一种基于时序数据的在线监控数据质量方法与流程
本发明属于数据预测技术领域,具体涉及一种基于时序数据的在线监控数据质量方法。
背景技术:
在过去的几十年中,统计过程控制(英文名称:statisticalprocesscontrol,英文缩写:spc)方法被广泛应用于质量结果的监控。通过评估一系列质量案例,控制图(英文名称:controlchart)可以检测质量的变化并对数据质量的恶化或改善发出警报,能够帮助确定问题的根源并提供有关解决问题的思路[1]。控制图方法用于测量、记录和评估过程质量特性,以监控过程是否处于受控(英文名称:incontrol,英文缩写:ic)状态,代表方法有指数加权移动平均(英文名称:exponentiallyweightedmovingaverage,英文缩写:ewma),累积总和(英文名称:cumulativesum,英文缩写:cusum),可变寿命调整显示(英文名称:variablelife-adjusteddisplay,英文缩写:vlad)和休哈特(英文名称:shewhart)。
现有方法均旨在监控数据质量平均水平的变化,即质量监控模型的位置参数(英文名称:locationparameters)的变化,而无法监控质量的“波动性”,即质量监控模型的比例参数(英文名称:scaleparameters)的变化,后者对数据质量评估同样至关重要。另一方面,现有方法的警报控制极限(英文名称:controllimit)为固定值,这意味着监控过程中的所有时刻都具有相同的权重,从而使它们在监控质量风险的波动性方面效果较差。因此,需要能够同时检测位置参数和比例参数变化的控制图来有效地监控数据质量,以提高数据的应用价值。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于时序数据的在线监控数据质量方法,解决现有大多数方法无法对质量的“波动性”(即质量监控模型的比例参数)进行有效监控的问题;以及解决现有方法的警报控制极限(英文名称:controllimit)是固定值从而对早期波动不敏感的问题。
本发明采用以下技术方案:
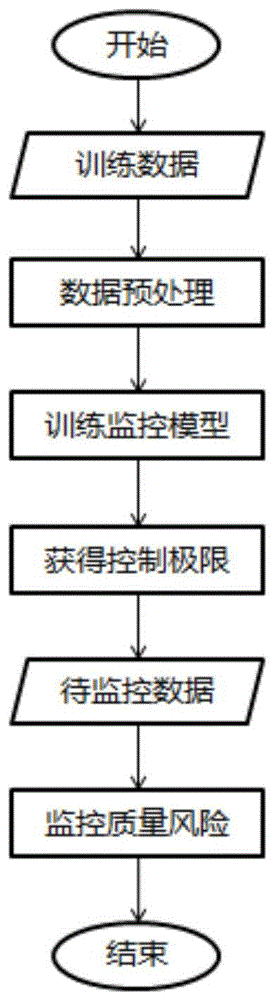
一种基于时序数据的在线监控数据质量方法,包括以下步骤:
s1、输入包括数据质量状态、数据质量不合格率、数据产生时间的时序数据,对时序数据进行数值化预处理;
s2、分别采用sesop、sesop-mfi、stsso和stsso-mfir方法计算统计量zn,训练监控模型;
s3、通过步骤s2计算得到统计量zn序列,利用对统计量zn序列的监控,并根据情况设定平均运行步长获得控制极限;
s4、监控质量风险,根据被监控数据的输入,实现输入一条数据及监控一条数据的实时监控。
具体的,步骤s2中,采用sesop和sesop-mfir计算统计量zn具体为:
s20101、利用训练数据,计算z1并储存;
s20102、利用训练数据,计算统计量zn并储存,通过建立风险调控模型得出数据质量不合格率pn。
进一步的,步骤s20101中,z1计算如下:
z1=λy1
其中,λ为平滑参数,y1为初始标准化后score统计量;y1为数据质量状态,当质量不合格时,y1=1,否则,y1=0;p1为数据质量不合格率。
进一步的,步骤s20102中,统计量zn计算如下:
zn=(1-λ)zn-1+λyn
其中,n为当前时间点,λ为平滑参数,yn为截止到第n个时序数据时得到的标准化后score统计量。
具体的,步骤s2中,采用stsso和stsso-mfir计算统计量zn具体为:
s20201、利用训练数据,计算z1并储存;
s20202、利用训练数据,计算统计量zn并储存,通过建立风险调控模型得出数据质量不合格率pn。
进一步的,步骤s20201中,z1计算如下:
z1=λt1
其中,t1为初始单边score型统计量,λ为平滑参数。
进一步的,步骤s20202中,统计量zn计算如下:
zn=(1-λ)zn-1+λtn。
具体的,步骤s3中,获得sesop和stsso的控制极限具体为:
s30101、根据数据规模和具体情况设定一个合适的目标arl;
s30102、根据目标arl,给控制极限clfixed=h一个初始h值;
s30103、结合蒙特卡洛方法原理,调整clfixed的值直到输出的arl等于目标arl为止;至此,获得sesop和stsso的固定值控制极限。
具体的,步骤s3中,获得sesop-mfir和stsso-mfir的控制极限具体为:
s30201、根据数据规模和具体情况设定一个合适的目标arl,并设置参数f和a;
s30202、根据目标arl,给控制极限
s30203、结合蒙特卡洛方法原理,调整clt中的h值直到输出的arl等于目标arl为止;至此,获得sesop-mfir和stsso-mfir的随时间变化的控制极限。
具体的,步骤s4中,对于被监控数据,根据步骤s2的流程计算统计量zn并通过步骤s3得到的控制极限进行监控,若超过控制极限值则发出警报;引入快速初始应答mfiradj,在sesop和stsso基础上将警报控制极限改进为随时间变化的控制极限clt。
与现有技术相比,本发明至少具有以下有益效果:
本发明一种基于时序数据的在线监控数据质量方法,通过对现有质量结果的ewma图方法的统计量zn的计算进行改进并监控zn,从而实现质量风险“波动性”的检测;利用检验统计量对统计量zn的计算进行改进,采用质量结果的分数测试统计量图方法stsso,将固定值的警报控制极限改进为随时间变化的控制极限。
进一步的,sesop及sesop-mfir通过加入标准化使得zn的监控能力更为稳定。
进一步的,stsso及stsso-mfir通过加入标准化和单边下界使得zn的在质量恶化方向上监控能力更为敏感。
进一步的,通过设置sesop和stsso的控制极限,使用者能够对发生的质量恶化趋势进行预警。
进一步的,通过设置带改进快速初始响应权重的控制极限,使用者能够更为快速对初始阶段发生的质量恶化进行预警。
进一步的,通过实时数据输入流程能够对数据质量状况进行实时监控,并对可能发生的质量恶化提出预警。
综上所述,本发明能够更为快速稳定的对不同阶段的数据质量情况进行监控,并对发生的质量恶化做出预警。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明流程图。
具体实施方式
本发明提供了一种基于时序数据的在线监控数据质量方法,基于指数加权移动平均(英文名称:exponentiallyweightedmovingaverage,英文缩写:ewma)图的质量风险监控方法:标准化后score监控方法(sesop)、标准化后单边score型监控方法(stsso)、带改进初始快速响应权重的标准化后score监控方法(sesop-mfir)和带改进初始快速响应权重的标准化后单边score型监控方法(stsso-mfir),输入数据为以每个数据为单位的数据质量状态及其对应的概率(或对应的其他可用于确定数据质量的状态变量),基于ewma控制图的原理,利用统计量的计算和监控,结合了标准化步骤和分数测试统计量,结合了调整快速初始应答特征,解决了现有技术在监控质量风险时对早期波动不敏感的问题。
请参阅图1,本发明一种基于时序数据的在线监控数据质量方法,包括以下步骤:
s1、数据预处理
输入数据为时序数据,包括数据质量状态、数据质量不合格率、数据产生时间等信息,一般来说,将数据划分为训练数据和监控数据,训练数据为往期数据质量,用来训练监控模型并找到控制极限(即警报线),监控数据为需要监控的数据质量,若为实时数据质量,则可以实现质量风险的实时监控和预测。本步骤将统计量计算所需的数据进行数值化,以便于后续的计算。例如,数据质量合格状态需处理为二值数据(0:合格;1:不合格)。
s2、训练监控模型
计算统计量zn,本发明所提供的四种监控方法中,sesop和sesop-mfir的统计量zn计算一致,将在步骤s201中进行详细说明;stsso和stsso-mfir的统计量zn计算一致,将在步骤s202中进行详细说明。
通过对现有方法——质量结果的ewma图方法的统计量zn的计算进行改进并监控zn,从而实现质量风险“波动性”的检测。
具体地,首先针对方法中的统计量做出如下说明:
zn=(1-λ)zn-1+λyn(1)
yn=(yn-pn)2-pn(1-pn)(2)
其中,n为当前时间点,λ为平滑参数,yn为第n个数据的独立二元质量结果,如果数据质量不合格,yn=1,否则,yn=0。xn为独立且均匀分布的正态随机变量,表示数据yn的质量风险因子。α为截距参数,β为另一个参数,pn为yn的对应数据质量不合格率。
对yn进行标准化,即,
提拱了一种ewma图方法——标准化质量结果的ewma图方法sesop,使得yn总体上服从标准正态分布,进而提高了质量结果的监控性能。
利用检验统计量(英文名称:teststatistic)t来对统计量zn的计算进行改进,提拱了另一种监控方法——质量结果的分数测试统计量图方法stsso。具体地,
zn=(1-λ)zn-1+λt(5)
其中,n=1,2,…,
s201、sesop和sesop-mfir的zn计算,具体包含以下步骤:
s20101、利用训练数据,按照公式(9)(10)计算z1并储存如下:
z1=λy1(9)
其中,λ为平滑参数;y1为数据质量状态,当质量不合格时,y1=1,否则,y1=0;p1为数据质量不合格率,其获得方法有两种:
1)输入数据直接给出;
2)输入数据给出一系列独立且均匀分布的正态随机变量xn
通过建立风险调控模型logit(pn)=xnβ+α,得出p1计算如下:
其中,α为截距参数,β为另一个参数。
s20102、利用训练数据,按照公式(1)(4)计算zn并储存。
类似地,数据质量不合格率pn有两种获得方式:
1)输入数据直接给出;
2)输入数据给出一系列独立且均匀分布的正态随机变量xn,通过建立风险调控模型logit(pn)=xnβ+α,得出pn的计算公式
s202、stsso和stsso-mfir的zn计算,具体包含以下步骤:
s20201、利用训练数据,按照公式(11)(12)(13)(14)计算z1并储存;
z1=λt1(11)
其中,b为判断常量;y1为数据质量状态,当质量不合格时,y1=1,否则,y1=0;u1=p1,p1为数据质量不合格率,其获得方法有两种,与步骤s20101相同。
s20202、利用训练数据,按照公式(15)(16)(17)(18)计算zn并储存,
zn=(1-λ)zn-1+λtn(15)
其中,b为判断常量;yn为数据质量状态,当质量不合格时,yn=1,否则,yn=0;un=pn,vn=pn(1-pn),pn为数据质量不合格率,其获得方法有两种,与s20102相同。
s3、获得控制极限
通过步骤s2的计算得到统计量zn序列,利用对zn的监控以及根据情况设定平均运行步长(英文名称:averagerunlength,英文缩写:arl)来获得控制极限(英文名称:controllimit,英文缩写:cl)。
平均运行步长是运行步长的平均值,常用来评估控制图的监控性能,其中,运行步长是一个随机变量,等价于观察到第一个失控信号所需的样本数量。
由于sesop、stsso与sesop-mfir、stsso-mfir的控制极限区别就在于前者是固定的后者是随时间变化的,因此sesop和stsso的控制极限获得过程一致,将在步骤s301中进行详细说明;sesop-mfir和stsso-mfir的控制极限获得过程一致,将在步骤s302中进行详细说明。
s301、获得sesop和stsso的控制极限:
s30101、根据数据规模和具体情况设定一个合适的目标arl;
s30102、根据目标arl,给控制极限clfixed=h一个初始h值;
s30103、结合蒙特卡洛方法原理,调整clfixed的值直到输出的arl等于目标arl为止;至此,获得sesop和stsso的固定值控制极限。
s302、获得sesop-mfir和stsso-mfir的控制极限;
s30201、根据数据规模和具体情况设定一个合适的目标arl,并设置参数f和a;
s30202、根据目标arl,给控制极限
s30203、结合蒙特卡洛方法原理,调整clt中的h值直到输出的arl等于目标arl为止;至此,获得sesop-mfir和stsso-mfir的随时间变化的控制极限。
s4、监控质量风险,根据被监控数据的输入,实现输入一条数据就监控一条数据的实时监控。
具体地,对于被监控数据,根据步骤s2的流程计算统计量zn并通过步骤s3得到的控制极限进行监控,若超过控制极限值则发出警报。
在sesop和stsso基础上将固定值的警报控制极限改进为随时间变化的控制极限。具体地,引入改进的快速初始应答(英文名称:modifiedfastinitialresponse,英文缩写:mfir)特征,具体为:
其中,a为调整参数,t为时间点或事件点,f为第一采样点的控制极限与初始值之间的距离比例。
进而,控制极限由原本的固定值h变为
将sesop和stsso升级为控制极限随时间变化的sesop-mfir和stsso-mfir,使得对监控过程早期出现的波动更为敏感。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明与目前已有算法相比,解决了现有算法在监控过程中对早期的波动不敏感的问题。为了验证本发明的有效性,测试了本发明所提供的四种方法——sesop、stsso、sesop-mfir和stsso-mfir的质量风险监控性能,并将平均运行长度(arl)这个重要指标与esop和cusum的结果进行了比较。
具体地,从arl和arl的标准差作为评价指标,其中,arl和arl的标准差越小,评价结果越好。
为了进行对比实验,本发明根据输入数据规模,将受控(英文名称:incontrol,英文缩写:ic)状态的arl设置为400;参数α和β分别设置为-1.386和0.5;参数α设置为0.014;参数λ一般在[0.005,0.1]内,当选取较小的λ值时,可以快速检测到较小的波动;反之,当选取较大的λ值时,可以快速检测到较大的波动。由于本实验的目的不是验证λ值对监控性能的影响,因此选择中间值0.01作为λ值。为了使结果可靠,所有实验均重复10,000次得出arl结果。结果如表1和表2所示:
表1:不同固定波动下的arl结果
表2:不同随机波动下的arl结果
由表1可见,当δ小于0.1,即固定漂移较小时,sesop和stsso在arl和arl标准差的表现都优于esop和cusum。具体地,sesop可以在早期阶段检测到微小的波动,stsso则有较为稳定的监控过程。由表2可见,当τ小于0.5时,cusum在arl结果上略有优势,但是随着随机效应的逐渐增大,esop和sesop在arl中的表现优于cusum。就arl标准差结果而言,stsso仍然具有绝对优势,这意味着当发生随机效应时,stsso的监控过程最稳定。因此,本发明不仅对早期波动较为敏感,而且在监控表现的稳定性上相较于现有技术也有大幅度提升。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!