面向无人驾驶的前背景编解码器网络目标提取方法与流程
本发明属于视频处理技术领域,具体是目标提取技术领域,涉及一种面向无人驾驶的前背景编解码器网络目标提取方法。
背景技术:
无人驾驶作为便利人们未来出行的重要方式近年来受到学术界和产业界的广泛关注。无人驾驶技术的要求能够获取实时视频路况信息,理解路况视频的内容并据此发出驾驶操作指令。而理解视频内容作为其中的关键与难点成为研究人员的攻关课题。具体而言,理解路况的视频内容首先要确定路面上不同目标的位置与类别(如行人、车辆、行道树等等),并进一步结合如雷达测距等其他信息准确判定应执行的驾驶操作类别。而视频目标提取作为一种针对视频的预处理技术,能够从像素级别提取任意目标的位置与类别信息,向车辆中央控制系统提供更加精确的目标区域方位,从而提高无人驾驶的安全性能。
视频目标提取顾名思义是针对给定视频逐帧地将一个或多个目标从背景中提取出像素级的区域。目前的主流方法主要考虑三种场景:1)提供了视频首帧图像目标标注的半监督视频目标提取;2)未提供视频首帧目标标注的无监督视频目标提取;3)模拟用户交互的交互式视频目标提取(提取过程中可交互地提供弱化的目标标注,如在目标上画一笔作为标注),其中关于第一种半监督视频目标提取场景的研究较多。
视频目标提取面临着诸多挑战,例如目标之间的相互遮挡、背景中存在与目标相似的实体、目标外观与尺寸的巨大变化、快速运动带来的模糊现象等等。借助以深层神经网络为代表的深度学习技术,研究人员提出了许多方法来处理视频目标提取问题。现有的模型和方法主要针对视频的三种不同输入信息:1)原始视频帧;2)原始视频帧的感兴趣区域(regionofinterest,简称roi);3)视频前一帧的预测掩膜(即提取结果)与当前视频帧(一般将两者沿着通道方向叠加)。具体来说,第一种是原始视频帧,保留了原始图像信息,但在视频目标提取任务中缺少时序信息;第二种使用roi对视频进行裁剪获得目标的粗略位置信息,有利于后续更准确地提取目标位置,但增加了视频的预处理时间且不是端到端(存在多个独立优化目标)的模型;第三种虽然拥有前一帧的目标掩膜信息,但是直接与当前帧叠加不能明确提供足够的指导信息用于网络模型训练,使得视频中的目标信息获取变得困难,从而增加了目标提取任务的复杂度。上述方法在处理输入信息时存在各自的缺陷,无法为后续视频目标的提取过程提供充分的目标信息。因此,为了提高无人驾驶的安全性能,有必要需要设计一种既能有效利用视频帧的时序相关性又能在输入信息中提供丰富目标信息的方法,以更准确地提取视频中的目标。
技术实现要素:
本发明的目的就是针对现有技术的不足,提供一种面向无人驾驶的前背景编解码器网络目标提取方法,充分结合目标空间信息与环境中包含的上下文信息获得更加准确的目标位置预测信息,能向无人驾驶中的车辆智能控制系统提供更加准确的目标位置信息,从而增加无人驾驶场景的安全系数。
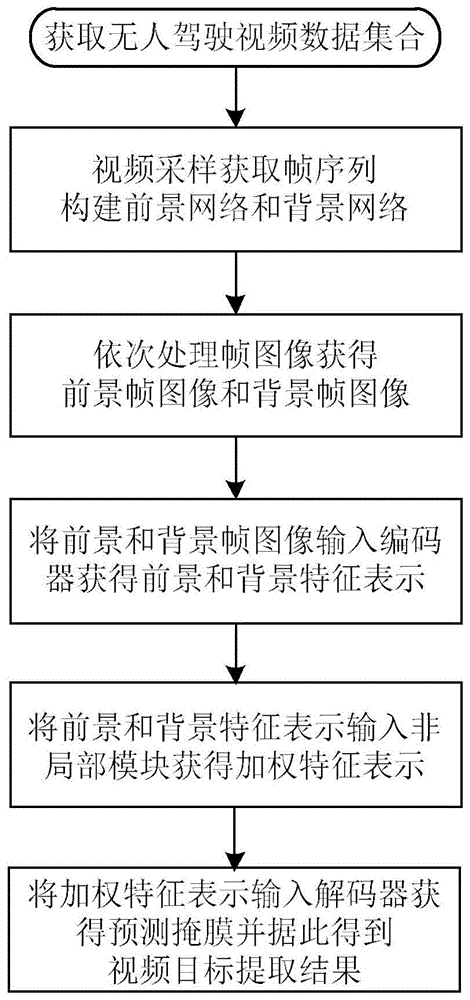
本发明方法首先获取无人驾驶场景的视频数据集合,然后进行以下操作:
步骤(1).对视频采样,获得帧序列,构建包括编码器、非局部模块和解码器的前景网络和背景网络;
步骤(2).依次处理帧图像,经过扩张和侵蚀处理获得放大和缩小的目标掩膜,并据此分别得到前景帧图像和背景帧图像;
步骤(3).将前景帧图像和背景帧图像分别输入前景网络和背景网络的编码器,获得前景特征表示和背景特征表示;
步骤(4).将前景特征表示和背景特征表示分别输入前景网络和背景网络的非局部模块,获得对应的加权特征表示;
步骤(5).将加权特征表示分别输入前景网络和背景网络的解码器,获得对应的预测掩膜并通过加权求和获得视频目标提取结果。
进一步,步骤(1)具体方法是:
(1-1).对视频进行均匀采样,获得对应的m帧rgb帧图像集合
(1-2).构建前景网络与背景网络,这两个网络是具有相同结构的孪生网络,由编码器、非局部模块和解码器级联组成;
所述的编码器由残差网络构成,去除残差网络最后的全局池化层和全连接层,且通过空洞卷积放大网络中间层的特征尺寸,其输入为帧图像,输出为特征表示;
所述的非局部模块由多种矩阵操作组成,包括矩阵点积和逐元素乘积,输入为编码器产生的特征表示,输出为加权后的特征表示;
所述的解码器由上采样与残差网络的基础模块组成,输入为非局部模块产生的加权特征表示,输出为帧图像每一像素的类别概率,即网络输出的预测结果。
进一步,步骤(2)具体方法是:
(2-1).对视频首帧即视频第一帧图像f1,其目标掩膜矩阵
所述的目标掩膜是指对应帧图像的目标类别矩阵,记为标注集合{mi|i=1,..,m},其中
(2-2).对视频的第i′张帧图像fi′,i′=2,..,m,其前一帧的前景网络预测结果为
(2-3).对视频的第i′张帧图像fi′,i′=2,..,m,其前一帧的背景网络预测结果为
再进一步,步骤(3)具体方法是:
(3-1).将前景帧图像fif输入到前景网络中的编码器,i=1,..,m,获得四个阶段的特征表示,记为:
(3-2).将背景帧图像fib输入到背景网络中的编码器模块,i=1,..,m,获得四个阶段的特征表示,记为:
又进一步,步骤(4)具体方法是:
(4-1).将视频首帧的前景帧图像f1f和背景帧图像f1b按照步骤(3)的处理分别获得前景特征表示
(4-2).将视频首帧经过前景网络获得的最后一个特征表示
采用相同操作,背景网络获得加权特征表示yb,其维度与
更进一步,步骤(5)具体方法是:
(5-1).解码器由三个调优模块组成,调优模块的输入为对应解码器产生的特征表示与上一调优模块的输出特征表示,通过上采样与残差网络的基础模块等操作,输出放大尺寸后的特征表示;
(5-2).对前景网络的解码器,将(4-2)中的加权特征表示yf与(3-1)中的前景网络编码器第三阶段的特征表示
(5-3).将第一个调优特征表示
(5-4).将第二个调优特征表示
(5-5).将第三个调优特征表示
(5-6).前景网络的优化目标是使得预测掩膜的概率表示矩阵
(5-7).对新的给定视频及其首帧目标掩膜,使用优化后的前景网络和背景网络,获得前景网络预测掩膜的概率表示矩阵
其中λp为加权参数,0<λp<1,[*,*]表示矩阵元素,预测掩膜包含视频帧图像的每一个像素所属类别,即像素属于背景或是目标区域,据此获得视频目标提取结果。
本发明方法主要针对无人驾驶场景给出基于前背景编解码器网络的目标提取技术,该技术具有以下几个特点:1)使用前景网络与背景网络分别学习视频内的前景目标特征与背景环境特征,而现有方法一般关注前景目标而忽视了背景中包含的上下文信息;2)利用前一时间步预测的目标掩膜扩张与侵蚀来缩小当前时间步输入视频帧的目标区域,而现有方法在预处理输入视频帧时使用感兴趣区域进行图像裁剪或进行简单的通道叠加,分别导致不能端到端处理和增加了任务的时空复杂度;3)考虑了模板帧即首帧真实目标信息的非局部模块可以获得时序上的长期依赖关系,而现有方法考虑一般仅使用特征叠加,无法准确刻画目标在视频中的长期时序关联特性。
本发明方法的主要优点在于:1)通过构建前景网络与背景网络分别学习前景目标与背景环境的特征,能够充分结合目标空间信息与环境中包含的上下文信息获得更加准确的目标位置预测信息;2)利用输入视频帧预处理,即利用前一时间步预测的目标掩膜扩张与侵蚀来估计当前时间步输入视频帧可能目标区域,使得模型能够快速关注可能的目标区域,减少了计算量且提升了速度;3)非局部模块使用了视频第一帧产生的特征建立长期时序依赖关系,避免了过度依赖短期时序关系造成目标位置预测的错误累加问题。本发明方法可应用于从路况视频中准确提取出像素级别的目标位置与类别,从而为无人驾驶车辆的中央控制系统提供精确的目标区域方位,提高无人驾驶的安全性能。
附图说明
图1是本发明方法的流程图。
具体实施方式
以下结合附图对本发明作进一步说明。
一种面向无人驾驶的前背景编解码器网络目标提取方法,对采样的帧序列利用目标位置信息结合扩张与侵蚀技术进行预处理,通过构建前景网络与背景网络提取对应的视频特征,利用改良的非局部模块结合视频首帧提取的模板特征对视频特征进行加权处理,并将加权后的视频特征输入到对应网络的解码器模块以获得视频目标的提取结果。本发明方法通过利用前景网络和背景网络刻画视频的前景目标和背景环境的结构特征,能够充分结合目标空间信息与环境中包含的上下文信息获得更加准确的目标位置预测信息;同时利用目标掩膜扩张与侵蚀来估计当前时间步视频帧可能存在的目标区域,降低时间复杂度和计算开销;非局部模块的利用使得视频帧的长期时序依赖关系得以构建。通过这样的方式可以更加准确地捕捉路况视频的目标位置与类别,为无人驾驶提供更加精准的目标区域方位。
如图1,该方法首先获取无人驾驶场景的视频数据集合,然后进行如下操作:
步骤(1).对视频采样,获得帧序列,构建包括编码器、非局部模块和解码器的前景网络和背景网络;具体方法是:
(1-1).对视频进行均匀采样,获得对应的m帧rgb帧图像集合
(1-2).构建前景网络与背景网络,这两个网络是具有相同结构的孪生网络,由编码器、非局部模块和解码器级联组成;
所述的编码器由残差网络resnet构成,去除残差网络最后的全局池化层和全连接层,且通过空洞卷积(dilatedconvolution)放大网络中间层的特征尺寸,其输入为帧图像,输出为特征表示;
所述的非局部模块由多种矩阵操作组成,包括矩阵点积和逐元素乘积,输入为编码器产生的特征表示,输出为加权后的特征表示;
所述的解码器由上采样与残差网络的基础模块组成,输入为非局部模块产生的加权特征表示,输出为帧图像每一像素的类别概率,即网络输出的预测结果。
步骤(2).依次处理帧图像,经过扩张和侵蚀处理获得放大和缩小的目标掩膜,并据此分别得到前景帧图像和背景帧图像;具体方法是:
(2-1).对视频首帧即视频第一帧图像f1,其目标掩膜矩阵
所述的目标掩膜是指对应帧图像的目标类别矩阵,记为标注集合{mi|i=1,..,m},其中
(2-2).对视频的第i′张帧图像fi′,i′=2,..,m,其前一帧的前景网络预测结果为
(2-3).对视频的第i′张帧图像fi′,i′=2,..,m,其前一帧的背景网络预测结果为
步骤(3).将前景帧图像和背景帧图像分别输入前景网络和背景网络的编码器,获得前景特征表示和背景特征表示;具体方法是:
(3-1).将前景帧图像fif输入到前景网络中的编码器,i=1,..,m,获得四个阶段的特征表示,记为:
(3-2).将背景帧图像fib输入到背景网络中的编码器模块,i=1,..,m,获得四个阶段的特征表示,记为:
步骤(4).将前景特征表示和背景特征表示分别输入前景网络和背景网络的非局部模块,获得对应的加权特征表示;具体方法是:
(4-1).将(2-1)中视频首帧的前景帧图像f1f和背景帧图像f1b按照步骤(3)的处理分别获得前景特征表示
(4-2).将视频首帧经过前景网络获得的最后一个特征表示
其中a对应特征表示
步骤(5).将加权特征表示分别输入前景网络和背景网络的解码器,获得对应的预测掩膜并通过加权求和获得视频目标提取结果;具体方法是:
(5-1).解码器由三个调优模块组成,调优模块的输入为对应解码器产生的特征表示与上一调优模块的输出特征表示,通过上采样与残差网络的基础模块等操作,输出放大尺寸后的特征表示;
(5-2).对前景网络的解码器,将(4-2)的加权特征表示yf与(3-1)中的前景网络编码器第三阶段的特征表示
(5-3).将第一个调优特征表示
(5-4).将第二个调优特征表示
(5-5).将第三个调优特征表示
(5-6).前景网络的优化目标是使得预测掩膜的概率表示矩阵
(5-7).对新的给定视频及其首帧目标掩膜,使用优化后的前景网络和背景网络,获得前景网络预测掩膜的概率表示矩阵
其中λp为加权参数,0<λp<1,[*,*]表示矩阵元素,预测掩膜包含视频帧图像的每一个像素所属类别,即像素属于背景或是目标区域,据此可获得视频目标提取结果。
本实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围的不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!