一种基于图核的深度网络嵌入学习方法与流程
本发明涉及一种基于图核的深度网络嵌入学习方法,为网络的节点生成表征向量,进而基于该向量可进行其他应用的研究,适用于社交网络分析等;属于数据挖掘、机器学习、社交网络与图算法研究领域。
背景技术:
随着社交网络的流行,研究人员开始利用机器学习的算法从社交网络多模态数据中挖掘有价值的信息,例如,利用用户之间的关注关系(结构数据)以及用户本身的属性信息(微博文本,个人属性,即内容数据),对用户进行兴趣建模,进而对用户进行分类、聚类和推荐。在这方面一个非常重要的技术就是网络嵌入(networkembedding),它的目的是为网络中的每个节点学习一个低维、连续、密集的表征向量。
现有的网络嵌入方法包括矩阵分解方法和基于深度学习的方法。基于矩阵分解的方法是利用矩阵分解技术,对稀疏网络的邻接矩阵进行分解,利用分解后得到的低维向量作为表征向量。例如,利用利用拉普拉斯图的谱分解方法对输入的邻接矩阵进行分解获得低维的表征向量。然而这类方法在计算性能以及效果上面都有缺陷。首先,矩阵分解消耗大量的时间以及计算资源,这类方法很难应用于大型网络中;然后,矩阵分解的过程中忽视了网络中很多重要的模式,比如同质性以及结构等价性;最后,利用矩阵分解的方法只考虑了节点之间的全局相关性,而忽略了节点的本地邻居之间的相关性。
近年来,研究人员利用神经网络以及深度学习来进行网络嵌入的学习。这类方法提升了表征向量的质量,同时可以适用于大规模的网络中。例如,首先利用随机游走将网络转化成节点构成的序列集合,然后利用skip-gram算法在节点序列上生成表征向量。这类网络嵌入的方法能够发掘网络中隐含的非线性关系,并且不需要人工预定义节点之间的关系,因此可以生成高质量的表征向量。
但是真实的社交网络往往是稀疏的,其中大部分的节点只有很少的链接指向其它节点。如何为稀疏节点生成更高质量的表征向量是社交网络分析的一个基础和关键问题。
技术实现要素:
针对当前方法对处理稀疏性的不足,提出一种基于图核的深度网络嵌入学习方法,来提高网络嵌入方法的性能,此方法融合了图核函数,深度学习,社交网络分析等技术,结合节点属性信息和潜在的隐式社区结构。
本发明的技术解决方案:
一种基于图核的深度网络嵌入学习模型,包括以下步骤:
步骤a.构造节点的子结构集合:节点的完整拓扑结构和语义信息往往被保留在某些子结构中。例如,节点与邻居节点的连接形成该节点的邻域子结构,节点往往属于某些社区构成社区子结构等。分别利用广度优先采样和常见的社区发现算法为每一个节点生成若干个邻域子结构和社区子结构,构造节点的子结构集合。
步骤b.生成子结构的特征向量:对步骤a.中所得到的每一个节点的子结构集合,用图核为每一个子结构生成一个特征向量。特别地,对于邻域子结构,首先将该子结构转化成字符串,然后再用频谱字符串核抽取其k-gram组成特征向量;对于社区子结构,利用r卷积核函数首先将社区子结构分解成一组邻域子结构,然后基于该组邻域子结构计算社区子结构的特征向量。
步骤c.在多个重构核希尔伯特空间(rkhs)上近似特征向量:由于步骤b.中子结构的特征向量维数往往很大甚至无穷维,利用sketch技术将子结构的特征向量在多个重构核希尔伯特空间上进行近似。特别地,引入多个不同指数的多项式核函数,利用tensor-sketch技术近似子结构特征向量在这些多项式核函数下的多阶特征向量,这些特征向量分别属于不同的重构核希尔伯特空间(rkhs)。
步骤d.设计基于图核的深度卷积模型:对于每一个节点,将步骤c中所有子结构的多个近似特征向量输入到一个深度卷积网络模型,得到节点的表征向量。特别地,构建一个基于图核的网络嵌入学习模型,包括一个输入层,一个深度卷积层,一个pooling层,多个线性层和一个输出层。输出为节点的最终表征向量。
步骤e.提出一种挖掘潜在社区信息的优化方法:对于步骤d.中提出的深度网络嵌入学习模型,提出一种挖掘潜在社区信息的优化方法,使得生成的表征向量可以保存社区结构信息。特别地,为了学习一阶或更高阶的结构特征,构建一种基于随机游走和负样本采样的损失函数;为了学习社区结构特征,构建一种基于tripletnetwork的损失函数,使得同一个社区下的节点拥有更相似的表征向量。
步骤a中,为每个节点构建一个子结构集合,记为gv={gi},其中gi是属于节点v的一个子结构。对于邻域子结构,采用广度优先采样方法,收集节点q跳范围内的所有邻居组成邻域子结构;将节点的某个社区子图作为社区子结构。每个节点都包含若干个邻域子结构和社区子结构。
步骤b中,对于邻域子结构,按照节点加入时间的顺序采用一种广度优先采样的方法来为每个子结构生成字符串,然后利用n-gram方法生成字符串核特征向量,该特征向量保留了节点加入网络的时间信息。特别地,给定一个邻域子结构n,首先采用按照广度优先采样及节点加入的先后顺序收集所有节点的属性信息,然后连接它们得到字符串sn。记prej和sufj分别代表节点v的第j个邻居属性值cj的(k-1)个前缀和(k-1)个后缀。设函数ψ:
步骤b中,对于社区子结构,首先依据r卷积核要求将该子结构分解成多个邻域子结构,然后为每个邻域子结构生成特征向量,最后利用利用r卷积公式生成社区子结构特征向量,该特征向量保留了节点的潜在社区结构信息。特别地,r卷积图核分解子结构g为一组可比较的原子单位的集合γ(g)。两个子结构g和h间的r卷积图核被定义为,
其中k是一个用于比较原子单位g和h间的核函数,φ(g)是子结构g的特征向量记录子结构中每个原子单位的个数。依据r卷积图核的定义,每个社区子结构m可以被分解多个邻域子结构,其特征向量可以被呈现为,
其中,
步骤c中,考虑到子结构的特向量维数往往很大甚至接近无穷,利用sketch技术压缩子结构特征向量。特别地,给定φ(g),
步骤d中,构建一个基于图核的深度卷积模型,包括一个输入层,一个深度卷积层,一个pooling层,多个线性层和一个输出层。输出为节点的最终表征向量。特别地,对于节点v的每一层近似特征向量集合
tk=f(w·xk:(k+h-1)+b)
其中,
步骤e中,计目标函数来优化深度学习模型保留网络结构信息。特别地,我们寻求优化以下目标函数,从而在给定深度模型
上下文集合
其中,σ(x)=1/(1+e-x),
步骤e中,为了捕获社区特征,上下文集合
其中,
最后,训练深度嵌入学习模型的目标函数被定义为,
本发明与现有技术相比的优点在于:在网络嵌入学习中,提供了一种解决网络稀疏性问题的新思路,通过以子结构为基本单位,构建基于图核的深度网络嵌入学习模型,节点的潜在结构和语义都可以被有效地捕获;而传统方法以连接、属性为基本单位,这些单位是非结构的,不包含有效的特征模式,因此生成的表征向量往往很难克服稀疏性带来的表征向量质量下降的问题。另一个方面,在传统方法中,只是简单地构造属性或社区信息相关的目标函数,并与原有的目标函数联合优化,结构信息与其它信息之间潜在相关性没有得到进一步挖掘。而本模型定义了定义一个全局构架,不同模态的数据嵌入到统一的隐含空间,充分利用不同模态数据之间细粒度的内在关联信息,学习异构信息之间的潜在相关性。进而可以利用节点内容信息来补足结构信息的缺失,也可以利用结构信息来补全用户属性。
附图说明
图1是基于图核的深度网络嵌入学习模型的本发明所述方法流程示意图;
图2是基于图核的深度网络嵌入学习模型的本发明一个实施例;
图3是步骤d中基于图核的深度卷积模型的模型结构。
具体实施方式
下面结合附图及本发明的实施方式对本发明的方法作进一步详细的说明。
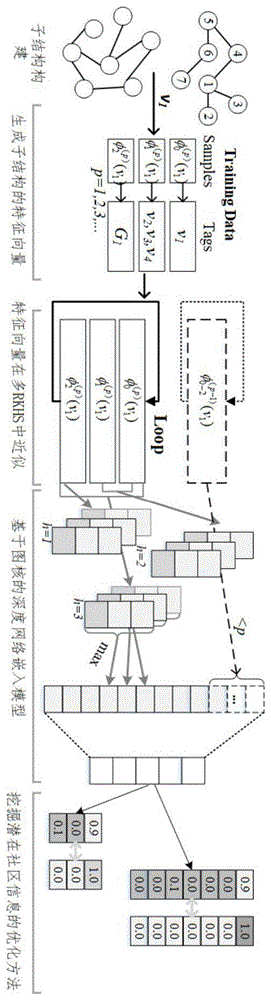
如图1所示,本发明一种基于图核的深度网络嵌入学习模型,图2给出一个本发明的例子。具体实现步骤如下:
步骤一:构造节点的子结构集合
节点的完整拓扑结构和语义信息往往被保留在某些子结构中。例如,节点与邻居节点的连接形成该节点的邻域子结构,节点往往属于某些社区构成社区子结构等。为每个节点构建一个子结构集合,记为gv={gi},其中gi是属于节点v的一个子结构。对于邻域子结构,采用广度优先采样方法,收集节点q跳范围内的所有邻居组成邻域子结构;将节点的某个社区子图作为社区子结构。每个节点都包含若干个邻域子结构和社区子结构。
步骤二:生成子结构的特征向量
对步骤一中所得到的每一个节点的子结构集合gv,用图核技术为每一个子结构生成一个特征向量。特别地,对于邻域子结构,按照节点加入时间的顺序采用一种广度优先采样的方法来为每个子结构生成字符串,然后利用n-gram方法生成字符串核特征向量,该特征向量保留了节点加入网络的时间信息。特别地,给定一个邻域子结构n,首先采用按照广度优先采样及节点加入的先后顺序收集所有节点的属性信息,然后连接它们得到字符串sn。记prej和sufj分别代表节点v的第j个邻居属性值cj的(k-1)个前缀和(k-1)个后缀。设函数ψ:
对于社区子结构,首先依据r卷积核要求将该子结构分解成多个邻域子结构,然后为每个邻域子结构生成特征向量,最后利用利用r卷积公式生成社区子结构特征向量,该特征向量保留了节点的潜在社区结构信息。特别地,r卷积图核分解子结构g为一组可比较的原子单位的集合γ(g)。两个子结构g和h间的r卷积图核被定义为,
其中k是一个用于比较原子单位g和h间的核函数,φ(g)是子结构g的特征向量记录子结构中每个原子单位的个数。依据r卷积图核的定义,每个社区子结构m可以被分解多个邻域子结构,其特征向量可以被呈现为,
其中,
步骤三:在多个重构核希尔伯特空间(rkhs)上近似特征向量
由于步骤二中子结构的特征向量维数往往很大甚至无穷维,利用sketch技术将子结构的特征向量在多个重构核希尔伯特空间上进行近似。特别地,给定φ(g),
步骤四:设计基于图核的深度卷积模型
对于每一个节点,将步骤三中所有子结构的多个近似特征向量输入到一个深度卷积网络模型,得到节点的表征向量。如图3所示,该模型包括一个输入层,一个深度卷积层,一个pooling层,多个线性层和一个输出层。输出为节点的最终表征向量。特别地,对于节点v的每一层近似特征向量集合
tk=f(w·xk:(k+h-1)+b)
其中,
步骤五:提出一种挖掘潜在社区信息的优化方法
对于步骤四中提出的深度网络嵌入学习模型,提出一种挖掘潜在社区信息的优化方法,使得生成的表征向量可以保存社区结构信息。特别地,我们寻求优化以下目标函数,从而在给定深度模型
上下文集合
其中,σ(x)=1/(1+e-x),
为了捕获社区特征,上下文集合
其中,
最后,训练深度嵌入学习模型的目标函数被定义为,
总之,本发明综合利用了社交网络分析、数据挖掘、机器学习等技术,为网络的节点生成高质量表征向量,进而基于该向量可进行其他应用的研究,对进一步研究社交网络的特性和挖掘相关信息提供了关键基础。
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!