一种识别中文书写错误的方法与流程
本发明涉及数据分析技术领域,更具体地说,它涉及一种识别中文书写错误的方法。
背景技术:
近年来,为改进中文学习者对中文字符的书写和记忆,市面上出现了一些辅助书写装置,例如书写模板、书写识别装置(例如数位板)等。书写模块预先压制有文字形状的凹槽,书写者用笔顺着凹槽就能描出漂亮的文字,但是采用书写模块来练习书写需要大量的、重复的练习,耗时耗力且不利于练习者形成自己的书写风格;利用书写识别装置可以对练习者的书写字符进行识别,并能在出现书写错误时指出错误。
但是现有的现在的书写识别装置是通过建立标准模板库然后记录练习者的书写轨迹,通过将字符的轨迹简单地与字符模板进行相似度对比,从而对书写的结构性错误以及书写笔顺等进行判别。由于汉字书写的复杂度以及每个人书写的多样性,单纯地与标准模板进行对比并不能很好地反映书写的准确度,识别的准确率偏低,有待改进。
技术实现要素:
针对现有技术存在的不足,本发明的目的在于提供一种识别中文书写错误的方法,其可以大大提高中文书写错误识别的准确率。
为实现上述目的,本发明提供了如下技术方案:
一种识别中文书写错误的方法,包括以下步骤:
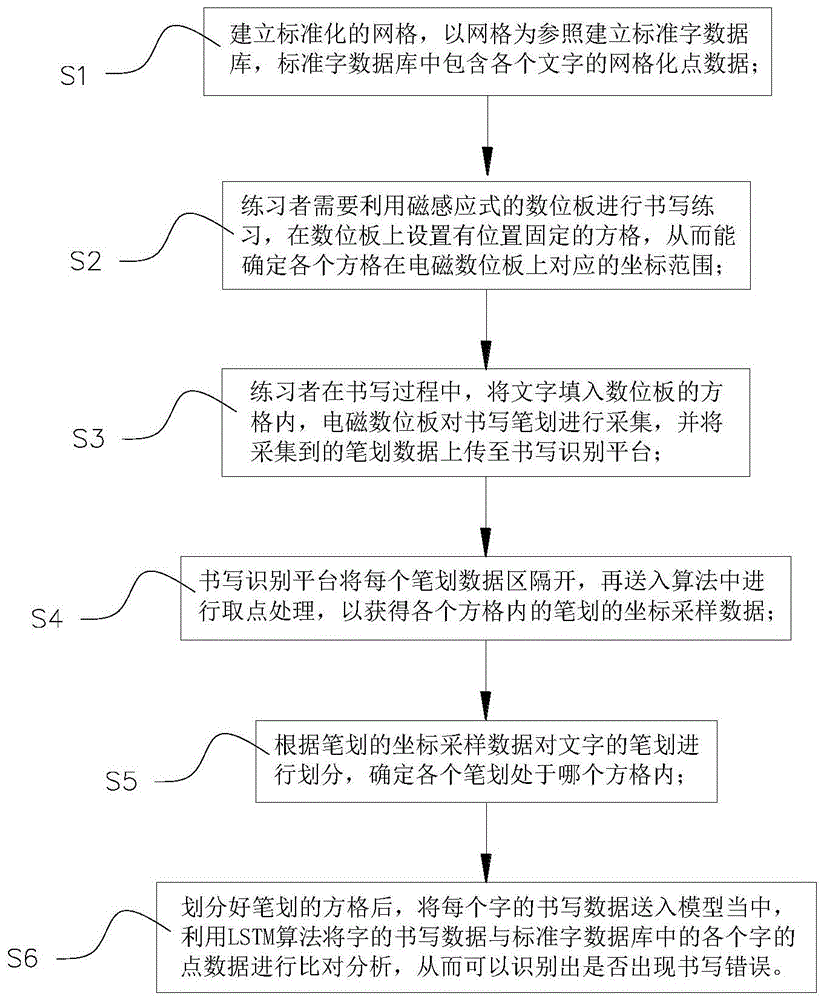
s1、建立标准化的网格,以网格为参照建立标准字数据库,标准字数据库中包含各个文字的网格化点数据;
s2、练习者需要利用磁感应式的数位板进行书写练习,在数位板上设置有位置固定的方格,从而能确定各个方格在电磁数位板上对应的坐标范围;
s3、练习者在书写过程中,将文字填入数位板的方格内,电磁数位板对书写笔划进行采集,并将采集到的笔划数据上传至书写识别平台;
s4、书写识别平台将每个笔划数据区隔开,再送入算法中进行取点处理,以获得各个方格内的笔划的坐标采样数据;
s5、根据笔划的坐标采样数据对文字的笔划进行划分,确定各个笔划处于哪个方格内;
s6、划分好笔划的方格后,将每个字的书写数据送入模型当中,利用lstm算法将字的书写数据与标准字数据库中的各个字的点数据进行比对分析,从而可以识别出是否出现书写错误。
作为优选方案,在s4步骤中,取点处理的具体方法为:将采集到的笔划划分为等长的20段,获得各段笔划的中点的坐标数据,即得到该笔划的采样坐标点集。
作为优选方案,在s5步骤中对笔划划分方格的规则为:若一个笔划的采样坐标点集都在某个方格内,则认为该笔划就属于该方格;若一个笔划的点集在几个方格里面,则分别计算该笔划在这几个方格内的点长,点长定义为sqrt(sqrt(xt–xt-1)+sqrt(yt–yt-1),其中(xt,yt)为该笔划在某个方格内的t时刻点坐标,笔划在哪个方格内的点长最长,则认为该笔划属于该方格;对于相邻的两个方格a和b,如果有连续三个笔划的方格划分为aba,其中划分为b方格的笔划符合前面两种规则,则该笔划改为划分到a方格。
作为优选方案,在s6步骤中lstm算法的计算步骤为:定义n=字的笔划数,输入定义为a={a0,a1…an-1},输出定义为h={h0,h1…hn-1}。输入a为时序点集合;输出h为a集合中每个输入笔划与标准笔划的匹配概率,对于第t个笔划的输入和输出,at为20个点的向量,把笔划t划分为等长的20段,对于划分的每一段的向量,(x’,y’)为每一段的中心点坐标;ht为n维的向量,对于第k维htk为输入笔划t与标准笔划k的匹配概率,在学习样本中笔划匹配值为1,不匹配值为0。
作为优选方案:所述电磁数位板的采点率为每秒200个点,位移监测精度为0.01mm。
一种识别中文书写错误的系统,包括计算机和与之通信连接的磁感应式的数位板,所述数位板的书写面上设置有位置固定的方格阵列,所述计算机上载有书写识别软件平台。
作为优选方案:所述数位板内装有振动马达,并在数位板内装有用于控制振动马达以不同模式振动的控制器,所述控制器与所述计算机通信连接,当书写识别平台识别出某种书写错误时,所述计算机向控制器发出对应的控制指令,所述控制器接收到所述控制指令后控制振动马达以相应的模式振动。
作为优选方案:所述控制器包括单片机模块,所述单片机模块的串口通过通信模块与计算机通信连接,所述单片机模块的pwm信号输出端用于向振动电机输出pwm控制信号。
作为优选方案:所述控制器采用包括单片机和放大电路,其中单片机采用的是at89c51芯片u1,放大电路包括npn型的三极管q1和pnp型的三极管q2,u1的40号引脚连接电源vcc,u1的18号引脚与19号引脚之间连接有晶振x1,电容c1与电容c2串联,电容c1的另一端与u1的19号引脚连接,c2的另一端与u1的18号引脚连接,u1的21号引脚通过电容r1与q1的基极连接,q1的集电极连接电源vcc,q1的发射极与q2的发射极连接,q2的基极与q1的基极连接,q2的集电极接地,振动马达的正极通过电感l1与q1的发射极连接,振动马达的负极接地,在振动马达的正极与负极之间连接有电容c3。
与现有技术相比,本发明的优点是:该方法对练习者书写的每个文字进行单独识别,且对文字的识别是识别文字的每个笔划,该方法具有极高的识别成功率,可以准确识别出中文书写的各种错误。
附图说明:
图1为书写识别方法的步骤示意图;
图2为书写识别系统的构成示意图;
图3为振动马达的控制器的电路图。
附图标记说明:1、计算机;2、数位板;3、方格。
具体实施方式
实施例一:
一种识别中文书写错误的方法,包括以下步骤:
s1、建立标准化的网格,以网格为参照建立标准字数据库,标准字数据库中包含各个文字的网格化点数据,即各个文字的各个笔划的点坐标。
s2、练习者需要利用磁感应式的数位板进行书写练习,在数位板上设置有位置固定的方格,从而能确定各个方格在电磁数位板上对应的坐标范围,各个方格的坐标向量与标准化网格的坐标向量相对应(两者可以相等或是成比例关系)。
s3、练习者在书写过程中,将文字填入数位板的方格内,电磁数位板对书写笔划进行采集,并将采集到的笔划数据上传至书写识别平台。
s4、书写识别平台将每个笔划数据区隔开,再送入算法中进行取点处理,以获得各个方格内的笔划的坐标采样数据。取点处理的具体方法为:将采集到的笔划划分为等长的20段,获得各段笔划的中点的坐标数据,即得到该笔划的采样坐标点集(包含20个点坐标)。
s5、根据笔划的坐标采样数据对文字的笔划进行划分,确定各个笔划处于哪个方格内。笔划划分方格的规则为:若一个笔划的采样坐标点集都在某个方格内,则认为该笔划就属于该方格;若一个笔划的点集在几个方格里面,则分别计算该笔划在这几个方格内的点长,点长定义为sqrt(sqrt(xt–xt-1)+sqrt(yt–yt-1),其中(xt,yt)为该笔划在某个方格内的t时刻点坐标,笔划在哪个方格内的点长最长,则认为该笔划属于该方格;对于相邻的两个方格a和b,如果有连续三个笔划的方格划分为aba,其中划分为b方格的笔划符合前面两种规则,则该笔划改为划分到a方格。
s6、划分好笔划的方格后,将每个字的书写数据送入模型当中,利用lstm算法将字的书写数据与标准字数据库中的各个字的点数据进行比对分析,从而可以识别出是否出现书写错误。具体的,lstm算法的计算步骤为:每个字使用1500以上训练样本,训练模型为lstm,训练样本定义如下:定义n=字的笔划数,输入定义为a={a0,a1…an-1},输出定义为h={h0,h1…hn-1}。输入a为时序点集合,目的是尽可能无损的捕捉到学生的书写行为;输出定义h,为a集合中每个输入笔划与标准笔划的匹配概率。对于at和ht(第t个笔划的输入和输出),at为20个点的(x,y)向量(即x轴维度、y轴维度),这里我们需要把笔划t量化为20个点,量化方式为把笔划划分了等长的20段,对于划分的每一段的向量(x,’y’)为每一段的中心点坐标;ht为n维的向量,对于第k维htk为输入笔划t与标准笔划k的匹配概率,在学习样本中笔划匹配值为1,不匹配值为0。模型评估函数为模型输出与样本输出的方差和最小。
模型运行:把输入字数据t={t0,t1…tn–1}(n=为输入字的笔划数)输入到训练好的模型,得到输出p={p0,p1…pn-1},p集合中每个元素为m维向量(m=标准字的笔划数),从输出我们得到输入字n笔与标准字m笔之间的匹配概率,因为标准字m笔只能对应输入字n笔中不重复的一笔,故我们要从n*m的矩阵中取出m个,使得匹配概率和最大,这里使用动态规划。从概率匹配和最大的结果中,我们可以为输入笔每一笔划分是否出现书写错误,分别是wrongstroke错笔,additionalstroke加笔,missingstroke漏笔,concatenatedstroke连笔,reversedstroke反笔,wrongsequence笔顺错误。
书写错误情况举例:
wrongstroke错笔:如果把“二”写成了“十”,得到概率匹配和最大结果为:输入字第一笔匹配标准字第一笔,值为0.93,输入字第二笔匹配标准字第二笔,值为0.03,故输入字第二笔错误。
additionalstroke加笔:如果把“二”写成“三”,得到概率匹配和最大结果为:输入字第一笔匹配标准字第一笔,值为0.91,输入字第三笔匹配标准字第二笔,值为0.96,输入字第二笔无匹配,故输入字第二笔为加笔。
missingstroke漏笔:如果把”二”写成”一”,得到概率匹配和最大结果为:输入字第一笔匹配标准字第一笔,值为0.91,标准字第二笔无匹配,故漏掉标准字第二笔。
concatenatedstroke连笔:把输入字中一笔拆成多笔,使得概率匹配和最大结果更大,则该笔为连笔。
reversedstroke反笔:把输入字中一笔调转,使得概率匹配和最大结果更大,则该笔为反笔。
wrongsequence笔顺错误:如果把”十“先写竖再写横,得到概率匹配和最大结果为:输入字第一笔匹配标准字第二笔,值为0.91,输入字第二笔匹配标准字第一笔,值为0.96,故第一第二笔笔顺错误。
本实施例中,数位板的采点率为每秒200个点,位移监测精度为0.01mm。
实施例二:
参照图2,一种识别中文书写错误的系统,包括计算机1和与之通信连接的磁感应式的数位板2,在数位板2的书写面上设置有位置固定的方格阵列3,计算机上1载有书写识别软件平台。
为了在练习者出现书写错误时发出提醒,本实施例中,在数位板内装有振动马达,并在数位板内装有用于控制振动马达的控制器。
参照图3,控制器采用包括单片机和放大电路,其中单片机采用的是at89c51芯片u1,放大电路包括npn型的三极管q1和pnp型的三极管q2,u1的40号引脚连接电源vcc,u1的18号引脚与19号引脚之间连接有晶振x1,电容c1与电容c2串联,电容c1的另一端与u1的19号引脚连接,c2的另一端与u1的18号引脚连接,u1的21号引脚通过电容r1与q1的基极连接,q1的集电极连接电源vcc,q1的发射极与q2的发射极连接,q2的基极与q1的基极连接,q2的集电极接地,振动马达的正极通过电感l1与q1的发射极连接,振动马达的负极接地,在振动马达的正极与负极之间连接有电容c3。
u1的串口(即其10号引脚和11号引脚)通过串口通信模块(例如常用的max232模块)转接数位板的usb插头,当数位板的usb插头插入计算机的usb接口时,控制器与计算机建立通信连接。u1的40号引脚以及q1的集电极均与数位板的usb插头连接,当usb插头与usb接口插接时,即可获得直流5v的电源vcc。
在练习者练习书写时,书写识别软件平台对书写笔划进行识别,在出现书写错误的时候,判断出错误的类型。并向控制器输出控制指令。例如出现错笔时,计算机向控制器发送指令一,u1接收到指令一时其21号引脚发出第一脉冲信号,第一脉冲信号使三极管q1和q2导通,同时脉冲信号能被qi和q2放大,放大的脉冲信号驱动振动马达发出较强的振动,从而使数位板向练习者反馈明显的振动,起到提醒练习者的作用,能够加深练习者对错误书写的印象,提升书写练习的效果;又如出现加笔的错误时,计算机向控制器发送指令二,u1接收到指令二时发出第二脉冲信号,第二脉冲信号与第一脉冲信号具有不同的占空比,如此可以驱动振动马达以不同的频率振动,从而实现了通过振动马达的不同模式振动来向练习者提示不同类型的书写错误,可以更好地辅助练习者改正各种书写错误。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!