深度图像、左侧视图深度图像、右侧侧视图深度图像进行三角化,然后在尺度空间中融合所有三角化的深度图像构建分层有向距离场,对距离场中所有的体素应用整体三角剖分算法产生一个涵盖所有体素的凸包,并利用marchingtetrahedra算法构造等值面,将获得的前侧视图等值面、后侧视图等值面、左侧视图等值面、右侧视图等值面进行拼接,拼接时,使得前侧视图等值面、后侧视图等值面、左侧视图、右侧视图等值面的顶面完全重合,从而得到目标物资的三维图像;
s5、调用ssd_inception_v2_coco模型实现三维图像的监测,从而实现目标物资形状的识别。
本实施例中,所述ssd_inception_v2_coco模型采用ssd目标检测算法,用coco数据集预训练inception_v2深度神经网络,然后用先前准备好的物资三维图像数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测物资形状的目标检测模型。所述tiramisu_coco模型用coco数据集训练,然后用先前准备好的带目标物资和背景的数据集训练该模型,微调模型中的各项参数,最后得到合适的模型。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!